前言:
收到回复评论说,按照我之前文章写的:
爬虫工作量由小到大的思维转变---<第三十一章 Scrapy Redis 初启动/conn说明书)>-CSDN博客
在启动scrapy-redis后,往redis丢入url网址的时候遇到:
TypeError: ExecutionEngine.crawl() got an unexpected keyword argument 'spider
整得人都崩溃了....
好嘛,来解决这个问题!
正文:
代码
__author__ = '大河之J天上来'
from scrapy import cmdline
from scrapy_redis.spiders import RedisSpider
class DahezhijianSpider(RedisSpider):
name = "Dahezhijian"
redis_key = 'da:he'
def parse(self, response):
print(response.text)
if __name__ == '__main__':
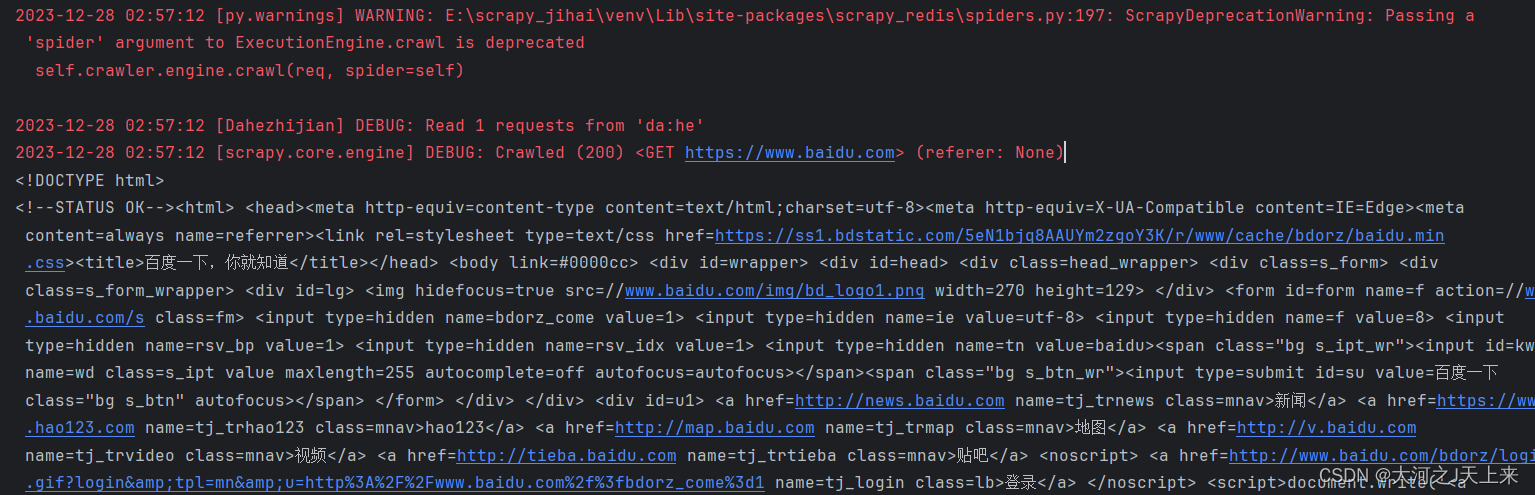
cmdline.execute(['scrapy','crawl','Dahezhijian'])还原问题(截图):
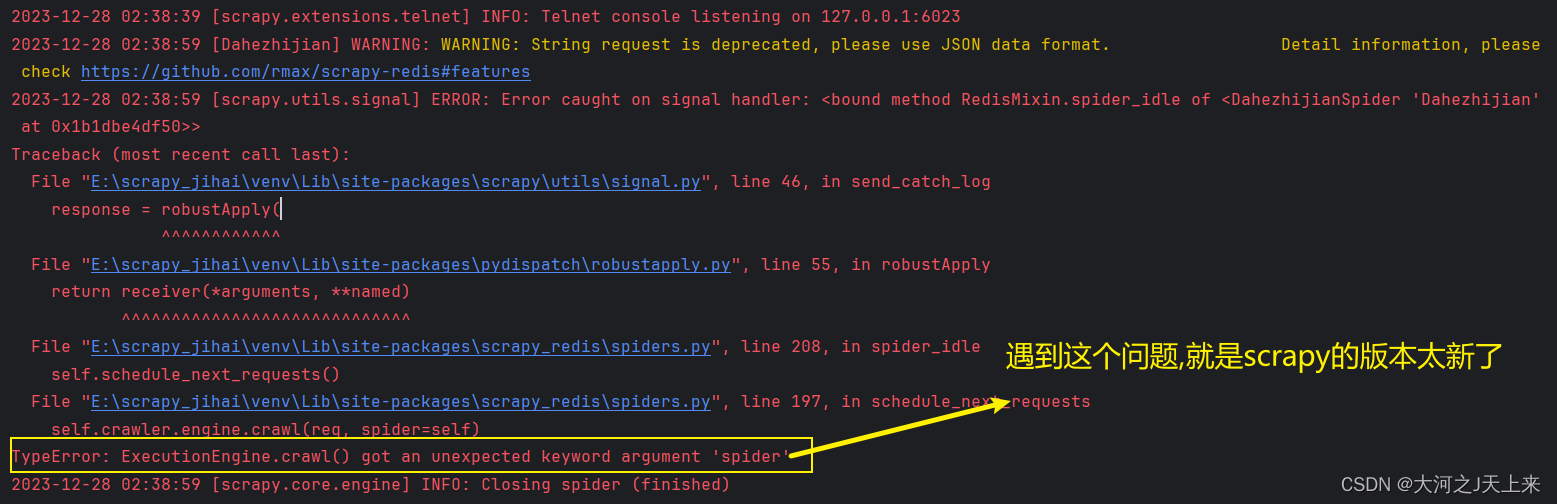
问题追溯:
1.查看版本:
我用的版本是:
也就是2023年12月28日的最新版~ 也会遇到这个问题!!!
2.追踪更新:
scrapy的最新版是2023.9.18 (真特么会挑日子! 918,我才看到! 以后我都不用这版本了...)

而scrapy_redis的最新版是:(2022年7月26日)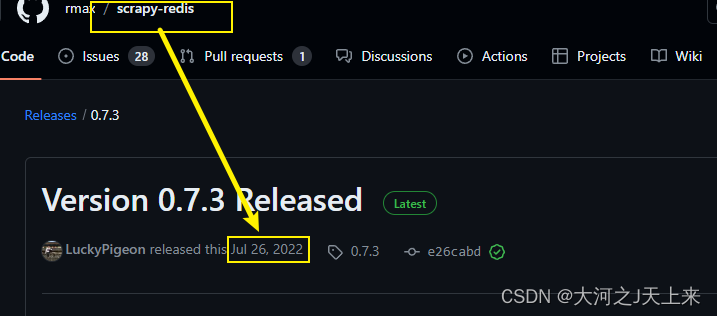
----相差了1年零2个月,我估计明年1到2月 redis要更新了的..
3.莫问别人,先管自己:
我帮大家测试过了,>=2.10.0现在都不兼容scrapy_redis;
直接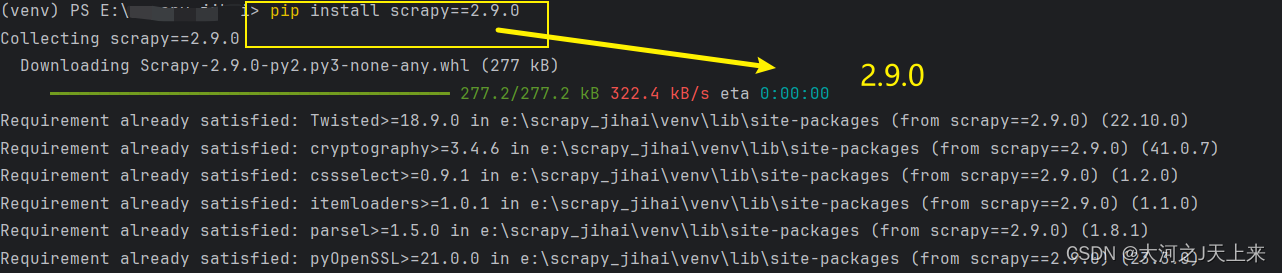
4.最终搭配:
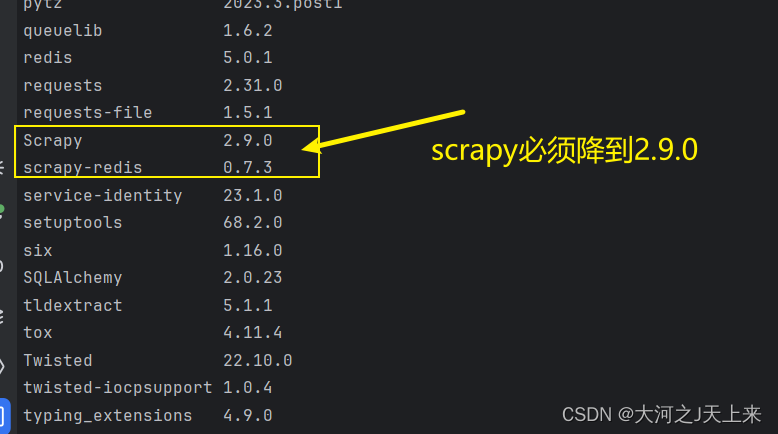
成功!!!

![[BUG] Hadoop-3.3.4集群yarn管理页面子队列不显示任务](https://img-blog.csdnimg.cn/img_convert/37336e757cd0f068ab4399b7ee2fb63b.png)