本系列为作者学习UnityShader入门精要而作的笔记,内容将包括:
- 书本中句子照抄 + 个人批注
- 项目源码
- 一堆新手会犯的错误
- 潜在的太监断更,有始无终
总之适用于同样开始学习Shader的同学们进行有取舍的参考。
文章目录
- 复习(阶段性总结,答疑请直接从目录跳转)
- 渲染阶段
- 应用阶段和CPU的工作
- GPU渲染管线
- 几何阶段
- 光栅化阶段
- 最后
- 答疑
- 什么是OpenGL/DirectX
- 什么是HLSL、GLSL、CG
- 什么是DrawCall?
- 那么CPU和GPU是如何并行工作的?
- 为什么DrawCall多了影响帧率?
- 如何减少DrawCall
- 什么是固定管线渲染
- 所以什么是Shader?
- 拓展
(PS:章节答疑不是我答,是原作者对一些比较容易产生困惑的地方进行的解释)
复习(阶段性总结,答疑请直接从目录跳转)
上节笔记中,我们学习了GPU的渲染流水线。总结一下我们前两章所学习的全部知识。
首先,我们学习了渲染的基本流程,其实渲染的本质是将纹理,材质,网格等数据先从硬盘加载到RAM中,再从RAM加载到VRAM由GPU进行计算得到屏幕画面。往往是由3D场景出发渲染成2D的屏幕画面,整个渲染是GPU和CPU共同作用的结果。
渲染阶段
我们将整个渲染流水线简单划分为3个阶段:应用阶段(Application Stage),几何阶段(Geometry Stage),光栅化阶段(Rasterizer Stage)。
CPU的工作往往在应用阶段,在这一阶段大部分工作都是由开发者自定义的,我们需要实现的工作有:
- 布置场景,设定场景内的摄像机,物体,灯光等等需要被渲染的东西
- 进行粗粒度剔除(Culling),将画面中不需要被渲染的物体剔除掉
- 为场景及其物体设置纹理,材质,shader等渲染状态
应用阶段就是我们在游戏引擎或者3D软件中进行的那些常规的设置,例如进行Occlusion Culling,或者设置摄像机的深度、视锥,物体的Layer层级或者图层遮挡关系。这些是我们在3D应用程序中设置的渲染关系。
应用阶段和CPU的工作
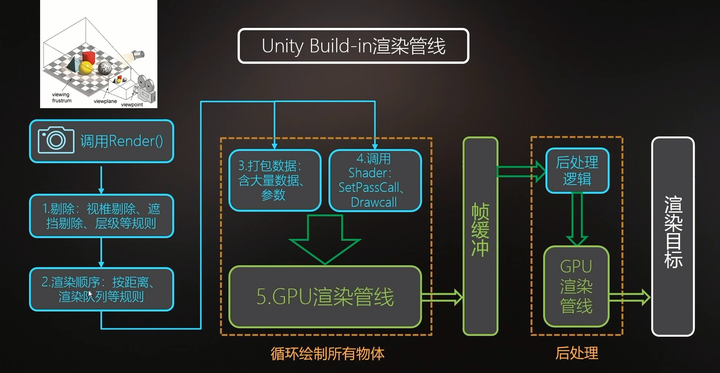
而Unity中应用阶段的工作其实也可细分为三个阶段:
1. 将数据加载到内存
2. 设置渲染状态
3. 调用DrawCall
第一阶段的作用是将硬盘中的网格,纹理,材质等等数据加载到RAM中,这是为了给GPU调用到VRAM作准备。
第二阶段,对应我们刚刚提到的那些常规的设置,可以对应到上图的123步骤。所有的数据会被打包成一个图元列表。
第三阶段,CPU已经把一切准备工作都处理好了,开发者在应用阶段的渲染状态设置了,所有数据也加载到RAM中了,此时我们需要GPU来完成接下来的工作。因此CPU会调用一个DrawCall,这个DrawCall代表了图形API的处理接口,来通知GPU渲染指定的图元列表。
(上图中的后处理阶段是Unity渲染管线为画面提供的二次渲染阶段,我们可以添加一些额外的画面处理效果,本质流程还是和我们讲的渲染流水线一致)
注意,图元以及后文提到的片元,并不是指代某个物体或者某个像素,而应该视为包含了各种状态信息和数据的集合。
GPU渲染管线
几何阶段
在GPU的流水线中,划分为两个阶段,就是上文提到的几何阶段和光栅化阶段。首先,GPU接受了应用阶段准备好的图元列表作为输入,而最终的输出结果是屏幕画面。

首先在几何阶段,会经历以下几步:
- 顶点着色器
- 曲面细分着色器
- 几何着色器
- 裁剪
- 屏幕映射
上述三个着色器都是完全可以由开发者配置以及编程的,裁剪是可配置不可编程,屏幕映射不可配置。
(着色器部分往往在Shader中可以被编程)
顶点着色器的作用是设置顶点的渲染状态。它主要完成的工作是:顶点坐标变换和逐顶点光照。
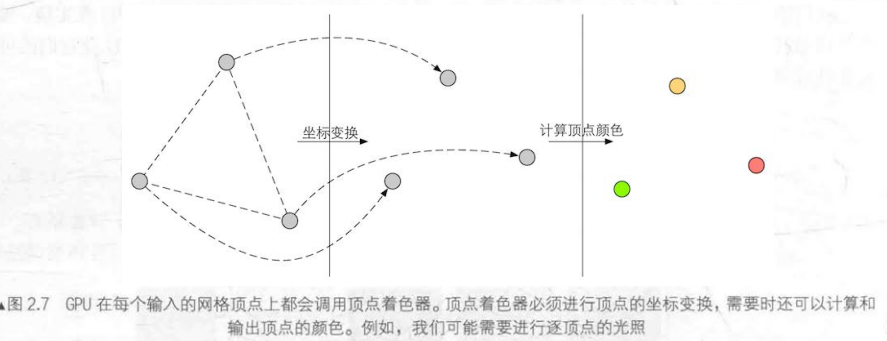
顶点坐标变换的作用是将顶点坐标从模型空间转换到一个齐次裁剪空间。 之所以转换为齐次坐标,是为了由硬件做透视算法后,最终得到归一化的设备坐标(Normalized Device Coordinates,NDC),其目的最终还是为了在屏幕上映射出正确的视图。
(对于坐标变换这一块只涉及了一点,篇幅实在有限,反正就是模型空间->齐次裁剪空间->NDC,详细请参考该文图形渲染中的坐标变换)
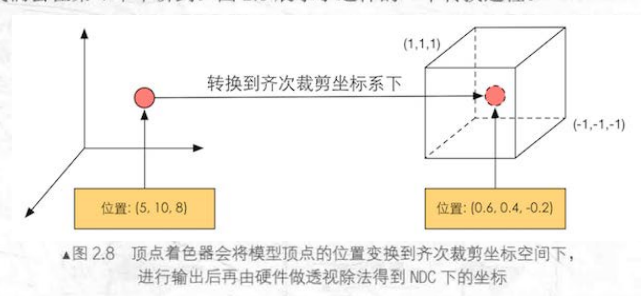
(左图是模型空间,右图是NDC,齐次裁剪坐标空间是四维的)
在我们将模型坐标转换为齐次裁剪坐标后,就方便我们进行裁剪了。上一阶段的顶点着色器的输出结果是图元,接下来会进入裁剪步骤(如果没有配置曲面细分着色器和几何着色器)。怪不得叫齐次裁剪坐标系,我们会根据图元在齐次裁剪坐标空间的位置来判断它是否被裁剪,那么位置状态总共就三种:
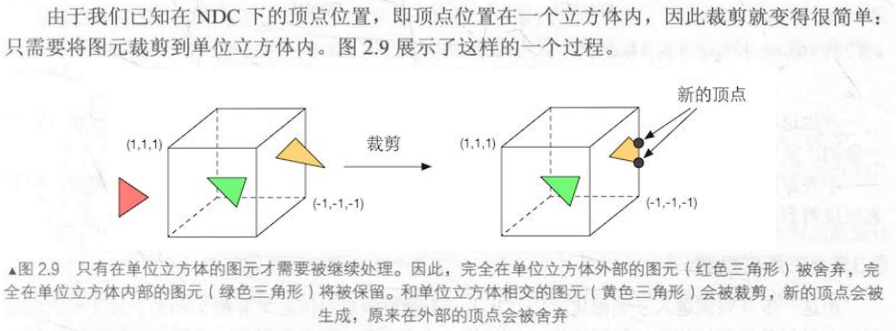
- 图元完全在空间内
- 图元完全在空间外
- 图元部分在空间内
(上图的单位立方体代表的是NDC,而实际裁剪工作是在裁剪空间内完成的)
如果图元完全在空间外则被舍弃,图元完全在空间内则保留,图元部分在空间内则在裁剪的位置添加新的顶点。
裁剪后需要对处理完的图元进行屏幕映射,这是几何阶段的最后一步,其输出结果将作为下一阶段光栅化的输入。在转化为NDC之后这一步就简单了,毕竟分量都是[-1,1]或者[0,1],因此只需与屏幕坐标进行简单的乘法,就可以得到屏幕坐标系了。

不难发现屏幕坐标系的变换实际上是二维的,而z坐标不会处理,屏幕坐标和z坐标会共同构成一个窗口坐标系 以作为光栅化阶段的输入。
光栅化阶段
光栅化阶段有两个重要的目标:
- 计算图元覆盖了那些像素
- 为这些像素计算颜色
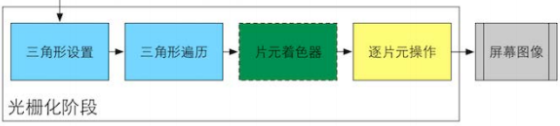
光栅化阶段又可以分为上述几个小阶段:
- 三角形设置
- 三角形遍历
- 片元着色器
- 逐片元操作
上述步骤都是围绕光栅化阶段的任务进行的。其中三角形设置和三角形遍历不可配置,片元着色器部分是完全可配置可编程,逐片元操作可配置不可编程。
现在,我们准备好了一个窗口坐标系作为输入,输入信息包括了当前的屏幕坐标系下的顶点位置,以及其他信息,例如z坐标代表的深度信息、法线方向、视角方向等等。更具体一点,这些顶点信息其实就是三角形网格的顶点。在三角形设置这一步,会连接每条边的两个端点,计算出三角形边界像素的坐标信息。
简单来说就是根据顶点信息连接三角形,并计算出三角形网格的表示数据。
经过三角形设置后,模型网格已经规划出了一大堆三角形网格,而在三角形遍历阶段会检查每个像素是否被一个三角形网格所覆盖,如果该像素被覆盖了,就会为其生成一个片元。并使用三角网格的3个顶点的顶点信息为覆盖区域内的像素进行插值。
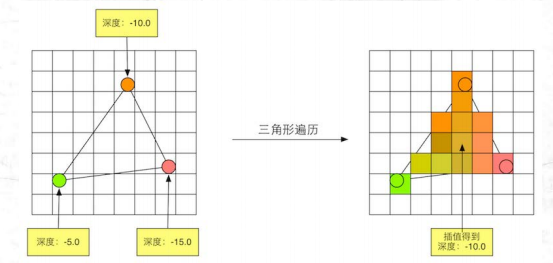
(插值的方法往往是建立当前三角形的重心坐标系)
经过了三角形遍历后,就会输出一系列的片元序列。一个片元并不是真正意义上的像素,而是包含了很多种状态的集合,这些状态用于计算每个像素的最终颜色。状态包括且不限于:屏幕坐标,深度信息,以及其他从几何阶段输出的顶点信息,例如法线、纹理坐标等。
片元着色器 的作用则是为每一个片元进行数据计算。前面的光栅化阶段计算的颜色信息实际上并不会影响屏幕上的像素颜色,只是一系列还未发生作用的数据信息——用于描述一个三角网格是怎样覆盖每个像素的。只有到了逐片元操作阶段才会正式地影响屏幕上的像素颜色。
在三角形遍历阶段,我们根据顶点信息(这些顶点信息本质上是顶点着色器的输出结果)插值得到了一系列数据。而在片元着色器阶段,我们会对刚才得到的数据进行插值,得到的输出结果是一个或者多个颜色值。(如下图所示):
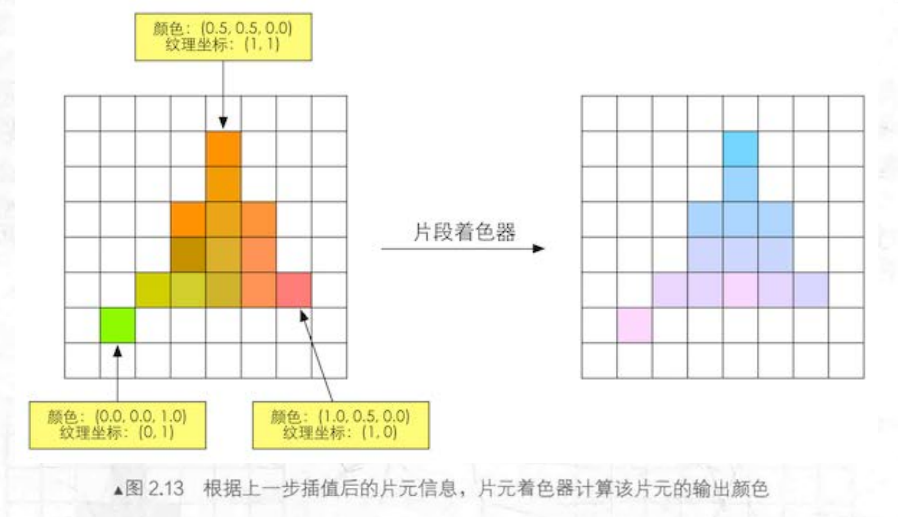
片元着色器会完成一个重要的工作,就是对纹理坐标的计算,当然每个顶点的纹理坐标也是由顶点着色器计算的,片元着色器则会对每个片元进行插值计算出它们的纹理坐标。
片元着色器用于完成许多重要的效果,但是仅能影响单个片元。(当片元着色器可以访问到导数信息时例外)
逐片元操作 是渲染流水线的最后一步。它完成的任务是:
- 进行模板测试,深度测试等等测试工作,以决定每个片元的可见性。
- 对通过测试的片元的颜色值和已经存储在颜色缓冲区的颜色值进行合并
逐片元操作阶段是高度可配置的。

该阶段首先会判断片元的可见性,它会对每个片元进行一系列测试,例如模板测试,深度测试。简单来说,响应的测试有其对应的缓冲区,例如模板测试有模板缓冲区,深度测试有深度缓冲区。
以模板测试为例,首先模板测试会读取(根据读取掩码)和片元相同位置的模板缓冲区内的模板值,并与片元的参考值(也使用读取掩码读取)进行比较,根据参考值与模板值的大小关系来确定如何对模板缓冲区进行对应的修改操作。
深度测试也是一样,会读取和片元相同位置的深度缓冲区的模板值与片元的参考值进行比较。不同的是如果片元被舍弃了,那么深度测试不会对缓冲区进行任何操作。而模板测试无论成功与否都可以对缓冲区进行修改操作。
经过了上述测试之后,依旧保存下来的片元是可以写入颜色缓冲的,因此我们会把片元颜色和颜色缓冲区内相同位置的颜色进行混合 。当然混合部分也会根据配置进行操作,例如对于不透明的物体,它们的渲染关系往往是根据深度值进行覆盖,因此我们可以关闭混合选项,这样片元的颜色信息就会覆盖相同位置的颜色缓冲。
而对于透明物体,我们希望进行颜色混合来展现透明度,因此片元颜色值就会根据透明通道和颜色缓冲区内的颜色进行混合,这个混合函数也和透明通道息息相关,可以进行相加、相减、相乘等操作。
如果想要提高渲染性能,我们发现可以把逐片元操作中的测试步骤提前,先对片元进行测试,再对其进行计算。这样就能节约下为那些注定被舍弃的片元计算的时间了。这个方法确实能够优化性能,例如有种叫Early-Z 的技术可以将深度测试提前执行。
但是,如果将测试提前,可能存在的问题就是:检验结果会与片元着色器冲突,例如我们在片元着色器中进行了透明度测试,并对没通过测试的片元手动舍弃。而这就导致GPU无法提前测试,为了避免冲突,现代GPU会判断片元着色器的操作是否与提前测试冲突,若有则禁用提前设置。这样反而造成了性能下降。
最后
最终,当光栅化阶段也完成了,渲染结果会被绘制到屏幕上,我们的屏幕显示的是颜色缓冲区的颜色值,为了避免屏幕看到正在光栅化的图元。GPU采取了双重缓冲 的策略 ,屏幕显示的是前置缓冲 ,而光栅化是在后置缓冲 进行的。当光栅化完成后,GPU就会交换前置缓冲和后置缓冲的内容,这样屏幕上就显示出连续的画面了。
答疑
什么是OpenGL/DirectX
简单来说,OpenGL和DirectX就是两个不同的图形编程API。类似的问题还有:Unity还是UE,Huawei还是iPhone,NVIDIA还是AMD,pytorch还是tensorflow,甜豆腐脑还是咸豆腐脑。
总而言之,这俩就是图像应用编程接口,我们开发者不想直接和GPU中的寄存器打交道,就需要使用到这些接口。它们是上层应用程序和底层GPU的沟通桥梁,应用程序向接口发送渲染命令,接口向显卡驱动发送渲染命令。
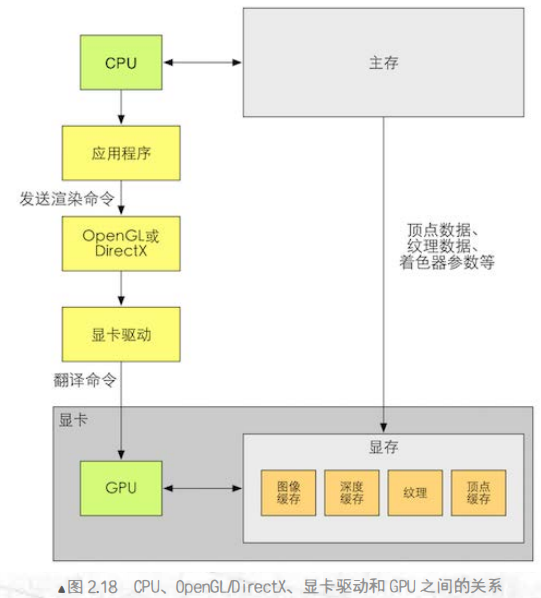
显卡驱动类似于显卡的操作系统,负责把接口函数翻译成GPU能听懂的语言,也负责把纹理等数据转换成GPU所支持的格式。而接口函数类似于机器语言。至于底层驱动怎么实现的,是显卡厂商的事情。
根据上图我们不难看出,不同的层级是高度抽象和封装的,CPU只需和应用程序以及内存中的数据打交道,应用只需向图像编程API发出指令——例如DrawCall 来通知OpenGL或者DirectX进行一些操作,例如对显卡驱动发出相应的指令,或者将内存中的顶点数据,纹理数据,着色器参数等数据转存到显卡的显存(VRAM)中(这些数据也是由图像编程接口转换成GPU支持的格式),而GPU也只需要和显卡驱动以及显存打交道。大家各司其职,还不需要接触自己不熟悉的对象。
什么是HLSL、GLSL、CG
这三种语言说白了就是图像编程中的高级语言,类似C++、C#、Java等等。
开发者在着色器阶段需要编写着色器语言(在Unity中也就是Shader),使用这些高级着色语言来方便我们为各种着色器进行编程。常见的着色语言就是DirectX的HLSL,OpenGL的GLSL以及NVIDIA的CG。这些语言会被翻译成与机器无关的汇编语言,也被称为中间语言(IL)(我在之前的C#学习笔记中学习.NET跨平台特性的时候也讲到了IL)。IL被显卡驱动翻译成真正的GPU可以理解的机器语言。
至于学习哪种语言?都2024年了还用选择吗?NVIDIA,YEEEEEEEEEES!
什么是DrawCall?
DrawCall就是应用程序向图像编程API调用渲染的指令,再溯源一点也就是CPU命令GPU进行渲染的指令。
开发者们都知道,在Unity中要优化渲染,就需要减少DrawCall。一个很直觉的想法是,既然渲染工作是GPU执行的,那么DrawCall过多一定会导致GPU在状态切换上耗时太多,造成性能问题。然而事实恰恰相反,真正拖后腿的是CPU。
那么CPU和GPU是如何并行工作的?
如果没有流水线,那么它们会怎么工作?就像第一章写到的洋娃娃厂一样,第一道工序完成后,CPU通过DrawCall告诉GPU:该你了。然后GPU去完成第二道工序。当然效率是很低的,任何一方没有完成工作都会影响手头的进度。

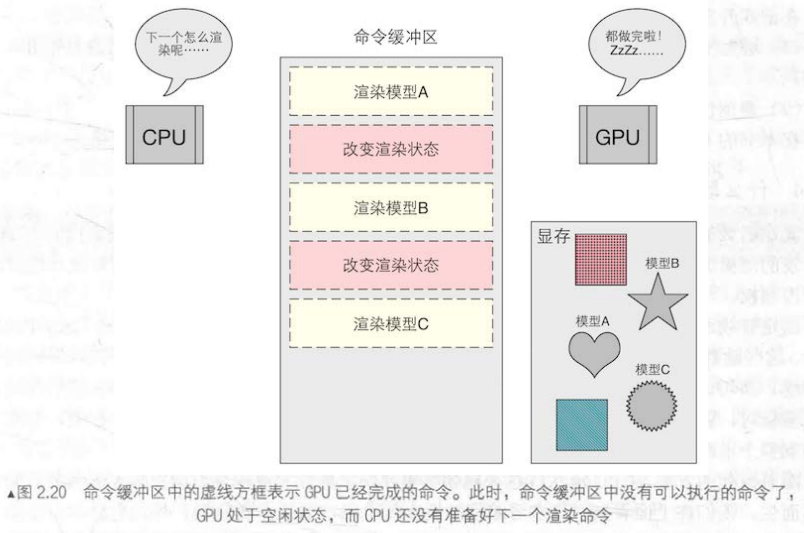
一个解决方法是使用命令缓冲区(Command Buffer) 。CPU打包完图元的渲染状态后,向命令缓冲区发送一条命令,缓冲区中有一个命令队列,每条命令都会加入到命令队列中。GPU处理完手头的工作后就会从命令队列取出队头的命令。那就很简单了,CPU只管发,GPU只管取,双方可以相互独立工作。
命令缓冲区内的命令有很多种类,DrawCall是其中一种,其他命令还有改变渲染状态等。比起DrawCall(上图黄色框框部分),改变渲染状态(红色框框部分)的命令要更加耗时 (此处指GPU耗时) 。
为什么DrawCall多了影响帧率?
文中举了一个简单的例子,创建10000个小文件,每个大小1KB,然后将它们从一个文件夹复制到另一个文件夹。同样的创建一个大小为10MB的文件,然后将它从一个文件夹复制到另一个文件夹。
那么移动同样大小的文件,我们发现前者消耗时间更多,因为对于操作系统来说文件大小不是关键,本质上大小相同,消耗的时间是相同的。问题在于10000个小文件,同样的复制指令就需要重复一万次,大部分的时间开销都在这些指令上了。
那么同样的,在每次调用DrawCall的时候,CPU都需要向GPU发送图元列表,其中会包括数据、状态和命令等。而发送前CPU还需要完成许多准备工作,例如检查渲染状态等。实际上GPU的渲染能力是很强的,200个或是2000个三角网格基本没有什么区别。因此渲染速度往往快于CPU提交命令的速度。如果DrawCall的数量太多,CPU就会把大量时间花费在提交DrawCall上,造成CPU的过载,如下图所示:
如何减少DrawCall
之前讲过,DrawCall过多会造成性能过载,CPU把大量的时间花费在准备DrawCall的工作上了,那么一个很自然的优化方法就是把一堆小的DrawCall合并为一个大的DrawCall。我们称之为合批(Batching) 。

合批也分为静态合批和动态合批两种方法 ,静态合批需要对物体勾选Static属性。Unity在Build的时候,会自动生成合并的网格,并将它以文件形式存储合并后的数据,这样在当场景被加载时,就会一次性提交整个合并模型的顶点数据。反正就是优化中经典的空间换时间的策略。
需要注意的是,虽然静态合批在编辑器里会显示减少了DrawCall,但实际上DrawCall并没有减少,所有合批的静态物体经历了一次状态设置和多次DrawCall。只不过由于我们将物体进行了静态合批,因此在渲染时可以视为同一个网格体,由于我们预先把所有的子模型的顶点变换到了世界空间下(第一次调用DrawCall的时候就已经完成了),并且这些子模型共享材质,所以在多次Draw call调用之间并没有渲染状态的切换,因为渲染API会缓存绘制命令,所以多次调用是不影响的。(当然某些情况不能用静态合批,例如大量的物体合并,渲染确实快了,但是你的内存受不了啊)
另一种方案就是动态合批,动态合批是专门为优化场景中共享同一材质的动态GameObject的渲染设计的。目标是以最小的代价合并小型网格模型,减少Drawcall。
动态合批的原理也很简单,在进行场景绘制之前将所有的共享同一材质的模型的顶点信息变换到世界空间中,然后通过一次Draw call绘制多个模型,达到合批的目的。当然,由于物体是动态的,每一帧都需要重新合并再发送,而模型顶点变换的操作是由CPU完成的,所以这会带来一些CPU的性能消耗。
在游戏开发过程中,为了减少 Draw Call 的开销,有两点需要注意。
(1) 避免使用大蜇很小的网格。当不可避免地需要使用很小的网格结构时,考虑是否可以合并
它们
(2) 避免使用过多的材质。尽量在不同的网格之间共用同一个材质。
什么是固定管线渲染
**固定函数的流水线(Fixed-Function Pipeline)**看,也称固定管线,这种管线只给开发者提供一些配置操作,但开发者没有对流水线阶段的完全控制权。
如果不是为了对较旧的设备兼容,不建议继续使用固定管线的渲染方式。
所以什么是Shader?
Shader所在的阶段就是渲染流水线的一部分,更具体地说,Shader就是:
- GPU流水线上一些高度可编程的阶段,而由着色器编译出来的最终代码是会再GPU上运行的。(对于固定管线的渲染,着色器有时等同与一些特定的渲染设置)
- 对特定类型着色器的编写,如顶点着色器,片元着色器等
- 依靠Shader我们可以控制流水线中的渲染细节,例如用顶点着色器进行顶点变换以及传递输出,用片元着色器来进行逐像素的渲染。
出色的游戏画面需要包括Shader在内的所有渲染流水线阶段的共同参与才能够完成,也包括引擎中的一些设置,例如:设置合适的渲染状态,使用合适的混合函数,开启还是关闭深度测试/深度写入。
拓展
如果你对渲染管线感兴趣,去学习RTR4!
如果对 OpenGL和DirectX 的渲染流水线感兴趣请阅读官方文档。