note
- RAG流程(写作论文中的background:公式设定、emb、召回内容、召回基准)(工作中的思路:嵌入模型、向量存储、向量存储检索器、LLM、query改写、RAG评测方法)
- 仅为个人关于RAG的一些零碎总结,持续更新中。
文章目录
- note
- 一、常见本地知识库问答流程
- 1 整体框架
- 2. 文本切分
- 3. 图解流程
- 二、相关RAG综述/工作
- 一篇RAG综述
- 1、Retrieval Source知识来源源
- 2、Retrieval Metrics召回的度量标准
- 3、Integration集成的方法
- HIT的RAG+知识融合综述
- Retrieval-Augmented-LLM
- FastGPT:基于 LLM 大语言模型的知识库问答实现:
- 陈丹琦Tutorial-基于检索的大语言模型
- 1. 架构:What & How & When
- 2. 如何训练
- 3. 应用
- 三、相关RAG项目
- chatlaw项目
- 1. query抽取为key word
- 2. 项目中的模型
- 3. 调度模型
- 四、embedding模型相关
- FlagEmbedding
- M3E embedding
- 文本嵌入框架uniem
- 五、RAG评测相关
- 六、RAG相关比赛
- 七、常见问题
- 注意事项
- 讨论记录
- Reference
一、常见本地知识库问答流程
1 整体框架

- 改进的点(方向):
- 改LLM模型
- embedding模型
- 文本分割方式
- 多卡加速模型部署
- 提升top-k检索召回的质量
- 基于数据隐私和私有化部署,可以方便的使用Langchain+大模型进行推理
2. 文本切分
Langchain源码:https://github.com/hwchase17/langchain/blob/master/langchain/text_splitter.py
Langchain的内置文本拆分模块的常见参数:
- chunk_size:文本块的大小,即文本块的最大尺寸;
- chunk_overlap:表示两个切分文本之间的重合度,文本块之间的最大重叠量,保留一些重叠可以保持文本块之间的连续性,可以使用滑动窗口进行构造,这个比较重要。
- length_function:用于计算文本块长度的方法,默认为简单的计算字符数;
其他文本分割器:
文本分割器
LatexTextSplitter
沿着Latex标题、标题、枚举等分割文本。
MarkdownTextSplitter
沿着Markdown的标题、代码块或水平规则来分
割文本。
NLTKTextSplitter
使用NLTK的分割器
PythonCodeTextSplitter
沿着Python类和方法的定义分割文本。
RecursiveCharacterTextSplitter
用于通用文本的分割器。它以一个字符列表为
参数, 尽可能地把所有的段落 (然后是句子,
然后是单词) 放在一起
SpacyTextSplitter
使用Spacy的分割器
TokenTextSplitter
根据openAl的token数进行分割
\begin{array}{|c|c|} \hline \text { 文本分割器 } & \\ \hline \text { LatexTextSplitter } & \text { 沿着Latex标题、标题、枚举等分割文本。 } \\ \hline \text { MarkdownTextSplitter } & \begin{array}{l} \text { 沿着Markdown的标题、代码块或水平规则来分 } \\ \text { 割文本。 } \end{array} \\ \hline \text { NLTKTextSplitter } & \text { 使用NLTK的分割器 } \\ \hline \text { PythonCodeTextSplitter } & \text { 沿着Python类和方法的定义分割文本。 } \\ \hline \text { RecursiveCharacterTextSplitter } & \begin{array}{l} \text { 用于通用文本的分割器。它以一个字符列表为 } \\ \text { 参数, 尽可能地把所有的段落 (然后是句子, } \\ \text { 然后是单词) 放在一起 } \end{array} \\ \hline \text { SpacyTextSplitter } & \text { 使用Spacy的分割器 } \\ \hline \text { TokenTextSplitter } & \text { 根据openAl的token数进行分割 } \\ \hline \end{array}
文本分割器 LatexTextSplitter MarkdownTextSplitter NLTKTextSplitter PythonCodeTextSplitter RecursiveCharacterTextSplitter SpacyTextSplitter TokenTextSplitter 沿着Latex标题、标题、枚举等分割文本。 沿着Markdown的标题、代码块或水平规则来分 割文本。 使用NLTK的分割器 沿着Python类和方法的定义分割文本。 用于通用文本的分割器。它以一个字符列表为 参数, 尽可能地把所有的段落 (然后是句子, 然后是单词) 放在一起 使用Spacy的分割器 根据openAl的token数进行分割
我们直接举个栗子,比如对中文文本切分,继承langchain中类CharacterTextSplitter的ChineseTextSplitter类。正则表达式sent_sep_pattern来匹配中文句子的分隔符(如句号,感叹号,问好,分号等):
# 中文文本切分类
class ChineseTextSplitter(CharacterTextSplitter):
def __init__(self, pdf: bool = False, **kwargs):
super().__init__(**kwargs)
self.pdf = pdf
def split_text(self, text: str) -> List[str]:
if self.pdf:
text = re.sub(r"\n{3,}", "\n", text)
text = re.sub('\s', ' ', text)
text = text.replace("\n\n", "")
sent_sep_pattern = re.compile('([﹒﹔﹖﹗.。!?]["’”」』]{0,2}|(?=["‘“「『]{1,2}|$))') # del :;
sent_list = []
for ele in sent_sep_pattern.split(text):
if sent_sep_pattern.match(ele) and sent_list:
sent_list[-1] += ele
elif ele:
sent_list.append(ele)
return sent_list
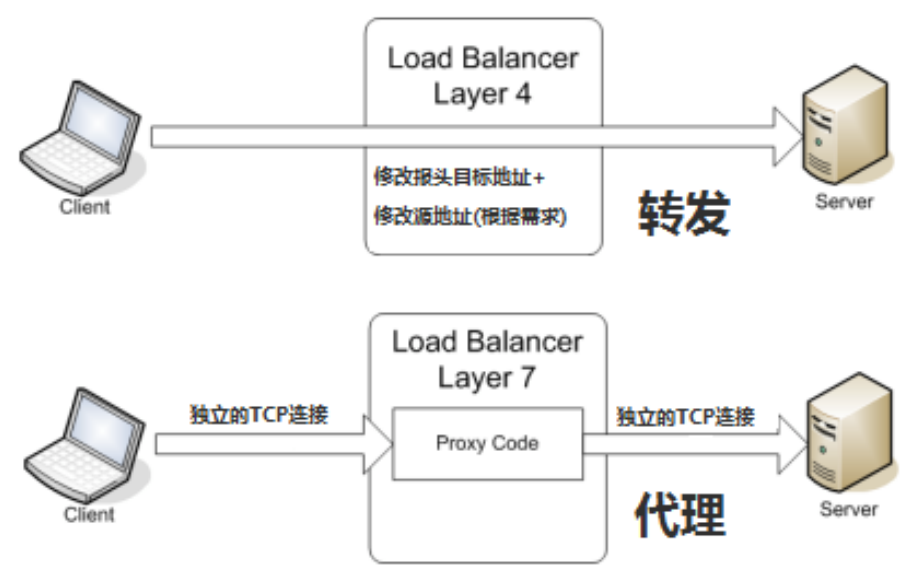
3. 图解流程

二、相关RAG综述/工作
一篇RAG综述
《A Survey on Retrieval-Augmented Text Generation》
地址:https://arxiv.org/abs/2202.01110
该工作旨在对检索增强文本生成进行研究。主要核心的点如下:

1、Retrieval Source知识来源源
训练语料:有标注的训练数据直接作为外部知识;
外部数据:支持提供训练数据之外的外部知识作为检索来源,比如于任务相关的领域数据,实现模型的快速适应;
无监督数据:前两种知识源都需要一定的人工标注来完善“检索依据-输出”的对齐工作,无监督知识源可以直接支持无标注/对齐的知识作为检索来源;
2、Retrieval Metrics召回的度量标准
浅层语义检索:针对稀疏向量场景的度量方法,比如TF-IDF, BM25等;
深层语义检索: 针对稠密向量的度量方法,比如文本相似度;
特定任务检索:在通用的度量场景下,度量得分高并不能代表召回知识准确,因此有学者提出基于特定任务优化的召回度量方法,提高度量的准确率;
3、Integration集成的方法
数据增强:直接拼接用户输入文本和知识文本,然后输入文本生成模型;
注意力机制:引入额外的Encoder,对用户输入文本和知识文本进行注意力编码后输入文本生成模型;
架抽取:前两种方法都是通过文本向量化的隐式方法完成知识重点片段的抽取,skeleton extraction方法可以显式地完成类似工作;
该工作针对后续优化方向提出了一些观点,认为:
RATG效果强依赖于召回知识的准确率,这个问题在query和目标知识片段的文本相似度较低的情况尤为突出;
需要做好存储的容量和召回效率之间的平衡;
逻辑上,召回度量模块和文本生成模块的联合训练会有更好的效果;但是在这样的框架下,其训练和预测之间会存在较大的Gap:训练时,模型只针对少量标注的知识源完成优化(Local);而预测时,模型是针对大量的知识源完成度量(Global);
此外,针对目前都基于通用的文本语义完成知识召回,后续可以考虑关注基于任务层级的召回方法的多样化研究,以及不同召回方法的调用的灵活性和可控制性,针对多模态知识源召回方法的优化;
HIT的RAG+知识融合综述
参考:
论文:Trends in Integration of Knowledge and Large Language Models: A Survey and Taxonomy of Methods, Benchmarks, and Applications
HIT解读:赛尔笔记 | 大语言模型与知识融合综述:方法、基准和应用
arxiv:https://arxiv.org/abs/2311.05876
刘老师:也看大模型的选择题评估方式是否鲁棒:兼看RAG知识增强问答中的知识冲突和评测基准
Retrieval-Augmented-LLM
项目:https://github.com/Wang-Shuo/A-Guide-to-Retrieval-Augmented-LLM
检索增强LLM:给 LLM 提供外部数据库,对于用户问题 ( Query ),通过一些信息检索 ( Information Retrieval, IR ) 的技术,先从外部数据库中检索出和用户问题相关的信息,然后让 LLM 结合这些相关信息来生成结果。

FastGPT:基于 LLM 大语言模型的知识库问答实现:
github.com/c121914yu/FastGPT
陈丹琦Tutorial-基于检索的大语言模型
ACL23 Tutorial
陈丹琦 ACL23 Tutorial笔记
前沿重器[36] | ACL23-基于检索的大语言模型-报告阅读
链接:https://acl2023-retrieval-lm.github.io
1. 架构:What & How & When
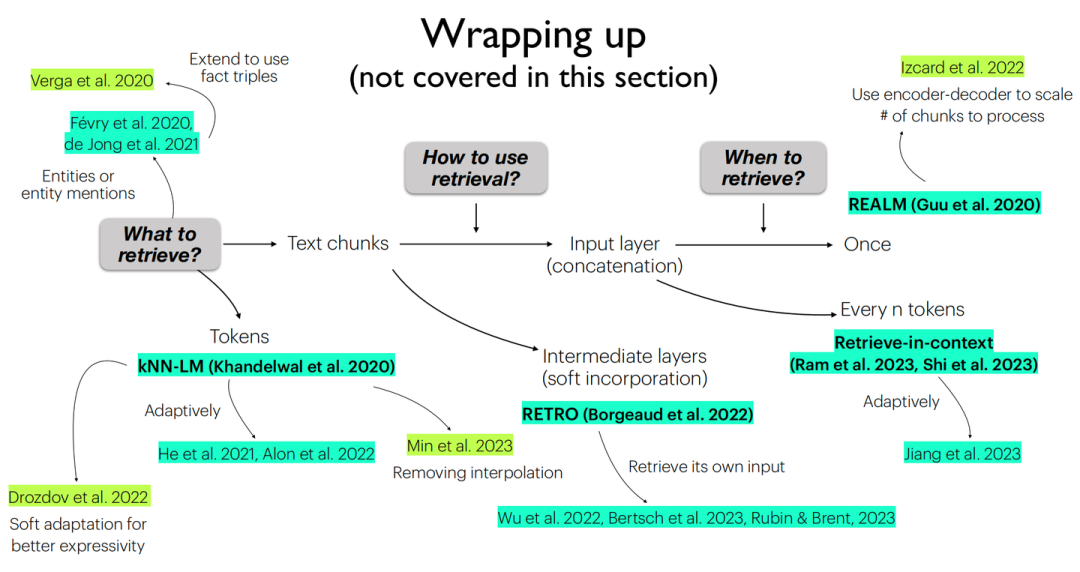
2. 如何训练
现有工作中对于检索增强的语言模型被证实的比较work的训练方式可划分为以下四类:
- Independent training:语言模型与检索器均是独立训练的。
- Sequential training:独立训练单个组件后将其固定,另一个组件根据此组件任务目标进行训练。
- Joint training w/ asynchronous index update:允许索引是“过时”的,即每隔T步才重新更新检索索引。
- Joint training w/ in-batch approximation:使用“批内索引”,而不是完整知识库中的全部索引。
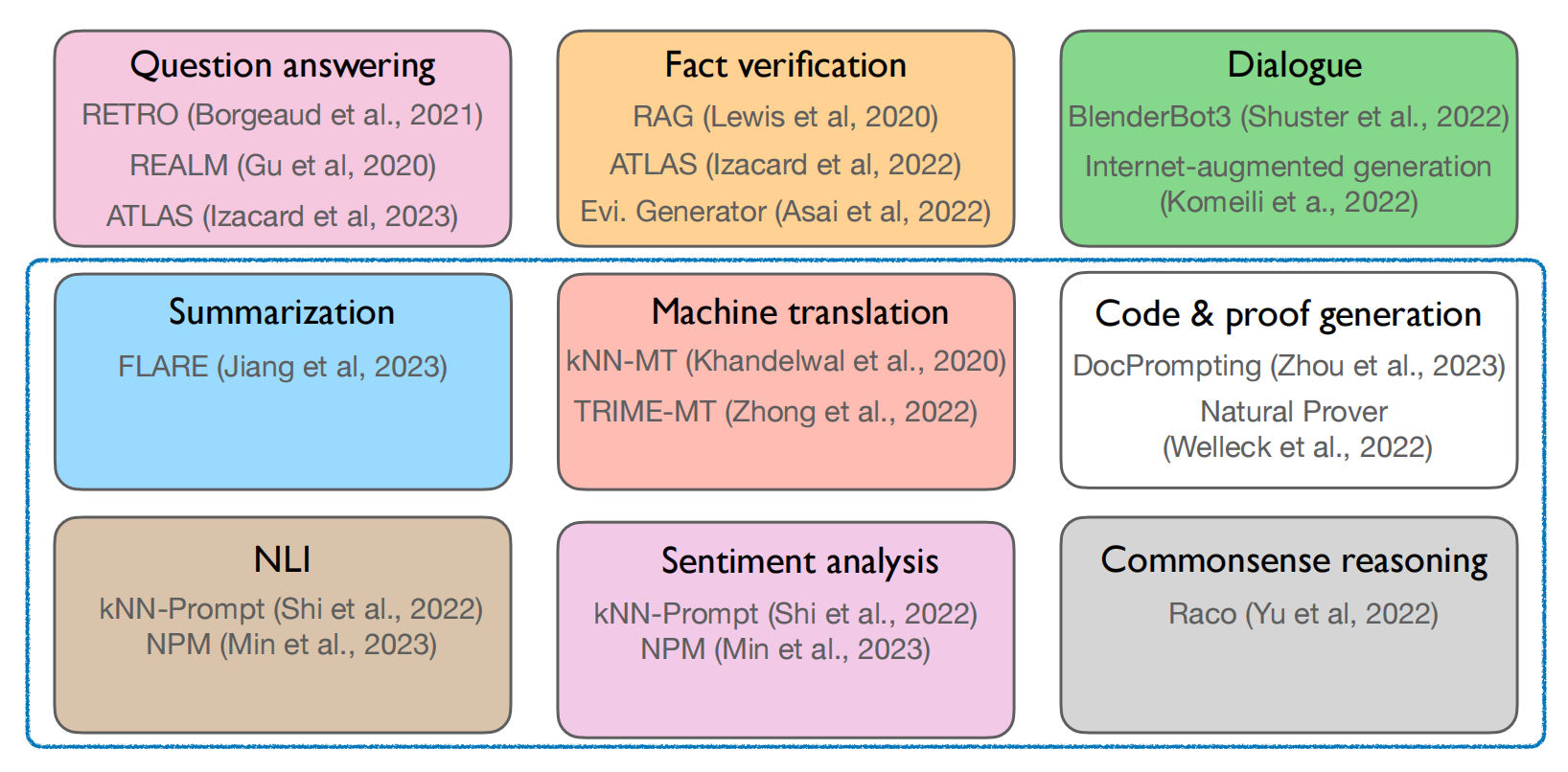
3. 应用
RAG常用在知识密集型任务上。
三、相关RAG项目
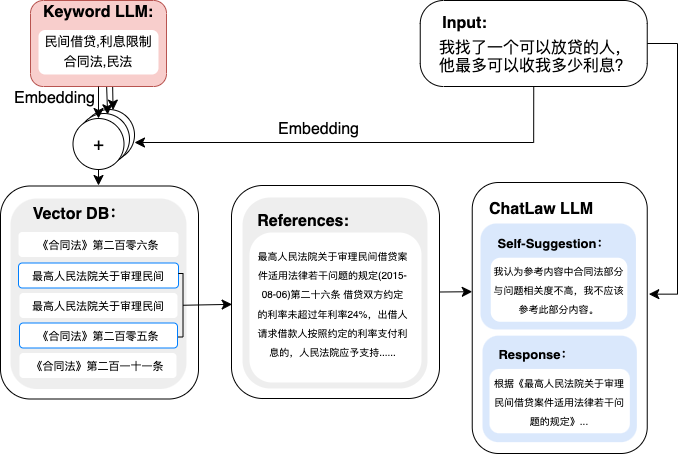
chatlaw项目
1. query抽取为key word
参考:
[1] 北大团队发布大模型 ChatLaw
[2] https://github.com/PKU-YuanGroup/ChatLaw

2. 项目中的模型
-
ChatLaw-13B,此版本为学术demo版,基于姜子牙Ziya-LLaMA-13B-v1训练而来,中文各项表现很好,但是逻辑复杂的法律问答效果不佳,需要用更大参数的模型来解决。
-
ChatLaw-33B,此版本为学术demo版,基于Anima-33B训练而来,逻辑推理能力大幅提升,但是因为Anima的中文语料过少,导致问答时常会出现英文数据。
-
ChatLaw-Text2Vec,使用93w条判决案例做成的数据集基于BERT训练了一个相似度匹配模型,可将用户提问信息和对应的法条相匹配,例如:
“请问如果借款没还怎么办。”
“合同法(1999-03-15): 第二百零六条 借款人应当按照约定的期限返还借款。对借款期限没有约定或者约定不明确,依照本法第六十一条的规定仍不能确定的,借款人可以随时返还;贷款人可以催告借款人在合理期限内返还。”
两段文本的相似度计算为0.9960
3. 调度模型
将文件、音频、文字整合在一起,同时支持法律援助、法律文书、思维导图等多样化输出。
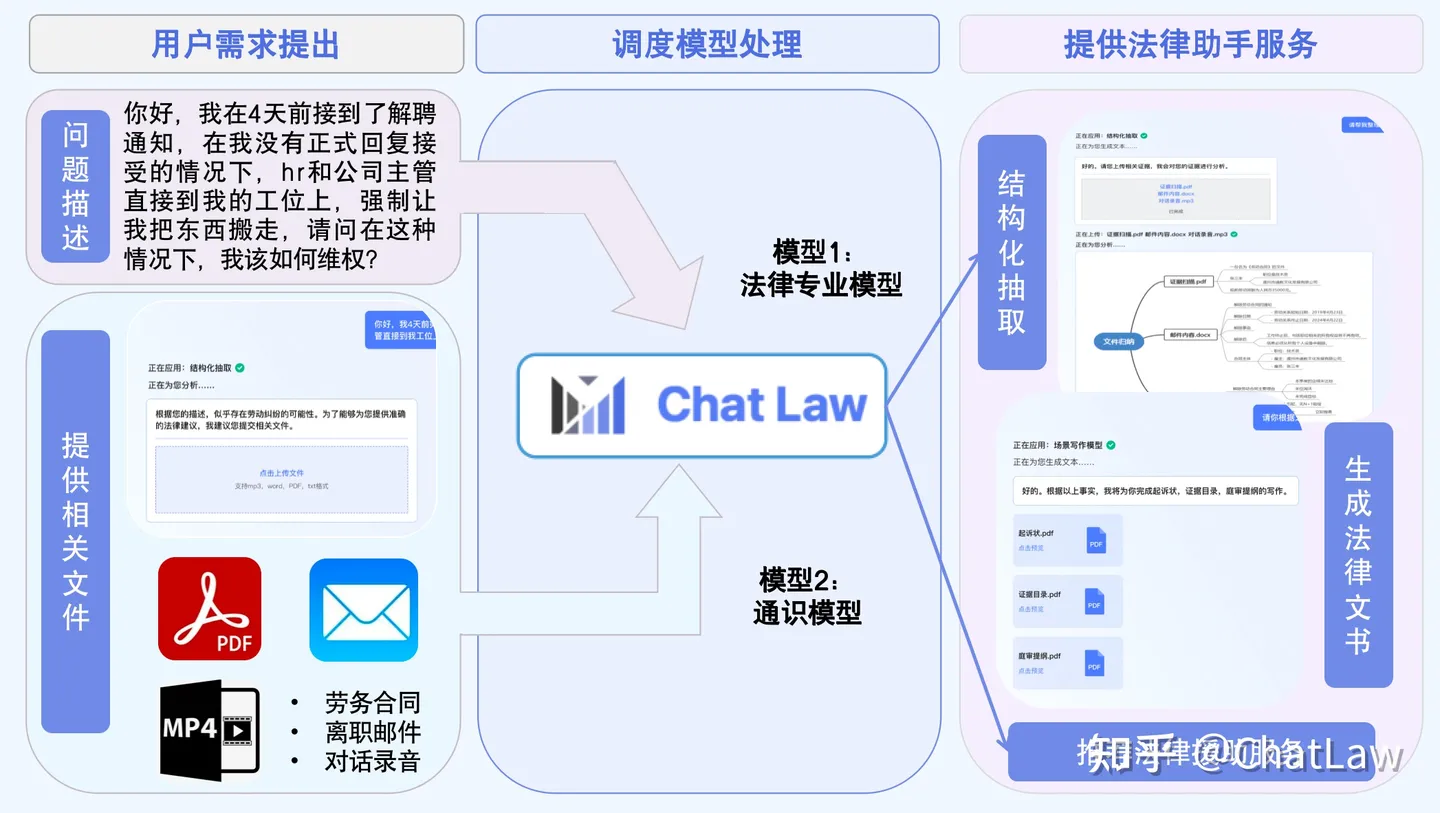
参考:某乎官方回答。
四、embedding模型相关
FlagEmbedding
参考另一篇博客。微调emb实践。
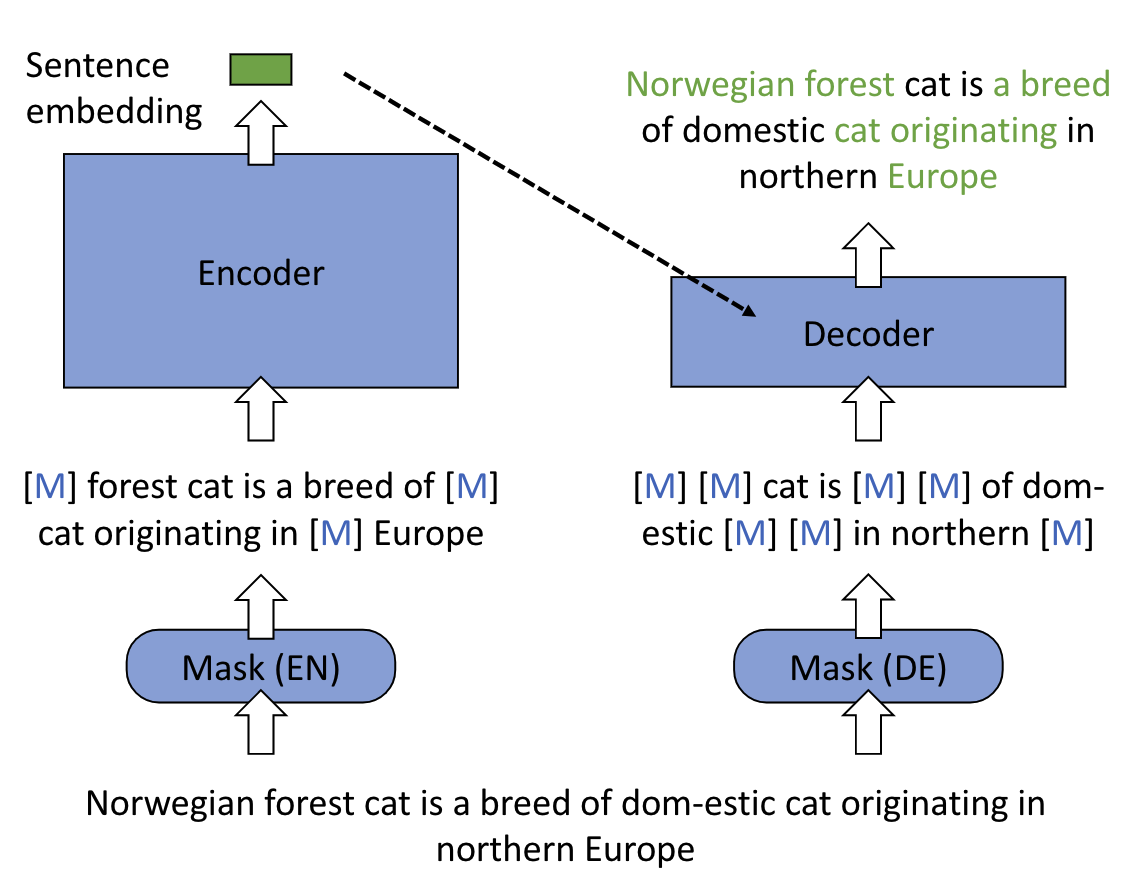
[1] Sentence Embedding 现在的 sota 方法是什么?
M3E embedding
【M3E(Moka Massive Mixed Embedding)]
链接:https://huggingface.co/moka-ai/m3e-base?continueFlag=9b46d5a6f39f18849cafedf79fff183f
M3E模型的微调:https://github.com/wangyuxinwhy/uniem/blob/main/examples/finetune.ipynb
文本嵌入框架uniem
- 项目链接:https://github.com/wangyuxinwhy/uniem
- uniem 0.3.0, FineTuner 除 M3E 外,还支持 sentence_transformers, text2vec 等模型的微调,同时还支持 SGPT 的方式对 GPT 系列模型进行训练,以及 Prefix Tuning。
➿ 2023.07.11 , 发布 uniem 0.3.0, FineTuner 除 M3E 外,还支持 sentence_transformers, text2vec 等模型的微调,同时还支持 SGPT 的方式对 GPT 系列模型进行训练,以及 Prefix Tuning。 FineTuner 初始化的 API 有小小的变化,无法兼容 0.2.0
➿ 2023.06.17 , 发布 uniem 0.2.1 , 实现了 FineTuner 以原生支持模型微调,几行代码,即刻适配!
📊 2023.06.17 , 发布 MTEB-zh 正式版 , 支持 6 大类 Embedding 模型 ,支持 4 大类任务 ,共 9 种数据集的自动化评测
🎉 2023.06.08 , 发布 M3E models ,在中文文本分类和文本检索上均优于 openai text-embedding-ada-002,详请请参考 M3E models README。
五、RAG评测相关
HIT综述《Trends in Integration of Knowledge and Large Language Models: A Survey and Taxonomy of Methods, Benchmarks, and Applications》
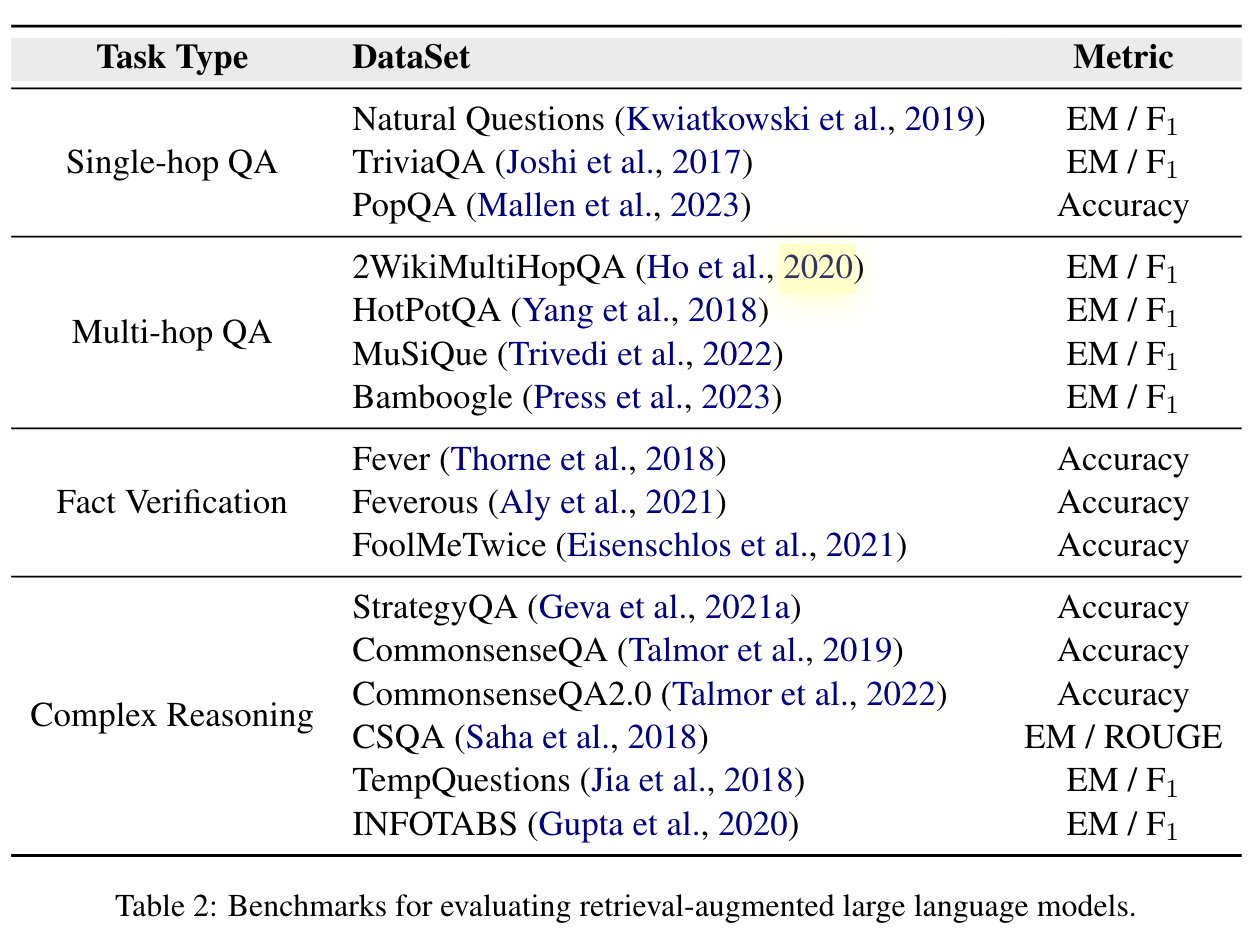
六、RAG相关比赛
链接:大模型Kaggle比赛首秀冠军方案总结
经验:第一名很早之前就使用了RAG+微调,一直遥遥领先,其具体的关键点为:
1.RAG+维基百科文档(上TB原始cirrussearch维基百科数据,夸张)
2.e5向量模型,具体是e5-base-v2,e5-large-v2,gte-base,gte-large和bge-large
3.自己定制pytorch的相似度模型,无需faiss,可以解决GPU显存不够的问题。
4.大多数模型是7B和融合,又一个13B,单更大的模型没起作用。
5. 想让deberta work,但是大模型太强了,甚至融合都没用。
6.所有的LLM都是二分类头+微调的。
7.用了两种典型的分类头结构
七、常见问题
知识库问题:扫码版图文表图区精度不高,超长文本存储和检索精度低
改进(除了第三点,其他都能粗暴地用prompt实现):
- 1、把问答域细化,给检索文本分类,打标签处理,以缩小召回目标域,提升相关性。
- 2、增加问答逻辑。如问题与上下文是否相关,上下文是否可以回答用户问题的判定逻辑,拒答逻辑。
- 3、不同种类问答的分流逻辑。打个比方,问百科,问医药,问金融,走不同的回答逻辑。
- 4、使用多重召回逻辑。基于向量,基于领域向量,基于es,基于编辑距离等,走投票策略。
- 5、增加生成前判定,生成后判定逻辑。前者判定适合是否该回答,是否该拒答,后者判定是否对自己回答有置信。
注意事项
- 向量库只是个数据库,并不能优化什么决定性的东西【除了检索速度】。重心要放在,
- 1)对相关性内容的召回上,把不对的踢掉【分类,拒答】,把对的提高(加权,投票)
- 2)不受控生成的缓解【听懂指令,不跳出给定上下文,这靠SFT】。
讨论记录
- 如果你目前的知识库组织方式是文档那么你就用文档,不用再抽取
- 如果你数据库里有结构化数据,例如医药数据库存了各种药以及各种属性,这是领域内你特有的sql数据或者以前积累的已抽取的三元组现在想用起来,你可以把他当成知识图谱融进大模型的推理里
- 文档检索增强的问答模型依然存在幻觉,减少这种幻觉的方式的办法是提高你召回片段的质量,以及训练你的模型拒绝回答的能力」
某人:去年才开始做知识抽取,已经抽取得到一些结构化知识库,今年chatgpt突然出现,感觉知识图谱没啥优势了[捂脸]。你的说的第三点可能就是领域知识图谱仅存的一点优势了。如果使用基于知识图谱的问答系统,那就是要将用户问题转成查询语句,如在知识库如Neo4j中,没有查到相应的答案,就告诉用户查无答案,也算是避免幻觉
Reference
[1] https://acl2023-retrieval-lm.github.io/
[2] RefGPT: Reference-to-Dialogue by GPT and for GPT
[3] m3e可能是目前最强的开源中文embedding模型-m3e
[4] 使用检索增强生成技术构建特定行业的 LLM.林立琨
[5] https://github.com/Wang-Shuo/A-Guide-to-Retrieval-Augmented-LLM
[6] 手工微调embedding模型,让RAG应用检索能力更强
[7] 分享Embedding 模型微调的实现