文章目录
- 11.树的应用
- (1).Huffman树
- #1.加权外部路径长度
- #2.Huffman算法
- #3.Huffman编码
- (2).二叉搜索树
- #1.基本定义
- #2.查找
- #3.插入结点
- #4.构建树
- #5.查找最小值和最大值
- #6.删除结点
- #7.一个问题
- (3).平衡搜索树
- #1.满二叉树、完全二叉树和丰满二叉树
- #2.平衡因子和平衡树
- #3.左旋与右旋
- #4.平衡调整方法
- #5.缺陷
- 小结
11.树的应用
(1).Huffman树
#1.加权外部路径长度
加权外部路径长度的定义如下:设给定一个具有n个结点的序列
F
=
k
0
,
k
1
,
.
.
.
,
k
n
−
1
F=k_0,k_1,...,k_{n-1}
F=k0,k1,...,kn−1,它们的权都是正整数,且分别为
w
(
k
0
)
,
w
(
k
1
)
,
.
.
.
,
w
(
k
n
−
1
)
w(k_0), w(k_1),...,w(k_{n-1})
w(k0),w(k1),...,w(kn−1),那么对于基于这n个结点作为叶结点的二叉树T,定义
∑
i
=
0
n
−
1
w
(
k
i
)
λ
k
i
\sum_{i=0}^{n-1}w(k_i)\lambda_{k_i}
i=0∑n−1w(ki)λki为T的加权外部路径长度,其中
λ
k
i
\lambda_{k_i}
λki是从根结点到达叶结点的树枝长度(外部路径长度)
例如下面这棵二叉树的加权外部路径长度就是141,而接下来我们希望做到的事情,就是求出包含k0~k4这五个结点的加权外部路径长度最小的二叉树

#2.Huffman算法
Huffman于1952年在A Method for the Construction of Minimum-Redundancy Codes这篇文章中提出了Huffman算法,用于构建具有最小加权外部路径长度的二叉树
算法的具体内容如下:对于n个结点的序列
F
=
k
0
,
k
1
,
.
.
.
,
k
n
−
1
F=k_0,k_1,...,k_{n-1}
F=k0,k1,...,kn−1,它们的权重分别为
w
(
k
0
)
,
w
(
k
1
)
,
.
.
.
,
w
(
k
n
−
1
)
w(k_0), w(k_1),...,w(k_{n-1})
w(k0),w(k1),...,w(kn−1),设
A
=
F
,
m
=
n
A=F,m=n
A=F,m=n,对
t
=
1
,
2
,
.
.
.
n
−
1
t=1,2,...n-1
t=1,2,...n−1执行:设
A
=
a
0
,
a
1
,
.
.
.
,
a
m
−
1
A=a_0,a_1,...,a_{m-1}
A=a0,a1,...,am−1,A中的结点都是已形成的子树的根。如果
a
i
a_i
ai和
a
j
a_j
aj分别是A中权最小的两个结点,那么用具有权
w
(
b
t
)
=
w
(
a
i
)
+
w
(
a
j
)
w(b_t)=w(a_i)+w(a_j)
w(bt)=w(ai)+w(aj)的新结点
b
t
b_t
bt和
a
i
a_i
ai,
a
j
a_j
aj形成新的子树(其中
b
t
b_t
bt是新子树的根结点)。然后,从A中删去
a
i
a_i
ai和
a
j
a_j
aj,并把
b
t
b_t
bt作为A的最后一个结点,m减一
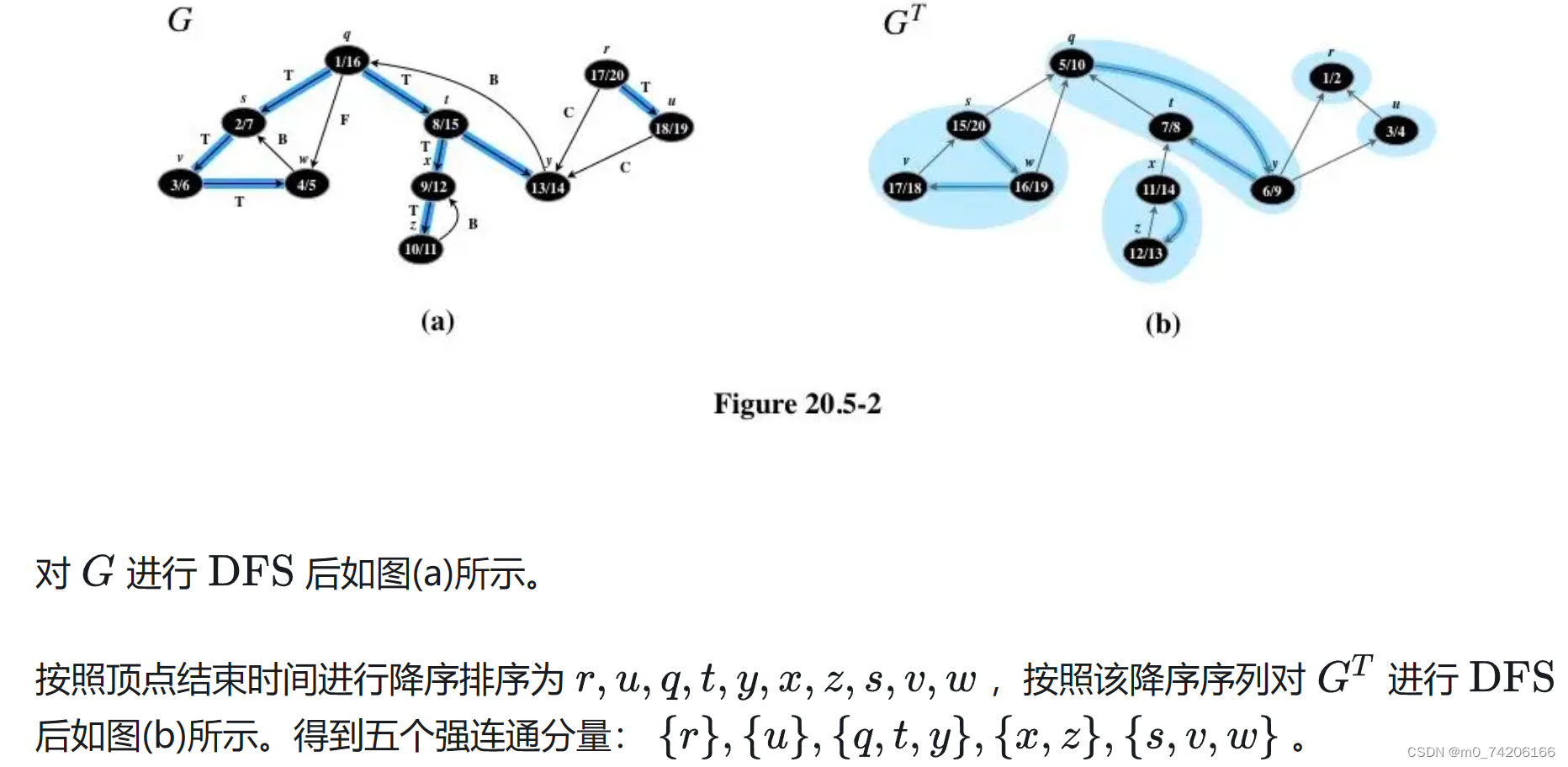
一直循环以上操作,直到A中仅剩下一个结点,则Huffman树构建完毕,得到的结点为这棵树的根,这棵树满足加权外部路径长度最小,例如对于五个结点:10,5,20,10,18,你可以尝试一下以上的算法
首先我们取出最小的两个结点5和10,构造一个新的结点
b
1
(
15
)
b_1(15)
b1(15),放回其中,现在结点序列变成了20,10,18,
b
1
(
15
)
b_1(15)
b1(15),再取出两个最小的结点
b
1
(
15
)
b_1(15)
b1(15)和10,构造一个新的结点
b
2
(
25
)
b_2(25)
b2(25),再放回去,序列变成了20, 18,
b
2
(
25
)
b_2(25)
b2(25),这时候再取出最小的18和20构造结点
b
3
(
38
)
b_3(38)
b3(38),再放回,序列为
b
2
(
25
)
,
b
3
(
38
)
b_2(25), b_3(38)
b2(25),b3(38),最后取出两个结点构造整棵树的根
b
4
(
63
)
b_4(63)
b4(63),如此一来就构造除了我们的这棵Huffman树,它的一个形态如下:

哎呀,正好就是我们上面放的那张图,所以这样你应该就明白了吧?
#3.Huffman编码
对于一棵树,如果定义向左为0,向右为1,则对于每一个叶结点都可以得到一个唯一的编码,这些编码是不等长的,但是只要所有作为编码主体的结点都是叶结点,它们就不可能是另一个叶结点的前缀,例如上面的这棵树,其中的 k 1 k_1 k1编码为010,而 k 0 k_0 k0编码为011,所有其他的结点均不可能在顺着读取的情况下出现二义性,这给了我们一些启示:如果等长编码占据的空间太大,我们是不是可以用非等长编码来完成对一个文本的存储呢?
我们可以把这个问题抽象一下,对于一个全英文的文件,我们首先读取所有的字符的出现频次,以频次作为权重,构建一棵Huffman树,然后按照上面说的编码方式对每个叶结点进行编码,这样一来,问题就变成了:能不能在已知字符频次的情况下,求出一个能够使出现频次多的字符编码尽可能短,而出现频次少的字符编码可以更长的编码方式呢?
诶,这不正好就是Huffman树做的事情吗?Huffman树保证了这棵树的加权外部路径是最小的,我们只要利用这个编码就可以得到一个比较好的编码了,并且所有结点都是叶结点还可以保证不会出现某个字符的编码是另一个字符的前缀这种可能导致编码出现二义性的问题,这就是Huffman编码,我们对字符赋予频次/频率作为权重,构建一棵Huffman树,这样最后就能对每个字符给出唯一的编码
这里给出OI-Wiki的一段基于C语言实现的构建Huffman树的代码,因为算法的步骤是不断将小树合并,因此会出现森林,森林就是多棵树构成的集合:
typedef struct HNode
{
int weight;
HNode *lchild, *rchild;
} * Htree;
Htree createHuffmanTree(int arr[], int n)
{
Htree forest[N];
Htree root = NULL;
for (int i = 0; i < n; i++) { // 将所有点存入森林
Htree temp;
temp = (Htree)malloc(sizeof(HNode));
temp->weight = arr[i];
temp->lchild = temp->rchild = NULL;
forest[i] = temp;
}
for (int i = 1; i < n; i++) { // n-1 次循环建哈夫曼树
int minn = -1, minnSub; // minn 为最小值树根下标,minnsub 为次小值树根下标
for (int j = 0; j < n; j++) {
if (forest[j] != NULL && minn == -1) {
minn = j;
continue;
}
if (forest[j] != NULL) {
minnSub = j;
break;
}
}
for (int j = minnSub; j < n; j++) { // 根据 minn 与 minnSub 赋值
if (forest[j] != NULL) {
if (forest[j]->weight < forest[minn]->weight) {
minnSub = minn;
minn = j;
}
else if (forest[j]->weight < forest[minnSub]->weight) {
minnSub = j;
}
}
}
// 建新树
root = (Htree)malloc(sizeof(HNode));
root->weight = forest[minn]->weight + forest[minnSub]->weight;
root->lchild = forest[minn];
root->rchild = forest[minnSub];
forest[minn] = root; // 指向新树的指针赋给 minn 位置
forest[minnSub] = NULL; // minnSub 位置为空
}
return root;
}
(2).二叉搜索树
#1.基本定义
我们在前面的线性表就提过搜索的问题,对于一个有序的序列,我们可以使用二分搜索的方式来加速查找过程,把时间复杂度从线性查找的 O ( n ) O(n) O(n)变成 O ( log n ) O(\log n) O(logn),但是这有一个问题:如果我们在序列中插入一系列无序的新元素,我们想要再次进行查找,要么就要对这个序列进行排序,而基于比较的内部排序的时间复杂度上限是 Θ ( n log n ) \Theta(n\log n) Θ(nlogn),这就比线性查找还要慢了,所以能不能有一个办法,让我们的序列始终保持有序,同时还能保证无论如何插入元素之后都是 O ( log n ) O(\log n) O(logn)的查找时间复杂度呢?
聪明的计算机科学家想出了这样一个办法,我们把二分搜索的过程具象化:二分查找每次在查找的过程当中,我们每次比较区间中间的值,如果比中间值小,就往左搜索,反之则往右边搜索,这听起来好像可以构成一棵二叉树
假设我们给这种二叉树定义成这个形式:对于一个结点,它的左子树要么为空,要么所有结点值都比该结点小,右子树同理,要么为空,要么所有结点值都比该结点大,并且,左子树和右子树也必须都满足这个性质,那么对于这样一棵树,我们每次只要比较结点就可以排除掉比较大的一个范围,在理想状况下,每次可以排除一半,它的效率就跟二分搜索差不多了!是 O ( log n ) O(\log n) O(logn),这真的很不错啊!
#2.查找
所以我们先不考虑怎么构建这棵树,我们先来看看对于一个已经构建好的二叉搜索树,怎么进行查找呢?假设查找的结点存在返回指针,不存在则返回空指针,那我们可以比较轻松地写出下面的代码:
struct TreeNode
{
int val;
TreeNode* left;
TreeNode* right;
}; // 结点定义
TreeNode* search(TreeNode* root, int val)
{
if (!root) return nullptr;
if (val < root->val) return search(root->left, val);
else if (val > root->val) return search(root->right, val);
else return root;
}
你看,递归定义的树总是有一个好处:我们可以很轻松地写出递归函数来完成树的各种操作,在这里这串代码我其实不需要过多解释你应该也能明白它在干什么了,对吧?
#3.插入结点
要插入结点,首先要知道这个结点是否存在,我们一般认为二叉搜索树不允许有重复的结点,所以此时如果待插入的值已经存在于树中,我们就不插入,否则就插入到对应的位置上去,而已经构建好的二叉搜索树的所有结点是不会改变本来的位置的,所以这个插入其实也不难写,一样采用递归的方式完成就好了:
TreeNode* insert(TreeNode* root, int val)
{
if (!root) return new TreeNode{ val, nullptr, nullptr };
if (val < root->val) {
root->left = insert(root->left, val);
}
else if (val > root->val) {
root->right = insert(root->right, val);
}
return root;
}
对于不空的情况下我们一直采取递归的方式查找到能够供这个结点插入的空的位置,这样就可以完成整个插入过程了
#4.构建树
只要插入结点写完,我们就可以写构建树的过程了,你看,我们只要一直向一棵树中插入结点即可:
TreeNode* buildTree(const vector<int>& vec)
{
if (!vec.empty()) {
TreeNode* tree{ nullptr };
tree = insert(tree, vec[0]);
for (int i = 1; i < vec.size(); i++) {
insert(tree, vec[i]);
}
return tree;
}
return nullptr;
}
这里再顺便写一个能够在不同行打印出不同层的层序遍历:
void levelOrderTraversal(const TreeNode* root)
{
queue<const TreeNode*> q;
if (root) {
q.push(root);
while (!q.empty()) {
queue<const TreeNode*> tmp;
while (!q.empty()) {
auto t = q.front();
q.pop();
cout << t->val << " ";
if (t->left) tmp.push(t->left);
if (t->right) tmp.push(t->right);
}
cout << endl;
q = tmp;
}
}
}
在建树结束之后,我们就来尝试一下吧:
int main()
{
vector<int> a;
for (int i = 0; i < 50; i++) {
a.push_back(rand() % 1000);
}
TreeNode* root = buildTree(a);
levelOrderTraversal(root);
return 0;
}

#5.查找最小值和最大值
这你肯定一下就想明白了,最大值就是最右的结点,最小值就是最左的结点:
int findMin(const TreeNode* root)
{
if (!root) return -1;
while (root->left) {
root = root->left;
}
return root->val;
}
int findMax(const TreeNode* root)
{
if (!root) return -1;
while (root->right) {
root = root->right;
}
return root->val;
}
#6.删除结点
删除其实就是一个比较麻烦的问题了,假设删除的是叶结点,那么直接删掉即可,这个比较简单,因为毕竟它没有左右子树;如果是只有左子树或者右子树的也好说,我们只要把左子树或者右子树直接替换掉当前结点即可;但如果是左右子树都有,那么问题就会比较麻烦了,这时候我们一般用左子树的最大值或右子树的最小值替换掉当前结点,这里代码采取右子树的最小值替换:
TreeNode* findMinNode(TreeNode* root)
{
while (root->left) {
root = root->left;
}
return root;
}
TreeNode* remove(TreeNode* root, int val)
{
if (!root) return root;
if (val < root->val) {
root->left = remove(root->left, val);
}
else if (val > root->val) {
root->right = remove(root->right, val);
}
else {
if (!root->left) {
TreeNode* tmp = root->right;
delete root;
return tmp;
}
else if (!root->right) {
TreeNode* tmp = root->left;
delete root;
return tmp;
}
else {
TreeNode* successor = findMinNode(root->right);
root->val = successor->val;
root->right = remove(root->right, successor->val);
}
}
return root;
}
#7.一个问题
你应该发现了,这么构建出的二叉搜索树,好像可能发生比较大的偏移,比如这个序列:0, 1, 2, 3, 4, 5, 6,构建出来的树长这样:

糟了,这下树直接退化成了链表,我们的查找效率从最优的
O
(
log
n
)
O(\log n)
O(logn)直接退化到了
O
(
n
)
O(n)
O(n),那有没有什么办法能解决这个问题呢?确实有,平衡搜索树就是一种比较严格的解决这个问题的方法
(3).平衡搜索树
#1.满二叉树、完全二叉树和丰满二叉树
满二叉树和完全二叉树我之前貌似在堆那里提过,如果结点正好填满整棵二叉树,则这棵树是满二叉树,如果除了最后一层,所有结点都填满,最后一层的所有结点都从最左向右依次排布,编号没有发生超过1的跳变,这时候我们就认为这棵树是完全二叉树,而丰满二叉树则是对完全二叉树进行了要求的放宽,丰满二叉树的最后一层结点可以随意排布
#2.平衡因子和平衡树
对于二叉树T某个结点k,我们定义k的左子树
T
k
l
T_{k_l}
Tkl和右子树
T
k
r
T_{k_r}
Tkr的高度差为结点k的平衡因子
当二叉树T中每个结点k的平衡因子绝对值都小于等于1时(即左子树和右子树的高度差最大为1),称树T是一棵平衡树
所以简单思考一下,平衡树是在尽可能满足丰满树的要求,只要我们的查询序列分布越均匀,通过二叉搜索树进行查找的效率就会越高,所以,如果T即是查找树,又是平衡树,那么树T就是平衡查找树,又称AVL树
可以证明,n个结点的平衡树的数值最大长度小于 3 2 log 2 n \frac{3}{2}\log_2n 23log2n,因此平衡查找树的查找效率相当高
#3.左旋与右旋
对于AVL树,我们定义结点的左旋和右旋两种操作(图源:OI-Wiki):
首先是对T右旋,这时候将L作为根节点,L的右子树作为T的左子树,T作为L的右子树

然后是对T左旋,这时候将R作为根节点,R的左子树作为T的右子树,T作为R的左子树

有了左旋和右旋两个方法之后,我们就可以应对AVL树中各种不平衡的问题了
#4.平衡调整方法
平衡的调整过程遵循最小被破坏原则,我们只调整在插入或删除后第一个不平衡的结点,因此我们可以把平衡被破坏的情况总结为四种:LL,RR,LR和RL型,分别是左子树的左子树,右子树的右子树,左子树的右子树和右子树的左子树过长导致的结点不平衡,对于LL和RR两种,你发现上面的左旋和右旋操作只要做一次就可以把树调整到平衡了,所以这里我们只需要介绍一下LR和RL的调整方法即可
对于LR型,我们首先对L做一次左旋操作,这时候这三个结点的不平衡情况就变成了LL型,再对T进行一次右旋操作即可:

同理,对于RL型,我们首先对R做一次右旋操作,然后不平衡情况就变成了RR型,这时候再对T进行一次左旋操作即可:

所以你发现,AVL树的平衡调整其实并不困难,只要组合左旋和右旋操作即可,不过探索不平衡结点其实不是一件很容易的事情,你需要在回溯双亲结点的同时进行路径记忆,否则可能会显著增大程序的时间复杂度
#5.缺陷
AVL树的旋转操作实在是太多了!如果我们插入的序列是精心构造过的,有可能在第三个之后的每个结点插入之后都要对树进行旋转操作,而这个过程还要伴随大量的结点回溯操作,这样时间复杂度显然比较高,当然,这样构建的树查找效率非常高。因此后来的人们在AVL树的基础上提出了红黑树,对平衡因子的严格要求进行了放宽,不过红黑树的实现非常困难,在这里就不展开了
小结
其实这一节我还打算讲一讲外部排序、红黑树和B树的,但是这仨实在是有点难度,我打算在这学期之后单独出三篇博客来单独介绍三种数据结构,那么树的内容到这里就结束了,下一篇我们就要进入图的内容了,其实图的内容没有那么困难,只要遵循一些基本的思考方式即可








![[大厂实践] Chick-fil-A的服务API流程实践](https://img-blog.csdnimg.cn/img_convert/206f502e73c8c4186536855a2f275fa2.png)