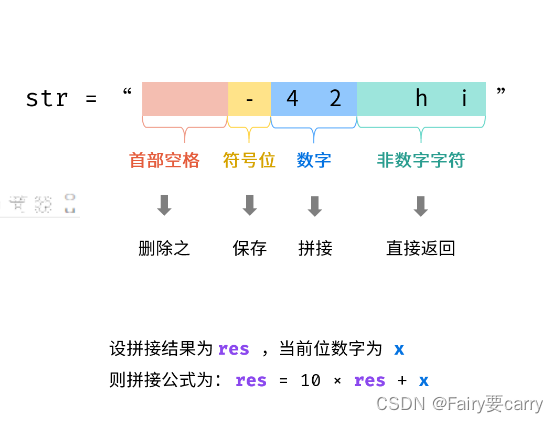
大家好,我是带我去滑雪,每天教你一个小技巧!
房价数据集通常包含各种各样的特征,如房屋面积、地理位置、建造年份等。通过对数据进行处理和分析,可以更好地理解这些特征之间的关系,以及它们对房价的影响程度。这有助于确定哪些特征是最重要的,从而更有针对性地制定房地产策略。本次使用波士顿房价数据集boston_housing_data.csv,该数据集有城镇人均犯罪率(CRIM)、住宅用地所占比例(ZN)、城镇中非住宅用地所占比例(INDUS)等共计13个特征变量,响应变量为社区房价中位数(MEDV)。实现对房价数据进行可视化和统计分析:如绘制直方图、密度图、箱线图以及查看各个散点图的分布,最后使用支持向量机和KNN等几种机器学习方法进行学习。下面开始实战。
(1)导入相关模块
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from numpy import arange
from matplotlib import pyplot
from pandas import read_csv
from pandas import set_option
from pandas.plotting import scatter_matrix
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_predict
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import GridSearchCV
from sklearn.linear_model import LinearRegression
from sklearn.linear_model import Lasso
from sklearn.linear_model import ElasticNet
from sklearn.tree import DecisionTreeRegressor
from sklearn.neighbors import KNeighborsRegressor
from sklearn.svm import SVR
from sklearn.pipeline import Pipeline
from sklearn.ensemble import RandomForestRegressor
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.ensemble import ExtraTreesRegressor
from sklearn.ensemble import AdaBoostRegressor
from sklearn.metrics import mean_squared_error
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import f_regression(2)导入数据并进行可视化分析
def testHouse():
data = pd.read_csv("house_data.csv")
set_option('display.column_space', 120)
print(data.shape)
print(data.isnull().any().sum())
prices = data['MEDV']
features = data.drop('MEDV', axis=1)
# 直方图
data.hist(sharex=False, sharey=False, xlabelsize=1, ylabelsize=1)
pyplot.show()
# 密度图
data.plot(kind='density', subplots=True, layout=(4, 4), sharex=False, fontsize=1)
pyplot.show()
# 箱线图
data.plot(kind='box', subplots=True, layout=(4, 4), sharex=False, sharey=False, fontsize=8)
pyplot.show()
# 查看各个特征的散点分布
scatter_matrix(data, alpha=0.7, figsize=(10, 10), diagonal='kde')
pyplot.show()
# Heatmap
testHouse()结果展示:
绘制房价数据的直方图:
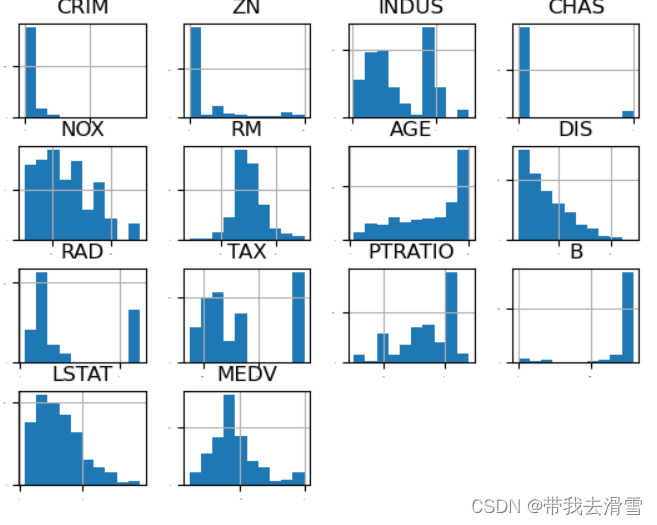
绘制房价数据的密度图:

绘制 房价数据的箱线图:

查看房价数据各个特征的散点分布:

(3)使用支持向量机和KNN等机器学习方法学习
def featureSelection():
data = pd.read_csv("house_data.csv")
x = data[['CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD', 'TAX',
'PTRATIO', 'B', 'LSTAT']]
# print(x.head())
y = data['MEDV']
from sklearn.feature_selection import SelectKBest
SelectKBest = SelectKBest(f_regression, k=3)
bestFeature = SelectKBest.fit_transform(x, y)
SelectKBest.get_support(indices=False)
# print(SelectKBest.transform(x))
print(x.columns[SelectKBest.get_support(indices=False)])
features = data[['RM', 'PTRATIO', 'LSTAT']].copy()
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
for feature in features.columns:
features.loc[:, '标准化' + feature] = scaler.fit_transform(features[[feature]])
# 散点可视化,查看特征归一化后的数据
font = {
'family': 'SimHei'
}
x_train, x_test, y_train, y_test = train_test_split(features[['标准化RM', '标准化PTRATIO', '标准化LSTAT']], y,
test_size=0.3, random_state=33)
import warnings
warnings.filterwarnings(action="ignore", module="scipy", message="^internal gelsd") #过滤告警
lr = LinearRegression()
lr_predict = cross_val_predict(lr, x_train, y_train, cv=5)
lr_score = cross_val_score(lr, x_train, y_train, cv=5)
lr_meanscore = lr_score.mean()
#SVR
from sklearn.svm import SVR
linear_svr = SVR(kernel = 'linear')
linear_svr_predict = cross_val_predict(linear_svr, x_train, y_train, cv=5)
linear_svr_score = cross_val_score(linear_svr, x_train, y_train, cv=5)
linear_svr_meanscore = linear_svr_score.mean()
poly_svr = SVR(kernel = 'poly')
poly_svr_predict = cross_val_predict(poly_svr, x_train, y_train, cv=5)
poly_svr_score = cross_val_score(poly_svr, x_train, y_train, cv=5)
poly_svr_meanscore = poly_svr_score.mean()
rbf_svr = SVR(kernel = 'rbf')
rbf_svr_predict = cross_val_predict(rbf_svr, x_train, y_train, cv=5)
rbf_svr_score = cross_val_score(rbf_svr, x_train, y_train, cv=5)
rbf_svr_meanscore = rbf_svr_score.mean()
knn = KNeighborsRegressor(2, weights='uniform')
knn_predict = cross_val_predict(knn, x_train, y_train, cv=5)
knn_score = cross_val_score(knn, x_train, y_train, cv=5)
knn_meanscore = knn_score.mean()
dtr = DecisionTreeRegressor(max_depth=4)
dtr_predict = cross_val_predict(dtr, x_train, y_train, cv=5)
dtr_score = cross_val_score(dtr, x_train, y_train, cv=5)
dtr_meanscore = dtr_score.mean()
evaluating = {
'lr': lr_score,
'linear_svr': linear_svr_score,
'poly_svr': poly_svr_score,
'rbf_svr': rbf_svr_score,
'knn': knn_score,
'dtr': dtr_score
}
evaluating = pd.DataFrame(evaluating)
print(evaluating)
def main():
if __name__ == "__main__":
main()输出结果:
Index(['RM', 'PTRATIO', 'LSTAT'], dtype='object')
lr linear_svr poly_svr rbf_svr knn dtr
0 0.738899 0.632970 0.866308 0.758355 0.806363 0.787402
1 0.755418 0.618558 0.865458 0.772783 0.888141 0.871562
2 0.433104 0.386320 0.569238 0.529242 0.590950 0.545247
3 0.604445 0.554785 0.723299 0.740388 0.728388 0.583349
4 0.793609 0.611882 0.805474 0.736040 0.863620 0.824755
需要数据集的家人们可以去百度网盘(永久有效)获取:
链接:https://pan.baidu.com/s/173deLlgLYUz789M3KHYw-Q?pwd=0ly6
提取码:2138
更多优质内容持续发布中,请移步主页查看。
若有问题可邮箱联系:1736732074@qq.com
博主的WeChat:TCB1736732074
点赞+关注,下次不迷路!







![达梦数据库报错 执行失败(语句1) -2111: 第1 行附近出现错误: 无效的列名[system]](https://img-blog.csdnimg.cn/direct/ac26cb0770b34e6980b8e6e131c202c1.png)