传统 tcp 以序列号差度量乱序,比如 1, 2, 3, 4, 6, 7, 8, 5 这个序列的 5 延后了 3 个段,就称这个序列的乱序度为 3。
如果乱序度为 m,则序列 n, n + 1 + k, n + 1 + k + r, …, n + 1 + k + r + x 中,只要 (n + 1 + k + r + x) - (n + 1) = k + r + x < m,就不会判定为丢包,因为乱序度 m 意味着 n + 1 及后续 hole 可能在 k + r + x 达到 m 前被确认。
只考虑顺序而不考虑数量时,更松散的约束是,上述序列中只要 sacked 段数量 < m,都不判定为丢包,因为乱序度为 m 意味着 n + 1 及后续 hole 在顺序 sacked 段数量到达 m 前被确认。
既然如此,丢包标记就很简单了。以松散顺序约束为例,如果被 sacked 段数量 > m 时,只要在最后面保留 m 个被 sacked 段,前面的 hole 全部标记为 lost 即可,因为最后面 m 个 sacked 段间的 hole 仍在乱序允许之内。
如下图:
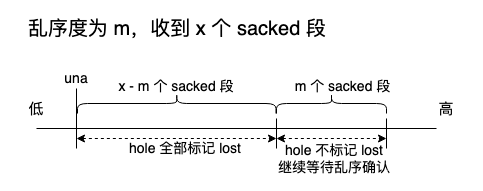
但这个乱序检测机制有问题。
首先,如果最后面 m 个 sacked 段后面再没有足够的 sacked 超过 m,就不会触发 mark lost,另外,由于重传段的序列号不会变,重传段将无法再次被该机制 mark lost,因此这种乱序检测机制下 mark lost 只能 oneshot,重传丢了只能等 rto。
现代 rack 乱序检测机制解决了这些问题,它采用了时间序,重传段和原始段的时间序可明确区分,因此 rack 可源源不断重复 mark lost,这就不会导致 window 憋死盲等 rto。rack 是解耦重传和拥塞控制的核心,有了 rack,就有源源不断的段(可重复 mark lost 的段和新段)填充任意大小 cwnd,而 cwnd 完全由 cc 决定。
rack 思想很简单,乱序是链路属性而不是协议属性。一个 rtt 内发送 cwnd 个段,链路上最多有 cwnd 段,最极端情况,该 cwnd 的第一个段和最后一个段乱序交换,一个段至多延迟 1 个 rtt 被确认,因此 rack 的乱序时间窗口 reo_wnd 在 (0, rtt) 内。乱序度不由序列号差决定,而由乱序时间窗口约束。
rack 不再使用序列号做差来计算乱序度,而通过 dsack 确认,每收到一个 dsack,reo_wnd 就增加一点点,最大增加到一个 rtt 不会再涨。
有了 rack,reordering 参数的意义就不大了,因为在时间序的 rtt 明确约束下,手调乱序度就完全没必要了。值得一提的是,rack 的思想早在 1994 年的 vegas 中就有提及,几乎和 google 的 rack 完全一致,详见 vegas 论文 3.1 New Retransmission Mechanism 小节。
rack 乱序检测要比传统基于序列号的乱序检测更加有效,更加合理,且更加简洁,经理觉得呢?
浙江温州皮鞋湿,下雨进水不会胖。