一、概述
数据库与缓存数据一致性问题,一直以来都是大家比较关注的问题。针对一致性的解决方案也是非常多,以下主要针对方案的梳理与分类:
数据库数据与缓存数据一致性的方案,可以从不同的角度来分类,比如:
一致性的强度
可以分为强一致性和最终一致性。强一致性要求每次写入操作后,缓存中的数据和数据库中的数据完全一致。最终一致性允许每次写入操作后,缓存中的数据和数据库中的数据存在一定的延迟,但最终会达到一致。
更新缓存的时机
可以分为先更新缓存,后更新数据库和先更新数据库,后更新缓存。这两种方案都需要考虑操作失败、并发冲突、数据过期等情况,以及如何处理这些情况。
删除缓存的时机
可以分为先删除缓存,后更新数据库和先更新数据库,后删除缓存。这两种方案都可以避免缓存利用率低的问题,但也需要考虑操作失败、并发冲突、缓存重建等情况,以及如何处理这些情况。
保证一致性的手段
可以分为分布式锁、消息队列、订阅变更日志等。这些手段都是为了解决一些特定的场景或问题,比如减少数据不一致的时间窗口、避免并发导致的数据错乱、提高缓存利用率和并发性等。
二、实现方案分类
其实整个方案的着力点在于一致性,个人感觉可以按一致性的强度来分类:
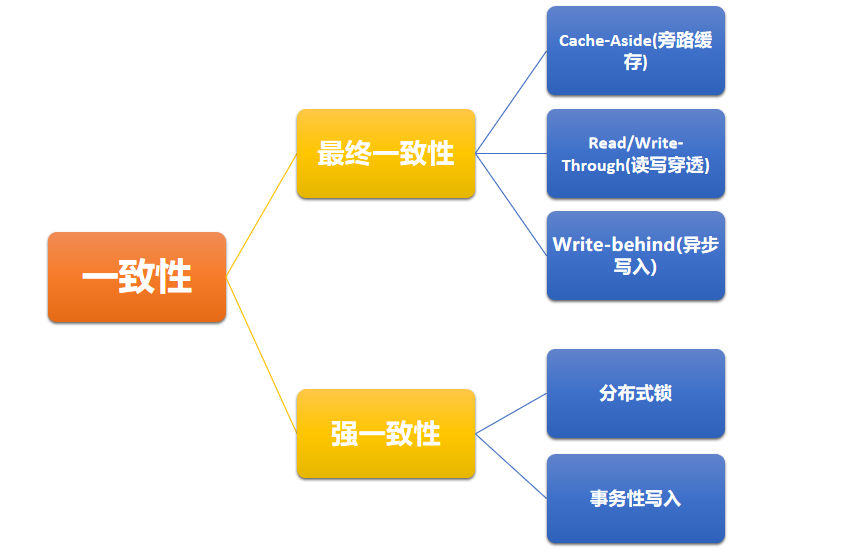
2.1、最终一致性

1)Cache-Aside Pattern (旁路缓存=更DB、删缓存)
Cache-Aside Pattern,也被称为旁路缓存模式,是一种常见的缓存设计模式,其中缓存的管理由应用程序显式处理。在这种模式下,应用程序负责决定何时读取、写入和使缓存失效,而不是由缓存系统自动处理。
以下是 Cache-Aside 模式的基本工作流程:
读取数据: 当应用程序需要从数据库中获取数据时,它首先检查缓存是否已有。
未命中缓存: 如果缓存中没有,应用程序从数据库中读取数据,并将其放入缓存。
写入数据: 当应用程序对数据进行写入操作时,它首先更新数据库,然后删除缓存。
Cache-Aside 模式的优点包括:
- 灵活性: 应用程序完全掌握缓存的读取、写入和失效策略,具有灵活性和可定制性。
- 简单性: 实现相对简单,不需要复杂的缓存管理逻辑。
然而,这种模式也有一些潜在的缺点:
- 一致性: 如果高并发或应用程序未能正确管理缓存时,可能导致短期数据库与缓存之间的数据不一致。
2)Read/Write-Through Pattern (读写穿透=缓存主)
Read/Write-Through Pattern(读写穿透模式)与 Cache-Aside 模式类似,但在数据的读取和写入方面有一些不同。
- Cache-Aside 要求应用程序主动管理缓存,读写操作都需要应用程序显式地处理。
- Read/Write-Through 则是一种更被动的方式,缓存系统自动处理数据的加载和写回,应用程序只需从缓存中读取和写入数据。
Read-Through:
-
- 读取数据: 当应用程序需要读取数据时,它首先检查缓存。
- 未命中缓存: 如果缓存中没有所需数据,应用程序不直接从数据存储中读取数据,它会请求缓存,缓存会在未命中时,自动从数据存储中获取数据,然后将数据写入缓存,并将数据返回给应用程序。
- 命中缓存: 如果缓存中存在所需数据,应用程序直接从缓存中获取数据。
Write-Through:
-
- 写入数据: 当应用程序对数据进行写入操作时,它首先更新缓存,然后再更新底层的数据存储。
- 保持一致性: 写入操作始终通过缓存,以确保数据在写入到底层存储之前已经存在于缓存中,从而保持数据一致性。
- 缓存失效: 由于写入操作总是通过缓存进行,可以确保缓存中的数据是最新的。在写入后,缓存中的对应数据可能需要失效,以便下次读取时重新从数据存储加载。
Read/Write-Through 模式的优点包括:
- 一致性: 通过在写入时通过缓存,可以保持数据的一致性。
- 简化应用程序逻辑: 应用程序只需关心读写缓存,而不需要关心底层数据存储的具体细节。
但与此同时,这种模式也可能引入一些延迟,另外缓存本身实现。
3)Write-behind Pattern (异步写入=缓存主、DB异步)
Write-Behind Pattern(异步写入模式)与 Cache-Aside 模式和 Read/Write-Through 模式类似,但在写入数据方面有一些不同之处。该模式的主要特点是,写入操作首先更新缓存,然后异步地将数据写回到底层数据存储,而不会阻塞应用程序。
以下是 Write-Behind 模式的基本工作流程:
写入数据: 当应用程序对数据进行写入操作时,它首先更新缓存,然后立即返回成功,而不等待底层数据存储的写入完成。
异步写入: 缓存系统异步地将更新后的数据写回到底层数据存储。这可以通过后台任务、消息队列等异步机制来实现。
Write-Behind 模式的优点包括:
- 提高写入性能: 应用程序无需等待底层存储的写入操作完成,因此写入操作的性能可能更高。
- 降低延迟: 应用程序获得写入成功的反馈速度更快,因为不需要等待底层存储的确认。
缺点:
- 一致性风险: 在异步写入过程中,如果底层存储发生故障或写入失败,可能导致缓存与底层存储的不一致。
- 难以调试: 异步写入模式可能增加系统的复杂性,特别是在处理一致性和错误情况时。
4)延时双删
- 先删缓存
- 再更新DB
- 延时(保证DB完全被更新)
- 再次删缓存(第一次删缓存后,在更新DB完成前,这时的线程读取DB数据还是旧的,它放入缓存的数据也是旧的,所以要二次删缓存)
这两次缓存删除操作确保了在写操作期间,即使有其他线程在更新数据库之前读取了旧的数据,延时双删策略也能保证最终缓存中的数据是最新的。这样可以有效地维护数据库和缓存之间的一致性。
2.2、强一致性
1)分布式锁
在分布式系统中,实现数据库与缓存数据的强一致性通常需要使用分布式锁。分布式锁可以确保在任何时候只有一个节点能够对数据进行写操作,从而避免了并发写入导致的一致性问题。实现分布式锁需要谨慎处理,并确保在各种异常情况下都能够保持一致性。此外,分布式锁的性能开销相对较高,因此在设计时需要权衡一致性和性能。
2)分布式事务
分布式事务确保在涉及多个数据存储的复杂操作中,要么所有的操作都成功,要么所有的操作都失败,从而维护数据的一致性。同样分布式事务会引入性能开销,并且一些缓存系统可能并不原生支持分布式事务。在一些情况下,可能需要通过其他手段,例如补偿性操作或定期的一致性检查,来确保数据库与缓存之间的一致性。
三、总结
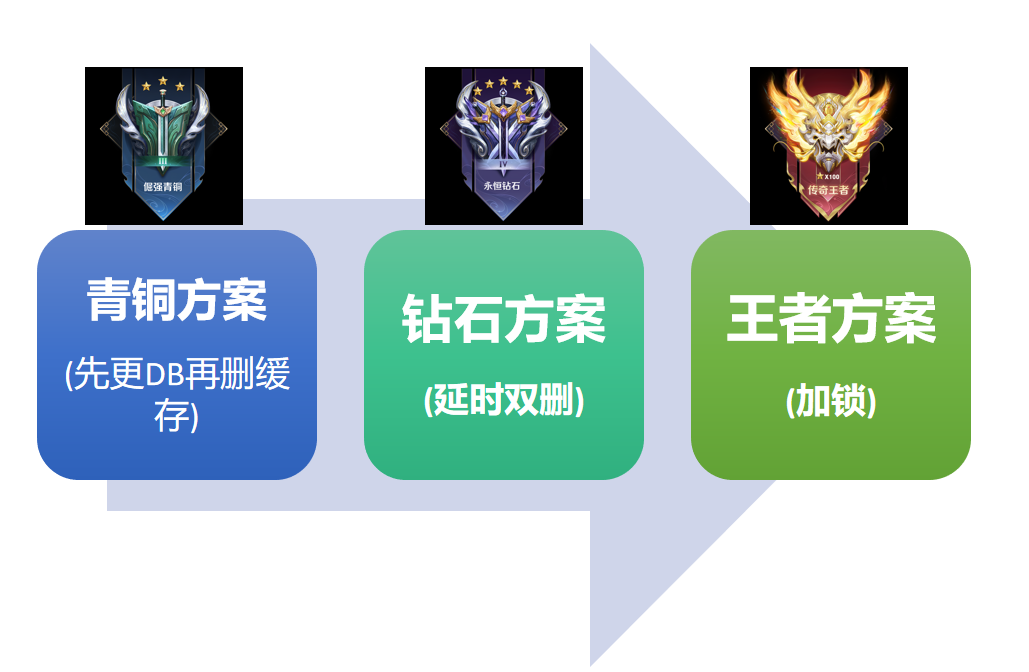
- 如果系统或业务相对比较简单,对一致性要求不是太高,可选择先更新DB再删除缓存(青铜方案=旁路缓存)。这也是我们平常用的最多的一种方案。
- 如果系统或业务相对比较复杂,对一致性要求相对较高,可以选择延时双删(钻石方案=删缓存->更DB->删缓存)。实现有的麻烦,但相对消耗较小。
- 如果系统或业务很复杂,对一致性要求很高,可以选择加锁或事物控制。可以保证强一致性,但相对消耗就很大。