目录
什么是 Direct IO
java 支持
使用场景
数据库
反思
在之前的文章零拷贝基础上,有一个针对那些不需要在操作系统的 page cache 里保存的情况,即绕过 page cache,对于 linux 提供了 direct io 的功能。
https://blog.csdn.net/zlpzlpzyd/article/details/135317834
什么是 Direct IO
Direct IO也叫无缓冲IO,裸IO(rawIO),意思是使用无缓冲IO对文件进行读写,不会经过page cache。
通常,我们使用的文件流读取、内存映射都属于 Cache IO,因为将数据写入文件,首先会写入cache,最终再落盘到 IO device 或者称为 disk上。
cache IO 使得我们在写入、读取(预读取、顺序读取等特性)文件数据的时候,性能得以提升,能够从cache(内存)中读取数据。
直接 IO,则是直接将数据写入文件、或者从文件中读取出来,绕过了cache,这使得看起来性能没那么好,但是,仔细分析,无论哪种IO方式,最终数据都必须落盘,而两种的区别在于有无 page cache。
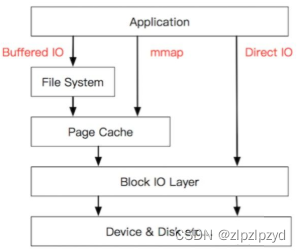
参照图片,即是直接走最后的红色方式,直接访问操作系统的 block io layer 来实现 direct io。
这样的话针对那种不经常使用的文件尤其是大文件可以使用这种方式来处理了。
那 java 里是否提供了这个功能?在网上搜了一下,发现了如下
https://bugs.openjdk.org/browse/JDK-8189192
从 jdk 10 开始原生支持
java 支持
主要添加了3个地方
java.nio.file.FileStore
/**
* Returns the number of bytes per block in this file store.
*
* <p> File storage is typically organized into discrete sequences of bytes
* called <i>blocks</i>. A block is the smallest storage unit of a file store.
* Every read and write operation is performed on a multiple of blocks.
*
* @implSpec The implementation in this class throws
* {@code UnsupportedOperationException}.
*
* @return a positive value representing the block size of this file store,
* in bytes
*
* @throws IOException
* if an I/O error occurs
*
* @throws UnsupportedOperationException
* if the operation is not supported
*
* @since 10
*/
public long getBlockSize() throws IOException {
throw new UnsupportedOperationException();
}com.sun.nio.file.ExtendedOpenOption
/**
* Requires that direct I/O be used for read or write access.
* Attempting to open a file with this option set will result in
* an {@code UnsupportedOperationException} if the operating system or
* file system does not support Direct I/O or a sufficient equivalent.
*
* @apiNote
* The DIRECT option enables performing file I/O directly between user
* buffers and the file thereby circumventing the operating system page
* cache and possibly avoiding the thrashing which could otherwise occur
* in I/O-intensive applications. This option may be of benefit to
* applications which do their own caching or do random I/O operations
* on large data sets. It is likely to provide the most benefit when
* the file is stored on a device which has high I/O throughput capacity.
* The option should be used with caution however as in general it is
* likely to degrade performance. The performance effects of using it
* should be evaluated in each particular circumstance.
*
* @since 10
*/
DIRECT(FileSystemOption.DIRECT);ByteBuffer#alignedSlice
从 java 9 开始支持
Path p; // initialization omitted
int blockSize = Math.toIntExact(Files.getFileStore(p).getBlockSize());
int capacity = Math.addExact(blockSize, blockSize - 1);
ByteBuffer block = ByteBuffer.allocateDirect(capacity).alignedSlice(blockSize);
try (FileChannel fc = FileChannel.open(p, StandardOpenOption.READ, ExtendedOpenOption.DIRECT)) {
int result = fc.read(block);
}使用场景
针对那种不经常使用的文件尤其是大文件可以使用 direct io 来处理了。
数据库
mysql 的 innodb 引擎就用了这个,绕过 page cache
https://dev.mysql.com/doc/refman/8.0/en/innodb-parameters.html#sysvar_innodb_flush_method
反思
让我想到了一点,很多功能底层支持,但是工具里没有,最终还是看 cpu 层次(指令集)和操作系统的 api 是否支持。例如 java 的很多功能之前不支持,后面底层支持了在 java 里也提供了对应的 api 间接使用这些底层功能。让我想到了虚拟线程的问题,在 alibaba 自研的 dragonwell jdk 之前的 jdk 里不支持,开发人员就改写了 jvm 的源码从底层上支持虚拟线程。
美团自研的 mjdk 针对现有的 java.util.zip.* 中使用的底层 zlib 改写使用 Intel 开源的 ISA-L 进行改造优化
https://mp.weixin.qq.com/s/etzzmbOsAzzLU13BsrXxTA
鉴于 java 的使用人员多,市场份额大,现在不像之前更新那么快了。对于底层 api 的支持也没有那么快了,自己要想使用那些底层操作系统的功能,需要自己编写 api 后面打包到 jdk 里去,通过 java api 来间接调用操作系统的 api,这样可以从 jdk 层面来支持这些底层的功能。
参考链接
https://blog.csdn.net/alex_xfboy/article/details/91865675
https://blog.csdn.net/weixin_39971435/article/details/114475097
https://blog.csdn.net/rekingman/article/details/109037276