原文链接
Pinterest 是一个以图片为主的社交网络,用户可以将图片保存或 "钉 / pin" 在自己的图板上。Pinterest 在 2019 年上市,目前市值 250 亿美金。本文内容主要根据 2012 年 Scaling Pinterest 的分享。

2012 年 1 月,Pinterest 的月独立用户数量达到 1170 万,而当时只有 6 名工程师。 Pinterest 于 2010 年 3 月推出,是当时月活用户突破 1000 万最快的公司。
扩展 Pinterest 的经验教训
- 使用已知的成熟技术。Pinterest 当时涉足较新的技术,导致了数据损坏等问题。
- 保持简单。(反复出现的主题!)
- 不要太有创意。团队采用的架构可以增加更多相同的节点来扩大规模。
- 限制选项。
- 数据库分片 > 集群。这减少了跨节点的数据传输,是件好事。
- 享受乐趣!新工程师能够在第一周内贡献代码。
2010 年 3 月:Closed beta 发布,1 名工程师
Pinterest 于 2010 年 3 月推出,当时只有一个小型 MySQL 数据库、一个小型 web server 和一名工程师(还有两位联合创始人)。
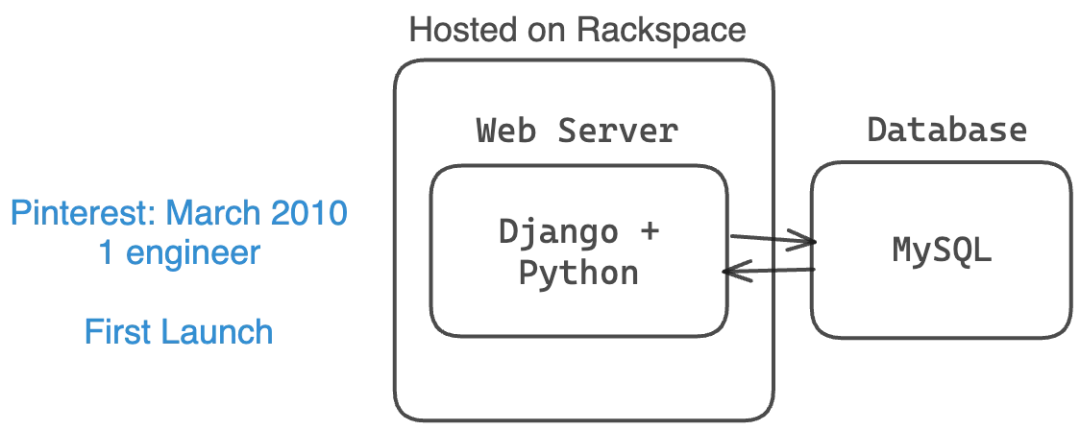
2011 年 1 月:10,000 名用户,2 名工程师
九个月后的 2011 年 1 月,Pinterest 的架构已经发展到可以处理更多用户。当时他们仍然只接受邀请,只有两名工程师。
他们拥有:
- 基本的 web server 技术栈(亚马逊 EC2、S3 和 CloudFront)
- 用于后端的 Django(Python)
- 4 台 web server 作为冗余
- NGINX 作为反向代理和负载均衡。
- 1 个 MySQL 主数据库 + 1 个只读数据库
- 用于计数的 MongoDB
- 1 个任务队列和 2 个任务处理器,用于异步任务
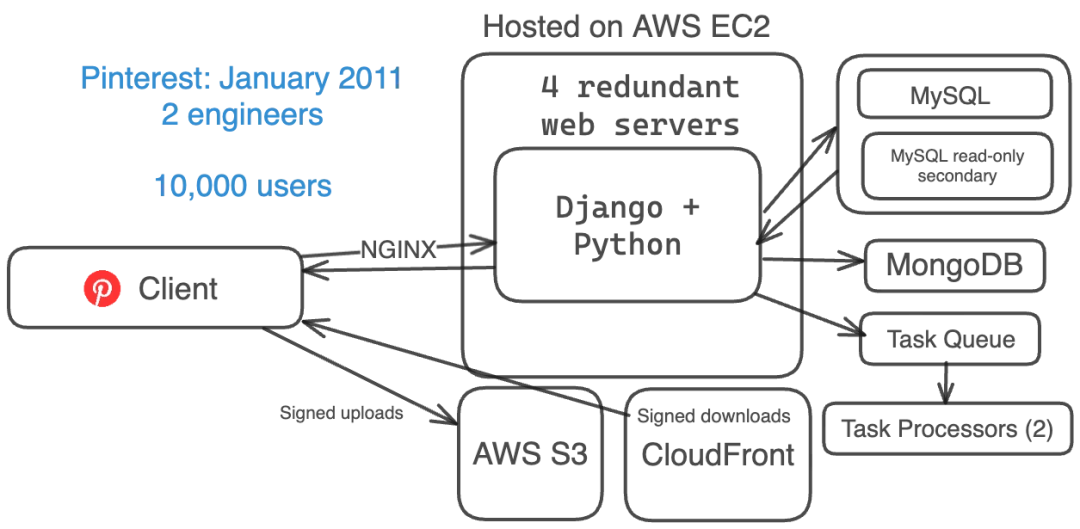
2011 年 10 月:320 万用户,3 名工程师
从 2011 年 1 月到 2011 年 10 月,Pinterest 的增长速度极快,用户数量每隔一个半月就翻一番。
他们在 2011 年 3 月推出的 iPhone 应用程序是推动这一增长的因素之一。
当事物快速发展时,技术出现问题的频率会超出你的预期。
这时Pinterest 犯了一个错误:他们把架构弄得过于复杂了。
他们只有 3 名工程师,但却采用了 5 种不同的数据库技术来存放数据。
他们既要手动对 MySQL 数据库进行分片,又要使用 Cassandra 和 Membase(现在的 Couchbase)对数据进行集群。
他们「过于复杂的技术栈」:
- Web server 栈(EC2 + S3 + CloudFront)
- Pinterest 开始使用 Flask(Python)作为后端服务器
- 16 台 web server
- 2 个 API 引擎
- 2 个 NGINX 代理服务器
- 5 个手动分片的 MySQL DB + 9 个只读
- 4 个 Cassandra 节点
- 15 个 Membase 节点(3 个独立集群)
- 8 个 Memcache 节点
- 10 个 Redis 节点
- 3 个任务路由器 + 4 个任务处理器
- 4 个 Elastic Search 节点
- 3 个 Mongo 集群
⚠️ 集群崩了
数据库集群 (Database Clustering) 是将多个数据库服务器连接起来作为一个系统共同工作的过程。
从理论上讲,集群可以自动扩展数据存储、提供高可用性、自由负载平衡,并且不会出现单点故障。
遗憾的是,在实践中,集群过于复杂,升级机制困难,而且存在一个大的单点故障 (SPOF)。

每个 DB 都有一个集群管理算法,在 DB 之间进行路由。
当一个数据库出现问题时,就会添加一个新的数据库来替代它。
理论上,集群管理算法应该可以很好地处理这个问题。
但实际上,Pinterest 的集群管理算法中存在一个 bug,破坏了所有节点上的数据,破坏了数据该如何重新平衡,并产生了一些无法修复的问题。

Pinterest 的解决方案是什么?
从系统中移除所有集群技术(Cassandra、Membase)。全面采用 MySQL + Memcached(更成熟)。
MySQL 和 Memcached 都是久经考验的技术。Facebook 利用这两种技术创建了世界上最大的 Memcached 系统,每秒轻松处理数十亿次请求。
2012 年 1 月:1100 万用户,6 名工程师
2012 年 1 月,Pinterest 的月活跃用户约为 1100 万,日活跃用户在 1200 万到 2100 万之间。
此时,Pinterest 已经花时间简化了他们的架构。
他们删除了当时不太成熟的方案,如集群和 Cassandra,取而代之的是成熟的方案,如 MySQL、Memcache 和分片。
他们简化后的技术栈:
- 亚马逊 EC2 + S3 + Akamai(取代 CloudFront)
- AWS ELB(弹性负载平衡)
- 90 个 web servers + 50 个 API 引擎(使用 Flask)
- 66 个 MySQL DB + 66 个只读
- 59 个 Redis 实例
- 51 个 Memcache 实例
- 1 个 Redis 任务管理器 + 25 个任务处理器
- 分片式 Apache Solr(取代 Elasticsearch)
- 移除 Cassanda、Membase、Elasticsearch、MongoDB、NGINX

Pinterest 如何手动分片数据库
数据库分片 (Database Sharding) 是一种将单个数据集分割成多个数据库的方法。 优点:高可用性、负载平衡、数据放置算法简单、易于拆分数据库以增加容量、易于定位数据
Pinterest 首次对数据库进行分片时,需要冻结新功能发布。在几个月的时间里,他们以渐进和手动的方式对数据库进行了分片:

团队删除了数据库层中的表 Join 和复杂查询。他们添加了大量缓存。
由于跨数据库维护唯一约束需要额外的工作,他们将用户名和电子邮件等数据保存在一个巨大的、未分片的数据库中。
这个数据库下的所有表都存在于所有分片中。
手动分片的一个小例子
由于他们有数十亿个 "pin",他们的数据库索引会耗尽内存。
他们会将数据库中最大的表转移到自己的数据库中。
然后,当数据库空间耗尽时,他们就会将其分片。
2012 年 10 月:2200 万用户,40 名工程师
2012 年 10 月,Pinterest 的月度用户约为 2200 万,但他们的工程团队却翻了两番,达到了 40 名工程师。
架构是一样的。他们只是增加了更多相同的系统。
- 亚马逊 EC2 + S3 + CDN(EdgeCast、Akamai、Level 3)
- 180 台 web servers + 240 个 API 引擎(使用 Flask)
- 88 个 MySQL DB + 88 个只读
- 110 个 Redis 实例
- 200 个 Memcache 实例
- 4 个 Redis 任务管理器 + 80 个任务处理器
- 分片式 Apache Solr

他们开始从 HDD 转向固态硬盘 SSD。
一个重要的教训是:有限的、经过验证的选择是件好事。
坚持使用 EC2 和 S3 意味着他们只有有限的配置可供选择,从而减少了麻烦,提高了简便性。
与此同时,新实例可以在几秒钟内准备就绪。这意味着他们可以在几分钟内添加 10 个 Memcache 实例。
Pinterest 的数据库结构 ID
和 Instagram 一样,Pinterest 也有一个独特的 ID 结构,因为他们有分片数据库。
他们的 64 位 ID 看起来像

分区 ID:哪个分区(16 位) 类型:对象类型,如针(10 位) 本地 ID:在表中的位置(38 位)
这些 ID 的查找结构是一个简单的 Python 字典。
数据库表
它们有对象表和映射表。
对象表适用于 pin、板块、评论、用户等。它们有一个映射到 MySQL blob(如 JSON)的本地 ID。
映射表用于对象之间的关系数据,如将板块映射到用户或将赞映射到 pin。它们有一个映射到完整 ID 和一个时间戳的完整 ID。
为了提高效率,所有查询都使用 PK(主键)或索引查找。他们删除了所有 JOIN。
译者语,Pinterest 高速发展的时期正好也出现了各种新数据库系统。尤其是 NoSQL 这块,除了 Pinterest 提到过的这些,还有 Riak, Tokyo Cabinet, Voldemort 等。 还是那句话,我们应该采用无聊的技术去构建创新的产品,而不是倒过来。
💡 更多资讯,请关注 Bytebase 公号:Bytebase