概述
在使用es中如果遇到了集群不可写入或者部分索引状态unassigned,明明写入了很多数据但是查不到等等系列问题该怎么办呢?咱们今天一起看下常用运维命令。
案例
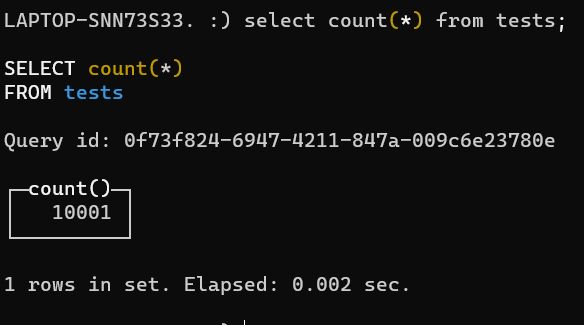
起初我们es性能还跟得上,随着业务发展壮大,发现查询性能越来越不行了,我们可以通过cat api查看索引的segments情况,比如下图:

如果发现索引的segment段过多,并且每个段数据量很小,那么就可以通过合并段的措施来提升检索性能。
那么我们在大批量迁移的时候,发现数据明明写入了但是少了很多?这是为什么呢,咱们还是可以通过cat api查看下线程池的状态,如下图:

通过查看写入线程池的状态观测是不是达到集群最大写入能力了,导致线程池执行了拒绝策略等等。更多的线程池说明可见官方文档:https://www.elastic.co/guide/en/elasticsearch/reference/current/modules-threadpool.html
还可以通过cat查看集群中节点数据分配情况如图:

上面都是介绍的cat api的使用方法,那么对于有的索引状态、集群状态不正常的时候我们怎么分析原因呢?这时候就得通过cluster api了,比如诊断当前集群什么不健康,如下图:
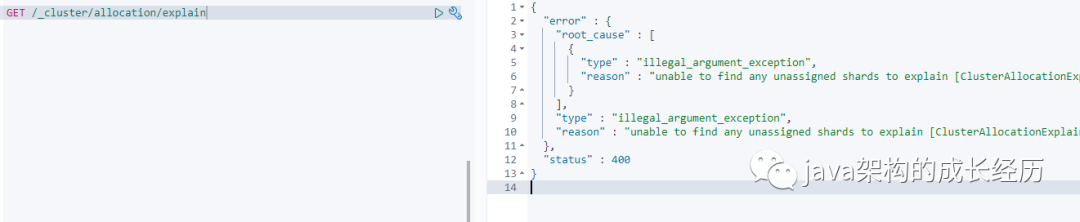
比如我们得到如下原因:
The node containing this shard copy recently left the cluster. Elasticsearch is waiting for it to return. If the node does not return within [%s] then Elasticsearch will allocate this shard to another node. Please wait.
那通过这个结果我们就可以清晰的了解到原来这个索引之所以是unassigned状态是因为,持有它的节点离开了集群,也就是说有个节点可能down了 和集群失去联系了。之前在中国电信就遇到过类似问题,由于集群中某个节点物理内存出现问题,未接到通知运维同事就临时停机修复了,当时集群部分索引状态就unassigned,也是通过explain查询到有一台物理节点失去联系了,联系运维同事后才知有一台集群出现了问题,好在当时只是存储了日志数据,停掉了所有的logstash,关闭了集群rebalance和自动分配功能,防止大量磁盘数据移动。
待该节点恢复后再开启rebalance和自动分配功能,开启logstash消费囤积在kafka中的日志数据。
包括我们升级es集群的时候也需要先关闭以上两个功能,具体api如下:
cluster.routing.allocation.enable :
all - (默认值)允许为所有类型的分片分配分片。
primaries - 仅允许分配主分片的分片。
new_primaries - 仅允许为新索引的主分片分配分片。
none - 任何索引都不允许任何类型的分片。
cluster.routing.rebalance.enable
all - (默认值)允许各种分片的分片平衡。
primaries - 仅允许主分片的分片平衡。
replicas - 仅允许对副本分片进行分片平衡。
none - 任何索引都不允许任何类型的分片平衡。
cluster.routing.allocation.allow_rebalance
all 始终 - 始终允许重新平衡。
indices_primaries_active - 仅在所有主分片激活时。
indices_all_active - (默认)仅当所有分片都激活时。
对于升级完后的集群或者部分节点正常后的es来说可能会发生数据恢复,那么这个时候如果想最短时间恢复完成,可以通过设置集群的并发度:
cluster.routing.allocation.node_concurrent_recoveries
该值最好等于磁盘的数量(对于raid0来说)。
总结
我们想要更好的使用es不能只注意查询语法的书写,需要全访问的深入的了解es,建议从头到尾过一遍官方文档,毕竟只有目前最了解孩子。
Elasticsearch系列经典文章
-
elasticsearch列一:索引模板的使用
-
elasticsearch系列二:引入索引模板后发现数据达到一定量还是慢怎么办?
-
elasticsearch系列三:常用查询语法
-
Elasticsearch 底层存储原理解密
-
Elasticsearch优化建议
-
干货 | Elasticsearch 8.X 节点角色划分深入详解