本文已收录至Github,推荐阅读 👉 Java随想录
微信公众号:Java随想录
文章目录
- Mapping 的基本概念
- 查看索引 Mapping
- 字段数据类型
- 数字类型
- 基本数据类型
- Keywords 类型
- 日期类型
- 对象类型
- 空间数据类型
- 文档排名类型
- 文本搜索类型
- 两种映射类型
- 自动映射:Dynamic Field Mapping
- 显式映射:Expllcit Field Mapping
- 映射参数
- Text & Keyword
- Text
- Keyword
- 映射模板
- 参数
- 案例
本篇讲解Elasticsearch中非常重要的一个概念: Mapping,Mapping是索引必不可少的组成部分。
Mapping 的基本概念
Mapping 也称之为映射,定义了 ES 的索引结构、字段类型、分词器等属性,是索引必不可少的组成部分
ES 中的 Mapping 有点类似于关系型数据库中“表结构”的概念,在 MySQL 中,表结构里包含了字段名称,字段的类型还有索引信息等。在 Mapping 里也包含了一些属性,比如字段名称、类型、字段使用的分词器、是否评分、是否创建索引等属性。
查看索引 Mapping
//查看索引完整的mapping
GET /my_index/_mappings
//查看索引指定字段的mapping
GET /my_index/_mappings/field/field_name
例如,如果你有一个名为 “my_index” 的索引,并且你想查询字段 “my_field” 的 mapping,那么请求就像这样:
GET /my_index/_mapping/field/my_field
此请求会返回如下类型的输出:
{
"my_index" : {
"mappings" : {
"my_field" : {
"full_name" : "my_field",
"mapping" : {
"my_field" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
}
}
}
}
在这个响应中,你可以看到 “my_field” 是 “text” 类型,并且它也有一个子字段 “keyword”。
字段数据类型
映射的数据类型也就是 ES 索引支持的数据类型,其概念和 MySQL 中的字段类型相似,但是具体的类型和 MySQL 中有所区别,最主要的区别就在于 ES 中支持可分词的数据类型,如:Text 类型,可分词类型是用以支持全文检索的,这也是 ES 生态最核心的功能。
数字类型
- long:64 位有符号整形。
- integer:32 位有符号整形。
- short:16 位有符号整形。
- byte:8位有符号整形。
- double:双精度64位浮点类型。
- float:单精度32位浮点类型。
- half_float:半精度16位浮点数。
- scaled_float:缩放类型浮点数,按固定 double 比例因子缩放。
- unsigned_long:无符号 64 位整数。
基本数据类型
- binary:存储二进制字符串,经过Base64编码处理。
- boolean:布尔类型,接收 ture 和 false 两个值。
Keywords 类型
- keyword:这种类型被用来索引结构化数据,如 email 地址、主机名、状态码以及标签等。这类数据可以以精确值的形式进行搜索,并且可以用于过滤 (filtering),排序 (sorting) 和聚合 (aggregating)。关键词字段只和其确切的值匹配,它们的查询不会进行分词处理。
- constant_keyword:这种类型适用于在所有文档中都始终有相同值的字段。比如在一次特定的索引操作中,所有的文档都需要包含一个常量字段,例如
env的值可能为 “production”。 - wildcard:这种类型的字段可以存储任何字符串,并且对于这种类型的字段进行的查询可以使用通配符表达式。这种类型的字段对于像 grep 这样的场景非常有用,即当你需要在一个长字符串中搜索一个较短的子串时。但是要注意,虽然 wildcard 字段提供了强大的模式匹配能力,但是这种能力是需要付出性能代价的。
日期类型
JSON 没有日期数据类型,因此 Elasticsearch 中的日期可以是以下三种:
- 包含格式化日期的字符串:例如 “2015-01-01”、 “2015/01/01 12:10:30”。
- 时间戳:表示自"1970年 1 月 1 日"以来的毫秒数/秒数。
- date_nanos:此数据类型是对 date 类型的补充。但是有一个重要区别。date 类型存储最高精度为毫秒,而date_nanos 类型存储日期最高精度是纳秒,但是高精度意味着可存储的日期范围小,即:从大约 1970 到 2262。
对象类型
- object:默认情况下,Elasticsearch 使用 object 数据类型来处理 JSON 对象。
- flattened:这是用来索引对象数组或者具有未知结构的字段的特殊映射类型。其将整个JSON对象作为单个键值对存储,帮助降低索引大小和提高搜索速度。
- nested:这是一个类似于 object 的数据类型,但它能保存并查询对象数组内部对象的独立性,因此可以用来处理更复杂的结构。
- join:这是一个特殊数据类型,用于模拟在文档之间的父/子关系。这样可以创建一对多的连接,例如,在博客文章和评论这样的场景中使用。
空间数据类型
- geo_point:表示地理位置的点,存储纬度和经度信息。
- geo_shape:表示复杂的地理形状,如多边形、线、圆等。
- point:在笛卡尔空间中表示一个点,存储X和Y坐标。
- shape:在笛卡尔空间中表示任意复杂的几何形状。
文档排名类型
- dense_vector:记录浮点值的密集向量。这种类型常用于存储机器学习模型的输出,例如词嵌入、句子嵌入等。
- rank_feature:记录单个数值特征以优化排名。当这个字段被查询时,Elasticsearch 会考虑其值来重新排序搜索结果。
- rank_features:记录多个数值特征以优化排名。与
rank_feature类似,但它能够处理包含多个特征的对象。当这些字段被查询时,Elasticsearch 会考虑它们的值来重新排序搜索结果。
文本搜索类型
- text:用于存储全文和进行全文搜索的数据类型。
- **annotated-text:**这是一个特殊的文本字段,它支持包含标记的文本。这些标记表示文本中的命名实体或其他重要项,可以在后续搜索中使用。
- completion :这是一个专门为自动补全和搜索建议设计的数据类型。
- search_as_you_type: 这是一种特殊的文本字段,它被优化以提供按键查询时的即时反馈,从而提高用户输入时的搜索体验。
- token_count:这是一种数值型字段,用于存储文本字段中的词元数量。此字段常用于信息检索场景,比如评估某个字段的长度。
两种映射类型
自动映射:Dynamic Field Mapping
Elasticsearch的Dynamic Field Mapping是一种自动产生index mapping的机制。在通常情况下,当一个新文档被索引到Elasticsearch中,如果其中包含了未在mapping中定义的字段,Elasticsearch就会尝试根据这个新字段的数据类型自动生成相应的mapping。
自动映射关系如下:
| field type | dynamic |
|---|---|
| true/false | boolean |
| 小数 | float |
| 数字 | long |
| object | object |
| 数组 | 取决于数组中的第一个非空元素的类型 |
| 日期格式字符串 | date |
| 数字类型字符串 | float/long |
| 其他字符串 | text + keyword |
除了上述字段类型之外,其他类型都必须显式映射,也就是必须手工指定,因为其他类型ES无法自动识别。
这里有几点需要注意:
- 数据类型识别:Elasticsearch会按照以下顺序判断数据类型:长整数、浮点数、布尔值、日期、字符串(字符串可能会进一步映射为text或keyword)。
- 字段名称含义:Elasticsearch不会考虑字段名称的含义,它仅仅依靠字段的数据类型来生成mapping。
- 关闭动态映射:如果你不希望Elasticsearch自动创建mapping,可以将index的
dynamic设置为false。 - 动态模板:你可以使用动态模板来改变默认的mapping规则,例如,你可以将所有看起来像日期的字符串都映射为date类型。
- 对象和嵌套字段:对于对象(object)和嵌套字段(nested),Elasticsearch也会递归地应用动态映射规则。
- 更新映射:请注意,一旦字段的映射被创建,就不能再修改字段的数据类型了。因此,如果你要索引的文档中有新的字段,最好事先定义好mapping,避免让Elasticsearch自动映射可能产生不符合你期望的结果。
- 当一个字段第一次出现时,Elasticsearch会使用先行数据类型来设置映射。如果后续数据类型与先前设置的映射类型不一致,Elasticsearch可能无法正确索引这些文档。
总的来说,虽然动态字段映射可以在某些情况下提供便利,但它也可能导致未预见的问题。因此,更推荐在开始索引文档之前就定义好mapping。
显式映射:Expllcit Field Mapping
在 Elasticsearch 中,显式映射(Explicit Field Mapping)是指为索引预定义的字段类型和行为。当你创建一个索引时,你可以定义每个字段的数据类型、分词器或者其他相关的配置。这就是显式映射。
以下是一些主要的显式映射类型:
- 核心数据类型:包括 string(字符串)、integer(整型)、long(长整型)、double(双精度浮点型)、boolean(布尔型)等。
- 复合数据类型:包括 object(对象),用于单个 JSON 对象,nested,用于 JSON 数组。
- 地理数据类型:如 geo_point 和 geo_shape。
- 专门用途的数据类型:例如 IP、自动完成、token count、join types 等。
通过显式映射,Elasticsearch 可以更准确地解析和索引数据,对查询性能优化起到关键作用。如果不提供显式映射,Elasticsearch 将会根据输入数据自动推断并生成隐式映射,但可能无法达到最理想的效果。
以下是一个示例,展示了怎么设置一个简单的显式映射:
PUT my_index
{
"mappings": {
"properties": {
"name": { "type": "text" },
"age": { "type": "integer" }
}
}
}
上述代码中,我们在 my_index 索引中定义了两个字段的映射,name 字段类型为 text,age 字段类型为 integer。
注意:在 Elasticsearch 7.0 之后,映射类型被废弃,所有的映射参数直接放在 “properties” 下。
映射参数
在Elasticsearch中,映射参数是用于定义如何处理文档和其包含的字段的规则。
主要参数有下:
- index:是否对当前字段创建倒排索引,默认 true,如果不创建索引,该字段不会通过索引被搜索到,但是仍然会在 source 元数据中展示。
- analyzer:指定分析器(character filter、tokenizer、Token filters)。
- boost:对当前字段相关度的评分权重,默认1。
- coerce:是否允许强制类型转换,为 true的话 “1”能被转为 1, false则转不了。虽然这个参数可以帮助我们强制类型转换,但是它可能会在数据质量管理中引起问题。如果原始数据包含错误的类型,使用 “coerce” 可能会隐藏这些问题,而不是将其暴露出来。
- copy_to:该参数允许将多个字段的值复制到组字段中,然后可以将其作为单个字段进行查询。
- doc_values:为了提升排序和聚合效率,默认true,如果确定不需要对字段进行排序或聚合,也不需要通过脚本访问字段值,则可以禁用doc值以节省磁盘空间,对于text字段和annotated_text字段,无法禁用此选项,因为这些字段类型在默认情况下不使用doc values。
- dynamic:控制是否可以动态添加新字段
- true :新检测到的字段将添加到映射中(默认)。
- false :新检测到的字段将被忽略。这些字段将不会被索引,因此将无法搜索,但仍会出现在_source返回的匹配项中。这些字段不会添加到映射中,必须显式添加新字段。
- strict :如果检测到新字段,则会引发异常并拒绝文档。必须将新字段显式添加到映射。
- eager_global_ordinals:用于聚合的字段上,优化聚合性能,但不适用于 Frozen indices。
- Frozen indices(冻结索引):有些索引使用率很高,会被保存在内存中,有些使用率特别低,宁愿在使用的时候重新创建,在使用完毕后丢弃数据,Frozen indices 的数据命中频率小,不适用于高搜索负载,数据不会被保存在内存中,堆空间占用比普通索引少得多,Frozen indices是只读的,请求可能是秒级或者分钟级。
- enable:是否创建倒排索引,可以对字段操作,也可以对索引操作,如果不创建索引,仍然可以检索并在_source元数据中展示,谨慎使用,该状态无法修改。enable的作用和index类似,区别就是enable可以对全局进行设置。例如:
PUT my_index
{
"mappings": {
"enabled": false
}
}
- fielddata:查询时内存数据结构,在首次用当前字段聚合、排序或者在脚本中使用时,需要字段为fielddata数据结构,并且创建倒排索引保存到堆中。
- fields:给field创建多字段,用于不同目的(全文检索或者聚合分析排序)。
- format:格式化。例如:
"date": {
"type": "date",
"format": "yyyy-MM-dd"
}
- ignore_above:这是一个针对keyword类型字段的设置,对于超过指定长度的字符串,ES 不会对其建立索引。
- ignore_malformed:忽略类型错误。
- index_options:控制将哪些信息添加到反向索引中以进行搜索和突出显示。仅用于text字段。
- Index_phrases:提升 exact_value 查询速度,但是要消耗更多磁盘空间。
- Index_prefixes:前缀搜索。
- min_chars:前缀最小长度> 0,默认 2(包含)。
- max_chars:前缀最大长度< 20,默认 5(包含)。
- meta:附加元数据。
- normalizer:normalizer 参数用于解析前(索引或者查询时)的标准化配置。
- norms:是否禁用评分(在 filter 和聚合字段上应该禁用)。
- null_value:为 null 值设置默认值。
- position_increment_gap:对于数组或者列表类型的字段,在进行phrase query或者phrase suggest时,允许用户自定义同一字段内两个相邻元素间的位置增量,默认100。
- properties:除了mapping还可用于object的属性设置。
- search_analyzer:设置单独的查询时分析器,如果定义了analyzer而没有定义search_analyzer,则search_analyzer的值默认会和analyzer保持一致,如果两个都没有定义,则默认是:“standard”。analyzer针对的是元数据,而search_analyzer针对的是传入的搜索词。
- similarity:为字段设置相关度算法,和评分有关。支持BM25、classic(TF-IDF)、boolean。
- store:设置字段是否仅查询。
- term_vector:运维参数。这个参数可以设置存储哪些信息用于更复杂的文本处理,例如在词向量建模或者更复杂的文本检索场景中使用。
Text & Keyword
Text
当一个字段是要被全文检索时,比如 Email 内容、产品描述,这些字段应该使用 text 类型。设置 text 类型以后,字段内容会被分析,在生成倒排索引之前,字符串会被分析器分成一个个词项。text类型的字段不用于排序,很少用于聚合。
注意事项
- 适用于全文检索:如 match 查询。
- 文本字段会被分词。
- 默认情况下,会创建倒排索引。
- 自动映射器会为 Text 类型创建 Keyword 字段。
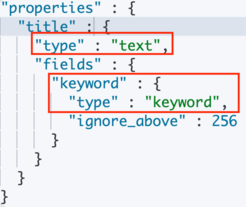
Keyword
Keyword 类型适用于不分词的字段,如姓名、Id、数字等。如果数字类型不用于范围查找,用 Keyword 的性能要高于数值类型。
当使用 Keyword 类型查询时,其字段值会被作为一个整体,并保留字段值的原始属性。
GET index/_search
{
"query": {
"match": {
"title.keyword": "测试文本值"
}
}
}
注意事项
- Keyword 不会对文本分词,会保留字段的原有属性,包括大小写等。
- Keyword 仅仅是字段类型,而不会对搜索词产生任何影响。
- Keyword 一般用于需要精确查找的字段,或者聚合排序字段。
- Keyword 通常和 Term 搜索一起用。
- Keyword 字段的
ignore_above参数代表其截断长度,默认 256,如果超出长度,字段值会被忽略,而不是截断,忽略指的是会忽略这个字段的索引,搜索不到,但数据还是存在的。
映射模板
之前讲过的映射类型或者映射参数,都是为确定的某个字段而声明的。
但是当我们不确定字段名字的时候该怎么设置mapping呢?映射模板就是用来解决这种场景的。
如果希望对符合某类要求的特定字段制定映射,就需要用到映射模板:Dynamic templates。映射模板有时也被称作:自动映射模板、动态模板等。
以下是一个示例:
{
"mappings": {
"dynamic_templates": [
{
"strings_as_keyword": {
"match_mapping_type": "string",
"mapping": {
"type": "keyword"
}
}
},
{
"longs_as_integer": {
"match_mapping_type": "long",
"mapping": {
"type": "integer"
}
}
}
]
}
}
在上述例子中,我们定义了两个模板:strings_as_keyword 和 longs_as_integer。当新字段被发现时,Elasticsearch 会检查这些模板以决定如何映射这个新字段。
strings_as_keyword模板将所有新的字符串类型字段映射为keyword类型。longs_as_integer模板将所有新的长整数(long)类型字段映射为integer类型。
注意:这些只是示例,实际的映射应该取决于实际数据和查询需求。例如,如果你需要对字符串字段进行全文搜索,那么将其映射为 text 可能更合适。
参数
match:匹配字段名称。unmatch:反匹配字段名称。match_mapping_type:匹配字段类型,例如 string、long、double、boolean、date。match_pattern:允许更复杂的名字模式,支持"starts_with"、“ends_with” 和 “contains”。path_match:允许你用路径 (如 article.title) 来匹配字段。path_unmatch:反匹配路径。mapping:该字段被匹配时,应用的映射设置。
案例
PUT test_dynamic_template
{
"mappings": {
"dynamic_templates": [{
"integers": {
"match_mapping_type": "long",
"mapping": {
"type": "integer"
}
}
},
{
"longs_as_strings": {
"match_mapping_type": "string",
"match": "num_*",
"unmatch": "*_text",
"mapping": {
"type": "keyword"
}
}
}
]
}
}
以上代码会产生以下效果:
- 所有 long 类型字段会默认映射为 integer。
- 所有文本字段,如果是以 num_ 开头,并且不以 _text 结尾,会自动映射为 keyword 类型。