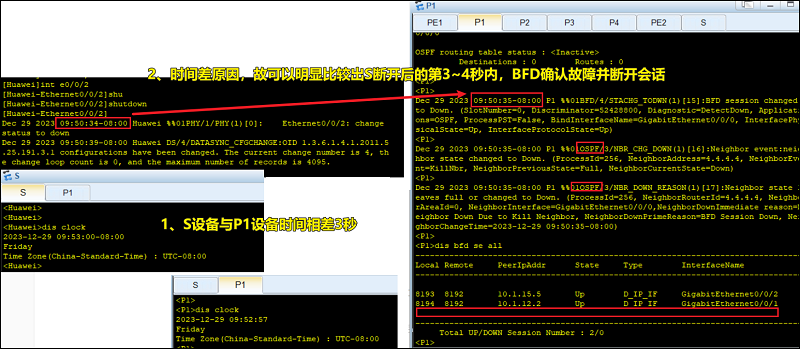
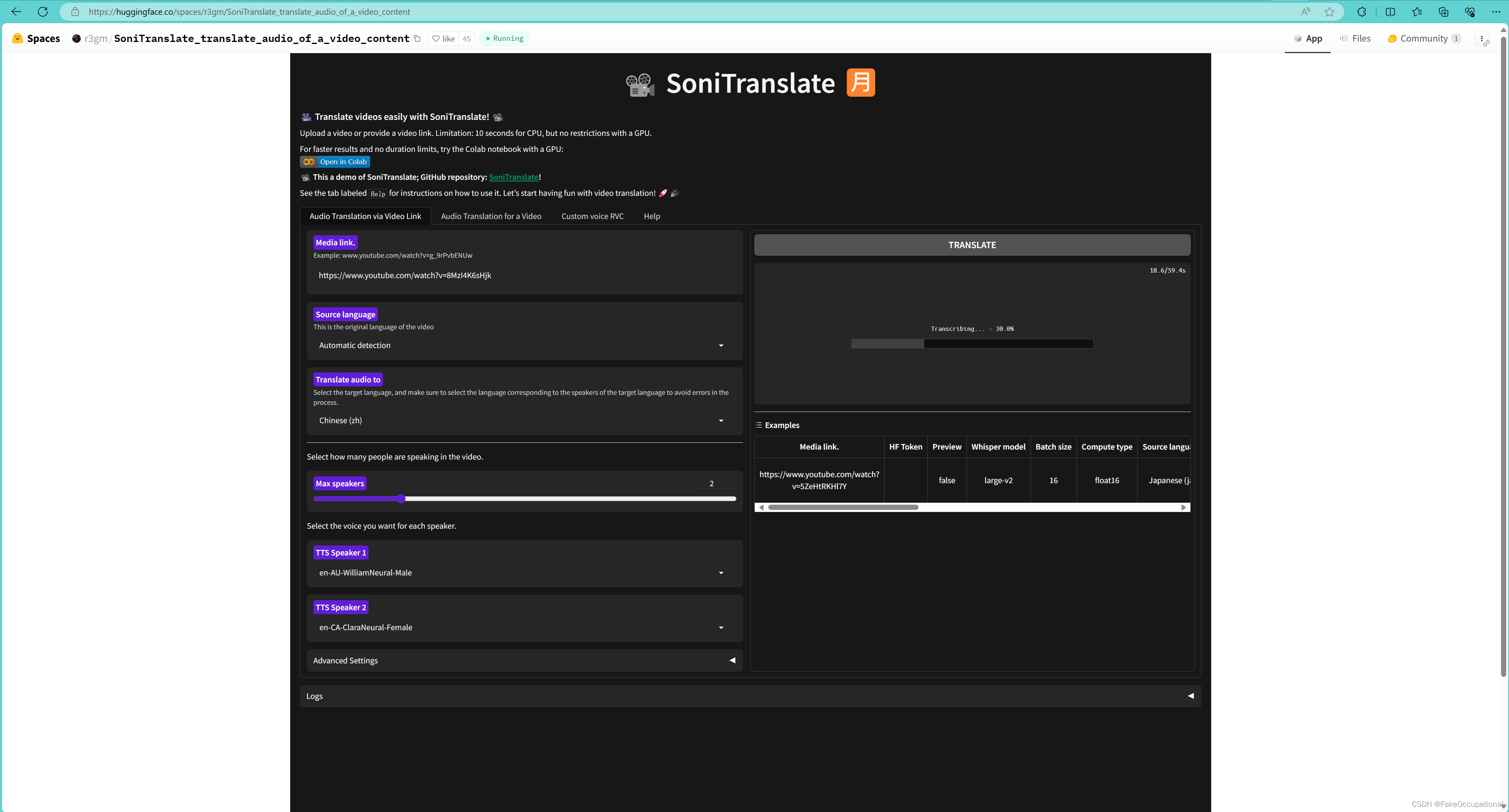
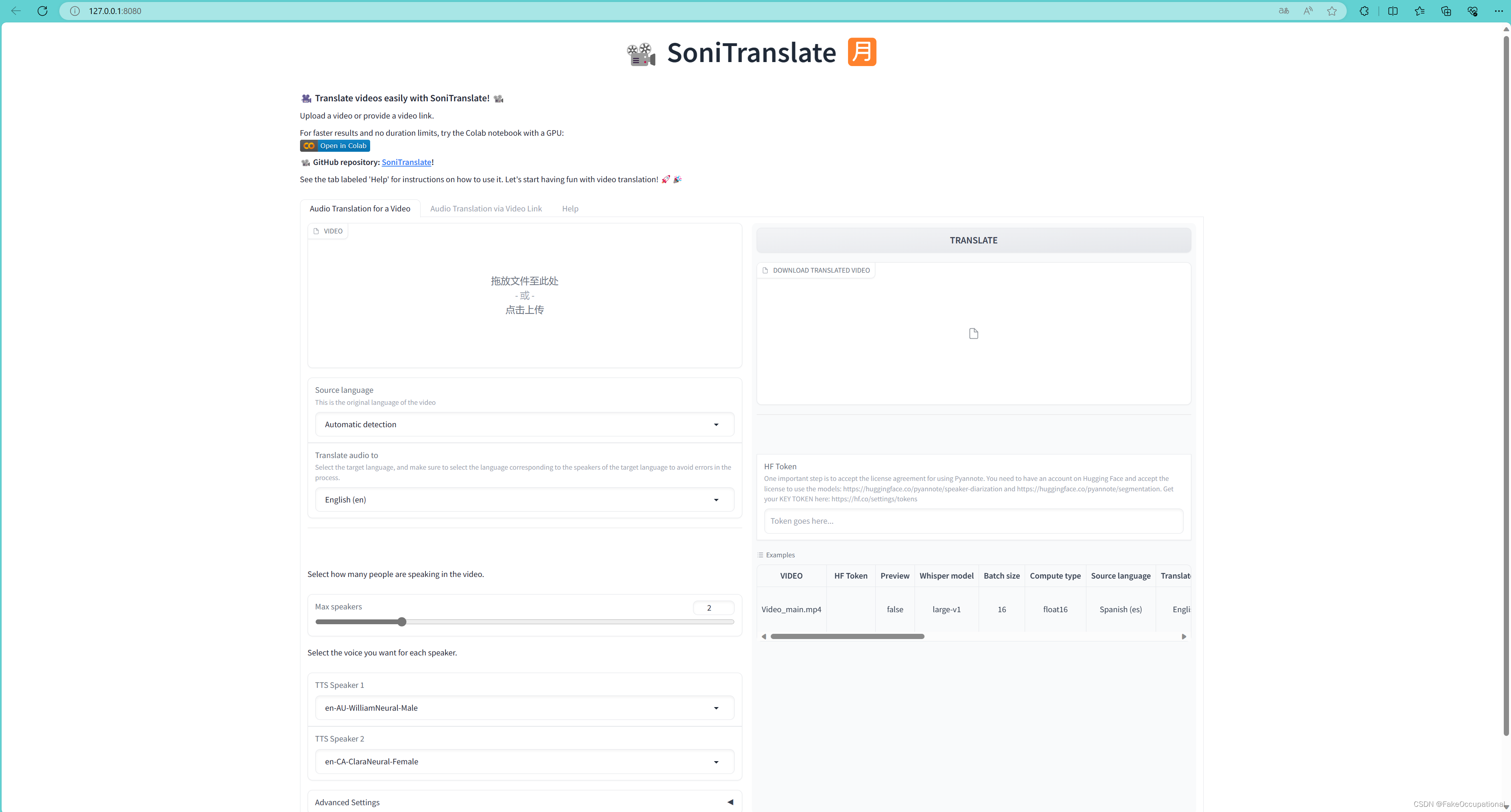
示例效果
- 官方在线运行地址:https://huggingface.co/spaces/r3gm/SoniTranslate_translate_audio_of_a_video_content
环境配置
git clone --recurse-submodules https://github.com/R3gm/SoniTranslate.gitconda create -n soni python=3.8conda activate sonipip install -r requirements.txt
// https://github.com/openai/whisper/discussions/1645
× git clone --filter=blob:none --quiet https://github.com/openai/whisper.git 'C:\Users\nminhtri2\AppData\Local\Temp\pip-req-build-w7avljik' did not run successfully.
│ exit code: 128
╰─> See above for output.
note: This error originates from a subprocess, and is likely not a problem with pip.
error: subprocess-exited-with-error
× git clone --filter=blob:none --quiet https://github.com/openai/whisper.git 'C:\Users\nminhtri2\AppData\Local\Temp\pip-req-build-w7avljik' did not run successfully.
│ exit code: 128
╰─> See above for output.
note: This error originates from a subprocess, and is likely not a problem with pip.
pip install openai-whisperpython app.py
home/ubuntu/anaconda3/envs/sys_soni/lib/python3.8/site-packages/pyannote/audio/core/io.py:43: UserWarning: torchaudio._backend.set_audio_backend has been deprecated. With dispatcher enabled, this function is no-op. You can remove the function call.
torchaudio.set_audio_backend("soundfile")
/home/ubuntu/anaconda3/envs/sys_soni/lib/python3.8/site-packages/torch_audiomentations/utils/io.py:27: UserWarning: torchaudio._backend.set_audio_backend has been deprecated. With dispatcher enabled, this function is no-op. You can remove the function call.
torchaudio.set_audio_backend("soundfile")
torchvision is not available - cannot save figures
Working in: cuda
Traceback (most recent call last):
File "app.py", line 432, in <module>
min_speakers = gr.Slider(1, MAX_TTS, default=1, label="min_speakers", step=1, visible=False)
File "/home/ubuntu/anaconda3/envs/sys_soni/lib/python3.8/site-packages/gradio/component_meta.py", line 157, in wrapper
return fn(self, **kwargs)
TypeError: __init__() got an unexpected keyword argument 'default'
(sys_soni) ubuntu@ubuntu-3090x2:~/userfile/***/SoniTranslate$ pip list | grep gradio
gradio 4.12.0
gradio_client 0.8.0
(sys_soni) ubuntu@ubuntu-3090x2:~/userfile/***/SoniTranslate$ pip install gradio==3.41.2
demo.launch(share=True, enable_queue=True)最后一句改为:demo.launch(server_name='127.0.0.1', server_port=8080, show_error=True, enable_queue=True)
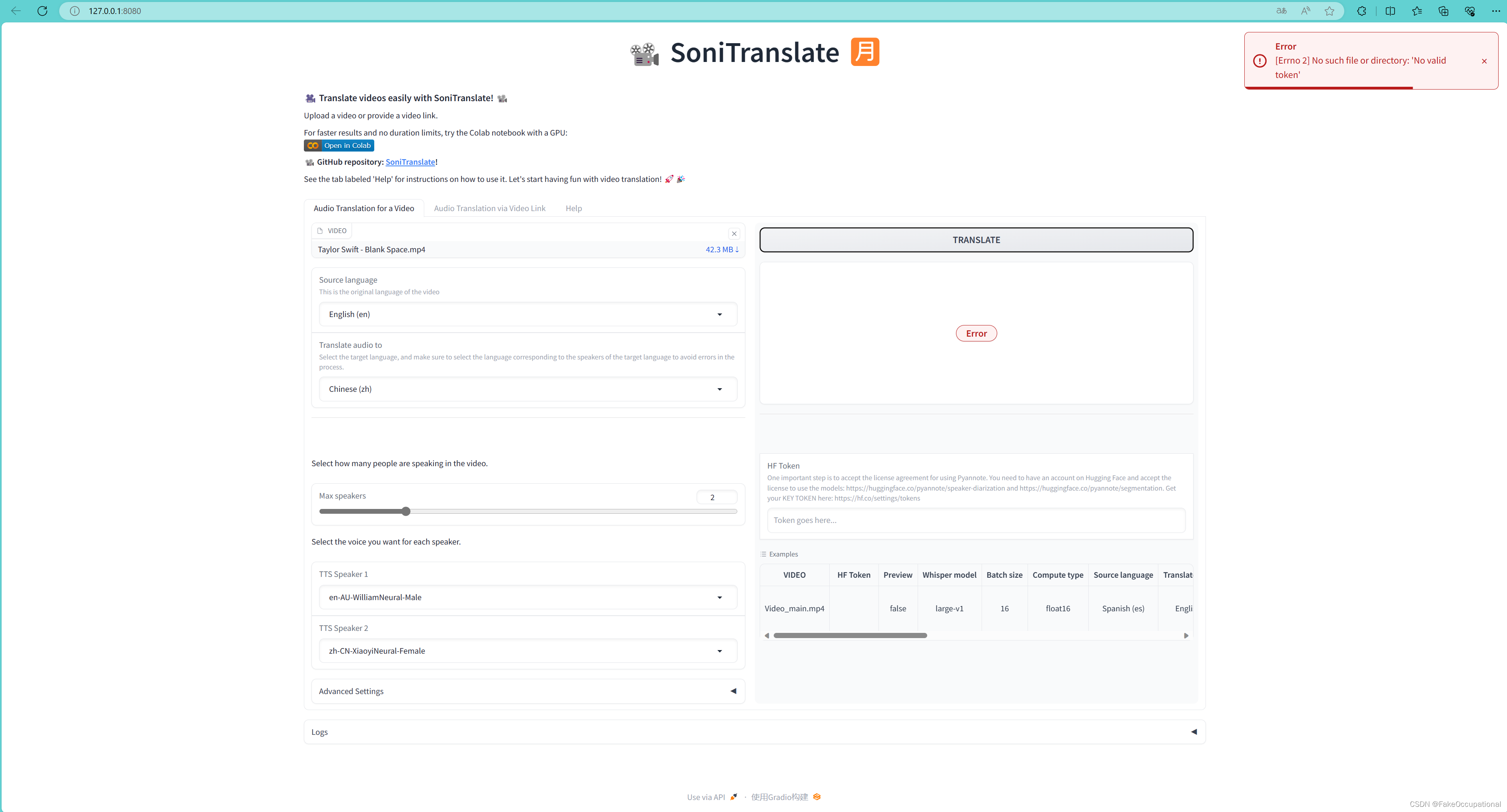
报错相关
报错 FileNotFoundError: [Errno 2] No such file or directory: ‘No valid token’
def translate_from_video(
video,
YOUR_HF_TOKEN,
preview=False,
WHISPER_MODEL_SIZE="large-v1",
batch_size=16,
compute_type="float16",
SOURCE_LANGUAGE= "Automatic detection",
TRANSLATE_AUDIO_TO="English (en)",
min_speakers=1,
max_speakers=2,
tts_voice00="en-AU-WilliamNeural-Male",
tts_voice01="en-CA-ClaraNeural-Female",
tts_voice02="en-GB-ThomasNeural-Male",
tts_voice03="en-GB-SoniaNeural-Female",
tts_voice04="en-NZ-MitchellNeural-Male",
tts_voice05="en-GB-MaisieNeural-Female",
video_output="video_dub.mp4",
AUDIO_MIX_METHOD='Adjusting volumes and mixing audio',
progress=gr.Progress(),
):
if YOUR_HF_TOKEN == "" or YOUR_HF_TOKEN == None:
YOUR_HF_TOKEN = "去官网获取token"#YOUR_HF_TOKEN = os.getenv("YOUR_HF_TOKEN")
if YOUR_HF_TOKEN == None:
print('No valid token')
return "No valid token"
else:
os.environ["YOUR_HF_TOKEN"] = YOUR_HF_TOKEN
video = video if isinstance(video, str) else video.name
print(video)
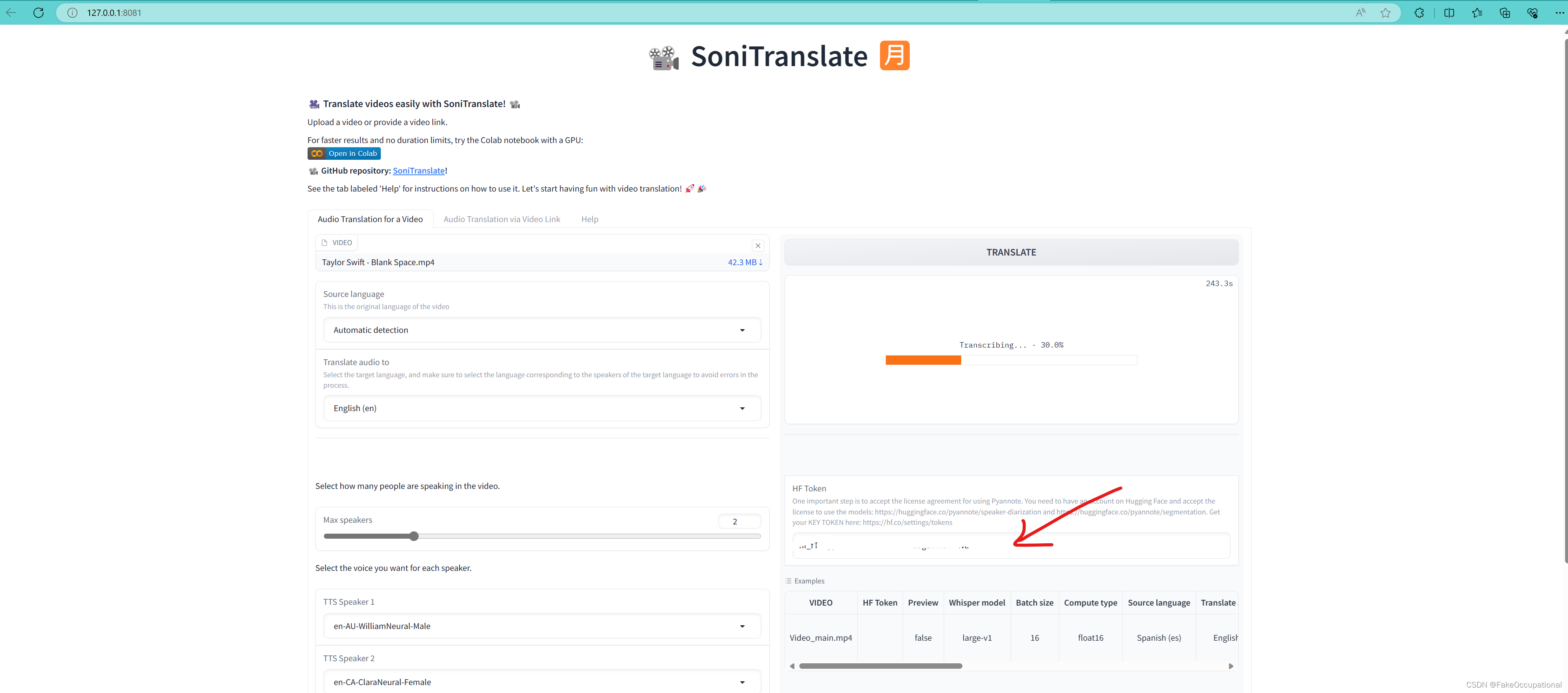
模型加载失败
错误信息
Set file complete.
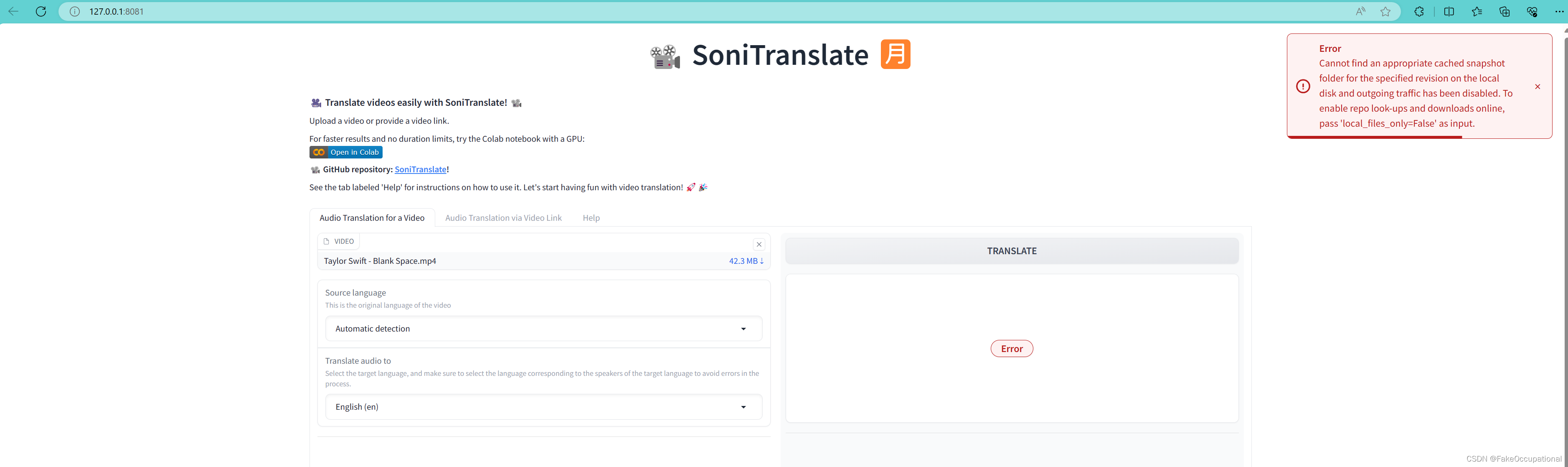
An error occured while synchronizing the model Systran/faster-whisper-large-v1 from the Hugging Face Hub:
An error happened while trying to locate the files on the Hub and we cannot find the appropriate snapshot folder for the specified revision on the local disk. Please check your internet connection and try again.
Trying to load the model directly from the local cache, if it exists.
Traceback (most recent call last):
File "/home/ubuntu/anaconda3/envs/sys_soni/lib/python3.8/site-packages/urllib3/connection.py", line 203, in _new_conn
sock = connection.create_connection(
File "/home/ubuntu/anaconda3/envs/sys_soni/lib/python3.8/site-packages/urllib3/util/connection.py", line 85, in create_connection
raise err
File "/home/ubuntu/anaconda3/envs/sys_soni/lib/python3.8/site-packages/urllib3/util/connection.py", line 73, in create_connection
sock.connect(sa)
OSError: [Errno 101] Network is unreachable
File "/home/ubuntu/anaconda3/envs/sys_soni/lib/python3.8/site-packages/huggingface_hub/_snapshot_download.py", line 235, in snapshot_download
raise LocalEntryNotFoundError(
huggingface_hub.utils._errors.LocalEntryNotFoundError: Cannot find an appropriate cached snapshot folder for the specified revision on the local disk and outgoing traffic has been disabled. To enable repo look-ups and downloads online, pass 'local_files_only=False' as input.
报错段落
progress(0.30, desc="Transcribing...")
print("Set file complete.")
SOURCE_LANGUAGE = None if SOURCE_LANGUAGE == 'Automatic detection' else SOURCE_LANGUAGE
# 1. Transcribe with original whisper (batched)
model = whisperx.load_model(
WHISPER_MODEL_SIZE,
device,
compute_type=compute_type,
language= SOURCE_LANGUAGE,
)
audio = whisperx.load_audio(audio_wav)
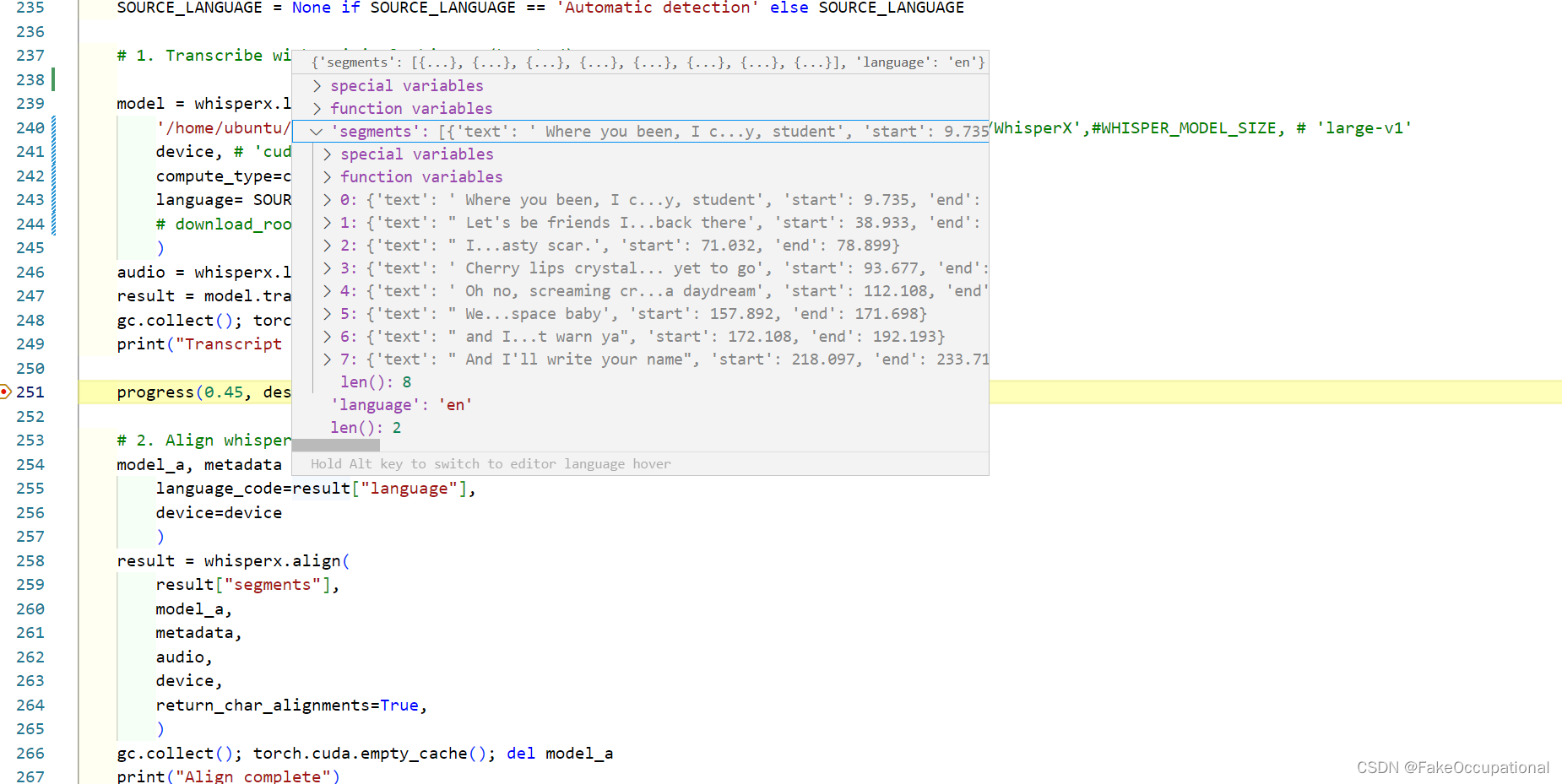
result = model.transcribe(audio, batch_size=batch_size)
gc.collect(); torch.cuda.empty_cache(); del model
print("Transcript complete")
progress(0.45, desc="Aligning...")
解决方法
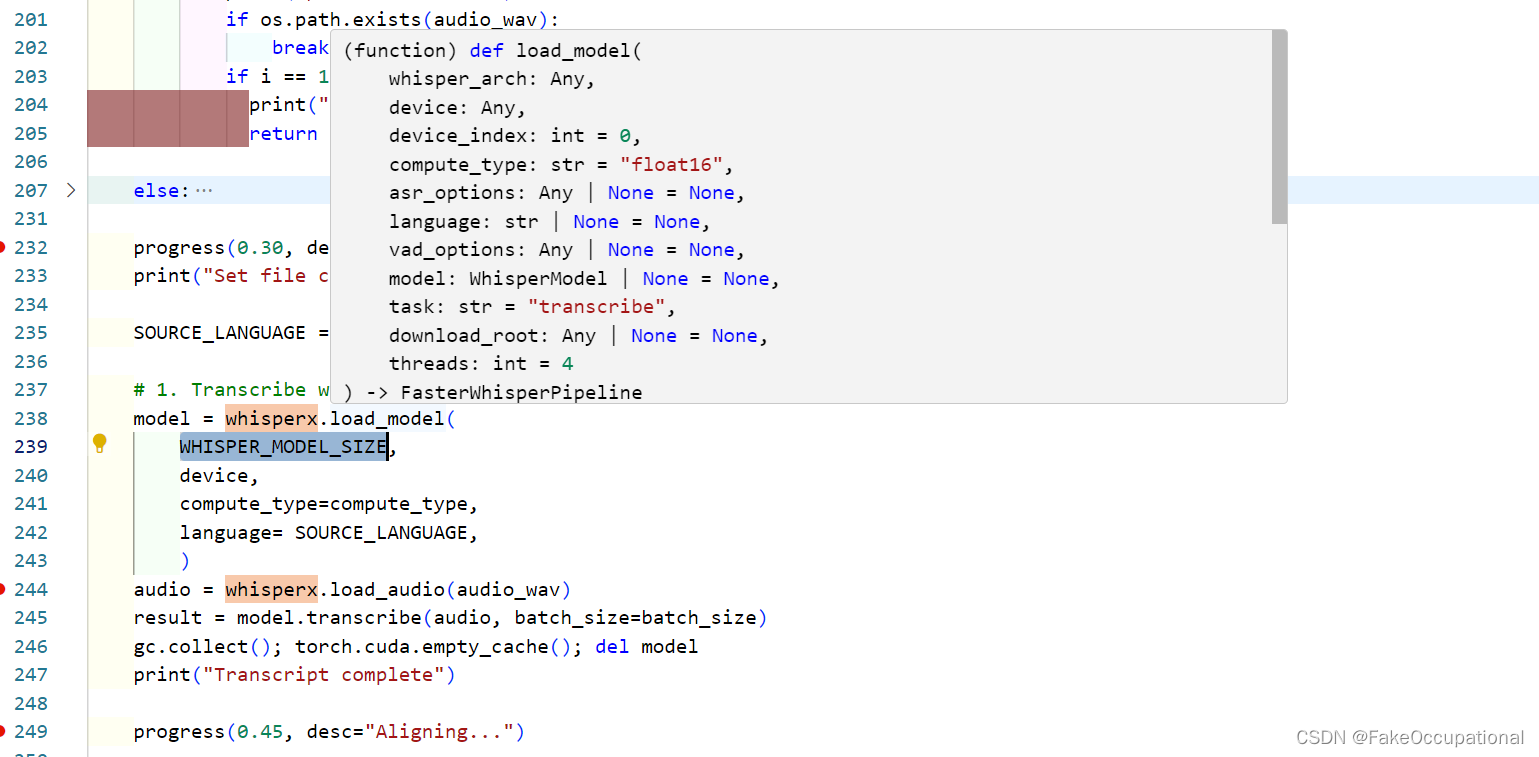
找到可以添加本地路径的参数 WHISPER_MODEL_SIZE
model = whisperx.load_model(
WHISPER_MODEL_SIZE, # 'large-v1'
device, # 'cuda'
compute_type=compute_type, # 'float16'
language= SOURCE_LANGUAGE, # NONE
)
- 无法直接使用huggingface的模型,会报以下错误,解决办法有两个
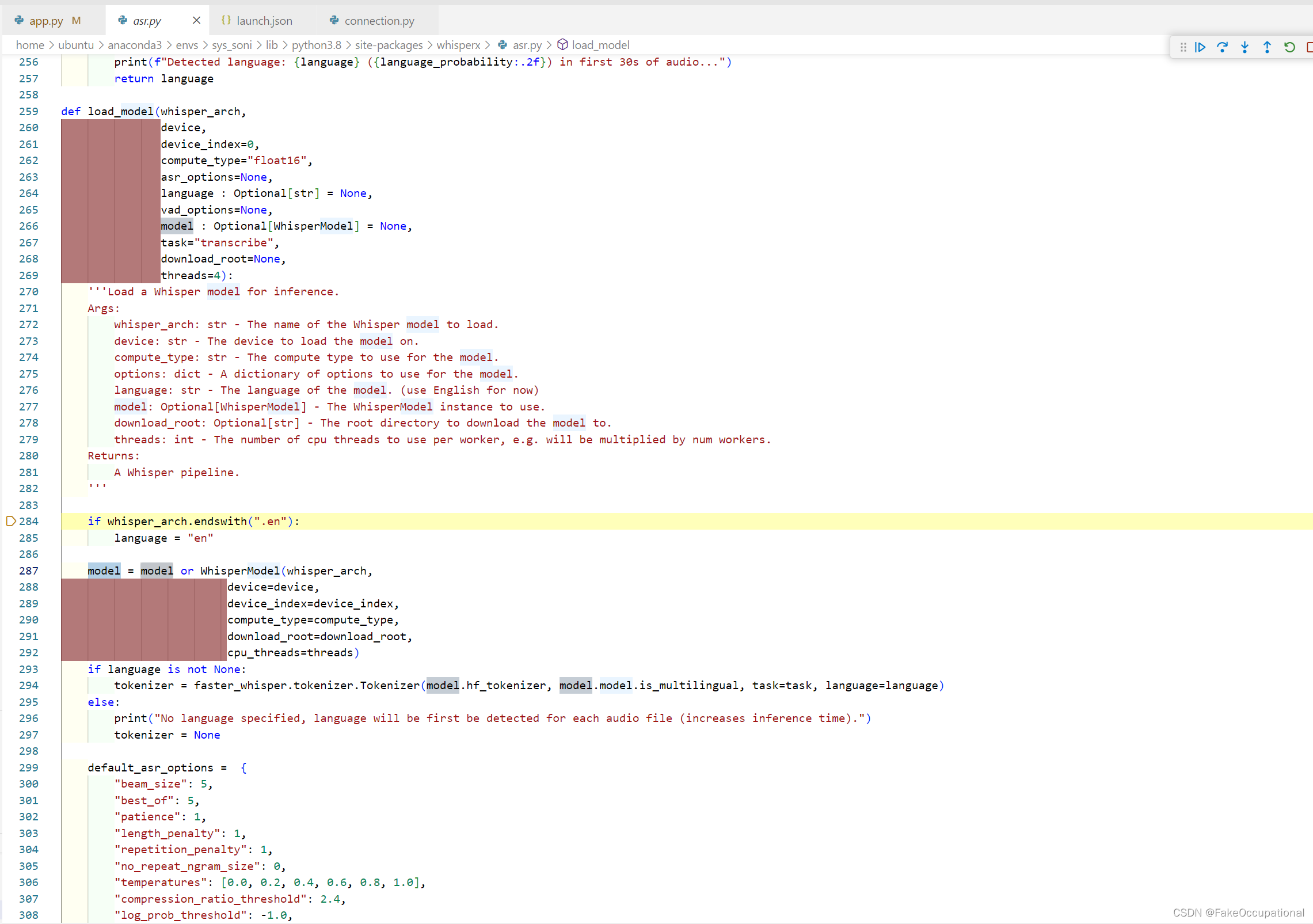
File "/home/ubuntu/anaconda3/envs/sys_soni/lib/python3.8/site-packages/whisperx/asr.py", line 287, in load_model
model = model or WhisperModel(whisper_arch,
File "/home/ubuntu/anaconda3/envs/sys_soni/lib/python3.8/site-packages/faster_whisper/transcribe.py", line 130, in __init__
self.model = ctranslate2.models.Whisper(
RuntimeError: Unable to open file 'model.bin' in model '/home/ubuntu/userfile/***/WhisperX'
在线下载faster_whisper的模型
python3 -c 'import faster_whisper; faster_whisper.download_model("tiny", "/tmp/tiny")'// https://github.com/SYSTRAN/faster-whisper/issues/116
(或者)本地转换
// https://github.com/SYSTRAN/faster-whisper
pip install transformers[torch]>=4.23
ct2-transformers-converter --model openai/whisper-large-v3 --output_dir whisper-large-v3-ct2 --copy_files tokenizer.json preprocessor_config.json --quantization float16
成功转换并运行
Set file complete.
No language specified, language will be first be detected for each audio file (increases inference time).
100%|█████████████████████████████████████| 16.9M/16.9M [00:02<00:00, 8.17MiB/s]
Lightning automatically upgraded your loaded checkpoint from v1.5.4 to v2.1.3. To apply the upgrade to your files permanently, run `python -m pytorch_lightning.utilities.upgrade_checkpoint ../../../.cache/torch/whisperx-vad-segmentation.bin`
Model was trained with pyannote.audio 0.0.1, yours is 3.1.0. Bad things might happen unless you revert pyannote.audio to 0.x.
Model was trained with torch 1.10.0+cu102, yours is 2.1.2+cu121. Bad things might happen unless you revert torch to 1.x.
whisperx-vad-segmentation.bin

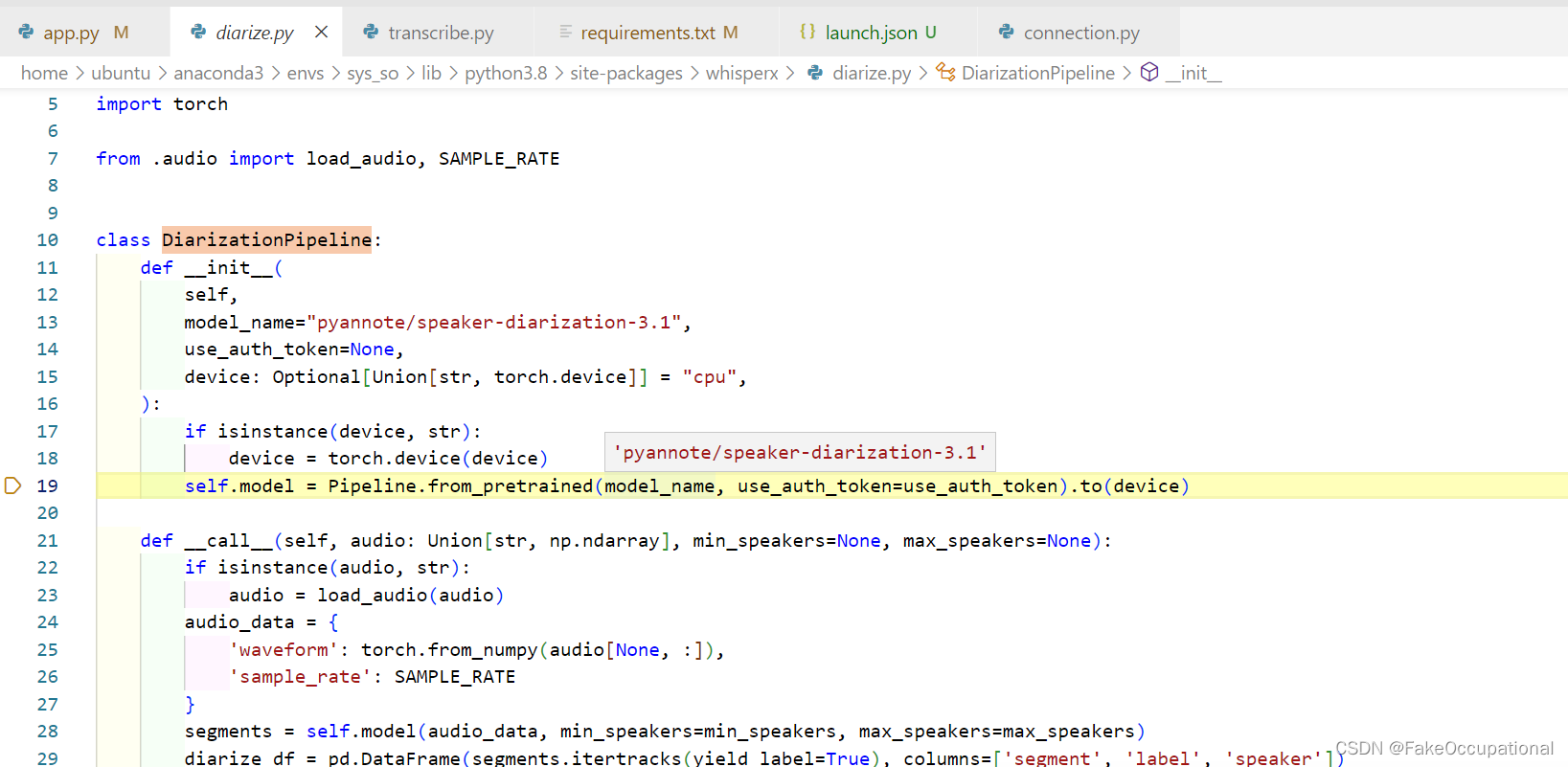
diarize_model = whisperx.DiarizationPipeline(use_auth_token=YOUR_HF_TOKEN, device=device)

- huggingface_hub.utils._errors.LocalEntryNotFoundError: An error happened while trying to locate the file on the Hub and we cannot find the requested files in the local cache. Please check your connection and try again or make sure your Internet connection is on.