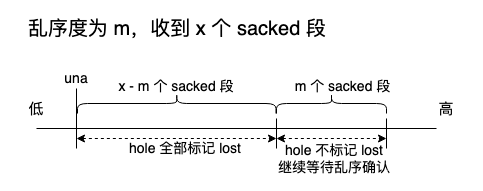
前言:之前我们关于llama2的相关内容主要停留在gc层面,没介绍chat模式,本文将简单介绍下llama2.c的chat模式如何跑起来。训练就算了,没卡训练不起来的,但是用CPU来对别人训练好的模型进行推理还是绰绰有余的,对的,这里没有GPU,不用烧钱,只需要一块CPU和足够的内存空间。
这篇文章自认为比较水,哈哈哈。
之前文件如下:
-
[玩转AIGC]sentencepiece训练一个Tokenizer(标记器)
-
[玩转AIGC]如何训练LLaMA2(模型训练、推理、代码讲解,并附可直接运行的kaggle连接)
-
[玩转AIGC]LLaMA2训练自己的中文故事撰写神器(content generation)
一、git代码
git clone https://github.com/karpathy/llama2.c.git
二、下载模型
hf 地址:
Llama-2-7b-chat
由于llama2.c目前只支持float32,所以不支持Llama-2-7b-cha-hf
最主要的模型为以下几个:
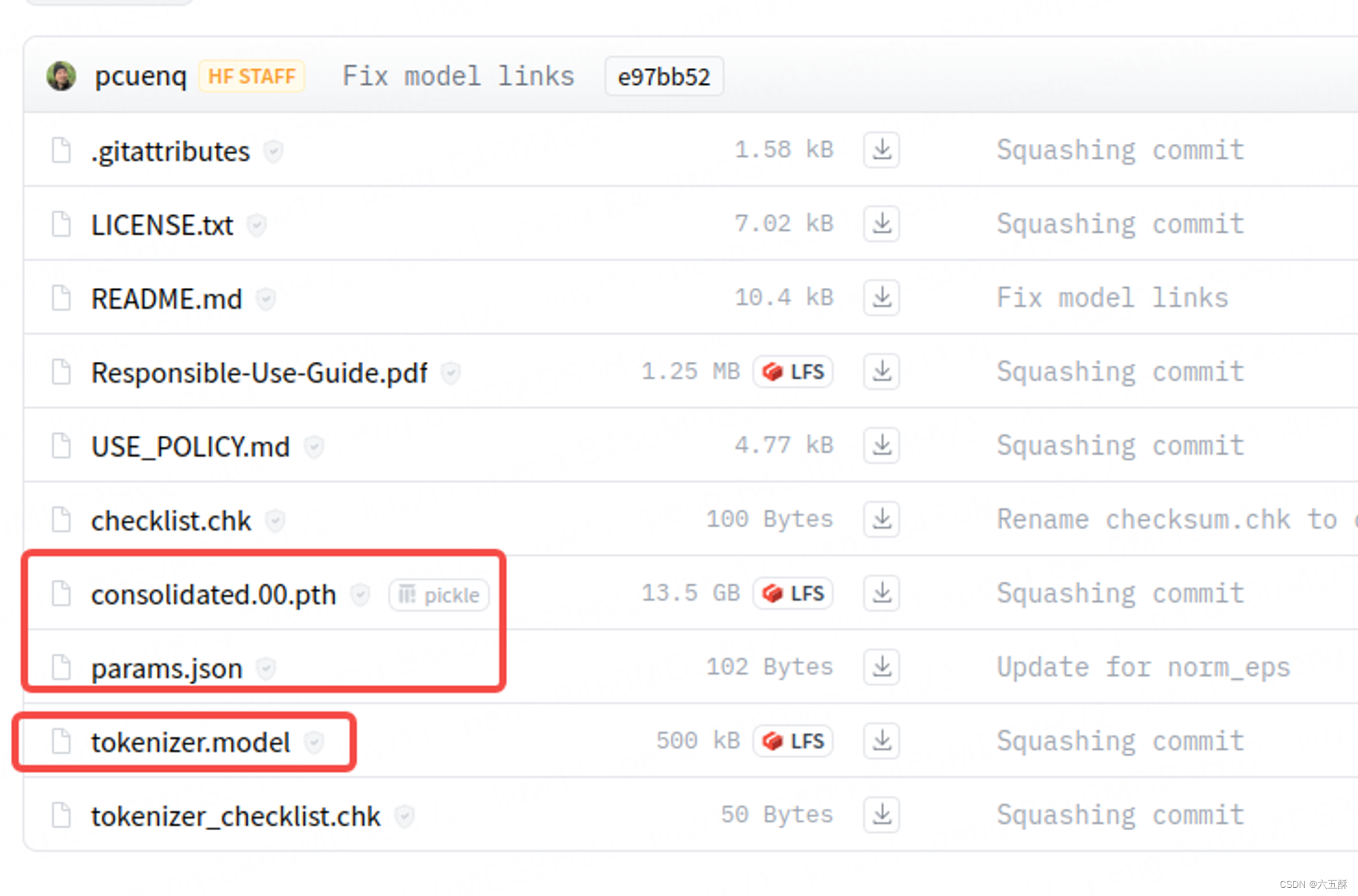
下载代码如下:
要把token改为你自己的token,怎么获取token就不赘述了,网上一大堆文章。
import huggingface_hub
huggingface_hub.snapshot_download(
"meta-llama/Llama-2-7b-chat",
local_dir="./Llama-2-7b-chat",
token="*****************"
)
下载后的模型放在git下来的项目根目录,然后就可以开始转换了,转换时,为了避免死机,可把交互内存空间改大一点,这里用的cpu转换,不需要gpu
三、模型转换
python3 export.py llama2_7b_chat.bin --meta-llama Llama-2-7b-chat
四、编译
make run
五、运行及其结果
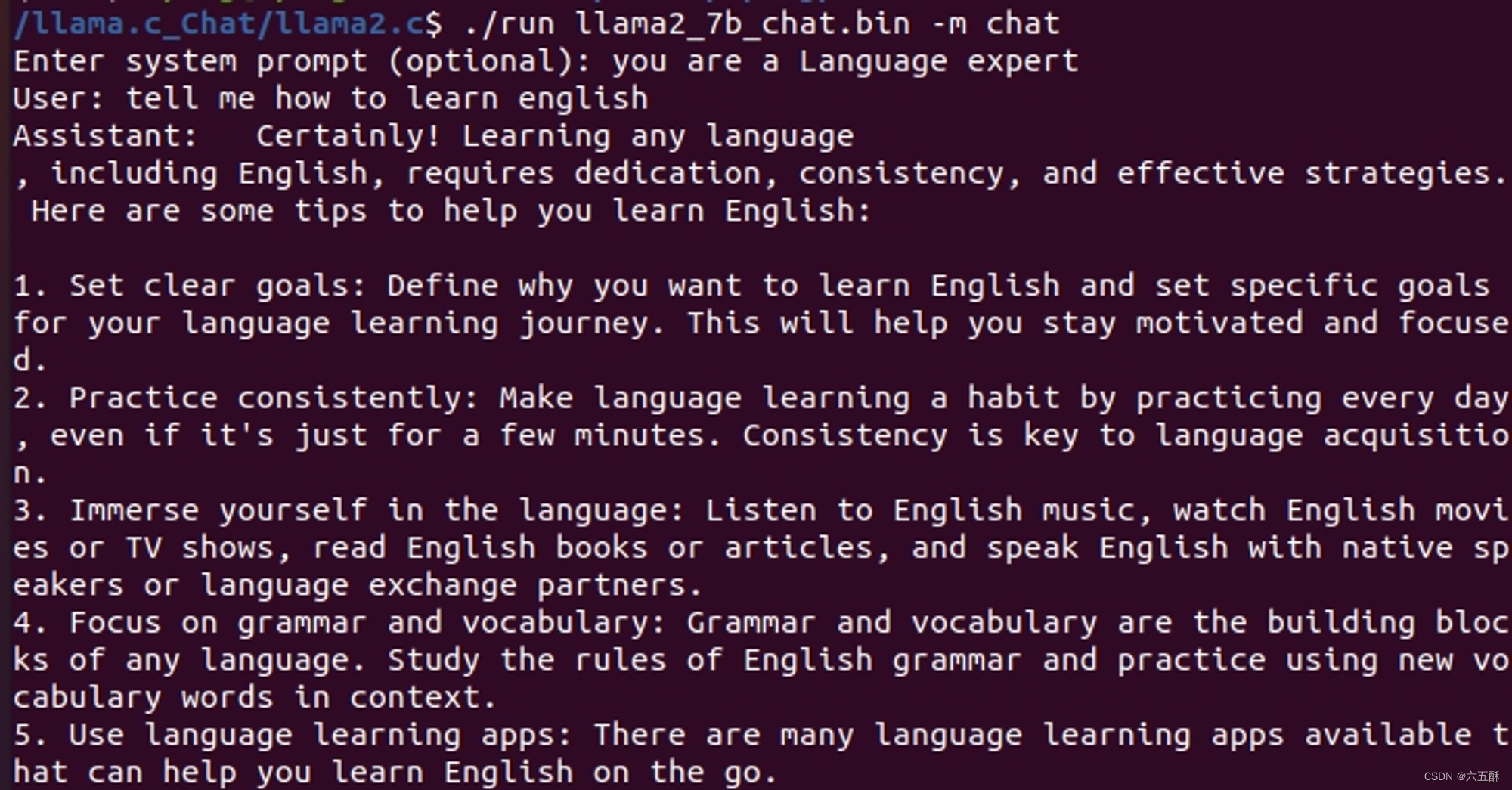
CPU直接跑,无需显卡,就是慢,哈哈哈!!无卡也能体验在自己的电脑上跑AIGC,杠杆的!!
./run llama2_7b_chat.bin -m chat
输入you are a Language expert 回车
再输入tell me how to learn english 回车

输出结果:
预告:后面将拿Stable Diffusion开刀,对里面的内容一探到底,并让你能够在移动手机上跑起来。


![[枚举涂块]画家问题](https://img-blog.csdnimg.cn/direct/c1508f65876249f99d4b47e1ecdd8391.jpeg)