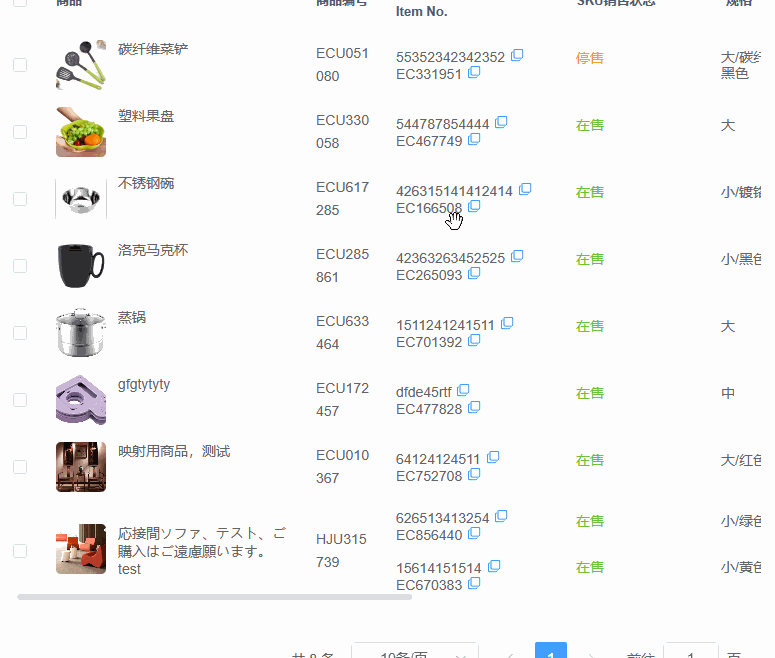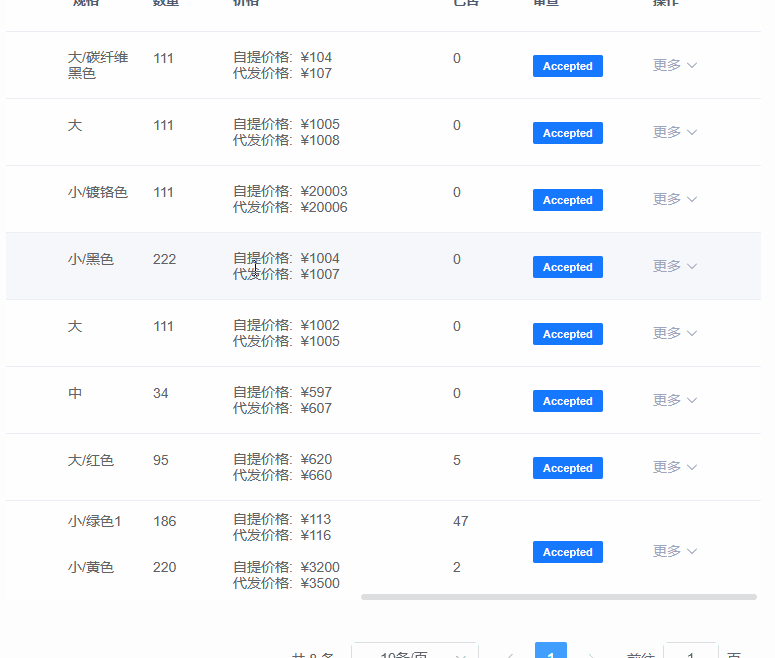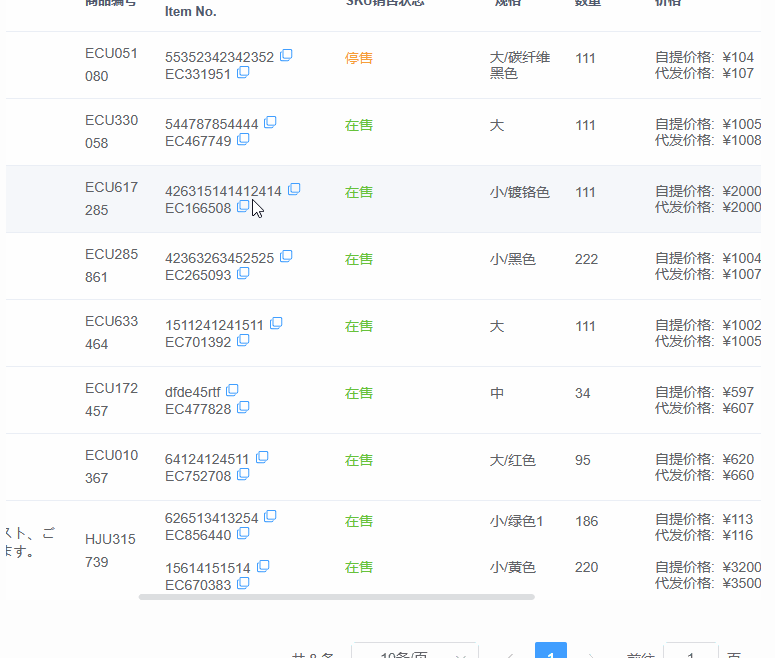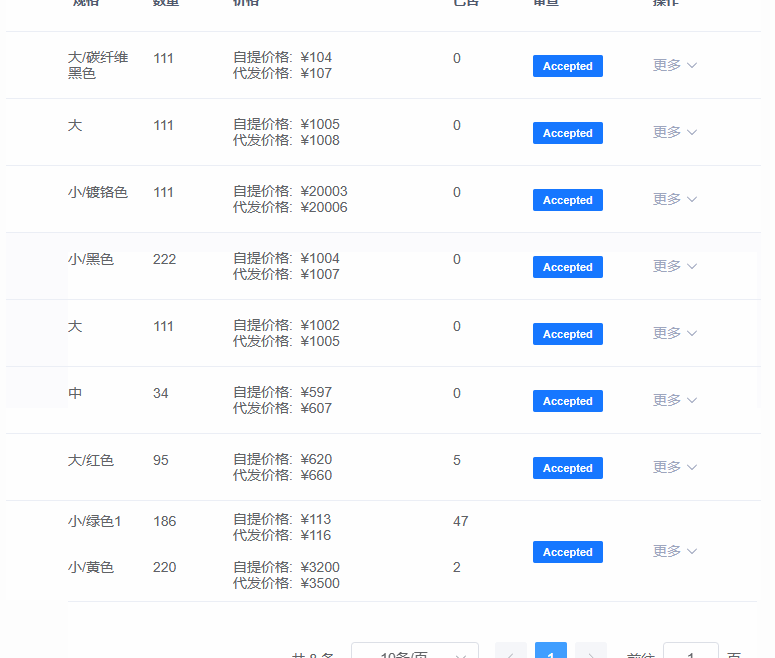
多模态大模型-CogVLm 论文阅读笔记
COGVLM: VISUAL EXPERT FOR LARGE LANGUAGEMODELS
- 论文地址 :https://arxiv.org/pdf/2311.03079.pdf
- code地址 : https://github.com/THUDM/CogVLM
- 时间 : 2023-11
- 机构 : zhipuai,tsinghua
- 关键词: visual language model
- 效果:(2023-11) :CogVLM-17B achieves state-of-the-art performance on 10 classic cross-modal benchmarks, including NoCaps, Flicker30k captioning, RefCOCO, RefCOCO+, RefCOCOg, Visual7W, GQA, ScienceQA, VizWiz VQA and TDIUC, and ranks the 2nd on VQAv2, OKVQA, TextVQA, COCO captioning, etc., surpassing or matching PaLI-X 55B
目录
多模态大模型-CogVLm 论文阅读笔记
- 多模态大模型-CogVLm 论文阅读笔记
- COGVLM: VISUAL EXPERT FOR LARGE LANGUAGEMODELS
- 目录
- 简介
- 论文大致翻译
- 介绍:
- 方法
- 结构
- 预训练
- 对齐
- 实验
- IMAGE CAPTIONING
- VISUAL QUESTION ANSWERING
- VISUAL GROUNDING
- INSTRUCTION FOLLOWING IN REAL-WORLD USER BEHAVIOR
- ABLATION STUDY (消融实验)
- 总结
- 代码部分
- 参考链接
简介
作者构建了一个名为CogVLM的开源的视觉语言集成模型,其关键点如下:
- 与目前流行的将 图像特征映射到语言模型的输入空间的 浅层方法不同,CogVLM通过一个在注意力层和FFN层构建的可训练的视觉专家模块 作为桥梁将冻结的预训练的语言模型和图像编码器连接起来。
- 开源
- 在各种数据集上达到SOTA或者前列的水平
- 这种视觉语言特征的深度融合可以在NLP任务中能够不牺牲性能
论文大致翻译
介绍:
视觉语言模型能力多样且强大,许多视觉和跨模态的任务可以表达为下一个token的预测。比如image captioning、VQA、visual grounding、 segmentation。而且上下文的能力也可以在VLMs扩大时在下游任务中表现出来。
然而,训练大型语言模型已经很不容易了,更难的是并且从头开始训练具有和训练有素的纯语言模型(如 LLAMA2)相同 NLP 性能的 VLM。因此自然而然就想到如何从现成的预训练语言模型中训练VLM。
流行的浅层对齐方法比如BLIP-2 这种方法速度快但是效果不如联合训练的视觉语言模型模块如PaLI-X。至于通过浅层对齐的聊天模式的VLM如MiniGPT-4,LLAVA和VisualGLM, 其视觉能力的羸弱常出现幻觉。所以在保持NLP能力的大语言模型中的同时加入顶级的视觉理解能力是否可能呢?
CogVLM 给出了答案,在作者看来,浅层对齐方法性能较差的根本原因在于视觉和语言信息之间缺乏深度融合。这种灵感源于p-tuning和LoRA之间在微调效果中的比较,这里 p-tuning 在输入中学习任务前缀embedding,而 LoRA 通过低秩矩阵调整每一层的模型权重。结果呢,LoRA表现的更好更稳健。同样的现象也可能出现在VLM任务中,因为浅层的对齐方法中图像特征就像 p-tuning 中的前缀embedding一样。p-tuning 和浅层对齐的性能下降的更详细原因包括:
- 语言模型中的冻结权重针对文本进行训练。视觉特征在输入文本空间中没有完美的对应物。因此,经过多层转换后,视觉特征可能不再匹配深层权重的输入分布。
- 在预训练期间,图像字幕任务的先验,例如写作风格和字幕长度,只能在浅层对齐方法中编码到视觉特征中。它削弱了视觉特征和内容之间的一致性。
一种可能的解决方案是将语言模型去适应图像-文本联合训练,PaLI (Chen et al., 2022b) 和 Qwen-VL (Bai et al., 2023a) 采用的方法。然而,通过这种方式,NLP 能力被破坏,这可能会影响以文本为中心的任务,例如基于图像的诗歌创建或介绍图像的背景故事。根据 PaLM-E (Driess et al., 2023),在 VLM 预训练期间,将大语言模型同时设置为可训练的,会导致灾难性遗忘,8B 语言模型的 NLG 性能下降 87.3%
CogVLM替换为给语言模型添加了一个可训练的Visual expert。在每一层中,序列中的图像特征使用一个新的不同的QKV矩阵和带有文本特征的MLP层。Visual expert在保持FLOPs不变的情况下(?为啥参数增加FLOPS却不变?)将参数数量加倍。由于原语言模型中的所有参数都是固定的,所以当输入序列不包含图像时,其表现与原语言模型相同。
作者从Vicuna-7B训练而来的CogVLM-17B在14个经典的跨模态基准上实现了最先进或第二好的性能,包括 1)图像描述数据集:NoCaps、Flicker30k、COCO, 2)VQA数据集:VQAv2、OKVQA、GQA、TextVQA、VizWiz,3)视觉基础数据集:RefCOCO、RefCOCOCO+、RefCOCOg、Visual7W,4)多选数据集:TDIUC、ScienceQA。作者还训练了来自ChatGLM-12B(Du et al.,2021)的CogVLM-28B-zh,以支持商业使用的英语和汉语,这不包括在本文中。
方法
结构
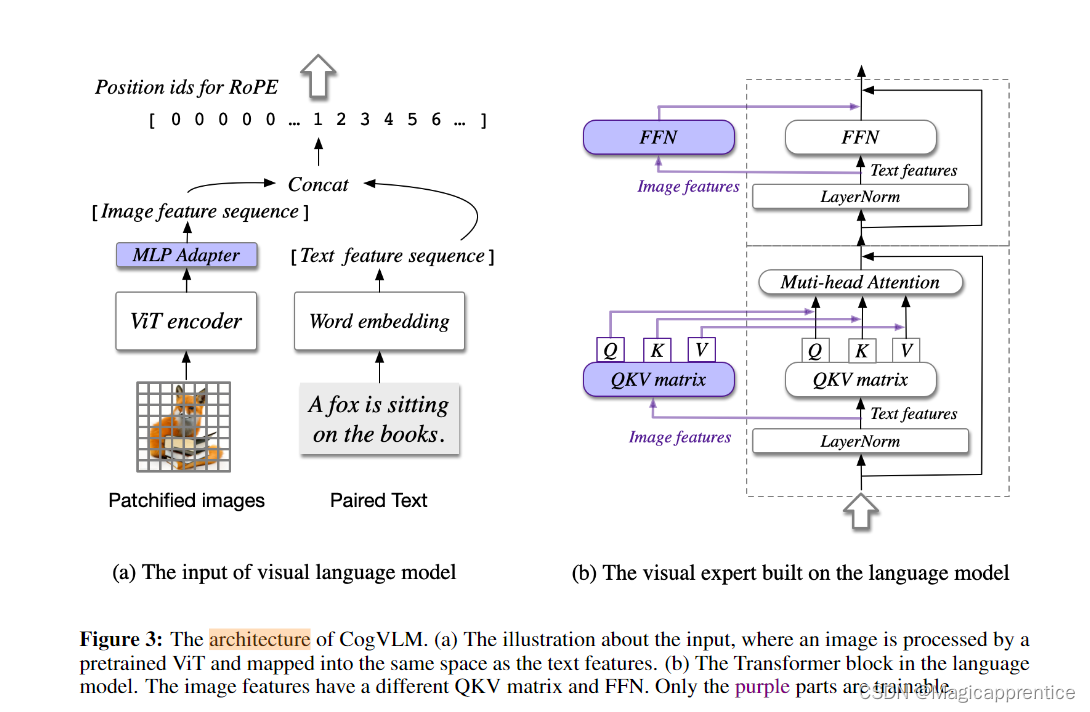
图3: CogVLM 的架构。(a) 视觉语言模型的输入,其中图像由预训练的 ViT 处理,并映射到与文本特征相同的空间。(b) 语言模型中的 Transformer 块。图像特征有不同的 QKV 矩阵和 FFN。只有紫色部分是可训练的。
CogVLM 模型包括四个基本组件:视觉转换编码器 (ViT) 、MLP 适配器、预训练的大型语言模型 (GPT) 和视觉专家模块。图 3 显示了 CogVLM 架构的概述。组件的设计和实现细节如下:
- ViT encoder,在 CogVLM-17B 中使用了预训练的 EVA2-CLIP-E (Sun et al., 2023)。ViT编码器的最后一层被删除,因为它专门用于聚合[CLS]特征进行对比学习。
- MLP adapter , MLP 适配器是一个两层 MLP (SwigLU (Shazeer, 2020)),用于将 ViT 的输出映射到与词嵌入中的文本特征相同的空间中。所有图像特征在语言模型中使用相同的位置 id。
- Pretrained large language model,CogVLM 的模型设计与任何现成的 GPT 风格的预训练大型语言模型兼容。具体来说,CogVLM-17B 采用 Vicuna-7BV1.5 (Chiang et al., 2023) 进行进一步训练。因果掩码应用于所有注意力操作,包括图像特征之间的注意力。
- Visual expert module,在每一层都添加了一个视觉专家模块,以实现视觉语言特征的深度对齐。具体来说,每一层的视觉专家模块由 QKV 矩阵和每一层的 MLP 组成。QKV 矩阵和 MLP 的形状与预训练语言模型的形状相同,并从预训练的语言模型中初始化。动机是语言模型中的每个注意力头都捕获了某些方面确切的语义信息,而可训练的视觉专家可以转换图像特征以与不同的头部对齐,从而实现深度融合。
假设注意力层的输入隐藏状态形式上是:
X
∈
R
B
×
H
×
(
L
I
+
L
T
)
×
D
X\in\R^{B\times H \times (L_I + L_T) \times D}
X∈RB×H×(LI+LT)×D ,其中
B
:
b
a
t
c
h
s
i
z
e
;
L
I
和
L
T
:
图像和文字的长度,
H
是注意力的头数,
D
是
h
i
d
d
e
n
s
i
z
e
B:batchsize;L_I 和 L_T:图像和文字的长度,H 是注意力的头数,D是hidden size
B:batchsize;LI和LT:图像和文字的长度,H是注意力的头数,D是hiddensize ,在视觉专家的注意力中,
X
X
X 首先被拆分为图像的隐藏状态
X
I
X_I
XI 和文本隐藏状态
X
T
X_T
XT ,注意力的计算为:
A
t
t
e
n
t
i
o
n
(
X
,
W
I
,
W
T
)
=
s
o
f
t
m
a
x
(
T
r
i
l
(
Q
K
T
)
D
V
Attention(X,W_I,W_T) = softmax( \frac {Tril(QK^T)}{\sqrt D} V
Attention(X,WI,WT)=softmax(DTril(QKT)V
Q
=
c
o
n
c
a
t
(
X
I
W
I
Q
,
X
T
W
T
Q
)
,
K
=
c
o
n
c
a
t
(
X
I
W
I
K
,
X
T
W
T
K
)
,
V
=
c
o
n
c
a
t
(
X
I
W
I
V
,
X
T
W
T
V
)
,
这里
W
I
,
W
T
Q=concat(X_IW_I^Q,X_TW_T^Q), K =concat(X_IW_I^K,X_TW_T^K),V=concat(X_IW_I^V,X_TW_T^V),这里W_I,W_T
Q=concat(XIWIQ,XTWTQ),K=concat(XIWIK,XTWTK),V=concat(XIWIV,XTWTV),这里WI,WT是视觉专家和原始语言模型的QKV矩阵,Tril(·)表示下三角掩码。视觉专家在FFN层中的表现相似:
F
F
N
(
X
)
=
c
o
n
c
a
t
(
F
F
N
I
(
X
I
)
,
F
F
N
T
(
X
T
)
)
,
FFN(X) = concat(FFN_I(X_I),FFN_T(X_T)),
FFN(X)=concat(FFNI(XI),FFNT(XT)),
其中 F F N I FFN_I FFNI和 F F N T FFN_T FFNT是视觉专家和原始语言模型的FFN。
预训练
数据,用于预训练的图像-文本对都是公开的,包括 LAION-2B 和 COYO-700M。在删除损坏的 URL、NSFW (不适合上班时间浏览(Not Safe For Work))图像、带有噪音字幕的图像、具有政治偏见的图像和纵横比 > 6 或 < 1/6 的图像后,剩下大约 1.5B 图像进行预训练。
作者还制作了一个包含40M张图像的visual grounding数据集。图像标题中的每个名词都与边界框相关联,以指示图像中的位置。构建过程基本遵循Peng等人的方法,他们通过spaCy提取名词(Honnibal & Johnson, 2015),并使用GLIPv2预测边界框(Zhang et al., 2022)。图像-文本对从LAION-115M中采样,这是Li等人(2023)过滤的LAION-400M的子集。我们过滤并保留了4000万张图像的子集,以确保75%以上的图像包含至少两个边界框。
训练
预训练的第一阶段是针对 image captioning 损失,即文本部分的下一个token预测,作者在上述介绍的1.5B 图像-文本对 上训练CogVLM-17B模型,进行了批大小为8,192的12万次迭代。预训练的第二阶段是混合图片描述(image captioning)和 指称表达理解Referring Expression Comprehension (REC)。REC是在给定对象的文本描述的情况下预测图像中的该对象的边界框的任务,以VQA的形式进行训练,即“问题:物品(object)在哪里?”和“答案:[[x0, y0, x1, y1]]”。x和y坐标的范围是000到999,(图像中归一化的位置),只考虑“答案”部分中下一个令牌预测的损失。我们在上面介绍的文本-图像对和visual grounding数据集上预训练了60,000次迭代,批大小为1,024。在最后的30,000次迭代中,作者将输入分辨率从224 × 224更改为490 × 490。可训练参数的总数为6.5B,预训练消耗约4,096 A100×days。
对齐
作者在更广泛的任务上进一步微调了 CogVLM,以便将 CogVLM 与任何主题的自由形式的指令对齐。作者将微调模型命名为 CogVLM-Chat。如图 2 和图附录中的示例所示,CogVLM-Chat 可以成功地与各种指令保持一致,从而能够与人类进行灵活的交互。
数据。监督微调 (SFT) 的高质量数据是从 LlaVA-Instruct (Liu et al., 2023b)、LRV-Instruction (Liu et al., 2023a)、LLaVAR Zhang et al. (2023) 和内部数据集收集的,总共有大约 500,000 个 VQA 对。SFT 数据的质量至关重要,但 LLAVA-Instruct 由仅语言形式的GPT-4 的pipline生成,因此错误是不可避免的。特别地,作者通过人工检查和注释来纠正 LLAAVA-Instruct 数据集中的错误。
SFT。对于监督微调,作者训练了 8000 次迭代,批量大小为 640,学习率为 10-5 和 50 次预热迭代
为了防止过度拟合数据集的文本答案,作者使用了较小的学习率(其他参数的 10%)来更新预训练的语言模型。除ViT编码器外的所有参数在SFT期间都是可训练的。
实验
为了严格验证作者的基础模型的卓越性能和鲁棒性,作者对一系列多模态基准进行了定量评估。这些基准可以分为三个广泛的领域,涵盖了比较全面的评测范围:
- Image Captioning。图片描述任务的主要目的是对于给定图像生成总结主要内容的文本。作者利用包括NoCaps (Agrawal et al., 2019)、COCO (Lin et al., 2014)、Flickr30K (Plummer et al., 2015)和TextCaps (Sidorov et al., 2020)在内的有代表性的数据集进行评估。
- **Visual Question Answering.**视觉问答。VQA 任务要求模型回答根据给定的图像可能关注的不同视觉内容的问题。作者的评估涵盖了不同的数据集,包括 VQAv2 (Antol et al., 2015)、OKVQA (Marino et al., 2019)、TextVQA (Singh et al., 2019)、VizWiz-VQA (Gurari et al., 2018)、OCRVQA (Mishra et al., 2019)、ScienceQA (Lu et al., 2022b) 和 TDIUC (Shrestha et al., 2019)
- Visual Grounding.涉及一组任务,这些任务在句子中的文本提及与图像的特定区域之间建立相关链接。作者在典型数据集上评估模型,包括 Visual7w (Zhu et al., 2016)、RefCOCO (Liu et al., 2017)、RefCOCO+ 和 RefCOCOg 以确保完整性。
IMAGE CAPTIONING
作者在上述Image Captioning的四个基准上评估预训练基础模型的图像描述能力。在 Nocaps 和 Flickr 数据集的零样本评估中,评估了模型在描述长尾视觉概念方面的精度。此外,作者还展示了对 COCO 和 TextCaps 数据集进行微调的结果。
详细性能如表1所示。总体而言,作者的模型全面实现了SOTA或相当的性能。具体来说,在 NoCaps 基准测试中,作者的基础模型在四个拆分中优于以前的最佳方法 GIT2,在out-of-domain中最多领先5.7 个点,而仅使用 10% 的预训练数据(1.5B vs 12.9B)。在 Flickr 基准测试中,作者的模型实现了 94.9 的 SOTA 分数,超过了同时期发布的 Qwen-VL 模型 9.1 分。这些结果证明了作者的预训练模型在图像字幕任务上的显着能力和稳健性。作者还在 COCO (Lin et al., 2014) 和 TextCaps 上进行评估,后者是专门为将给定图像中的文本信息集成到描述中而设计的。尽管在没有专用 OCR 数据的情况下进行训练,但令人鼓舞的是,作者的基础模型揭示了显着的文本阅读能力,并获得了与 PaLI-X-55B 相当的性能,并且优于之前在相同规模的最佳模型 PaLI-17B, 9.1 分。
VISUAL QUESTION ANSWERING
视觉问答是一项验证模型多模态能力的任务,这需要模型掌握包括视觉语言理解和常识推理在内的技能。作者在 7 个 VQA 基准上评估模型:VQAv2、OKVQA、GQA、VizWiz-QA、OCRVQA、TextVQA、ScienceQA,涵盖了广泛的视觉场景。在训练集上训练基础模型,并在所有基准测试的公开可用 val/ test 集上对其进行评估,其中两者都采用开放词汇生成设置,并且没有 OCR pipeline输入。
如表 2 所示,与 PALI-17B 和 Qwen-VL 等类似尺寸的模型相比,作者的模型在 7 个基准测试中的 6 个上实现了最先进的性能。模型甚至超过了在多个基准上更大规模的模型,例如 VizWiz-QA 上的 PaLI-X-55B(test-std +5.1、test-dev +3.8)、VQAv2 上的 PALM-E-84B(test-dev +4.2)和 OKVQA(+1.4),VQAv2 上的 Flaminggo-80B(test-dev +2.7、test-std +2.6)、VizWiz-QA(test-dev +10.7、test-std +10.4)和 TextVQA(+15.6)。模型还在 ScienceQA (Lu et al., 2022b) 的多模式拆分(即 IMG)上实现了 92.71 的最佳分数,实现了新的 SOTA。这些结果表明,该基础模型可以作为一个强大的多模态主干,能够解决各种视觉问答任务。
一般表现。为了与Unified IO(Lu et al.,2022a)、QwenVL(Bai等人,2023a)、mPLUG DocOwl(Ye等人,2021)和其他在多模态任务的广义范式中训练的模型进行公平比较,作者使用由数十个多模态数据集组成的数据进一步训练了一个统一模型,并使用一致的检查点进行评估。数据集包括14个QA数据集,如VQAv2、OKVQA,并扩展到TextVQA,以及图像描述数据集,包括COCO图像描述、TextCaps和在预训练阶段使用的图像描述数据集。实验结果表明,多任务学习不会显著降低模型在单个任务上的性能,CogVLM在所有任务中的性能仍然领先。
VISUAL GROUNDING
为了赋予模型一致、交互式的视觉基础能力,作者收集了一个高质量的数据集,涵盖了4种基础数据:(1)基础描述(GC)-图像描述数据集,其中字幕中的每个名词短语后面都有相应的指代边界框;(2) 指代生成(REG)-面向图像的数据集,图像中的每个边界框都用描述性文本表达式进行注释,该表达式准确地表征并引用特定区域内的内容;(3) 指代理解(REC)-面向文本的数据集,每个文本描述都用多个引用链接进行注释,将短语与相应的框相关联;(4) Grounded Visual Question Answering(GroundedVQA)-VQA风格的数据集,其中问题可能包含给定图像中的区域引用。基础数据的来源都是公开的,包括Flickr30K Entities(Plummer et al.,2015)、RefCOCO(Kazemzadeh et al.,2014;毛等人,2016;余等人,2016)、Visual7W(Zhu et al.,2016),VisualGenome(Krishna et al.,2017)和Grounded CoT VQA(Chen et al.,2023a)。本节中的[box]的格式为[[x0,y0,x1,y1]]。
在使用作者的40M视觉基础数据集的第二个预训练阶段之后,继续在这个高质量的数据集上训练模型,产生了一个广义基础增强模型CogVLMGrounding。值得注意的是,整理的数据集展示了视觉基础能力的多功能性,许多数据集可以在不同的任务中进行调整和重新调整用途。例如,可以重新制定grounded 描述数据集,以适应REG和REC任务。以“一个男人[box1]和一个女人[box2]走在一起。”为例,这可以被重新定义为问答对,如(“描述这个区域[box2]。”,“一个女人。”)和(“男人在哪里?”,“[box1]”)。类似地,REC数据集可以通过切换输入和输出转换为REG任务,反之亦然。然而,某些转换可能会导致歧义。例如,当出现标题“一个人[box1]在跑,而另一个人[box2]在看”中的单独查询“另一个人在哪里?”时,[box1]和[box2]之间的区别变得不清楚,可能会导致错误。
表 4 显示了标准视觉基础基准的结果。发现通用模型全面实现了最先进的性能,与之前的或并发模型相比具有显着优势。此外,还评估了模型在每个单独的基准训练集上训练的模型的专家性能,以便与专用于每个任务的最佳模型进行公平比较。如表 4 的底部所示,模型在 9 个拆分中的 5 个上实现了 SOTA 性能,在其他子集上实现了兼容结果。这些结果表明,模型结合了作者的训练范式具有显著的视觉基础能力。
INSTRUCTION FOLLOWING IN REAL-WORLD USER BEHAVIOR
为了评估CogVLM-Chat 模型在现实世界用户行为下的能力,作者进一步使用 TouchStone (Bai et al., 2023b),这是多模态语言模型的广泛基准。表 5 显示了生成和候选答案 GPT-4 (OpenAI, 2023)的 相似度得分,表明 CogVLM-Chat 显着优于所有其他公开可用的 VLM。
ABLATION STUDY (消融实验)
为了了解各种组件和设置对模型的性能的影响,作者对 6,000 次迭代和 8,192 的批量大小进行了广泛的消融研究。表 6 总结了以下方面的结果:
模型结构和调整参数。作者研究了仅调整 MLP 适配器层或调整所有 LLM 参数和适配器而不添加 VE 的有效性,以及修改 VE 架构以在每 4 个 LLM 层添加完整的 VE,或者仅在所有层添加配备 FFN 的 VE。从结果中可以看到,仅调整适配器层(例如,BLIP2)可能会导致浅层对齐,性能明显较差,并且减少每个 LLM 层的 VE 层数或 VE 参数都遭受显着的退化。
初始化方法。作者研究了从LLM初始化VE权重的有效性,性能略有下降表明了从LLM初始化VE权重是积极有效的。
视觉注意力掩码。根据经验发现,与全掩模相比,在视觉标记上使用因果掩模将产生更好的结果。作者假设对这一现象的可能解释是因果掩码更适合LLM的固有结构。
图像SSL损失。作者研究了图像特征的自监督学习损失,其中每个视觉特征预测视觉自我监督下一个位置的CLIP特征。与 PaLI-X (Chen et al., 2023b) 的观察结果一致,发现它对下游任务没有改进,尽管我们确实在早期实验中观察到了小模型的改进。
EMA。作者在预训练期间利用 EMA(指数移动平均),这通常会带来各种任务的改进。
总结
在本文中,作者介绍了 CogVLM,这是一种开放的视觉语言基础模型。CogVLM 将 VLM 训练的范式从浅层对齐转移到深度融合,在 10 个经典的多模态基准上实现了最先进的性能。
VLM 训练仍处于起步阶段,有许多方向需要探索,例如更好的 SFT 对齐、RLHF 和反幻觉。由于之前著名的VLM大多是闭源的,相信CogVLM将成为未来多模态研究的坚实基础。
代码部分
todo
参考链接
- https://arxiv.org/abs/2311.03079