文章目录
- 倒排索引(Inverted Index)和正排索引(Forward Index)
- es和MySQL对比
- IK分词器的总结
- mapping映射
- 使用springboot整合的ES来进行操作Es
- 1. 实体类中添加注解
- 2. 编写Repository层
- 3. 通过Repository进行增删改查
倒排索引(Inverted Index)和正排索引(Forward Index)
正排索引是一种以文档为单位的索引结构,它将文档中的每个单词或词组与其所在的文档进行映射关系的建立。正排索引通常用于快速检索指定文档的内容,可以根据文档的编号或其他标识符快速定位到文档的内容。
倒排索引是一种以单词或词组为单位的索引结构,它将每个单词或词组与包含该单词或词组的文档进行映射关系的建立。倒排索引通常用于根据关键词进行文档的检索,可以根据关键词快速找到包含该关键词的文档列表。
正排索引和倒排索引的主要区别在于索引结构的建立方式和使用场景。正排索引适用于需要快速定位到指定文档的场景,而倒排索引适用于根据关键词进行文档的检索和查询的场景。
下面是正排索引和倒排索引的示意图:
正排索引示意图:
文档1 -> 单词1, 单词2, ...
文档2 -> 单词3, 单词4, ...
文档3 -> 单词2, 单词5, ...
倒排索引示意图:
单词1 -> 文档1
单词2 -> 文档1, 文档3
单词3 -> 文档2
单词4 -> 文档2
单词5 -> 文档3
总的来说,正排索引和倒排索引是信息检索中常用的两种索引结构,它们在索引和搜索过程中发挥着不同的作用,对于不同的应用场景有着不同的优势。
正常情况下我们将Id设置为主键索引能够快速查询到某条记录,但是有些字段不方便创建索引,如名称,简介等字段,这时候就可以使用ES来进行创建索引

es和MySQL对比
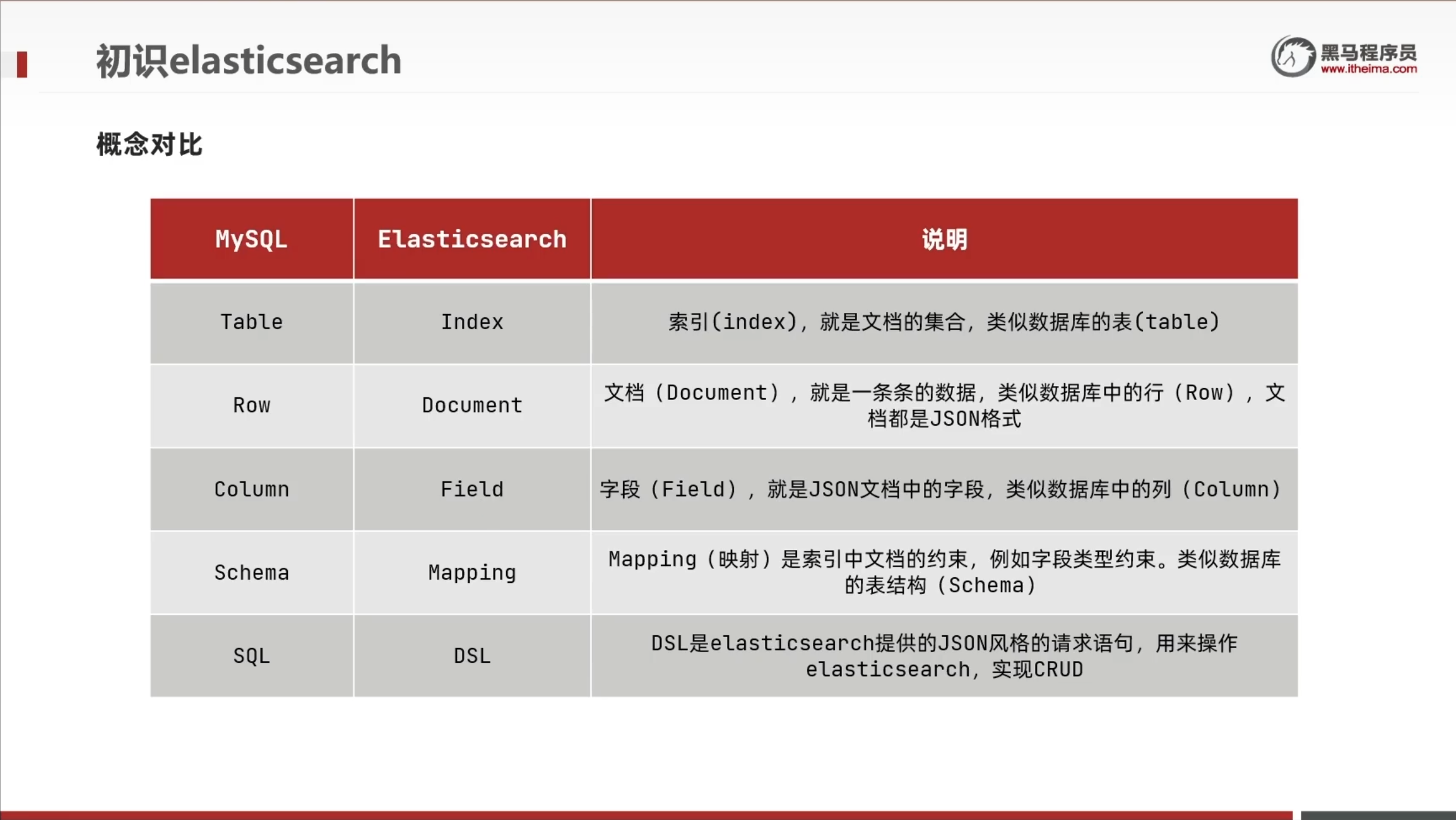
分词器
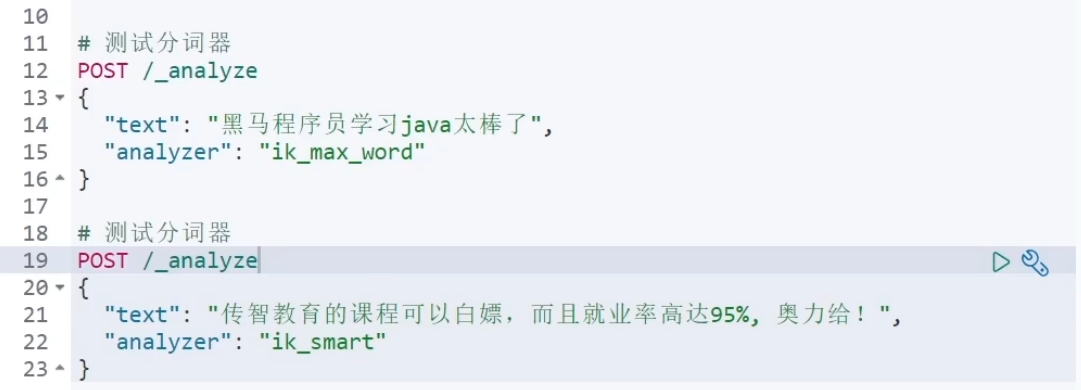
安装完IK分词器后有两个常用的分词模式ik_max_word和ik_smart
ik_max_word分词会分的更细。
ik_smart发现一个词后就不会再对分过的词进行重新分词
如程序员使用ik_max_word分词。会分为程序员,程序,员三个词
而使用ik_smart的话,则就分一个程序员一个词
各有优缺点
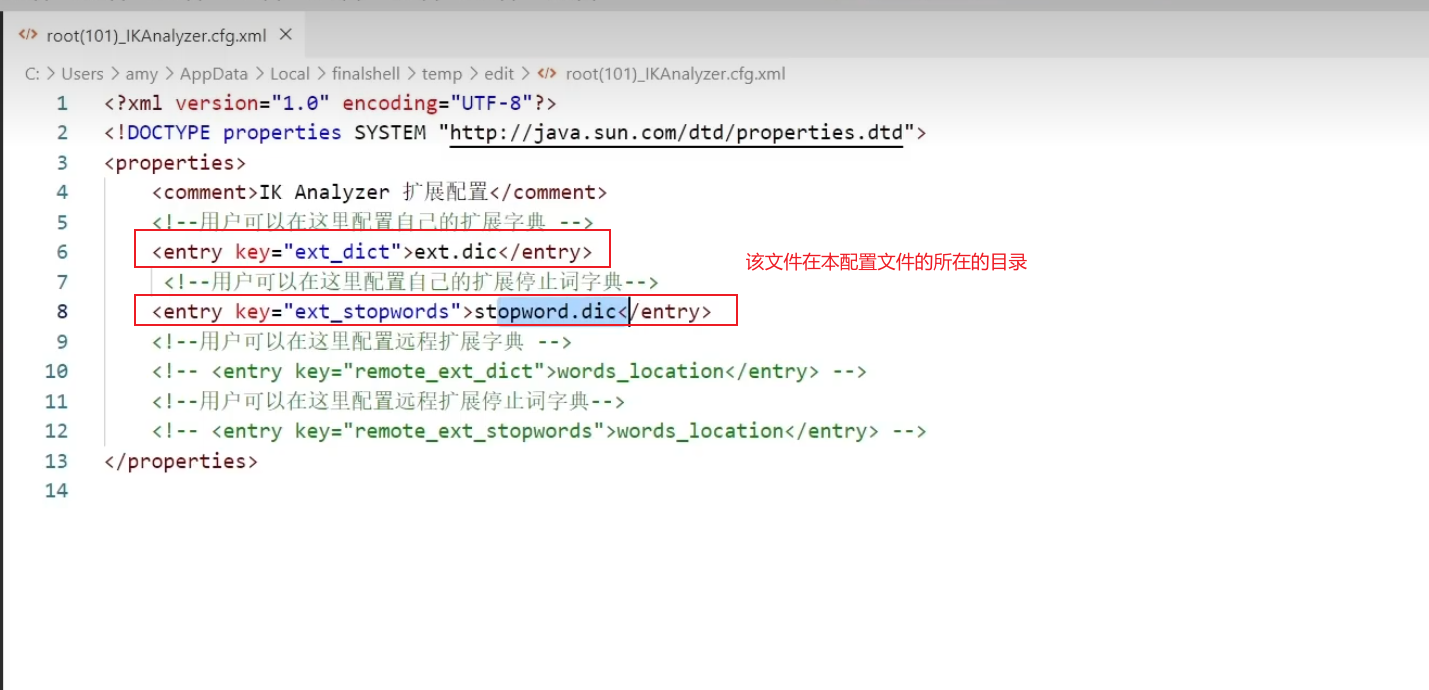
配置IK分词器的扩展字典,及禁用字典 
IK分词器的总结

mapping映射

使用springboot整合的ES来进行操作Es
1. 实体类中添加注解
import cn.creatoo.system.domain.BdDataData;
import cn.hutool.core.util.ObjectUtil;
import com.baomidou.mybatisplus.annotation.TableLogic;
import lombok.Data;
import org.springframework.data.annotation.Id;
import org.springframework.data.elasticsearch.annotations.Document;
import org.springframework.data.elasticsearch.annotations.Field;
import org.springframework.data.elasticsearch.annotations.FieldType;
import java.time.format.DateTimeFormatter;
/**
* 资源表对应的实体类
*
* @author shang tf
* @version 1.0
* @data 2023/12/22 11:47
*/
@Data
@Document(indexName = "data")
public class BdDataDataVo {
@Id
private Long dataId;
@Field(type = FieldType.Keyword)
private String dataNo;
@Field(type = FieldType.Keyword)
private String resourceLink;
@Field(type = FieldType.Keyword)
private String exposeLink;
@Field(type = FieldType.Keyword)
private String coverLink;
@Field(type = FieldType.Long)
private Long audioTime;
@Field(type = FieldType.Long)
private Long videoTime;
@Field(type = FieldType.Text, analyzer = "ik_max_word", searchAnalyzer = "ik_smart")
private String resourceName;
@Field(type = FieldType.Text, analyzer = "ik_max_word", searchAnalyzer = "ik_smart")
private String resourceInfo;
@Field(type = FieldType.Integer)
private Integer resourceType;
@Field(type = FieldType.Keyword)
private String resourceFormat;
@Field(type = FieldType.Long)
private Long size;
@Field(type = FieldType.Text, analyzer = "ik_max_word", searchAnalyzer = "ik_smart")
private String tags;
@Field(type = FieldType.Integer)
private Integer carrier;
@Field(type = FieldType.Keyword)
private String contributor;
@Field(type = FieldType.Keyword)
private String author;
@TableLogic(value = "0", delval = "1")
private Integer isDel;
@Field(type = FieldType.Keyword)
private String gifLink;
@Field(type = FieldType.Keyword)
private String fileName;
@Field(type = FieldType.Long)
private Long direId;
@Field(type = FieldType.Long)
private Long createBy;
@Field(type = FieldType.Keyword)
private String createTime;
@Field(type = FieldType.Long)
private Long updateBy;
@Field(type = FieldType.Keyword)
private String updateTime;
// 无参构造
public BdDataDataVo() {
}
// 构造方法将BdDataData类转换为BdDataDataVo
public BdDataDataVo(BdDataData bdDataData) {
this.dataId = bdDataData.getDataId();
this.dataNo = bdDataData.getDataNo();
this.resourceLink = bdDataData.getResourceLink();
this.exposeLink = bdDataData.getExposeLink();
this.coverLink = bdDataData.getCoverLink();
this.audioTime = bdDataData.getAudioTime();
this.videoTime = bdDataData.getVideoTime();
this.resourceName = bdDataData.getResourceName();
this.resourceInfo = bdDataData.getResourceInfo();
this.resourceType = bdDataData.getResourceType();
this.resourceFormat = bdDataData.getResourceFormat();
this.size = bdDataData.getSize();
this.tags = bdDataData.getTags();
this.carrier = bdDataData.getCarrier();
this.contributor = bdDataData.getContributor();
this.author = bdDataData.getAuthor();
this.isDel = bdDataData.getIsDel();
this.gifLink = bdDataData.getGifLink();
this.fileName = bdDataData.getFileName();
this.direId = bdDataData.getDireId();
this.createBy = bdDataData.getCreateBy();
this.updateBy = bdDataData.getUpdateBy();
DateTimeFormatter formatter = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss");
if (ObjectUtil.isNotEmpty(bdDataData.getCreateTime())){
String createTimeFormat = bdDataData.getCreateTime().format(formatter);
this.createTime = createTimeFormat;
}
if (ObjectUtil.isNotEmpty(bdDataData.getUpdateTime())){
String updateTimeFormat = bdDataData.getUpdateTime().format(formatter);
this.updateTime = updateTimeFormat;
}
}
}
2. 编写Repository层
import cn.creatoo.system.domain.vo.data.BdDataDataVo;
import org.springframework.data.elasticsearch.annotations.Query;
import org.springframework.data.elasticsearch.repository.ElasticsearchRepository;
import org.springframework.stereotype.Repository;
import java.util.List;
/**
* @author shang tf
* @version 1.0
* @data 2023/12/29 10:55
*/
@Repository
public interface BdDataDataRepository extends ElasticsearchRepository<BdDataDataVo, Long> {
/**
* 根据resourceName,resourceInfo,tags字段进行匹配
* @param query
* @return
*/
@Query("{\"multi_match\":{\"query\":\"?0\",\"fields\":[\"resourceName\", \"resourceInfo\", \"tags\"]}}")
List<BdDataDataVo> findByQuery(String query);
}
3. 通过Repository进行增删改查
package cn.creatoo.system;
import cn.creatoo.system.dao.BdDataDataRepository;
import cn.creatoo.system.domain.BdDataData;
import cn.creatoo.system.domain.vo.data.BdDataDataVo;
import cn.creatoo.system.mapper.BdDataDataMapper;
import com.baomidou.mybatisplus.core.conditions.query.QueryWrapper;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.util.ArrayList;
import java.util.List;
/**
* @author shang tf
* @version 1.0
* @data 2023/12/29 10:27
*/
@SpringBootTest
public class TestXXX {
// MybatisPlus - 数据库的Mapper
@Autowired
private BdDataDataMapper bdDataDataMapper;
// ES 的Repository
@Autowired
private BdDataDataRepository bdDataDataRepository;
/**
* 添加文档
*/
@Test
public void testAddData() {
BdDataData bdDataData = bdDataDataMapper.selectById(1739554563704041473L);
BdDataDataVo bdDataDataVo = new BdDataDataVo(bdDataData);
BdDataDataVo save = bdDataDataRepository.save(bdDataDataVo);
System.out.println("save = " + save);
}
/**
* 删除文档
*/
@Test
public void deleteData() {
bdDataDataRepository.deleteById(1739563811997585409L);
//bdDataDataRepository.deleteAll();
}
/**
* 根据条件查询,es会自动进行分词查询。将符合度高的放到前面
*/
@Test
public void testSelectData() {
List<BdDataDataVo> result = bdDataDataRepository.findByQuery("[阳光, 豁达]");
for (BdDataDataVo bdDataDataVo : result) {
System.out.println("bdDataDataVo = " + bdDataDataVo);
}
}
/**
* 添加数据库所有内容,
*/
@Test
public void init(){
List<BdDataData> bdDataData = bdDataDataMapper.selectList(new QueryWrapper<>());
List<BdDataDataVo> bdDataDataVos = new ArrayList<>();
for (BdDataData bdDataDatum : bdDataData) {
bdDataDataVos.add(new BdDataDataVo(bdDataDatum));
}
// 保存多个文档
Iterable<BdDataDataVo> bdDataDataVos1 = bdDataDataRepository.saveAll(bdDataDataVos);
for (BdDataDataVo bdDataDataVo : bdDataDataVos1) {
System.out.println("bdDataDataVo = " + bdDataDataVo);
}
}
}