CAP理论
关于CAP理论的介绍可以直接看这篇文章
CAP分别是什么?
一致性(Consistency
一致性包括强一致性,弱一致性,最终一致性。
一致性其实是指数据的一致性,为什么数据会不一致呢?
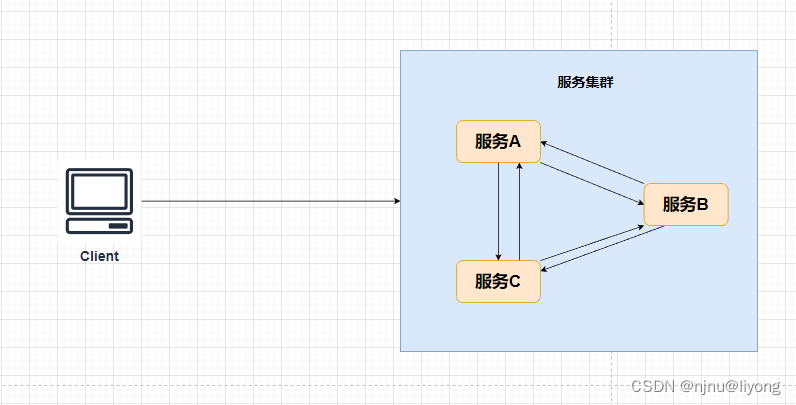
如上面这张图,我们服务是以集群的方式向外提供服务,客户端并不会关心我这次请求到了那个节点。如果我第一次请求到了A节点做了更新数据的操作,但是第二次我的请求被转发到B节点了。如果这个时候服务A和服务B的数据还没有进行同步,这个时候数据就不一致了,事实上我们也很难做到服务A的数据发生变化就可以立即传给B进行同步,特别是在请求特别频繁的情况下。因此要根据实际场景去判断是否一定要保证强一致性。例如涉及金钱和库存的这种服务集群肯定是要保证强一致性的。又例如点赞量和播放量或者访问量,这些并不需要实时一致,保证最终一致即可。
可用性(Availability)
其实就是不管数据正不正确,只要用户来请求,就返回给用户数据。
在我们说一致性的时候,如果去保证强一致性,这个时候客户端如果请求到达了B是不能对外提供服务的,因为一旦提供服务这个数据还是老的数据,就产生了数据的不一致性。但是如果不提供服务的话,那这个服务节点岂不是不可以用了吗?那就是没有保障可用性呀。所以我们也可以看到,一致性和可用性之间是需要做一定妥协的。
分区容错性(Partition tolerance)
1 分区
什么是分区,分布式系统分布在多个子网络中。分布式系统的服务节点可能由于网络原因,或者其它因素不能相互通信。这种情况就叫产生了分区。
2 什么是分区容忍?
因为产生分区这种情况一般来说是无法避免的,我们不能完全保证两个服务节点能够完全互通,不产生任何异常。
总结下来就是在一个分布式系统中,这个P分区是一定存在的。我们需要根据业务场景来做C和A的一些取舍。
常见组件保证的模式
- Nacos 保证了AP + CP
- Zookeeper 保证了CP
- Eureka 保证了AP
Distro 一致性协议(临时节点协议)
原文链接
distro协议网上的资料比较少,因为它是阿里“自创的协议“,通过源码总结一下distro协议的关键点:
distro协议是为了注册中心而创造出的协议;
客户端与服务端有两个重要的交互,服务注册与心跳发送;
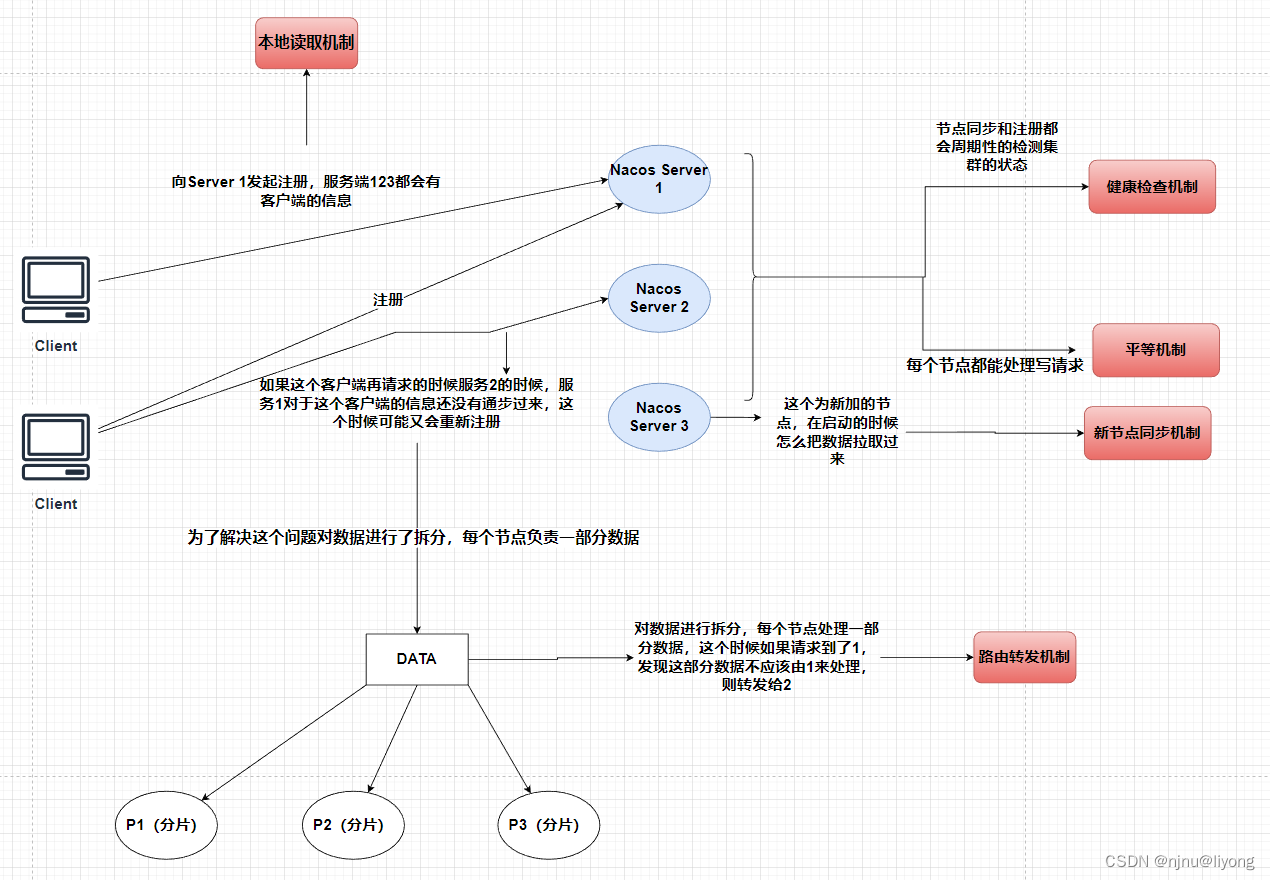
客户端以服务为维度向服务端注册,注册后每隔一段时间向服务端发送一次心跳,心跳包需要带上注册服务的全部信息,在客户端看来,服务端节点对等,所以请求的节点是随机的;
客户端请求失败则换一个节点重新发送请求;
服务端节点都存储所有数据,但每个节点只负责其中一部分服务,在接收到客户端的“写“(注册、心跳、下线等)请求后,服务端节点判断请求的服务是否为自己负责,如果是,则处理,否则交由负责的节点处理;
每个服务端节点主动发送健康检查到其他节点,响应的节点被该节点视为健康节点;
服务端在接收到客户端的服务心跳后,如果该服务不存在,则将该心跳请求当做注册请求来处理;
服务端如果长时间未收到客户端心跳,则下线该服务;
负责的节点在接收到服务注册、服务心跳等写请求后将数据写入后即返回,后台异步地将数据同步给其他节点;
节点在收到读请求后直接从本机获取后返回,无论数据是否为最新。
新节点同步机制:
DistroProtocol#startDistroTask
private void startDistroTask() {
if (EnvUtil.getStandaloneMode()) {
isInitialized = true;
return;
}
// 健康检查
startVerifyTask();
// 开始加载
startLoadTask();
}
平等机制:
Nacos 的每个节点是平等的,都可以处理写的请求
异步复制机制:
DistroProtocol#sync
public void sync(DistroKey distroKey, DataOperation action) {
sync(distroKey, action, DistroConfig.getInstance().getSyncDelayMillis());
}
健康检查机制:
DistroProtocol#startDistroTask
private void startVerifyTask() {
GlobalExecutor.schedulePartitionDataTimedSync(new DistroVerifyTimedTask(memberManager, distroComponentHolder,
distroTaskEngineHolder.getExecuteWorkersManager()),
DistroConfig.getInstance().getVerifyIntervalMillis());
}
本地读机制(每个节点拥有全量的数据):
但是写处理,是只有一部分数据,也就是有个数据拆分,分而治之的机制。
InstanceController#list
/**
* Get all instance of input service.
*
* @param request http request
* @return list of instance
* @throws Exception any error during list
*/
@GetMapping("/list")
@Secured(action = ActionTypes.READ)
public Object list(HttpServletRequest request) throws Exception {}
路由转发机制:
DistroFilter#doFilter
if (distroMapper.responsible(distroTag)) {
filterChain.doFilter(req, resp);
return;
}
Raft 一致性协议(持久化节点协议)
该协议主要是发起选举,选举后如何同步数据。一个节点起来了以后,会发起投票,如果集群过半数据认可这个节点则这个节点为leader,成为leader后与其它节点建立联系。
V1版本的选举与同步
try {
if (stopWork) {
return;
}
if (!peers.isReady()) {
return;
}
RaftPeer local = peers.local();
local.leaderDueMs -= GlobalExecutor.TICK_PERIOD_MS;
if (local.leaderDueMs > 0) {
return;
}
// 来到这里以后已经和Master失联了
// reset timeout
local.resetLeaderDue();
local.resetHeartbeatDue();
// 发起投票,里面会向其它节点发起异步请求
sendVote();
} catch (Exception e) {
Loggers.RAFT.warn("[RAFT] error while master election {}", e);
}
// 过半
if (maxApproveCount >= majorityCount()) {
RaftPeer peer = peers.get(maxApprovePeer);
peer.state = RaftPeer.State.LEADER;
if (!Objects.equals(leader, peer)) {
leader = peer;
ApplicationUtils.publishEvent(new LeaderElectFinishedEvent(this, leader, local()));
Loggers.RAFT.info("{} has become the LEADER", leader.ip);
}
}
// 处理心跳
try {
if (stopWork) {
return;
}
if (!peers.isReady()) {
return;
}
RaftPeer local = peers.local();
local.heartbeatDueMs -= GlobalExecutor.TICK_PERIOD_MS;
if (local.heartbeatDueMs > 0) {
return;
}
local.resetHeartbeatDue();
sendBeat();
} catch (Exception e) {
Loggers.RAFT.warn("[RAFT] error while sending beat {}", e);
}
V2版本的选举与同步
涉及源码
com.alibaba.nacos.naming.consistency.DelegateConsistencyServiceImpl
com.alibaba.nacos.naming.consistency.persistent.PersistentConsistencyServiceDelegateImpl#PersistentConsistencyServiceDelegateImpl
com.alibaba.nacos.naming.consistency.persistent.impl.PersistentServiceProcessor#afterConstruct
com.alibaba.nacos.core.distributed.raft.JRaftProtocol#addRequestProcessors
com.alibaba.nacos.core.distributed.raft.JRaftServer#createMultiRaftGroup
com.alipay.sofa.jraft.RaftGroupService#start(boolean)
com.alipay.sofa.jraft.RaftServiceFactory#createAndInitRaftNode
com.alipay.sofa.jraft.core.NodeImpl#init
com.alipay.sofa.jraft.core.NodeImpl#electSelf
com.alipay.sofa.jraft.core.NodeImpl#becomeLeader
同步
com.alipay.sofa.jraft.ReplicatorGroup#addReplicator(com.alipay.sofa.jraft.entity.PeerId)
部分源码:
private BasePersistentServiceProcessor createNewPersistentServiceProcessor(ProtocolManager protocolManager,
ClusterVersionJudgement versionJudgement) throws Exception {
final BasePersistentServiceProcessor processor =
EnvUtil.getStandaloneMode() ? new StandalonePersistentServiceProcessor(versionJudgement)
: new PersistentServiceProcessor(protocolManager, versionJudgement);
processor.afterConstruct();
return processor;
}
PersistentServiceProcessor#afterConstruct
@Override
public void afterConstruct() {
super.afterConstruct();
String raftGroup = Constants.NAMING_PERSISTENT_SERVICE_GROUP;
this.protocol.protocolMetaData().subscribe(raftGroup, MetadataKey.LEADER_META_DATA, o -> {
if (!(o instanceof ProtocolMetaData.ValueItem)) {
return;
}
Object leader = ((ProtocolMetaData.ValueItem) o).getData();
hasLeader = StringUtils.isNotBlank(String.valueOf(leader));
Loggers.RAFT.info("Raft group {} has leader {}", raftGroup, leader);
});
this.protocol.addRequestProcessors(Collections.singletonList(this));
// If you choose to use the new RAFT protocol directly, there will be no compatible logical execution
if (EnvUtil.getProperty(Constants.NACOS_NAMING_USE_NEW_RAFT_FIRST, Boolean.class, false)) {
NotifyCenter.registerSubscriber(notifier);
waitLeader();
startNotify = true;
}
}
JRaft
public void init(RaftConfig config) {
if (initialized.compareAndSet(false, true)) {
this.raftConfig = config;
NotifyCenter.registerToSharePublisher(RaftEvent.class);
this.raftServer.init(this.raftConfig);
this.raftServer.start();
// There is only one consumer to ensure that the internal consumption
// is sequential and there is no concurrent competition
NotifyCenter.registerSubscriber(new Subscriber<RaftEvent>() {
@Override
public void onEvent(RaftEvent event) {
Loggers.RAFT.info("This Raft event changes : {}", event);
final String groupId = event.getGroupId();
Map<String, Map<String, Object>> value = new HashMap<>();
Map<String, Object> properties = new HashMap<>();
final String leader = event.getLeader();
final Long term = event.getTerm();
final List<String> raftClusterInfo = event.getRaftClusterInfo();
final String errMsg = event.getErrMsg();
// Leader information needs to be selectively updated. If it is valid data,
// the information in the protocol metadata is updated.
MapUtil.putIfValNoEmpty(properties, MetadataKey.LEADER_META_DATA, leader);
MapUtil.putIfValNoNull(properties, MetadataKey.TERM_META_DATA, term);
MapUtil.putIfValNoEmpty(properties, MetadataKey.RAFT_GROUP_MEMBER, raftClusterInfo);
MapUtil.putIfValNoEmpty(properties, MetadataKey.ERR_MSG, errMsg);
value.put(groupId, properties);
metaData.load(value);
// The metadata information is injected into the metadata information of the node
injectProtocolMetaData(metaData);
}
@Override
public Class<? extends Event> subscribeType() {
return RaftEvent.class;
}
});
}
}