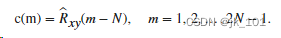流媒体学习之路(WebRTC)——GCC分析(4)
——
我正在的github给大家开发一个用于做实验的项目 —— github.com/qw225967/Bifrost
目标:可以让大家熟悉各类Qos能力、带宽估计能力,提供每个环节关键参数调节接口并实现一个json全配置,提供全面的可视化算法观察能力。
欢迎大家使用
——
文章目录
- 流媒体学习之路(WebRTC)——GCC分析(4)
- 一、间隔计算(InterArrival)
- 1.1 模块介绍
- 1.2 代码
- 二、码率控制(AimdRateControl)
- 2.1 背景
- 2.2 代码
- 三、总结
在讲具体内容之前插一句嘴,从GCC分析(3)开始,我们将针对GCC的实现细节去分析它设计的原理,让我们理解这些类存在的意义,不再带大家去串具体的流程了。
一、间隔计算(InterArrival)
1.1 模块介绍
WebRTC 的 InterArrival 类是用于计算包之间的到达时间差(Inter-Arrival Time)的类。 如果观察WebRTC的提交记录你会发现,这个类随着卡尔曼滤波器、趋势线等等算法的变更也一直在调整。那么为什么要存在这个接收间隔的计算类呢?

细心的小伙伴在观察我们发送视频数据的时候会发现,数据的发送是一股一股的——常常是一次发送几个包。
这是因为我们采集的数据帧大小是实时变化的每次可发送的数据量都不一样,而pacer发送是依赖于定时器去触发发送事件的,这样的触发模式有两种:周期模式(kPeriodic)、动态模式(kDynamic)——后来好像动态模式的代码被移除了,但是我们今天不是关注pacer的问题,而是补充一些小知识。
周期模式中,定时5ms会触发一次发送;
动态模式中,每次都会计算下一次触发发送的时间;
可以直观的理解为,当数据在接收端产生接收间隔增大时,这个间隔不仅仅是网络导致的,还有可能是发送时就已经造成了间隔增大。那么我们想把这个间隔计算出来也就需要发送端记录自己的发送时间了,InterArrival这个类就做这些变化的校准。
1.2 代码
该部分最重要的代码是在延迟估计IncomingPacketFeedback调用的,下面展示一部分伪代码
void DelayBasedBwe::IncomingPacketFeedback(const PacketResult& packet_feedback,
Timestamp at_time) {
...
uint32_t ts_delta = 0;
int64_t t_delta = 0;
int size_delta = 0;
// 校准接收间隔
bool calculated_deltas = inter_arrival_->ComputeDeltas(
timestamp, packet_feedback.receive_time.ms(), at_time.ms(),
packet_feedback.sent_packet.size.bytes(), &ts_delta, &t_delta,
&size_delta);
double ts_delta_ms = (1000.0 * ts_delta) / (1 << kInterArrivalShift);
// 把间隔放入检测器进行拥塞检测
delay_detector_->Update(t_delta, ts_delta_ms,
packet_feedback.sent_packet.send_time.ms(),
packet_feedback.receive_time.ms(), calculated_deltas);
}
ComputeDeltas里面细分了每个包组的概念,将包组的间隔区分出来保证我们计算的准确度:
bool InterArrival::ComputeDeltas(uint32_t timestamp, int64_t arrival_time_ms,
int64_t system_time_ms, size_t packet_size,
uint32_t* timestamp_delta,
int64_t* arrival_time_delta_ms,
int* packet_size_delta) {
// 传入参数:
// timestamp 数据发送的时间戳
// arrival_time_ms 对端接收到数据的时间戳
// system_time_ms 当前系统时间,其实是feedback接到的时间
// packet_size 当前数据包的大小
// 输出内容 —— timestamp_delta 发送间隔
// 输出内容 —— arrival_time_delta_ms 接收间隔
// 输出内容 —— packet_size_delta 两个包组直接包数量的差值
bool calculated_deltas = false;
// 第一个包组,记录信息
if (current_timestamp_group_.IsFirstPacket()) {
// We don't have enough data to update the filter, so we store it until we
// have two frames of data to process.
current_timestamp_group_.timestamp = timestamp;
current_timestamp_group_.first_timestamp = timestamp;
current_timestamp_group_.first_arrival_ms = arrival_time_ms;
// 连续包组返回
} else if (!PacketInOrder(timestamp, arrival_time_ms)) {
return false;
// 新包组开始计算间隔
} else if (NewTimestampGroup(arrival_time_ms, timestamp)) {
// First packet of a later frame, the previous frame sample is ready.
// 第一个包组不计算,后续包组开始计算
if (prev_timestamp_group_.complete_time_ms >= 0) {
// 记录包组之间的发送间隔
*timestamp_delta =
current_timestamp_group_.timestamp - prev_timestamp_group_.timestamp;
// 记录包组之间的接收间隔
*arrival_time_delta_ms = current_timestamp_group_.complete_time_ms -
prev_timestamp_group_.complete_time_ms;
// Check system time differences to see if we have an unproportional jump
// in arrival time. In that case reset the inter-arrival computations.
// 计算系统时间变化,防止系统时间跳变影响计算
int64_t system_time_delta_ms =
current_timestamp_group_.last_system_time_ms -
prev_timestamp_group_.last_system_time_ms;
if (*arrival_time_delta_ms - system_time_delta_ms >=
kArrivalTimeOffsetThresholdMs) {
Reset();
return false;
}
// 对端的接收时间戳可能已经生变化,影响计算
if (*arrival_time_delta_ms < 0) {
// The group of packets has been reordered since receiving its local
// arrival timestamp.
++num_consecutive_reordered_packets_;
if (num_consecutive_reordered_packets_ >= kReorderedResetThreshold) {
Reset();
}
return false;
} else {
num_consecutive_reordered_packets_ = 0;
}
// 计算两个包组的数据量差值
*packet_size_delta = static_cast<int>(current_timestamp_group_.size) -
static_cast<int>(prev_timestamp_group_.size);
calculated_deltas = true;
}
// 更新数据
prev_timestamp_group_ = current_timestamp_group_;
// The new timestamp is now the current frame.
current_timestamp_group_.first_timestamp = timestamp;
current_timestamp_group_.timestamp = timestamp;
current_timestamp_group_.first_arrival_ms = arrival_time_ms;
current_timestamp_group_.size = 0;
} else {
current_timestamp_group_.timestamp =
LatestTimestamp(current_timestamp_group_.timestamp, timestamp);
}
// Accumulate the frame size.
current_timestamp_group_.size += packet_size;
current_timestamp_group_.complete_time_ms = arrival_time_ms;
current_timestamp_group_.last_system_time_ms = system_time_ms;
return calculated_deltas;
}
bool InterArrival::PacketInOrder(uint32_t timestamp, int64_t arrival_time_ms) {
if (current_timestamp_group_.IsFirstPacket()) {
return true;
} else if (arrival_time_ms < 0) {
// NOTE: Change related to
// https://github.com/versatica/mediaproxy/issues/357
//
// Sometimes we do get negative arrival time, which causes BelongsToBurst()
// to fail, which may cause anything that uses InterArrival to crash.
//
// Credits to @sspanak and @Ivaka.
return false;
} else {
// Assume that a diff which is bigger than half the timestamp interval
// (32 bits) must be due to reordering. This code is almost identical to
// that in IsNewerTimestamp() in module_common_types.h.
uint32_t timestamp_diff =
timestamp - current_timestamp_group_.first_timestamp;
const static uint32_t int_middle = 0x80000000;
// 处理跳变
if (timestamp_diff == int_middle) {
return timestamp > current_timestamp_group_.first_timestamp;
}
return timestamp_diff < int_middle;
}
}
// Assumes that |timestamp| is not reordered compared to
// |current_timestamp_group_|.
bool InterArrival::NewTimestampGroup(int64_t arrival_time_ms,
uint32_t timestamp) const {
if (current_timestamp_group_.IsFirstPacket()) {
return false;
// 计算突发数据,确认突发数据直接返回
} else if (BelongsToBurst(arrival_time_ms, timestamp)) {
return false;
} else {
// 差值大于5ms就认为是下一个发送周期
uint32_t timestamp_diff =
timestamp - current_timestamp_group_.first_timestamp;
return timestamp_diff > kTimestampGroupLengthTicks;
}
}
bool InterArrival::BelongsToBurst(int64_t arrival_time_ms,
uint32_t timestamp) const {
if (!burst_grouping_) {
return false;
}
// 计算于上一个发送时间、接收时间的差值
int64_t arrival_time_delta_ms =
arrival_time_ms - current_timestamp_group_.complete_time_ms;
uint32_t timestamp_diff = timestamp - current_timestamp_group_.timestamp;
// 当发送间隔转为ms后差值在0.5浮动范围内
int64_t ts_delta_ms = timestamp_to_ms_coeff_ * timestamp_diff + 0.5;
if (ts_delta_ms == 0) return true;
// 一旦接收间隔比发送间隔加上浮动值0.5还小,证明这些包连续发送
int propagation_delta_ms = arrival_time_delta_ms - ts_delta_ms;
if (propagation_delta_ms < 0 && /* 连续发送 */
arrival_time_delta_ms <= kBurstDeltaThresholdMs && /* 处于同一发送周期 */
arrival_time_ms - current_timestamp_group_.first_arrival_ms <
kMaxBurstDurationMs) /* 最大异常值限制 */
return true;
return false;
}
经过该模块后就会进入TrendLine模块进行趋势计算,获得当前的拥塞情况。
二、码率控制(AimdRateControl)
2.1 背景
本系列文章GCC(3)提到了ack计算模块以及链路容量计算模块,事实上这两个模块在码率控制类中计算出了最终的码率。ack链路容量计算出完后输入到码率计算模块,码率区分上涨、下调、维持不变三种情况,他们所有的状态变化都取决于趋势线计算出来的状态。
状态机切换大家都很熟悉,就是下面这张图(来自于谷歌公开的Performance Analysis of Google Congestion Control Algorithm for WebRTC文章):

网络状态分为:
enum class BandwidthUsage {
// 网络正常
kBwNormal = 0,
// 网络过度使用
kBwUnderusing = 1,
// 网络正在排空
kBwOverusing = 2,
kLast
};
把趋势线的斜率图像化,可以看出来这几个状态在整个趋势计算的过程中是下图这样变化的:

之所以这样设计是因为,GCC思想希望保证整体的流畅性,整体非常敏感。码率下调很快,上涨则是比较缓慢的。状态上,随时可以进入overusing状态,但是上涨却不是立刻进行的,而是先转入hold状态再继续上探。
2.2 代码
这里展示一下代码中状态切换的代码:
void AimdRateControl::ChangeState(const RateControlInput& input,
Timestamp at_time) {
switch (input.bw_state) {
case BandwidthUsage::kBwNormal:
// 只有hold状态能进入码率上涨
if (rate_control_state_ == kRcHold) {
time_last_bitrate_change_ = at_time;
rate_control_state_ = kRcIncrease;
}
break;
case BandwidthUsage::kBwOverusing:
// 出现网络过度使用时下调码率
if (rate_control_state_ != kRcDecrease) {
rate_control_state_ = kRcDecrease;
}
break;
case BandwidthUsage::kBwUnderusing:
// 当网络开始排空时先转成hold状态
rate_control_state_ = kRcHold;
break;
default:
break;
}
}
码率计算:
DataRate AimdRateControl::ChangeBitrate(DataRate new_bitrate,
const RateControlInput& input,
Timestamp at_time) {
// 取出吞吐量估计值
DataRate estimated_throughput =
input.estimated_throughput.value_or(latest_estimated_throughput_);
if (input.estimated_throughput)
latest_estimated_throughput_ = *input.estimated_throughput;
// An over-use should always trigger us to reduce the bitrate, even though
// we have not yet established our first estimate. By acting on the over-use,
// we will end up with a valid estimate.
// 初始阶段,只要不是网络拥塞就不进行以下逻辑计算
if (!bitrate_is_initialized_ &&
input.bw_state != BandwidthUsage::kBwOverusing)
return current_bitrate_;
// 状态切换
ChangeState(input, at_time);
switch (rate_control_state_) {
// hold状态直接返回
case kRcHold:
break;
case kRcIncrease:
// 吞吐量估计大于了链路容量统计,则重置容量统计
if (estimated_throughput > link_capacity_.UpperBound())
link_capacity_.Reset();
// Do not increase the delay based estimate in alr since the estimator
// will not be able to get transport feedback necessary to detect if
// the new estimate is correct.
// alr状态下可以根据no_bitrate_increase_in_alr_决定是否继续进行码率增长
// 当alr状态下持续码率增长,一旦出现码率暴增发送码率就会爆发式增大
if (!(send_side_ && in_alr_ && no_bitrate_increase_in_alr_)) {
// 计算出链路容量则进入加性增,因为当前瓶颈已知
if (link_capacity_.has_estimate()) {
// The link_capacity estimate is reset if the measured throughput
// is too far from the estimate. We can therefore assume that our
// target rate is reasonably close to link capacity and use additive
// increase.
DataRate additive_increase =
AdditiveRateIncrease(at_time, time_last_bitrate_change_);
new_bitrate += additive_increase;
} else {
// If we don't have an estimate of the link capacity, use faster ramp
// up to discover the capacity.
// 未存在里哪路容量则需要乘性增去做探测
DataRate multiplicative_increase = MultiplicativeRateIncrease(
at_time, time_last_bitrate_change_, new_bitrate);
new_bitrate += multiplicative_increase;
}
}
time_last_bitrate_change_ = at_time;
break;
case kRcDecrease:
// TODO(srte): Remove when |estimate_bounded_backoff_| has been validated.
// 取当前链路容量的小值与吞吐量对比取大值,用于激进地下调码率
if (network_estimate_ && capacity_deviation_ratio_threshold_ &&
!estimate_bounded_backoff_) {
estimated_throughput = std::max(estimated_throughput,
network_estimate_->link_capacity_lower);
}
if (estimated_throughput > low_throughput_threshold_) {
// Set bit rate to something slightly lower than the measured throughput
// to get rid of any self-induced delay.
// 新的码率需要略低于吞吐量,避免引入新的排队导致延迟
new_bitrate = estimated_throughput * beta_;
if (new_bitrate > current_bitrate_) {
// Avoid increasing the rate when over-using.
// 当此时新的码率仍然高于当前码率,则根据链路容量重新设置新码率
if (link_capacity_.has_estimate()) {
new_bitrate = beta_ * link_capacity_.estimate();
}
}
// estimate_bounded_backoff_ 称为边界避退,目的是标记在链路容量下限高于当前容量时,使用链路容量下限
if (estimate_bounded_backoff_ && network_estimate_) {
new_bitrate = std::max(
new_bitrate, network_estimate_->link_capacity_lower * beta_);
}
} else {
// 吞吐量小于低吞吐的阈值,则直接使用吞吐量
new_bitrate = estimated_throughput;
// 已经估计出带宽则取吞吐量、带宽的最大值
if (link_capacity_.has_estimate()) {
new_bitrate = std::max(new_bitrate, link_capacity_.estimate());
}
// 超过吞吐阈值都使用阈值
new_bitrate = std::min(new_bitrate, low_throughput_threshold_.Get());
}
// 如果当前码率已经很小,则继续使用当前码率
new_bitrate = std::min(new_bitrate, current_bitrate_);
if (bitrate_is_initialized_ && estimated_throughput < current_bitrate_) {
// 有可能存在过度下降码率的情况,一旦超过下降的90%,则不使用该码率
constexpr double kDegradationFactor = 0.9;
if (smoothing_experiment_ &&
new_bitrate < kDegradationFactor * beta_ * current_bitrate_) {
// If bitrate decreases more than a normal back off after overuse, it
// indicates a real network degradation. We do not let such a decrease
// to determine the bandwidth estimation period.
last_decrease_ = absl::nullopt;
} else {
// 记录该下降的码率
last_decrease_ = current_bitrate_ - new_bitrate;
}
}
if (estimated_throughput < link_capacity_.LowerBound()) {
// The current throughput is far from the estimated link capacity. Clear
// the estimate to allow an immediate update in OnOveruseDetected.
link_capacity_.Reset();
}
// 更新状态记录
bitrate_is_initialized_ = true;
link_capacity_.OnOveruseDetected(estimated_throughput);
// Stay on hold until the pipes are cleared.
rate_control_state_ = kRcHold;
time_last_bitrate_change_ = at_time;
time_last_bitrate_decrease_ = at_time;
break;
default:
break;
}
// 选择码率
return ClampBitrate(new_bitrate, estimated_throughput);
}
DataRate AimdRateControl::ClampBitrate(DataRate new_bitrate,
DataRate estimated_throughput) const {
// Allow the estimate to increase as long as alr is not detected to ensure
// that there is no BWE values that can make the estimate stuck at a too
// low bitrate. If an encoder can not produce the bitrate necessary to
// fully use the capacity, alr will sooner or later trigger.
if (!(send_side_ && no_bitrate_increase_in_alr_)) {
// Don't change the bit rate if the send side is too far off.
// We allow a bit more lag at very low rates to not too easily get stuck if
// the encoder produces uneven outputs.
// 每次上涨有一个最大的上涨限度,1.5 * 吞吐量 + 10kbps,避免超出吞吐量上涨过多
const DataRate max_bitrate =
1.5 * estimated_throughput + DataRate::kbps(10);
if (new_bitrate > current_bitrate_ && new_bitrate > max_bitrate) {
new_bitrate = std::max(current_bitrate_, max_bitrate);
}
}
if (network_estimate_ &&
(estimate_bounded_increase_ || capacity_limit_deviation_factor_)) {
DataRate upper_bound = network_estimate_->link_capacity_upper;
new_bitrate = std::min(new_bitrate, upper_bound);
}
new_bitrate = std::max(new_bitrate, min_configured_bitrate_);
return new_bitrate;
}
DataRate AimdRateControl::MultiplicativeRateIncrease(
Timestamp at_time, Timestamp last_time, DataRate current_bitrate) const {
// 1.08这个参数与丢包估计的上涨参数一样
double alpha = 1.08;
if (last_time.IsFinite()) {
auto time_since_last_update = at_time - last_time;
alpha = pow(alpha, std::min(time_since_last_update.seconds<double>(), 1.0));
}
DataRate multiplicative_increase =
std::max(current_bitrate * (alpha - 1.0), DataRate::bps(1000));
return multiplicative_increase;
}
DataRate AimdRateControl::AdditiveRateIncrease(Timestamp at_time,
Timestamp last_time) const {
double time_period_seconds = (at_time - last_time).seconds<double>();
double data_rate_increase_bps =
GetNearMaxIncreaseRateBpsPerSecond() * time_period_seconds;
return DataRate::bps(data_rate_increase_bps);
}
double AimdRateControl::GetNearMaxIncreaseRateBpsPerSecond() const {
// RTC_DCHECK(!current_bitrate_.IsZero());
// 加性增以固定的15帧换算帧间隔,最终根据帧间隔计算出一个大致的平均包大小
const TimeDelta kFrameInterval = TimeDelta::seconds(1) / 15;
DataSize frame_size = current_bitrate_ * kFrameInterval;
const DataSize kPacketSize = DataSize::bytes(1200);
double packets_per_frame = std::ceil(frame_size / kPacketSize);
DataSize avg_packet_size = frame_size / packets_per_frame;
// Approximate the over-use estimator delay to 100 ms.
// 使用平均包大小换算出每个计算周期的增长值,最大为4kbps
TimeDelta response_time = rtt_ + TimeDelta::ms(100);
if (in_experiment_) response_time = response_time * 2;
double increase_rate_bps_per_second =
(avg_packet_size / response_time).bps<double>();
double kMinIncreaseRateBpsPerSecond = 4000;
return std::max(kMinIncreaseRateBpsPerSecond, increase_rate_bps_per_second);
}
三、总结
本文接着前面提到的码率控制,讲述了计算包组间隔的类,该类用于校准发送间隔在周期发送中的误差。后续接着上一篇GCC介绍讲了经过ack模块后,码率是怎么计算出来的。在什么情况下它会上涨?什么情况下会下跌?并且结合状态机图给大家分析了GCC上涨和下降的规律,发现它是个激进下降,缓慢上涨的拥塞控制算法。这样做的好处是:可以尽最大能力保证播放的流畅度,提高交互能力避免微小的拥塞导致卡顿。