了解如何在不向提供商公开您的私人数据的情况下训练您自己的语言模型
使用OpenAI的ChatGPT等公共人工智能服务的主要担忧之一是将您的私人数据暴露给提供商的风险。对于商业用途,这仍然是考虑采用人工智能技术的公司最大的担忧。
很多时候,你想创建自己的语言模型,根据你的数据集(如销售见解、客户反馈等)进行训练,但同时你不想将所有这些敏感数据暴露给OpenAI等人工智能提供商。因此,理想的方法是在本地训练自己的LLM,而无需将数据上传到云。
如果你的数据是公开的,并且你不介意将它们暴露给ChatGPT,我有另一篇文章展示了如何将ChatGPT与你自己的数据连接起来:
-
Connecting ChatGPT with Your Own Data using LlamaIndex
-
Learn how to create your own chatbot for your business
-
levelup.gitconnected.com
在这篇文章中,我将向您展示如何使用一个名为privateGPT的开源项目来利用LLM,这样它就可以根据您的自定义训练数据回答问题(如ChatGPT),而不会牺牲数据的隐私。
需要注意的是,privateGPT目前只是一个概念验证,尚未做好生产准备。
正在下载私有GPT
要试用privateGPT,您可以使用以下链接转到GitHub:https://github.com/imartinez/privateGPT.
您可以单击“代码|下载ZIP”按钮下载存储库:
或者,如果您的系统上安装了git,请在终端中使用以下命令克隆存储库:
$ git clone https://github.com/imartinez/privateGPT
无论哪种情况,一旦将存储库下载到您的计算机上,privateGPT目录应具有以下文件和文件夹:
安装所需的Python包
privateGPT使用许多Python包。它们封装在requirements.txt文件中:
langchain==0.0.171 pygpt4all==1.1.0 chromadb==0.3.23 llama-cpp-python==0.1.50 urllib3==2.0.2 pdfminer.six==20221105 python-dotenv==1.0.0 unstructured==0.6.6 extract-msg==0.41.1 tabulate==0.9.0 pandoc==2.3 pypandoc==1.11
安装它们最简单的方法是使用pip:
$ cd privateGPT $ pip install -r requirements.txt
根据我的实验,在执行上述安装时,可能无法安装某些必需的Python包。稍后当您尝试运行intake.py或privateGPT.py文件时,您就会知道这一点。在这种情况下,只需单独安装丢失的软件包即可。
编辑环境文件
example.env文件包含privateGPT使用的几个设置。内容如下:
PERSIST_DIRECTORY=db MODEL_TYPE=GPT4All MODEL_PATH=models/ggml-gpt4all-j-v1.3-groovy.bin EMBEDDINGS_MODEL_NAME=all-MiniLM-L6-v2 MODEL_N_CTX=1000
- PERSIST_DIRECTORY-加载和处理文档后将保存本地矢量存储的目录
- MODEL_TYPE-您正在使用的模型的类型。在这里,它被设置为GPT4All(由OpenAI提供的ChatGPT的免费开源替代方案)。
- MODEL_PATH—LLM所在的路径。在这里,它被设置为models目录,使用的模型是ggml-gpt4all-j-v1.3-groovy.bin(您将在下一节中了解该模型的下载位置)
- EMBEDDINGS_MODEL_NAME-这是指变压器模型的名称。在这里,它被设置为全MiniLM-L6-v2,它将句子和段落映射到384维的密集向量空间,并可用于聚类或语义搜索等任务。
- MODEL_N_CTX-嵌入和LLM模型的最大令牌限制
将example.env重命名为.env。
完成此操作后,.env文件将变为隐藏文件。
下载模型
为了使私有GPT工作,它需要预先训练模型(LLM)。由于privateGPT正在使用GPT4All,您可以从以下位置下载LLM:https://gpt4all.io/index.html:
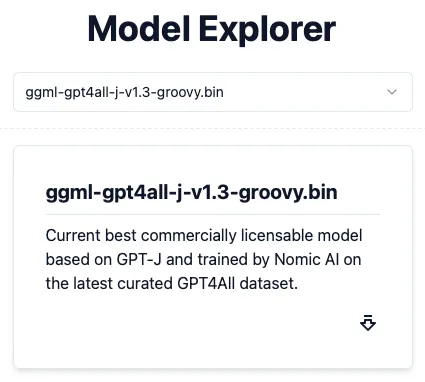
由于默认环境文件指定了ggml-gpt4all-j-v1.3-groovy.bin LLM,因此下载第一个模型,然后在privateGPT文件夹中创建一个名为models的新文件夹。将ggml-gpt4all-j-v1.3-groovy.bin文件放入models文件夹中:
准备您的数据
如果您查看intect.py文件,您会注意到以下代码片段:
".csv": (CSVLoader, {}),
# ".docx": (Docx2txtLoader, {}),
".doc": (UnstructuredWordDocumentLoader, {}),
".docx": (UnstructuredWordDocumentLoader, {}),
".enex": (EverNoteLoader, {}),
".eml": (UnstructuredEmailLoader, {}),
".epub": (UnstructuredEPubLoader, {}),
".html": (UnstructuredHTMLLoader, {}),
".md": (UnstructuredMarkdownLoader, {}),
".odt": (UnstructuredODTLoader, {}),
".pdf": (PDFMinerLoader, {}),
".ppt": (UnstructuredPowerPointLoader, {}),
".pptx": (UnstructuredPowerPointLoader, {}),
".txt": (TextLoader, {"encoding": "utf8"}),
这意味着privateGPT能够支持以下文档类型:
.csv: CSV.doc: Word Document.docx: Word Document.enex: EverNote.eml: Email.epub: EPub.html: HTML File.md: Markdown.odt: Open Document Text.pdf: Portable Document Format (PDF).ppt: PowerPoint Document.pptx: PowerPoint Document.txt: Text file (UTF-8)
每种类型的文档都由相应的文档加载器指定。例如,您可以使用UnstructuredWordDocumentLoader类来加载.doc和.docx Word文档。
默认情况下,privateGPT附带位于source_documents文件夹中的state_of_the_union.txt文件。我将删除它,并用一份名为Singapore.pdf的文件取而代之。

This document was created from https://en.wikipedia.org/wiki/Singapore. You can download any page from Wikipedia as a PDF document by clicking Tools | Download as PDF:

您可以将privateGPT支持的任何文档放入source_documents文件夹。以我为例,我只放了一份文件。
为文档创建嵌入
一旦文档就位,就可以为文档创建嵌入了。
创建嵌入是指为单词、句子或其他文本单元生成向量表示的过程。这些向量表示捕获了有关文本的语义和句法信息,使机器能够更有效地理解和处理自然语言。
在终端中键入以下内容(在privateGPT文件夹中提供了摄取.py文件):
$ python ingest.py
根据您使用的机器和您放入source_documents文件夹中的文档数量,嵌入处理可能需要相当长的时间才能完成。
完成后,您将看到以下内容:
Loading documents from source_documents Loaded 1 documents from source_documents Split into 692 chunks of text (max. 500 characters each) Using embedded DuckDB with persistence: data will be stored in: db
嵌入以Chroma db的形式保存在db文件夹中:
Chroma是开源嵌入数据库。
提出问题
您现在可以提问了!在“终端”中键入以下命令:
$ python privateGPT.py
加载模型需要一段时间。在此过程中,您将看到以下内容:
Using embedded DuckDB with persistence: data will be stored in: db gptj_model_load: loading model from 'models/ggml-gpt4all-j-v1.3-groovy.bin' - please wait ... gptj_model_load: n_vocab = 50400 gptj_model_load: n_ctx = 2048 gptj_model_load: n_embd = 4096 gptj_model_load: n_head = 16 gptj_model_load: n_layer = 28 gptj_model_load: n_rot = 64 gptj_model_load: f16 = 2 gptj_model_load: ggml ctx size = 4505.45 MB gptj_model_load: memory_size = 896.00 MB, n_mem = 57344 gptj_model_load: ................................... done gptj_model_load: model size = 3609.38 MB / num tensors = 285 Enter a query:
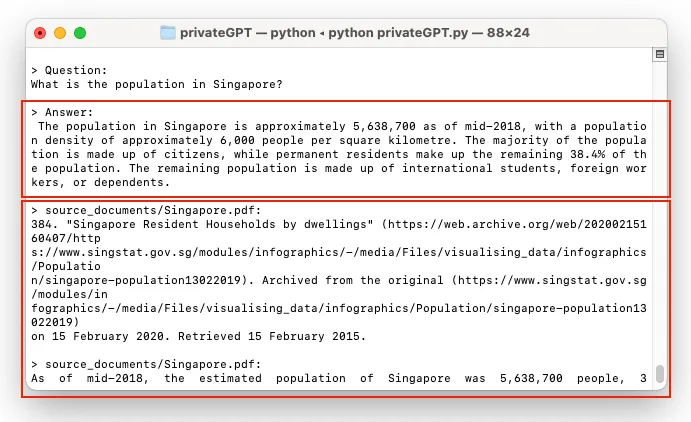
在提示下,你可以输入你的问题。我问:“新加坡的人口是多少?”。私人GPT花了很长时间才得出答案。一旦它找到了答案,它就会给你答案,并引用答案的来源:
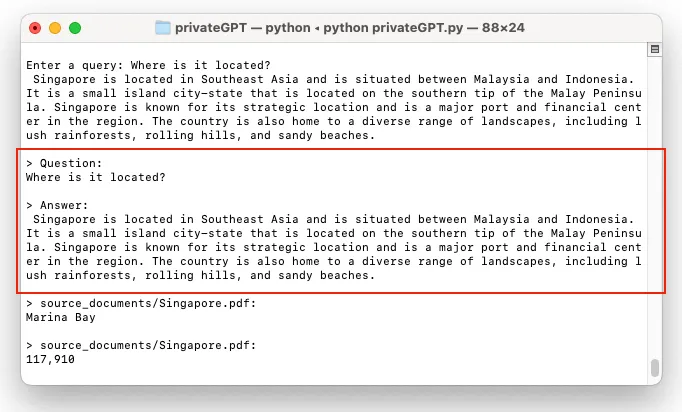
您可以继续询问后续问题:
总结
虽然privateGPT目前是一个概念验证,但它看起来很有前景,然而,它还没有准备好生产。有几个问题:
- 推理缓慢。执行文本嵌入需要一段时间,但这是可以接受的,因为这是一次性过程。然而,推理是缓慢的,尤其是在速度较慢的机器上。我用了一台32GB内存的M1 Mac,但还是花了一段时间才找到答案。
- 内存猪。privateGPT使用大量内存,在问了一两个问题后,我会得到一个内存不足的错误,如下所示:
segmentation fault python privateGPT.py. /Users/weimenglee/miniforge3/lib/python3.10/multiprocessing/resource_tracker.py:224: UserWarning: resource_tracker: There appear to be 1 leaked semaphore objects to clean up at shutdown. warnings.warn(‘resource_tracker: There appear to be %d ‘
在privateGPT的作者解决上述两个问题之前,privateGPT仍然是一个实验,看看如何在不将私人数据暴露给云的情况下训练LLM。
文章链接
【privateGPT】使用privateGPT训练您自己的LLM | 开发者开聊
自我介绍
- 做一个简单介绍,酒研年近48 ,有20多年IT工作经历,目前在一家500强做企业架构.因为工作需要,另外也因为兴趣涉猎比较广,为了自己学习建立了三个博客,分别是【全球IT瞭望】,【架构师研究会】和【开发者开聊】,有更多的内容分享,谢谢大家收藏。
- 企业架构师需要比较广泛的知识面,了解一个企业的整体的业务,应用,技术,数据,治理和合规。之前4年主要负责企业整体的技术规划,标准的建立和项目治理。最近一年主要负责数据,涉及到数据平台,数据战略,数据分析,数据建模,数据治理,还涉及到数据主权,隐私保护和数据经济。 因为需要,比如数据资源入财务报表,另外数据如何估值和货币化需要财务和金融方面的知识,最近在学习财务,金融和法律。打算先备考CPA,然后CFA,如果可能也想学习法律,备战律考。
- 欢迎爱学习的同学朋友关注,也欢迎大家交流。全网同号【架构师研究会】

欢迎收藏 【全球IT瞭望】,【架构师酒馆】和【开发者开聊】.