文章目录
- 一、了解AWR报告:数据库性能的仪表盘
- 二、生成AWR报告
- 三、解读AWR报告的关键部分
- 1.报告开头的系统基础信息
- 2.ADDM发现
- 3.负载概览(Load Profile)
- 4.参数文件
- 5.顶级前台等待事件
- 6.SQL 统计信息-顶级SQL
- 7.SGA Advisory AND PAG Advisory
一、了解AWR报告:数据库性能的仪表盘
Oracle的AWR(Automatic Workload Repository)报告是一个强大的性能监控工具,它为我们提供了数据库运行期间的各种统计数据。通过深入分析这些数据,我们可以更好地理解数据库的性能表现,并采取措施进行优化。
AWR每小时对v$active_session_history视图进行采样一次,并将信息保存到磁盘中,同时保留8天。这些采样信息保存在wrh_active_session_history视图中。这些数据对于DBA来说是无价之宝,通过分析这些数据,我们可以获取关于数据库性能的各种关键指标。
二、生成AWR报告
生成AWR报告在我其它文章里面
链接:https://blog.csdn.net/m0_49929446/article/details/123703897
三、解读AWR报告的关键部分
1.报告开头的系统基础信息
Oracle数据库版本
报告生成时间
数据库的名称、实例名和模式名
数据库运行的系统环境,如操作系统、硬件配置等
注意:
分析Elapsed时间和DB Time,可以评估数据库在这段时间内的负载情况和性能表现。如果DB Time占用的时间长,可能意味着数据库面临较大的负载和较多的事务处理。此时,可以进一步检查其他性能指标和详细信息,以确定是否存在性能瓶颈或问题,并采取相应的优化措施。
如:
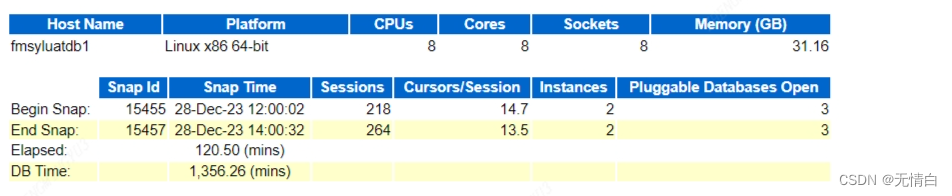
根据图中提供的数据:
Elapsed时间(经过的时间)为120.50分钟。
DB Time(数据库花费的时间)为1,356.26分钟。
我们可以计算DB Time与Elapsed时间的比率来评估数据库的繁忙程度:
DB Time / Elapsed Time = 1,356.26 / 120.50 = 11.28
这意味着在给定的时间段内,数据库的繁忙程度是相对较高的,因为DB Time是Elapsed时间的11倍多。这可能意味着数据库面临较大的负载或高并发事务,可能需要进一步分析性能指标和具体的使用情况,以确定潜在的性能瓶颈或问题,并采取相应的优化措施。
2.ADDM发现
Top ADDM Findings by Average Active Sessions
AWR Top ADDM Findings by Average Active Sessions是AWR报告中的一个重要部分,它列出了在给定时间段内平均活动会话数最多的性能问题。这些发现是由ADDM(Automatic Database Diagnostic Monitor)生成的,ADDM是一个自动诊断引擎,用于分析AWR收集的数据,并提供有关数据库性能问题的指导性意见。
通过查看AWR Top ADDM Findings by Average Active Sessions,DBA可以快速识别出哪些性能问题对数据库的整体性能影响最大。这有助于DBA优先处理最关键的问题,从而优化数据库的性能。
如:
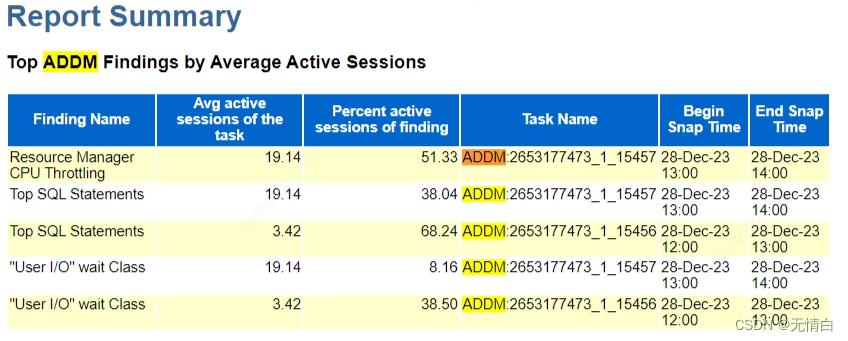
根据图中提供的数据:
Resource Manager CPU Throttling:资源管理器CPU。这可能意味着数据库的CPU使用率过高,可能需要优化或增加资源。
Top SQL Statements:排名靠前的SQL语句。这部分列出了执行次数最多或最耗时的SQL语句。这有助于识别和优化性能问题SQL语句。
“User I/O” wait Class:用户I/O等待类。这部分关注的是用户I/O等待事件,它可能表明磁盘I/O存在问题或数据库的存储性能不足。
Top ADDM Findings by Average Active Sessions 提供了一些关键的性能问题,如CPU过高、高执行次数的SQL语句和用户I/O等待事件。对于DBA来说,这些信息有助于识别数据库的性能瓶颈,并采取相应的优化措施来提高数据库的性能。
3.负载概览(Load Profile)
这一部分提供了数据库的整体性能指标,如:
DB Time(s):数据库花费的总时间,即数据库服务器在执行任务和操作上所花费的总CPU时间。
DB CPU(s):数据库服务器上实际使用的CPU时间。这排除了后台进程的CPU时间。
Background CPU(s):数据库后台进程使用的CPU时间。
Redo size (bytes):在给定时间段内,重做日志缓冲区中写入的数据量。
Logical read (blocks):从缓冲区缓存中读取的数据块数量。
Block changes:在给定时间段内,数据库中数据块更改的数量。
Physical read (blocks):从磁盘物理读取的数据块数量。
Physical write (blocks):写入磁盘的物理数据块数量。
Read IO requests:读取I/O请求的数量。
Write IO requests:写入I/O请求的数量。
Read IO (MB):读取的I/O量,以MB为单位。
Write IO (MB):写入的I/O量,以MB为单位。
IM scan rows:索引维护扫描的行数。
Session Logical Read IM:会话级别的逻辑读数量,与索引维护有关。
Global Cache blocks received:接收到的全局缓存数据块的数量。
Global Cache blocks served:提供的全局缓存数据块的数量。
User calls:用户调用的数量。
Parses (SQL):执行的SQL语句解析次数。
Hard parses (SQL):硬解析的SQL语句次数,这意味着解析了一个全新的SQL语句,而不是从共享池中获取已解析的版本。
SQL Work Area (MB):SQL工作区的总大小,以MB为单位。
Logons:给定时间段内的用户登录数。
User logons:尝试登录到数据库的用户数。
Executes (SQL):执行的SQL语句次数。
Rollbacks:回滚事务的数量。
Transactions:在给定时间段内开始的事务数量。
主要争对部分参数进行参看分析如:
DB Time
DB CPU
Redo size (bytes)
Logical read (blocks) >> Physical read (blocks)
User calls >> Executes (SQL)
Hard parses(SQL)
图:
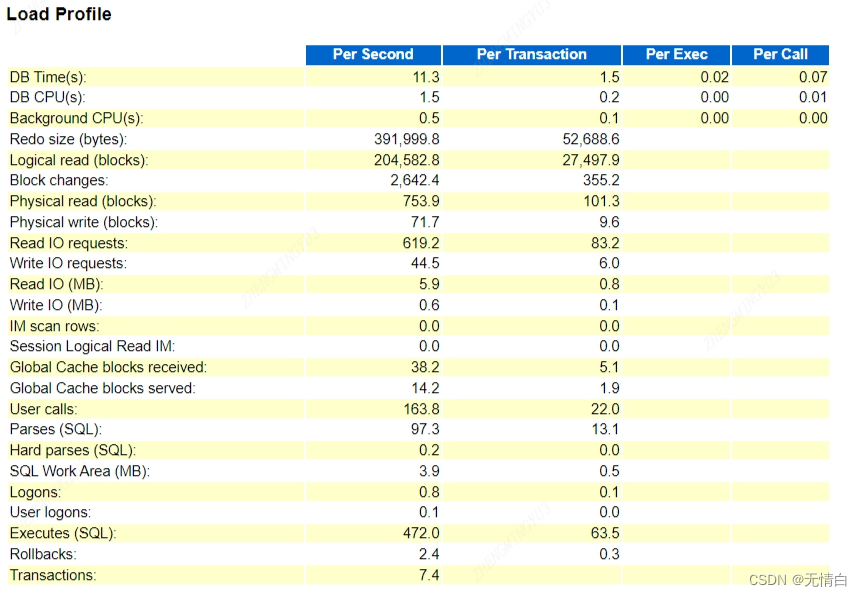
解释:
1)DB Time(s):
Per Second的值:
DB Time(s) per second: 11.3
这个值表示每秒数据库服务器在执行任务和操作上所花费的总CPU时间。该值为11.3秒,可能表明数据库在处理大量的操作和计算任务。
Per Transaction的值:
DB Time(s) per transaction: 1.5
这个值表示每个事务在执行时所花费的数据库服务器总CPU时间。该值为1.5秒,相对较高,可能表明每个事务处理都需要一定的计算资源。
2)DB CPU
DB CPU(s) per second: 1.5
这个值表示每秒数据库服务器实际使用的CPU时间。该值为1.5秒,可能表明数据库在处理大量的计算任务。
Per Transaction的值:
DB CPU(s) per transaction: 0.2
这个值表示每个事务在执行时所使用的数据库服务器CPU时间。该值为0.2秒,相对较低,可能表明每个事务处理所涉及的计算资源较少。
3)Redo size (bytes)
Per Second的值:
Redo size per second: 391,999.8 bytes
这个值表示每秒重做日志缓冲区中写入的数据量。该值为391,999.8字节,可能表明数据库的I/O负载较大,因为有大量的数据变更和事务操作产生redo日志。
Per Transaction的值:
Redo size per transaction: 52,688.6 bytes
这个值表示每个事务在执行时产生的redo日志大小。该值为52,688.6字节,相对较高,可能表明每个事务处理产生了较多的redo日志。
4)Logical read (blocks) >> Physical read (blocks)
Per Second的值:
Logical reads per second: 204,582.8 blocks
这个值表示每秒数据库执行的逻辑读操作数量。该值为204,582.8块,可能表明数据库在处理大量的查询和数据读取操作。
Physical reads per second: 753.9 blocks
这个值表示每秒数据库执行的物理读操作数量。该值为753.9块,可能表明数据库的磁盘I/O负载较高,因为需要从磁盘读取更多的数据块。
Per Transaction的值:
Logical reads per transaction: 27,497.9 blocks
这个值表示每个事务在执行时执行的逻辑读操作数量。该值为27,497.9块,相对较高,可能表明每个事务处理涉及大量的查询和数据读取操作。
Physical reads per transaction: 101.3 blocks
这个值表示每个事务在执行时执行的物理读操作数量。该值为101.3块,相对较低,可能表明每个事务处理的磁盘I/O负载较小。
Per Exec和Per Call的值:
综上所述,根据图中提供的数据,数据库可能在处理查询和数据读取操作方面似乎处于相对繁忙的状态,涉及大量的逻辑读和物理读操作。这可能表明数据库正在处理高负载的工作负载,并且涉及大量的数据读取操作和磁盘I/O负载。
5)User calls >> Executes (SQL)
Per Second的值:
User calls per second: 163.8
这个值表示每秒用户对数据库发出的调用次数。该值为163.8次,可能表明数据库接收到了大量的用户请求或操作。
Executes (SQL) per second: 472.0
这个值表示每秒执行的SQL语句数量。该值为472.0次,可能表明数据库正在处理大量的SQL查询和命令。
Per Transaction的值:
User calls per transaction: 22.0
这个值表示每个事务在执行时接收到的用户调用次数。该值为22.0次,相对较低,可能表明每个事务处理的用户请求较少。
Executes (SQL) per transaction: 63.5
这个值表示每个事务在执行时执行的SQL语句数量。该值为63.5次,相对较高,可能表明每个事务处理涉及较多的SQL查询和命令。
Per Exec和Per Call的值:
根据图中的数据,数据库在处理用户请求和SQL查询方面似乎处于相对繁忙的状态,涉及较高的用户调用和SQL语句执行频率。这可能表明数据库正在处理高负载的工作负载,并且接收到了大量的用户请求和操作。
6)Hard parses
“Hard parses”(硬解析)是指在Oracle数据库中,SQL语句第一次被解析时的过程。当一个SQL语句首次被执行时,它需要被解析以生成执行计划。如果该SQL之前没有被解析过,那么这就是一个"hard parse"。"hard parse"会消耗更多的资源,因为Oracle需要从内存中的共享池中获取该SQL的执行计划。
根据图中提供的数据:
每秒的硬解析次数为0.2次
每事务的硬解析次数为0.0次
这意味着在每秒内,数据库进行了0.2次硬解析操作,而在每个事务中,没有进行硬解析操作。
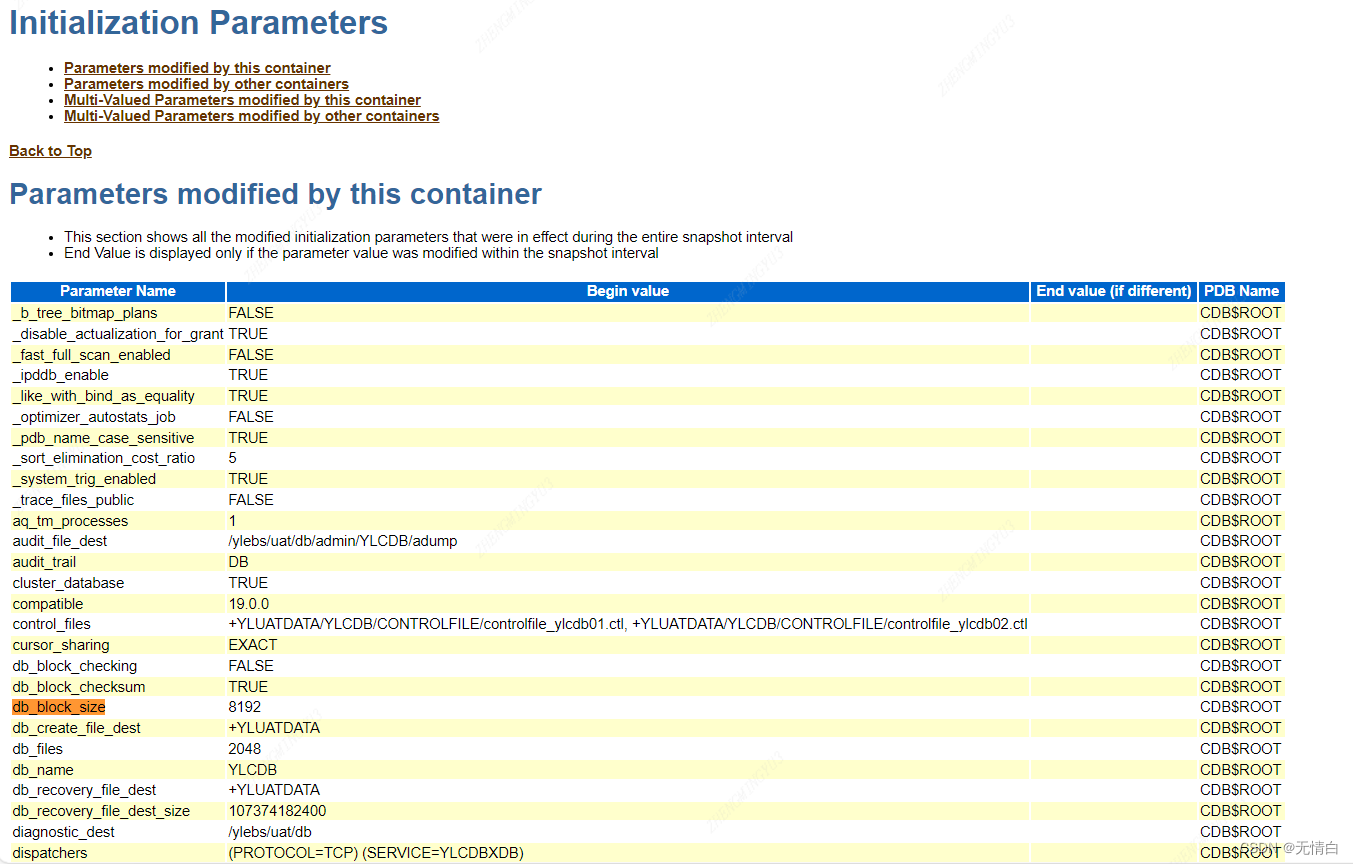
4.参数文件
init.ora参数
这一部分列出了数据库初始化时使用的配置参数。这些参数可能会影响数据库的性能,因此需要关注与性能相关的参数设置。
确认:下划线参数和事件仅在Oracle售后建议时临时设置
确认:参数应该使用默认值
确认:在不同节点上的配置应该保持一致
特别需要注意的:
db_block_size
db_file_multiblock_read_count
cursor_sharing
open_cursors
optimizer_*
parallel_*
processes
sessions
5.顶级前台等待事件
Top 10 Foreground Events by Total Wait Time
等待事件
主要检查平均等待时间、关注消耗最多的DB时间的等待事件
参数解释:
Event: 这是性能事件类别,描述了数据库中发生的事情。
Waits: 等待次数。表示该事件发生的次数。
Total Wait Time (sec): 总的等待时间,单位是秒。这表示该事件的总持续时间。
Avg Wait: 平均等待时间。表示每次发生该事件时的平均等待时间。
%DB time: 数据库时间的百分比。表示该事件占用的数据库时间的百分比。
Wait Class: 等待类别。
图:
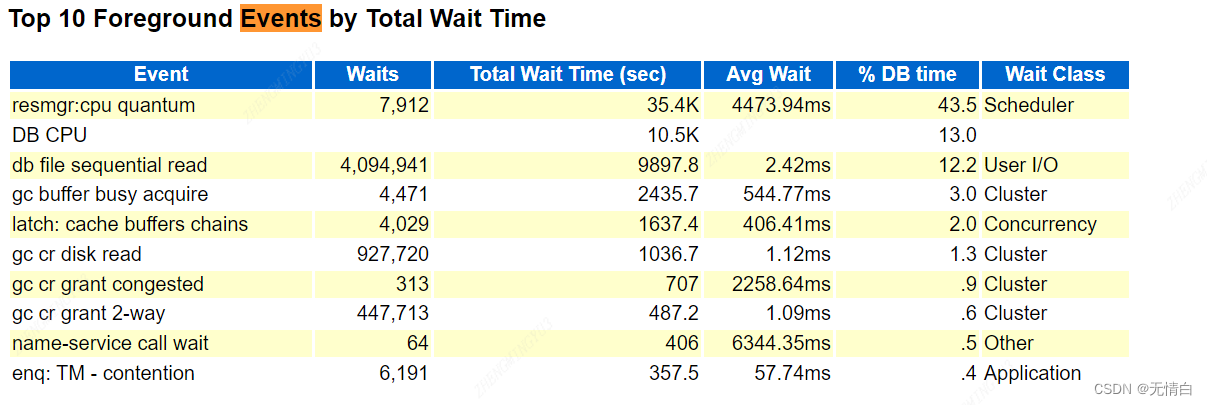
如图上数据
resmgr:cpuquantum
resmgr:cpuquantum 是一个与CPU相关的性能事件,该事件发生了7,912次,总等待时间是35,400秒,平均等待时间是4,473.94毫秒,占用了43.5%的数据库时间。这表明在数据库操作中存在一些问题,导致CPU资源的长时间占用和等待。可能需要优化查询或对系统资源进行更合理的配置和管理。
DB CPU
DB CPU是数据库CPU时间,总等待时间是10,500秒,占用了数据库13%的时间
db file sequential read
是一个用户I/O等待事件,总共有4,094,941次等待,总等待时间是9897.8秒,平均等待时间是2.42毫秒,占用了12.2%的数据库时间。这可能表明存在磁盘I/O瓶颈或配置问题,需要检查磁盘性能、I/O配置和数据库文件的位置,并进行适当的优化和配置调整。
6.SQL 统计信息-顶级SQL

SQL ordered by Elapsed Time 按运行时间排序的 SQL
SQL ordered by CPU Time 按 CPU 时间排序的 SQL
SQL ordered by User I/O Wait Time 按用户 I/O 等待时间排序的 SQL
SQL ordered by Gets 按 Gets 排序的 SQL
SQL ordered by Reads 按读取排序的 SQL
SQL ordered by Physical Reads (UnOptimized) 按物理读取排序的 SQL(未优化)
SQL ordered by Executions 按执行顺序排序的 SQL
SQL ordered by Parse Calls 按解析调用排序的 SQL
SQL ordered by Sharable Memory 按可共享内存排序的 SQL
SQL ordered by Version Count 按版本计数排序的 SQL
SQL ordered by Cluster Wait Time 按群集等待时间排序的 SQL
Complete List of SQL Text SQL 文本的完整列表
着重关注:
SQL ordered by Elapsed Time (按运行时间排序的 SQL)
检查耗时的SQL语句
查看每次执行的平均时间
点击SQL ID查看完整的SQL语句
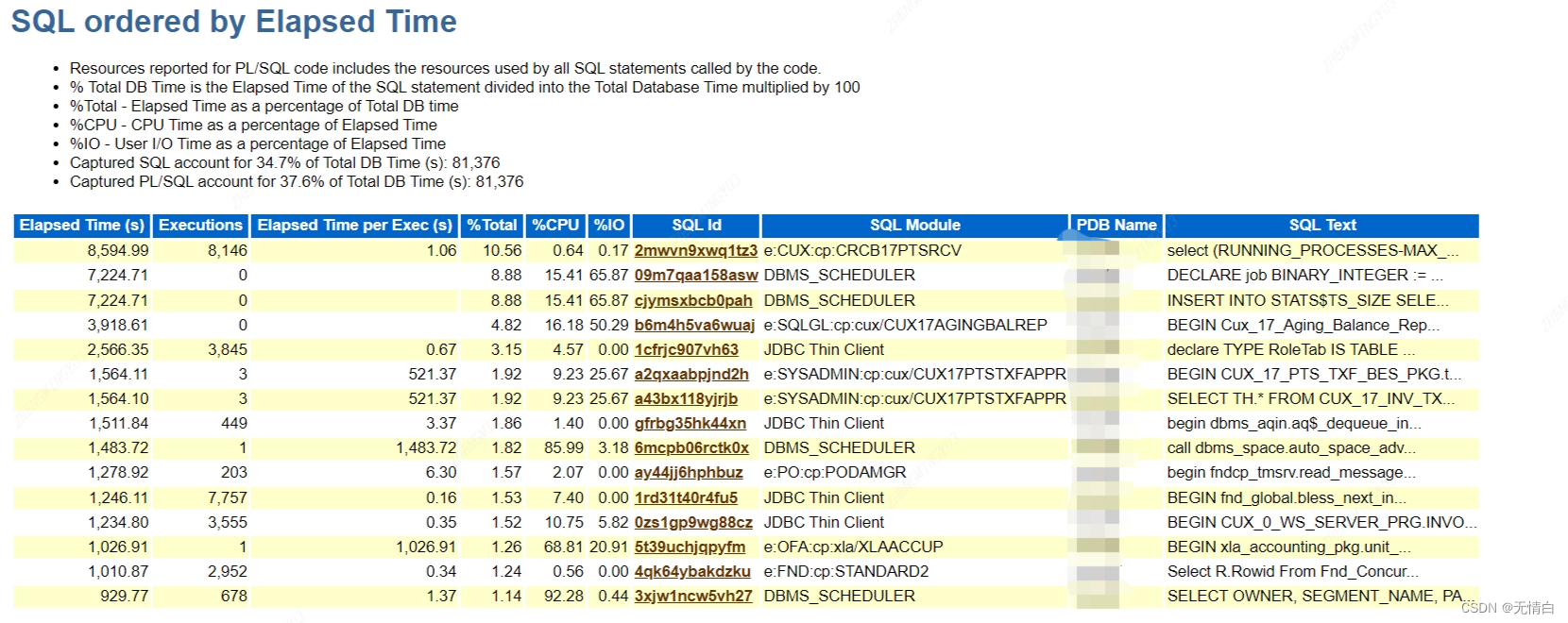
参数解释:
Executions: 这是SQL语句的执行次数,表示该查询被调用的次数。
Rows Processed: 这是SQL语句处理的总行数。
Rows per Exec: 这是每次SQL执行时处理的平均行数。
Elapsed Time (s): 这是SQL语句执行所需的总时间,单位是秒。
%CPU: 这表示SQL语句使用CPU的百分比。
%IO: 这表示SQL语句使用I/O的百分比。
SQL Id: 这是SQL语句的唯一标识符,用于标识和跟踪特定的SQL语句。
SQL Module: 这通常表示发起SQL语句的模块或应用程序。
PDB Name: PDB是Oracle的多租户架构中的容器数据库(Private Database)。这列显示了包含该SQL语句的PDB的名称。
SQL Text: 这列显示了SQL语句的实际文本。
SQL ordered by Executions (按执行顺序排序的 SQL)
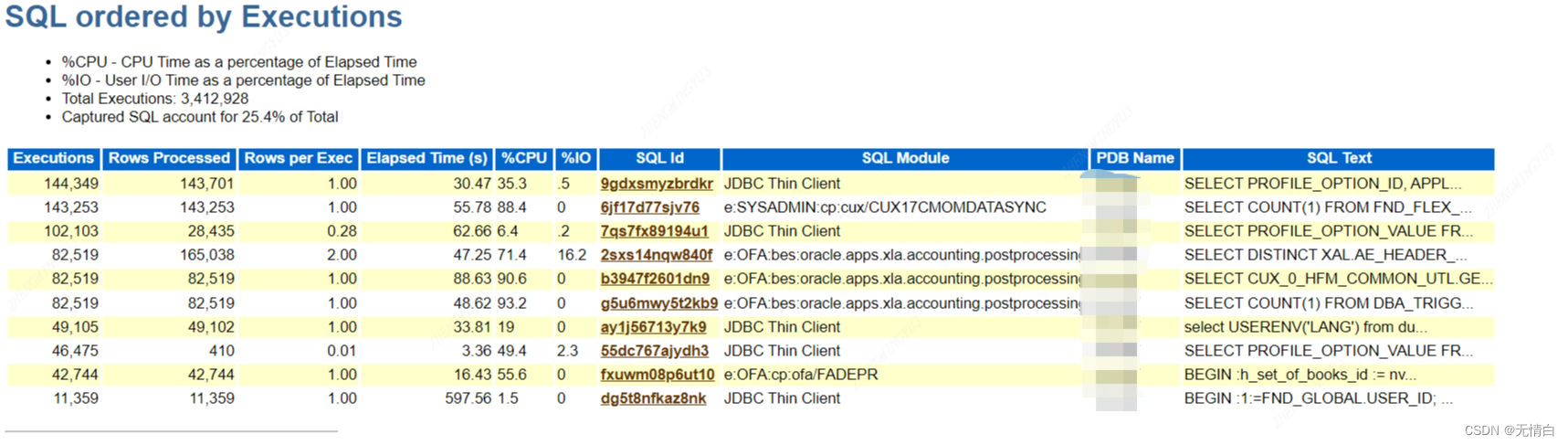
根据上述步骤里发现的大概数据库的性能问题,在通过其他部分获取特定的详细信息以进行分析。
IO Stats
IOStat by Function summary
IOStat by Filetype summary
IOStat by Function/Filetype summary
Tablespace IO Stats
File IO Stats等
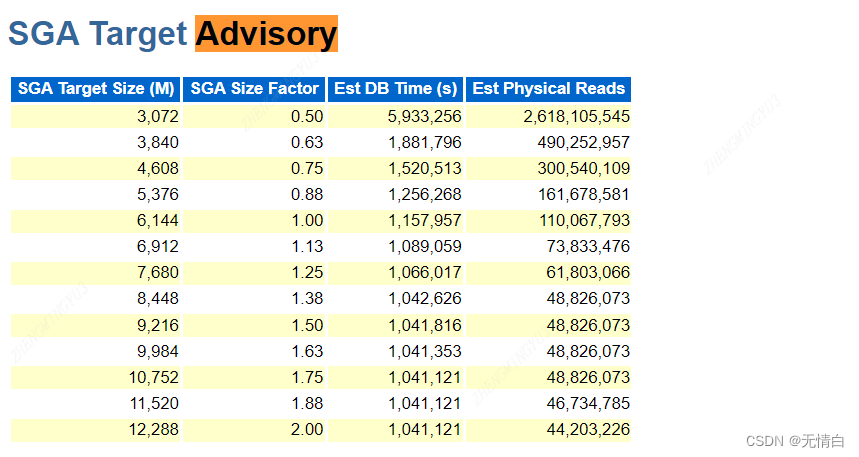
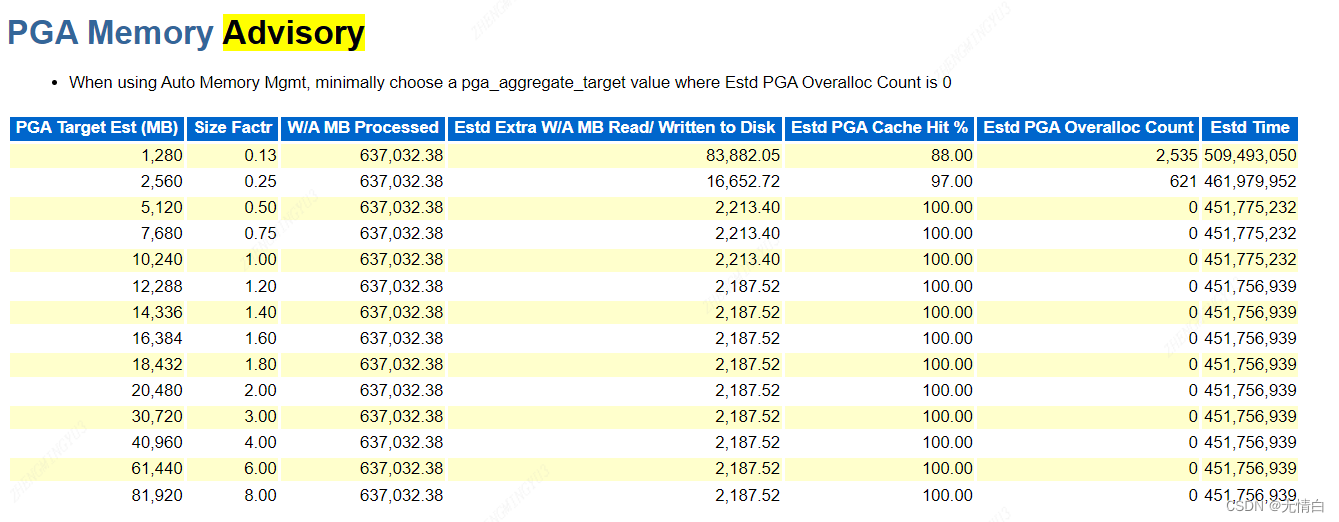
7.SGA Advisory AND PAG Advisory
AWR SGA Advisory会分析AWR报告中的数据,并根据数据库的性能表现提供关于SGA配置的建议。这些建议可能包括调整SGA的大小、增加或减少缓冲池的大小、优化共享池的大小等。通过调整SGA的配置,可以提高数据库的性能和响应速度。
PAG Advisory会分析数据库中所有表和索引的使用情况,并根据这些信息提供关于表和索引的存储和访问建议。这些建议可能包括增加或减少表空间的大小、优化表的存储参数、重建索引等。通过调整表和索引的存储和访问方式,可以提高数据库的查询性能和数据访问速度。
总的来说,AWR SGA Advisory和PAG Advisory的作用是帮助数据库管理员识别和解决性能问题,优化数据库性能,并确保系统正常运行。
建议设置 SGA Size Factor 1.00 对应的SGA和PGA大小