什么是模型量化
模型量化(Model Quantization)是一种通过减少模型参数表示的位数来降低模型计算和存储开销的技术。一般来说,模型参数在深度学习模型中以浮点数(例如32位浮点数)的形式存储,而模型量化可以将这些参数转换为较低位宽的整数或定点数。这有几个主要的作用:
减小模型大小: 通过减少每个参数的位数,模型占用的存储空间变得更小。这对于在移动设备、嵌入式系统或者边缘设备上部署模型时尤其有用,因为这些设备的存储资源通常有限。
加速推理: 量化可以降低模型推理时的计算开销。使用较低位宽的整数或定点数进行计算通常比使用浮点数更高效,因为它可以减少内存带宽需求,提高硬件的并行计算能力。这对于实时推理和响应时间敏感的应用程序非常重要。
减少功耗: 量化可以降低模型在部署环境中的能耗,因为计算和存储操作通常是耗电的。通过减少模型参数的位数,可以减少在部署设备上执行推理时的功耗。
提高模型在资源受限环境中的可用性: 在一些场景中,设备的存储和计算资源可能非常有限,例如在边缘设备或物联网设备上。模型量化使得在这些资源受限的环境中部署深度学习模型更加可行。
总体而言,模型量化是一种权衡计算、存储和功耗的技术,可以使得深度学习模型更适应于各种不同的部署场景。
常用的模型量化技术
Round nearest quantization:(最近整数量化)
是一种常见的模型量化技术,它用于将浮点数参数量化为整数或定点数。在这种量化中,每个浮点数参数被四舍五入到最接近的整数或定点数。这种方法旨在保留尽可能多的信息,同时将参数映射到有限的整数或定点值上。
AWQ(Activation-aware Weight Quantization)-激活感知权重量化:
激活感知权重量化(AWQ),一种面向LLM低比特权重量化的硬件友好方法。我们的方法基于这样一个观察:权重并非同等重要,仅保护1%的显著权重可以大大减少量化误差。然后,我们建议通过观察激活而不是权重来搜索保护显著权重的最佳通道缩放。AWQ不依赖于任何反向传播或重构,因此可以很好地保留LLMs在不同领域和模态中的泛化能力,而不会过度拟合校准集。AWQ在各种语言建模和特定领域基准上优于现有工作。由于更好的泛化能力,它在面向指令调整的LMs上实现了出色的量化性能,并且首次在多模态LMs上取得了成功,论文地址。
GPTQ:Generative Pretrained Transformer Quantization
GPTQ 的思想最初来源于 Yann LeCun 在 1990 年提出的 OBD 算法,随后 OBS、OBC(OBQ) 等方法不断进行改进,而 GPTQ 是 OBQ 方法的加速版。简单来说,GPTQ 对某个 block 内的所有参数逐个量化,每个参数量化后,需要适当调整这个 block 内其他未量化的参数,以弥补量化造成的精度损失。GPTQ 量化需要准备校准数据集,论文地址。
Transformers量化技术BitsAndBytes
BitsAndBytes 通过将模型参数量化为较低比特位宽的整数表示,从而在不显著影响任务性能的前提下减小了模型的存储需求和计算复杂度。然而,需要仔细选择位宽度,以平衡性能和信息损失之间的权衡。
大模型占用显存粗略计算公式

上面的推导公式中1GB=1024MB=2的10次方MB,1MB=1024KB,1KB=1024B,所以1GB=2的30次方B,1GB=1024*1024*1024B=1073741824B,约等于10亿B,所以约等于10的9次方B。通过上面的计算公式,可以粗略计算出对于6B的大模型,需要12G的显存,当然这只是对模型参数需要占用的显存的粗略计算,实际加载一个大模型,还需要更多的显存。这也是为什么有这些量化技术来缩小模型的大小。
采用AWQ量化模型代码例子
下面的代码例子来源于AWQ官网,在实际运行过程,如果选择加载vicuna-7b-v1.5-awq,一直在报“Token indices sequence length is longer than the specified maximum sequence length for this model (8322 > 4096). Running this sequence through the model will result in indexing errors”,换成了量化“facebook/opt-125m-awq”,量化成功,但是用量化后的模型尝试运行benchmark的脚本,也报错了。错误提示是“/home/ubuntu/python/opt-125-awq is not a folder containing a `.index.json` file or a pytorch_model.bin file”。但是这些错误不影响我们对AWQ量化模型的理解。
from awq import AutoAWQForCausalLM
from transformers import AutoTokenizer
model_path = 'lmsys/vicuna-7b-v1.5'
quant_path = 'vicuna-7b-v1.5-awq'
quant_config = { "zero_point": True, "q_group_size": 128, "w_bit": 4, "version": "GEMM" }
# Load model
# NOTE: pass safetensors=True to load safetensors
model = AutoAWQForCausalLM.from_pretrained(
model_path, **{"low_cpu_mem_usage": True, "use_cache": False}
)
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
# Quantize
model.quantize(tokenizer, quant_config=quant_config)
# Save quantized model
model.save_quantized(quant_path)
tokenizer.save_pretrained(quant_path)
print(f'Model is quantized and saved at "{quant_path}"')将model_path=‘facebook/opt-125m’可以量化成功。接下来再看看官网的benchmark脚本具体如何对量化后的模型做评估。官网完整的benchmark脚本。整个代码的目的是通过测试不同条件下的生成性能,包括速度和内存使用,以便评估模型的效果。
TimeMeasuringLogitsProcessor 类:在模型前向传播之后调用,用于测量模型生成的时间。通过记录每个时间点,计算了预填充和生成阶段的时间差,以及每个生成步骤的时间差。主要用于测量模型的速度,包括预填充和生成阶段的速度。
warmup 函数:通过进行矩阵乘法来对模型进行预热,以确保模型的权重已经加载到 GPU 中。
generate_torch 和 generate_hf 函数:generate_torch 函数使用 PyTorch 的 model 对象生成 tokens。generate_hf 函数使用 Huggingface Transformers 库的 model.generate 方法生成 tokens。这两个函数都会测量生成的时间,并返回上下文时间和每个生成步骤的时间。
run_round 函数:通过加载模型、进行预热、生成 tokens 等步骤来运行测试的一个循环。
测试了模型在不同上下文长度和生成步骤数下的性能。输出测试结果,包括上下文时间、生成时间、内存使用等。
main 函数:设置不同的上下文长度和生成步骤数的测试轮次。使用给定的生成器(PyTorch 或 Huggingface)运行测试。
运行脚本的时候,参数包括:model_path:模型路径。
quant_file:量化权重的文件名。
batch_size:生成时的批量大小。
no_safetensors:是否禁用安全张量。
generator:生成器类型,可以是 "torch" 或 "hf"。
pretrained:是否使用预训练模型。
采用GPTQ量化模型代码例子
下面的例子来源于gptq官网例子,这个例子中量化的也是opt-125m模型,gptq进行模型量化时,需要传递数据集,这里传递的数据集很简单,就是一句话。

模型量化成功后,用量化后的模型生成内容,可以看到,如果是数据集中的信息,模型能正确生成内容,如果是其他问题,例如“woman works as”,模型就无法输出内容了。所以,如果采用gptq进行模型量化,输入的数据集是非常关键的。

当然也支持一些默认数据集,例如:(包括['wikitext2','c4','c4-new','ptb','ptb-new'])。这些数据集都可以在huggingface上找到。如果采用默认数据集,在初始化GPTQConfig的时候设置dataset参数即可,代码如下所示:
quantization_config = GPTQConfig(
bits=4, # 量化精度
group_size=128,
dataset="c4",
desc_act=False,
)实际在gptq的github上提供了很多example的代码,包括量化后评估模型性能的脚本,更多信息可查看这里。
BitsAndBytes代码例子
BitsAndBytes的量化代码例子非常简单,在from_pretrained()方法中初始化三个参数即可。调用量化后的模型,让其生成内容“Merry Chrismas! I am glad to”,量化后的模型生成的内容也比较ok。具体如下图所示:
from transformers import AutoModelForCausalLM
model_id = "facebook/opt-2.7b"
model_4bit = AutoModelForCausalLM.from_pretrained(model_id,
device_map="auto",
load_in_4bit=True)
# 获取当前模型占用的 GPU显存(差值为预留给 PyTorch 的显存)
memory_footprint_bytes = model_4bit.get_memory_footprint()
memory_footprint_mib = memory_footprint_bytes / (1024 ** 2) # 转换为 MiB
print(f"{memory_footprint_mib:.2f}MiB")
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(model_id
)
text = "Merry Christmas! I'm glad to"
inputs = tokenizer(text, return_tensors="pt").to(0)
out = model_4bit.generate(**inputs, max_new_tokens=64)
print(tokenizer.decode(out[0], skip_special_tokens=True))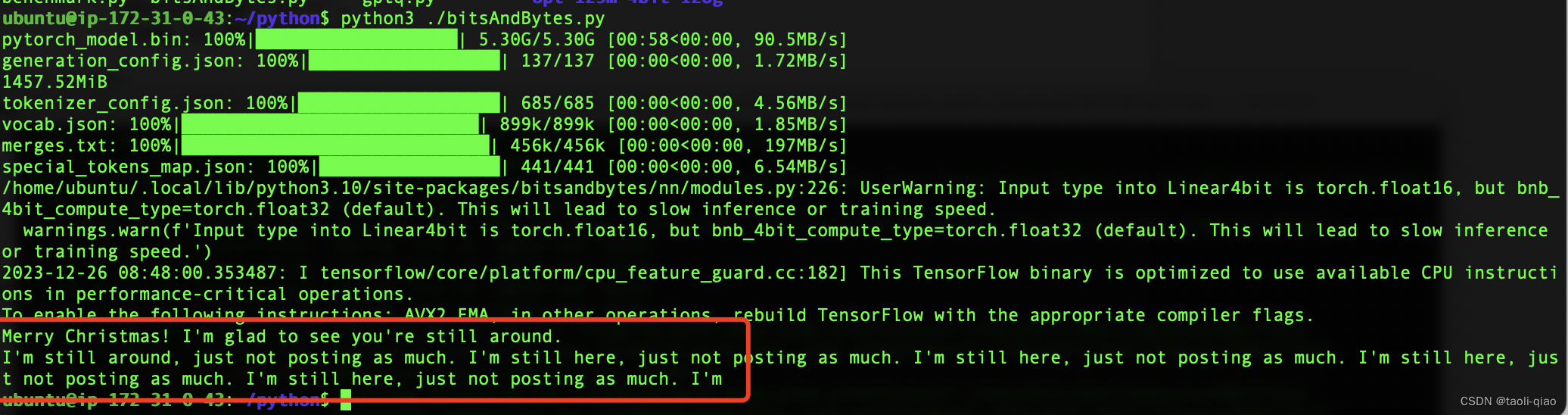
以上就是对于一些常用的模型量化技术的介绍。