Ubuntu22.04系统安装软件、显卡驱动、cuda、cudnn、pytorch
- 安装 Nvidia 显卡驱动
- 安装 CUDA
- 安装 cuDNN
- 安装 VSCode
- 安装 Anaconda 并更换源
- 在虚拟环境中安装 GPU 版本的 PyTorch
- Reference
这篇博文主要介绍的是 Ubuntu22.04 系统中软件、显卡驱动、cuda、cudnn、pytorch 等软件和环境的安装和配置,在上一篇博文 Ubuntu22.04 双系统安装、配置及常用设置 中介绍了 Ubuntu22.04 双系统的安装、配置、终端常用操作的快捷键以及一些常用设置(如同步时间、更改启动默认项、添加右击新建文件选项、创建桌面快捷方式等),有需要的可自行点击链接查看。
安装 Nvidia 显卡驱动
本节按照 【超详细】【ubunbu 22.04】 手把手教你安装nvidia驱动,有手就行,隔壁家的老太太都能安装的教程安装的。
-
在 英伟达官网 根据选择自己的显卡型号->Search->下载相应的驱动(博主选择的是第一个,大家可以自行下载相应的驱动)NVIDIA-Linux-x86_64-535.146.02.run ,然后复制到
主目录(用户目录)下(避免路径中出现中文)。

-
在终端输入以下命令,更新软件列表并安装一些必要的软件、依赖。
# 更新软件列表 sudo apt-get update # 安装g++ sudo apt-get install g++ # 安装gcc sudo apt-get install gcc # 安装make sudo apt-get install make -
禁用默认驱动
安装 NVIDIA 驱动之前需要禁止系统自带显卡驱动 nouveau,在终端输入下面命令打开 blacklist.conf 文件。sudo gedit /etc/modprobe.d/blacklist.conf在打开的 blacklist.conf 文件末尾输入以下两行代码并保存,然后关闭:
blacklist nouveau options nouveau modeset=0之后更新一下系统的 initramfs 镜像文件,并在终端中输入:
sudo update-initramfs -u完成以上步骤后,重启电脑。然后在终端中输入下面的命令,如果没有输出的话就说明禁用了 nouveau。
lsmod | grep nouveau -
进入 tty 模式
进入 tty 模式就关闭了图形界面进入命令行模式,因此后续安装推荐使用其他设备阅读该教程进行安装。
在终端输入下面的命令进入 tty 模式,此时会进入全黑的命令行界面。sudo telinit 3(在 tty 模式下输入
sudo telinit 3命令可以重新打开图形界面)
进入 tty 模式后,需要输入用户名和密码进行登录,对于一些字符可能显示的为白色菱形可能是编码格式的问题不用管。 -
安装驱动
步骤1 已经将下载后的驱动文件放在了主目录(用户目录),因此在 tty 模式的终端中进入主目录(用户目录),通过ls命令查看目录中是否存在下载的 NVIDIA 驱动文件(NVIDIA-Linux-x86_64-535.146.02.run),之后通过下面的命令进行安装即可。# 给下载的驱动赋予可执行权限 sudo chmod 777 NVIDIA-Linux-x86_64-535.146.02.run # 安装 # -no-opengl-files:只安装驱动文件,不安装OpenGL文件 # -no-x-check:安装驱动时关闭X服务,不设置可能导致安装失败。 sudo ./NVIDIA-Linux-x86_64-535.146.02.run –no-opengl-files -no-x-check安装时会出现以下几个选择界面:
- An alternate method of installing the NVIDIA driver was detected. (This is usually a package provided by your distributor.) A driver installed via that method may integrate better with your system than a driver installed by nvidia-installer.
Please review the message provided by the maintainer of this alternate installation method and decide how to proceed:
选择 Continue installation - 在 Install NVIDIA’s 32-bit compatibility libraries?
选择 No - Would you like to run the nvidia-xconfig utility to automatically update your X configuration file so that the NVIDIA X driver dill be used dhen you restart X? Any pre-existing X configuration file will be backed up.
选择 Yes - Your x configuration file has been successfully updated. Installation of the NVIDIA Accelerated Graphics Driver for Linux-x86_64 (version 535.146.02) is now complete.
选择 Ok
- An alternate method of installing the NVIDIA driver was detected. (This is usually a package provided by your distributor.) A driver installed via that method may integrate better with your system than a driver installed by nvidia-installer.
-
安装完成后,返回图形界面并进行验证
输入下面的命令,再次启动图形界面。sudo service gdm3 start进入图形化界面后,打开终端(Ctrl+Alt+T),并输入下面的命令打印出显卡信息则说明安装成功了。
nvidia-smi
如果安装失败的话或者之后想卸载显卡驱动的,可通过如下的命令卸载显卡驱动。
sudo apt-get remove --purge nvidia*
安装 CUDA
本节按照 ubuntu系统安装CUDA和CUDNN(CUDA安装) 安装的 CUDA。CUDA 官方下载链接为 CUDA Toolkit Archive
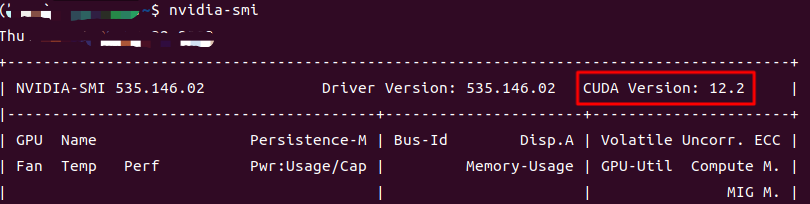
注意:通过显卡驱动的nvidia-smi命令,可以看到自己显卡所支持的最高 CUDA 版本,安装 CUDA 时需要注意安装的 CUDA 版本号不能高于这里显示的最高版本号。
注意:本节安装的 CUDA 版本号决定了后续要安装的 PyTorch 的版本号,详情可参见后面博文在虚拟环境中安装 GPU 版本的 PyTorch部分。
-
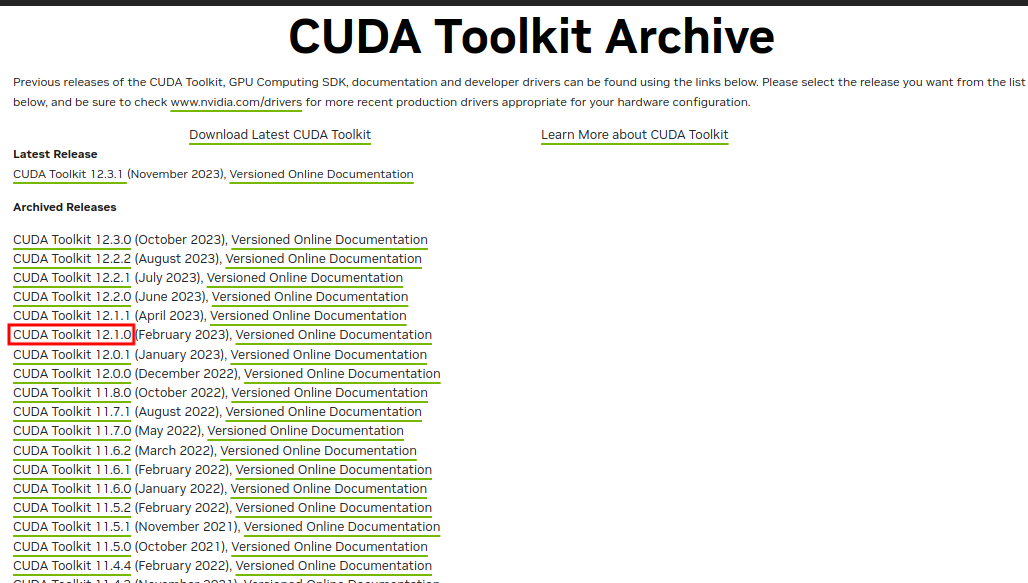
在 CUDA官网 CUDA Toolkit Archive 找到自己要下载的 CUDA 的版本号(通过
nvidia-smi命令显示的是12.2,因此需要选择不高于12.2的版本,博主选择的是12.1),然后点击进入下载页面。
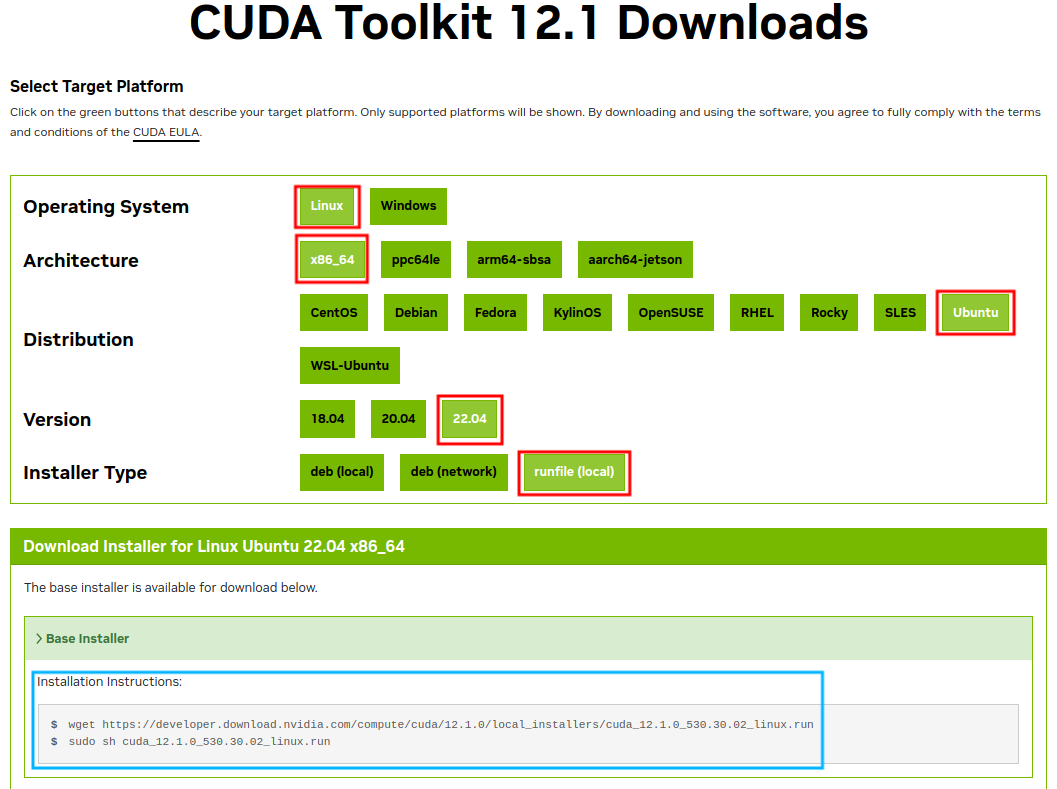
 在下载页面,根据需要(红色框)选择相应的版本,然后最下方(蓝色框内)就会出现安装命令。
在下载页面,根据需要(红色框)选择相应的版本,然后最下方(蓝色框内)就会出现安装命令。
-
根据上述下载命令,安装 CUDA
打开终端,依次执行下面的命令即可安装。# 下载CUDA,需要几分钟的时间 wget https://developer.download.nvidia.com/compute/cuda/12.1.0/local_installers/cuda_12.1.0_530.30.02_linux.run # 安装下载好的CUDA sudo sh cuda_12.1.0_530.30.02_linux.run安装时会出现以下几个选择界面:
Do you accept the above CUDA?(accepted/decline/quit):
输入 accept 按下回车
在 CUDA Installer 页面,在第一行 Driver 上按下空格取消驱动的安装(因为之前的步骤已经手动安装过驱动了),然后按下方向键下键到 Install 行按下回车即可安装。 -
添加环境变量
# 打开终端 # 通过gedit编辑器打开.bashrc文件 gedit ~/.bashrc # 在该文件的最后添加下面两行 # `注意:下面两行命令的cuda-x.x需要根据自己安装的版本号进行修改,如博主安装的是12.1版本,所以下面两行修改为cuda-12.1` export PATH=/usr/local/cuda-12.1/bin:${PATH} export LD_LIBRARY_PATH=/usr/local/cuda-12.1/lib64:${LD_LIBRARY_PATH} # 使得修改后的环境变量生效 source ~/.bashrc -
验证 CUDA 是否安装成功
在终端中输入下面的命令查看 CUDA 的版本号,出现版本号就表示安装成了。# 下面的两条命令均可以查看当前安装的CUDA的版本号,选择其中一条尝试即可 nvcc --version # 或者 nvcc -V
安装 cuDNN
本节按照 手把手教你安装双系统 windows11+ubuntu 22.04(2)配置基础的深度学习环境 安装 Linux x86_64 (Tar) 的 cuDNN。
- 下载 cuDNN 安装包
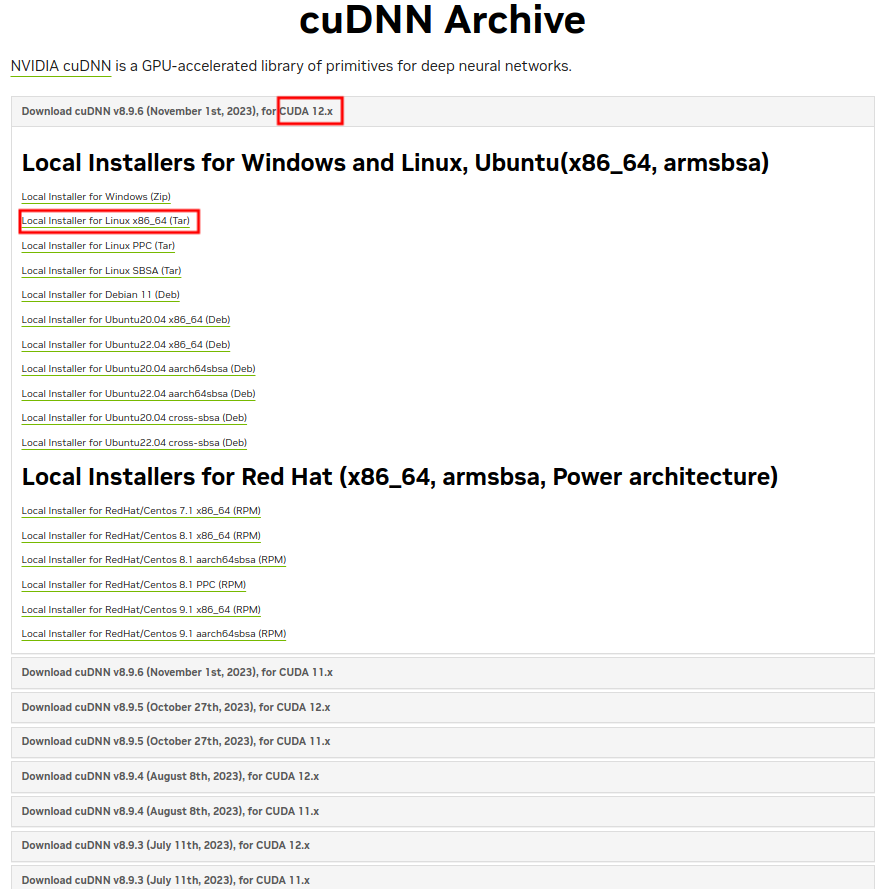
根据上面安装的 CUDA 版本 在 cuDNN 官网 cuDNN Archive 选择相应的 CUDA 版本 for 12.x (之前博主安装的 CUDA 版本是 12.1),然后下载 Tar 类型的 cuDNN 安装包(cudnn-linux-x86_64-8.9.6.50_cuda12-archive.tar.xz),并复制到主目录(用户目录下)。
- 安装
打开 cuDNN 的官方安装教程 Installation Guide (PDF),可参照它进行安装,其中的.tar 类型的适合所有的Linux系统,.deb 类型的适用于Debian 11, Ubuntu 18.04, Ubuntu 20.04, and 22.04等系统。(官方文档的解释:1.3. Installing on Linux. The following steps describe how to build a cuDNN dependent program. Choose the installation method that meets your environment needs. For example, the tar file installation applies to all Linux platforms. The Debian package installation applies to Debian 11, Ubuntu 18.04, Ubuntu 20.04, and 22.04. The RPM package installation applies to RHEL7, RHEL8, and RHEL9. )
按照教程的 1.3.1 Tar File Installation 部分的安装教程,通过下面的命令进行解压和安装已经下载的安装包 cudnn-linux-x86_64-8.9.6.50_cuda12-archive.tar.xz ,具体过程如下:# 解压下载的cuDNN压缩包,官方命令为tar -xvf cudnn-linux-$arch-8.x.x.x_cudaX.Y-archive.tar.xz # `将官方命令根据自己下载的cuDNN版本号进行修改cudnn-linux-x86_64-8.9.6.50_cuda12-archive.tar.xz` tar -xvf cudnn-linux-x86_64-8.9.6.50_cuda12-archive.tar.xz # 分别将解压的文件复制到相应目录 sudo cp cudnn-*-archive/include/cudnn*.h /usr/local/cuda/include sudo cp -P cudnn-*-archive/lib/libcudnn* /usr/local/cuda/lib64 sudo chmod a+r /usr/local/cuda/include/cudnn*.h /usr/local/cuda/lib64/libcudnn* # 之后便可以手动删除主目录(用户目录)下解压的cuDNN文件了 - 验证
在终端输入以下命令,查看安装的 cuDNN 的版本号,如果输出相应的结果则表明安装成功。sudo cat /usr/local/cuda/include/cudnn_version.h | grep CUDNN_MAJOR -A 2
其他安装教程:
ubuntu22.04安装nvidia驱动+cuda11.7+cudnn8.6
Ubuntu 安装 GPU 驱动、CUDA、cuDNN,以及是否安装成功的检测
cuda版本与pytorch版本依赖关系 cuda8.0 pytorch
安装 VSCode
在相应软件的官网下载 Linux 的包,之后在终端进行安装。下面展示 .deb 格式的 VSCode 安装过程,其他 .deb 格式的软件安装过程类似,均使用 sudo dpkg -i XXX(你下载的安装包名).deb 进行安装。
到 VSCode 的官网 https://code.visualstudio.com/ 下载 code_1.85.1-1702462158_amd64.deb 安装包。
将安装包复制到用户目录(主目录)下,进入到终端进行安装。
# 列出当前目录下的文件,查看有无 VSCode 的安装包 code_1.85.1-1702462158_amd64.deb
ls
# 使用命令 sudo dpkg -i XXX(你下载的安装包名).deb 安装下载的安装包
sudo dpkg -i code_1.85.1-1702462158_amd64.deb
# 为VSCode安装插件:点击左侧功能窗口中的Extensions中进行扩展
# 安装汉化插件:搜索中文,点击搜索列表中Chinese(Simplified)中文简体包旁边的Install进行安装,然后重启
# 安装Python插件:搜索python,安装Python插件,用于运行和调试已有的Python程序
# 打开文件夹指定相应的python环境
# 1. 左上角文件->打开文件夹(代码文件夹),之后点信任所有文件
# 2. 随便点击一个.py文件,然后点击界面最下面右边的Python后面的版本号,如3.10.12 64-bit
# 3. 在弹出的选择解释器窗口选择对应的python解释器(可以是配好的conda虚拟环境中的python解释器)
安装 Anaconda 并更换源
本节参考 Ubuntu安装Anaconda详细步骤(Ubuntu22.04.1,Anaconda3-2023.03) 安装 Anaconda,关于 anaconda3 的下载、安装、换源和使用 进行换源。
在 清华大学开源软件镜像站 下载 Anaconda 安装包,博主下载的是 Anaconda3-2023.03-1-Linux-x86_64.sh ,并将下载的安装包复制到 (主目录)用户目录下。
# 在用户目录下打开终端,查看当前目录下的文件
ls
# 安装 anaconda
bash Anaconda3-2023.03-1-Linux-x86_64.sh
# 之后就是输入一连串的Enter,输yes,等待安装完成。
# 安装完成后在用户目录(主目录)下会生成一个anaconda3的文件夹,之后打开终端就可以看到 base 环境了
更换Anaconda的源:
(注意:更换源后在 PyTorch官网上 通过 conda 命令安装 pytorch 可能出现下面的错误,所以建议先不更换源安装 pytorch 等。
UnsatisfiableError: The following specifications were found to be incompatible with each other.
PackagesNotFoundError: The following packages are not available from current channels)
# 查看Anaconda中已存在的镜像源,第一次执行会在`主目录(用户目录)`生成一个.condarc文件
conda config --show channels
# 永久添加镜像源
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/
# 设置搜索时显示的通道地址
conda config --set show_channel_urls yes
在虚拟环境中安装 GPU 版本的 PyTorch
打开终端,使用anaconda 创建虚拟环境并安装 GPU 版本的 PyTorch 环境,PyTorch官方网址
# 创建一个名为py39的虚拟环境,并指定了python的版本为3.9
conda create --name py39 python=3.9
# 然后输入y,即可创建该虚拟环境
# 激活该虚拟环境
conda activate py39
# 根据pytorch的官方网址的命令进行安装,
# 在https://pytorch.org/选择Linux、Conda、Python以及已经安装好的CUDA版本号得到的安装命令进行安装
# 分析该命令,-c后面为安装包的源,-c pytorch表示使用官方源,可能出现速度慢等问题
conda install pytorch torchvision torchaudio pytorch-cuda=12.1 -c pytorch -c nvidia
# 之后可以使用conda或者pip命令继续安装其他包
# 安装好之后在Python中进行验证
# 在conda的虚拟环境终端,`输入python`进入该环境下的Python开发环境
import torch
# 查看pytorch的版本号(version前后各有2个_)
torch.__version__
# 查看CUDA是否可用(GPU是否可用)
# `如果下面的命令输出的结果显示为False,则安装的可能是cpu版本的pytorch,可通过下面方法进行解决`
torch.cuda.is_available()
# 查看当前使用的GPU序号
torch.cuda.current_device()
# 查看可用的GUDA数量(GPU数量)
torch.cuda.device_count()
# 查看cuda版本号
torch.version.cuda
# 查看cnDNN版本号
torch.backends.cudnn.version()
# 如果上述命令均没问题,则GPU版本的PyTorch等安装成功,退出当前的Python开发环境即可
exit()
如果使用上述 pytorch 官方命令总是安装 cpu 版本的 pytorch(通过 conda list 检查发现 pytorch 是 py3.x_cpu_0),那么可能有以下几种原因:
- 参照 下载pytorch时总是下成CPU版本的一种解决办法, 由于当前(虚拟)环境内的 python 版本过低,可以在 https://download.pytorch.org/whl/torch_stable.html 上查看对应 cuda 版本所需的 python 版本。
解决方法:创建虚拟环境时参照上述网址指定 python 版本号。 - 参照 安装pytorch-gpu时会默认安装cpu版本, 在安装 pytorch 时会默认安装一个名为 cpuonly 的库,这使 pytorch 以及 torchvision 的版本都默认为 cpu 版,即便你在安装时给出cudatoolkit 版本也无效。
解决方法:通过conda list检查是否存在 cpuonly 的库,若存在则可通过conda uninstall cpuonly卸载,此时 cpu 版本的 pytorch 会 转成 gpu 版本。若通过conda list检查发现并没有 cpuonly 库但 pytorch 版本仍为 cpu(pytorch 是 py3.x_cpu_0),则只需先将conda install cpuonly安装 cpuonly 库,再conda uninstall cpuonly卸载 cpuonly 库即可。
参考链接:
pytorch cuda安装报错的解决方法
下载pytorch时总是下成CPU版本的一种解决办法
安装pytorch-gpu时会默认安装cpu版本
Reference
【超详细】【ubunbu 22.04】 手把手教你安装nvidia驱动,有手就行,隔壁家的老太太都能安装
ubuntu系统安装CUDA和CUDNN(CUDA安装)
手把手教你安装双系统 windows11+ubuntu 22.04(2)配置基础的深度学习环境
ubuntu22.04安装nvidia驱动+cuda11.7+cudnn8.6
Ubuntu 安装 GPU 驱动、CUDA、cuDNN,以及是否安装成功的检测
cuda版本与pytorch版本依赖关系 cuda8.0 pytorch
Ubuntu安装Anaconda详细步骤(Ubuntu22.04.1,Anaconda3-2023.03)
关于 anaconda3 的下载、安装、换源和使用


![[mysql 基于C++实现数据库连接池 连接池的使用] 持续更新中](https://img-blog.csdnimg.cn/direct/4a9a02ef547d45dcb9e5094eb407ae6e.png)