文章目录
- 一、 约束
- 1、 主键
- 2、 非空
- 3、唯一
- 4、检查
- 5、外键
- 6、默认值
- 二、触发器
- 1、构建表信息,填充数据
- 2、触发器函数
- 3、触发器
- 三、 表空间
- 四、 视图
- 五、索引
- 1、 索引的基本概念
- 2、索引的分类
- 3、创建索引
- 六、 物化视图
一、 约束
1、 主键
primary key
-- 主键约束
drop table test;
create table test(
id bigserial primary key,
name varchar(32)
);
2、 非空
not null,基本都要,避免全表扫描
-- 非空约束
drop table test;
create table test(
id bigserial primary key ,
name varchar(32) not null
);
3、唯一
unique
drop table test;
create table test(
id bigserial primary key ,
id_card varchar(32) unique
);
4、检查
check
drop table test;
create table test(
id bigserial primary key,
price numeric check(price > 0),
discount_price numeric check(discount_price > 0),
check(price >= discount_price)
);
5、外键
基本不用
6、默认值
default
-- 默认值
create table test(
id bigserial primary key,
created timestamp default current_timestamp
);
二、触发器
触发器Trigger,是由事件触发的一种存储过程。
创建时指定的事件(insert,update,delete,truncate表),当对表进行相关操作时,会触发表的Trigger。
案例:学生信息表,学生分数表,在删除学生信息的同时,自动删除学生的分数。
1、构建表信息,填充数据
create table student(
id int,
name varchar(32)
);
create table score(
id int,
student_id int,
math_score numeric,
english_score numeric,
chinese_score numeric
);
INSERT INTO student (id,name) values (1,'张三');
INSERT INTO student (id,name) values (2,'李四');
INSERT INTO score ( ID, student_id, math_score, english_score, chinese_score )
VALUES( 1, 1, 66, 66, 66 );
INSERT INTO score ( ID, student_id, math_score, english_score, chinese_score )
VALUES( 2, 2, 55, 55, 55 );
2、触发器函数
PostgreSQL的plsql语法
[ <<label>> ]
[ DECLARE
declarations ]
BEGIN
statements
END [ label ];
触发器函数的一些特殊变量
NEW,数据类型是RECORD。该变量为行级触发器中的INSERT/UPDATE操作保持新数据行。在语句级别的触发器以及DELETE操作,这个变量是null。
OLD,数据类型是RECORD。该变量为行级触发器中的UPDATE/DELETE操作保持新数据行。在语句级别的触发器以及INSERT操作,这个变量是null。
构建一个删除学生分数的触发器函数
-- $$可以理解为是一种特殊的单引号,避免你在declare,begin,end中使用单引号时,出现问题,
-- 需要在编写后,在$$之后添加上当前内容的语言。
create function trigger_function_delete_student_score() returns trigger as $$
begin
delete from score where student_id = old.id;
return old;
end;
$$ language plpgsql;
3、触发器
开始构建触发器,在学生信息表删除时,执行前面声明的触发器函数
CREATE [ OR REPLACE ] [ CONSTRAINT ] TRIGGER name { BEFORE | AFTER | INSTEAD OF } { event [ OR ... ] }
ON table_name
[ FROM referenced_table_name ]
[ NOT DEFERRABLE | [ DEFERRABLE ] [ INITIALLY IMMEDIATE | INITIALLY DEFERRED ] ]
[ REFERENCING { { OLD | NEW } TABLE [ AS ] transition_relation_name } [ ... ] ]
[ FOR [ EACH ] { ROW | STATEMENT } ]
[ WHEN ( condition ) ]
EXECUTE { FUNCTION | PROCEDURE } function_name ( arguments )
where event can be one of:
INSERT
UPDATE [ OF column_name [, ... ] ]
DELETE
TRUNCATE
当
CONSTRAINT选项被指定,这个命令会创建一个 约束触发器 。这和一个常规触发器相同,不过触发该触发器的时机可以使用SET CONSTRAINTS调整。约束触发器必须是表上的AFTER ROW触发器。它们可以在导致触发器事件的语句末尾被引发或者在包含该语句的事务末尾被引发。在后一种情况中,它们被称作是被 延迟 。一个待处理的延迟触发器的引发也可以使用SET CONSTRAINTS立即强制发生。当约束触发器实现的约束被违背时,约束触发器应该抛出一个异常。
编写触发器,指定在删除某一行学生信息时,触发当前触发器,执行触发器函数
create trigger trigger_student
after
delete
on student
for each row
execute function trigger_function_delete_student_score();
测试效果
select * from student;
select * from score;
delete from student where id = 1;
三、 表空间
在存储数据时,数据肯定要落到磁盘上,基于构建的tablespace,指定了数据存放在磁盘上的物理地址。
如果没有自己设计tablespace,PostgreSQL会自动指定一个位置作为默认的存储点。
查询表存储的物理地址
select pg_relation_filepath('student');
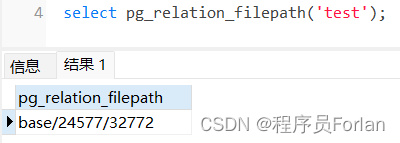
上面这个地址是$PG_DATA下的地址,不太好管理,后面需要自己指定。32772其实就是存储数据的物理文件。
$PG_DATA == /var/lib/pgsql/12/data/
构建表空间,指定数据存放位置
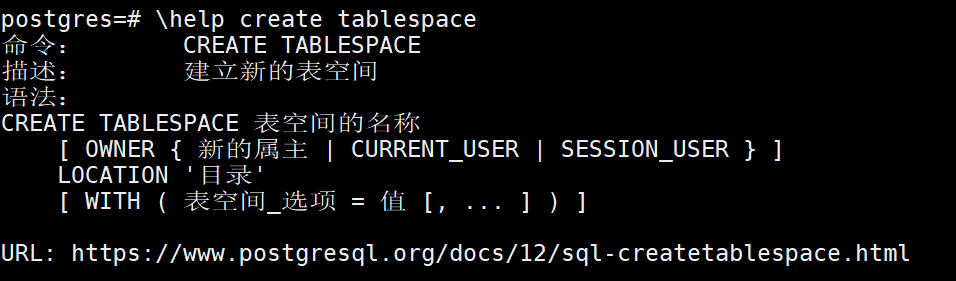
构建表空间,构建表空间需要用户权限是超级管理员,其次需要指定的目录已经存在
create tablespace tp_test location '/var/lib/pgsql/12/tp_test';

构建数据库,以及表,指定到这个表空间中
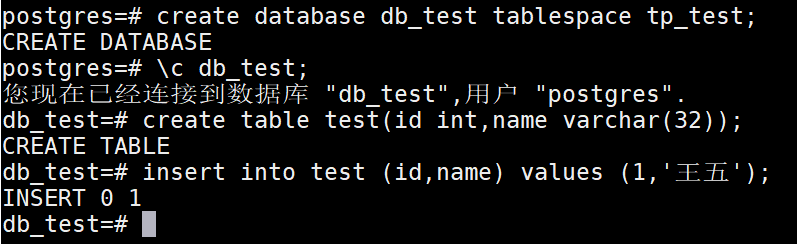
指定表空间的存储位置后,PGSQL会在$PG_DATA目录下存储一份,同时在咱们构建tablespace时,指定的路径下也存储一份。
这两个绝对路径下的文件都有存储表中的数据信息。
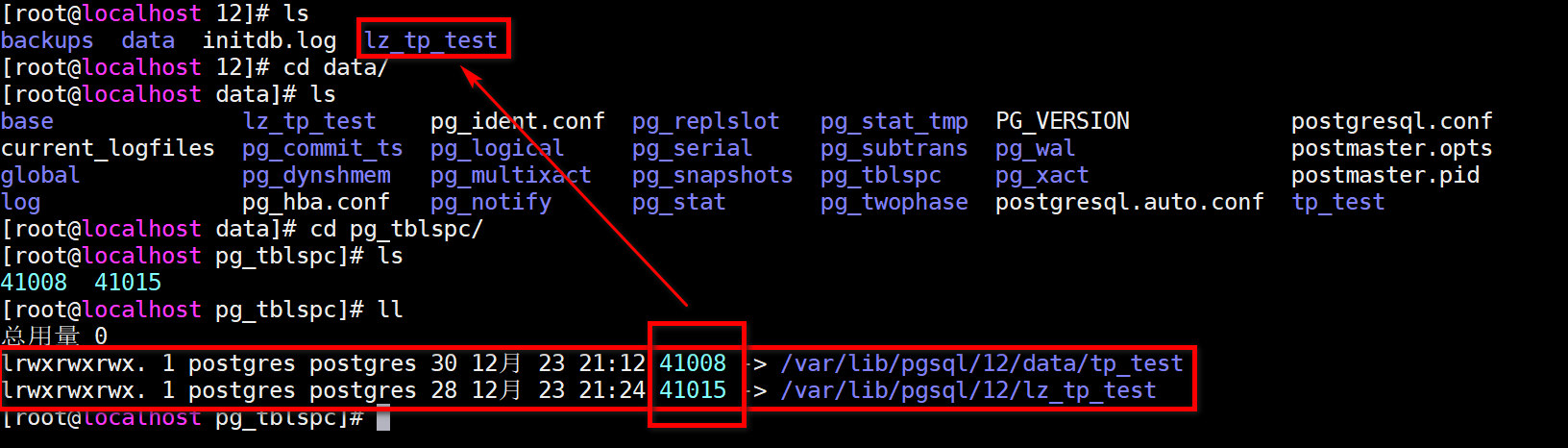
/var/lib/pgsql/12/data/pg_tblspc/41015/PG_12_201909212/41016/41020
/var/lib/pgsql/12/lz_tp_test/PG_12_201909212/41016/41020
细心发现,其实在PostgreSQL的默认目录下,存储的是一个link,连接文件,类似一个快捷方式
四、 视图
跟MySQL的没啥区别,把一些复杂的操作封装起来,还可以隐藏一些敏感数据。
视图对于用户来说,就是一张真实的表,可以直接基于视图查询一张或者多张表的信息。
视图对于开发来说,就是一条SQL语句。
在PGSQL中,简单(单表)视图是允许写操作的。但强烈不推荐对视图进行写操作,虽然PGSQL默认允许(简单视图),因为写入的时候,其实修改的是表本身。
简单视图
create view vw_score as (select id,math_score from score);
复杂视图(多表视图)
-- 复杂视图(两张表关联)
create view vw_student_score as
(select stu.id as id ,stu.name as name ,score.math_score from student stu,score score where stu.id = score.student_id);
五、索引
1、 索引的基本概念
索引是数据库中快速查询数据的方法。
索引能提升查询效率的同时,也会带来一些问题
- 增加了存储空间
- 写操作时,花费的时间比较多
索引可以提升效率,甚至还可以给字段做一些约束
2、索引的分类
B-Tree索引:最常用的索引。
Hash索引:跟MySQL类似,做等值判断,范围不支持。
GIN索引:针对字段的多个值的类型,比如数组类型。
3、创建索引
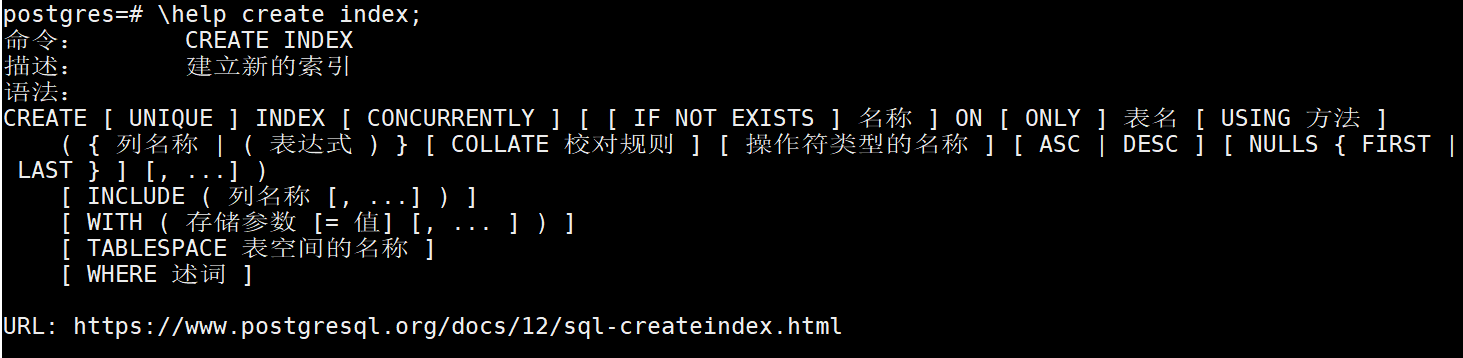
准备测试数据
create table tb_index(
id bigserial primary key,
name varchar(64),
phone varchar(64)[]
);
-- 添加300W条数据测试效果
do $$
declare
i int := 0;
begin
while i < 3000000 loop
i = i + 1;
insert into
tb_index
(name,phone)
values
(md5(random()::text || current_timestamp::text)::uuid,array[random()::varchar(64),random()::varchar(64)]);
end loop;
end;
$$ language plpgsql;
在没有索引的情况下,先基于name做等值查询,时间0.3秒左右,同时看执行计划,Seq Scan 这个代表全表扫描
select * from tb_index where name = 'c0064192-1836-b019-c649-b368c2be31ca';
explain select * from tb_index where name = 'c0064192-1836-b019-c649-b368c2be31ca';
在有索引的情况下,再基于name做等值查询,时间 0.1s左右,同时看执行计划,Index Scan 使用索引
-- name字段构建索引(默认就是b-tree)
create index index_tb_index_name on tb_index(name);
-- 测试效果
select * from tb_index where name = 'c0064192-1836-b019-c649-b368c2be31ca';
explain select * from tb_index where name = 'c0064192-1836-b019-c649-b368c2be31ca';
测试GIN索引效果
在没有索引的情况下,基于phone字段做包含查询,查询时间0.5s左右,同时看执行计划,Seq Scan 全表扫描
-- phone:{0.6925242730781953,0.8569644964711074}
select * from tb_index where phone @> array['0.6925242730781953'::varchar(64)];
explain select * from tb_index where phone @> array['0.6925242730781953'::varchar(64)];
给phone字段构建GIN索引,查询时间0.1s以内,同时看执行计划,Bitmap Index 位图扫描
-- 给phone字符串数组类型字段构建一个GIN索引
create index index_tb_index_phone_gin on tb_index using gin(phone);
select * from tb_index where phone @> array['0.6925242730781953'::varchar(64)];
explain select * from tb_index where phone @> array['0.6925242730781953'::varchar(64)];
六、 物化视图
物化视图从名字上就可以看出来,必然是要持久化一份数据的。使用套路和视图基本一致。查询物化视图,就相当于查询一张单独的表。相比之前的普通视图,物化视图就不需要每次都查询复杂SQL,每次查询的都是真实的物理存储地址中的一份数据(表)。
物化视图因为会持久化到本地,完全脱离原来的表结构,而且物化视图是可以单独设置索引等信息来提升物化视图的查询效率。
坏处:更新时间不太好把控。 如果更新频繁,对数据库压力也不小。 如果更新不频繁,会造成数据存在延迟问题,实时性就不好了。
如果要更新物化视图,可以采用触发器的形式,当原表中的数据被写后,可以通过触发器执行同步物化视图的操作。或者就基于定时任务去完成物化视图的数据同步。
语法

构建物化视图
create materialized view mv_test as (select id,name,price from test);
操作物化视图和操作表的方式没啥区别,操作原表时,对物化视图没任何影响。
select * from mv_test;
不允许写物化视图,物化视图如何从原表中进行同步操作。
PostgreSQL中,对物化视图的同步,提供了两种方式,一种是全量更新,另一种是增量更新。
全量更新语法,没什么限制,直接执行,全量更新
-- 查询原来物化视图的数据
select * from mv_test;
-- 全量更新物化视图
refresh materialized view mv_test;
-- 再次查询物化视图的数据
select * from mv_test;
增量更新,增量更新需要一个唯一标识,来判断哪些是增量,同时也会有行数据的版本号约束。
-- 查询原来物化视图的数据
select * from mv_test;
-- 增量更新物化视图,因为物化视图没有唯一索引,无法判断出哪些是增量数据
refresh materialized view concurrently mv_test;
-- 给物化视图添加唯一索引。
create unique index index_mv_test on mv_test(id);
-- 增量更新物化视图
refresh materialized view concurrently mv_test;
-- 再次查询物化视图的数据
select * from mv_test;










![python调用openai api报错self._sslobj.do_handshake()OSError: [Errno 0] Error](https://img-blog.csdnimg.cn/direct/edd1e8c626554ae09829c83f4874e811.png#pic_center)