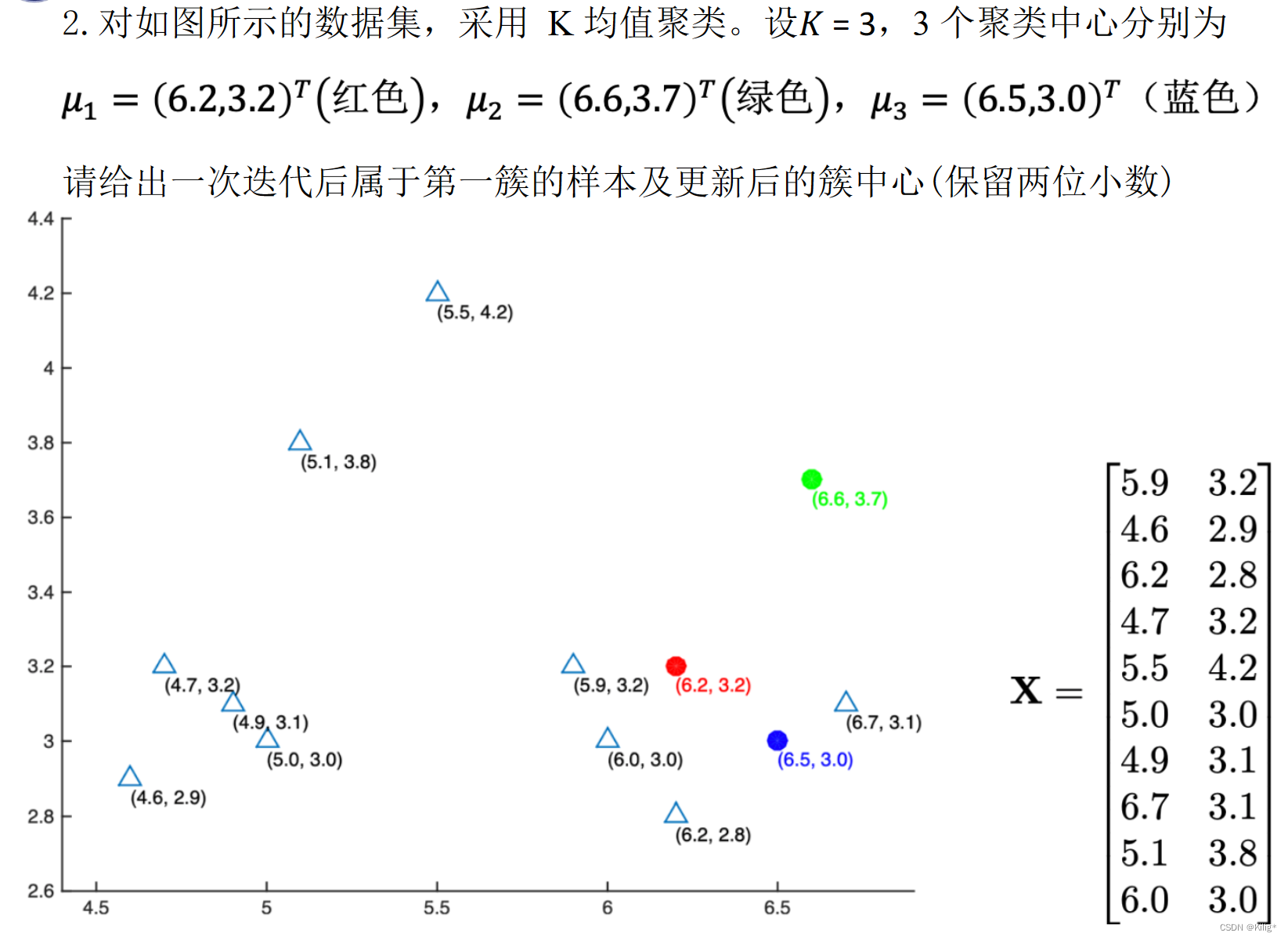
给定一个长度为 n n n的序列 A A A, A A A中的数各不相同。
对于 A A A 中的每一个数 A i A_i Ai,求: m i n 1 ≤ j < i ∣ A i − A j ∣ min_{1≤j<i}|A_i−A_j| min1≤j<i∣Ai−Aj∣,以及令上式取到最小值的 j j j(记为 P i P_i Pi)。若最小值点不唯一,则选择使 A j A_j Aj较小的那个。
输入格式
第一行输入整数 n n n,代表序列长度。
第二行输入 n n n个整数 A 1 … A n A_1…A_n A1…An,代表序列的具体数值,数值之间用空格隔开。
输出格式
输出共 n − 1 n−1 n−1 行,每行输出两个整数,数值之间用空格隔开。
分别表示当 i i i取 2 ∼ n 2\sim n 2∼n 时,对应的 m i n 1 ≤ j < i ∣ A i − A j ∣ min_{1≤j<i}|A_i−A_j| min1≤j<i∣Ai−Aj∣和 P i P_i Pi的值。
数据范围
n ≤ 1 0 5 n\le10^5 n≤105, ∣ A i ∣ ≤ 1 0 9 |A_i|≤10^9 ∣Ai∣≤109
输入样例
3
1 5 3
输出样例
4 1
2 1
算法思想一
根据题目描述,对于每个元素 A i A_i Ai,要找到其左边与它差值最小的元素 A j A_j Aj( 1 ≤ j < i 1\le j \lt i 1≤j<i),输出它们的差值的绝对值 ∣ A i − A j ∣ |A_i-A_j| ∣Ai−Aj∣,以及 j j j。
计算与 A i A_i Ai差值有两种情况:
- A i < A j A_i<A_j Ai<Aj,差值 v = A j − A i v = A_j-A_i v=Aj−Ai
- A i > A j A_i>A_j Ai>Aj,差值 v = A i − A j v = A_i-A_j v=Ai−Aj
也就是说,对于任意的 A i A_i Ai,如果能在 1 ∼ i 1\sim i 1∼i之间找到与 A i A_i Ai大小相邻的两个数 A l A_l Al和 A r A_r Ar,其中 A l A_l Al是小于 A i A_i Ai的最大值, A r A_r Ar是大于 A i A_i Ai的最小值,分别计算其与 A i A_i Ai的差值,取其中的较小者即可。
从给出的数据范围来看,
n
≤
1
0
5
n\le10^5
n≤105,对于每个元素必须在
O
(
l
o
g
n
)
O(logn)
O(logn)的时间复杂度内,查找到大小相邻的两个元素,而且根据题目中给出的限制,序列
A
A
A的数各不相同,可以用C++ 标准库的std::set 来实现。
std::set是 C++ 标准库中的一个容器,它按有序方式存储唯一元素的集合。std::set中的元素自动按照严格弱序(Strict Weak Ordering)排序,并且每个元素都是唯一的。这意味着std::set中的元素是按照特定顺序排列并且不会存在重复值。下面是一些std::set的特点和用途:
- 自动排序:
std::set内部使用红黑树(一种自平衡的二叉搜索树)实现,因此元素在容器中按照严格弱序排序。这使得元素能够以有序的方式存储,方便进行遍历和搜索操作。- 唯一性:
std::set中的元素是唯一的,相同的元素只会在容器中存在一个副本。这可以确保每个元素在集合中的唯一性。- 插入和查找效率高:由于
std::set内部使用红黑树实现,插入和查找元素的时间复杂度为 O ( l o g n ) O(log n) O(logn),其中 n n n 是容器中的元素数目。这使得std::set适合于需要高效地插入和查找元素的情况。std::set的大部分操作是与vector类似的,不过set不支持随机访问,必须要使用迭代器去访问;std::set插入元素的方法为insertstd::set查找元素的方法为find,返回一个迭代器set<类型>::iterator
- 若元素存在,返回的迭代器指向键值
- 若元素不存在,返回的迭代器指向
set.end()。
由于set是以有序方式存储唯一元素,那么可以遍历每个元素
A
i
A_i
Ai:
- 将
A
i
A_i
Ai插入到
set中 - 在
set中查找元素 A i A_i Ai,返回指向 A i A_i Ai的迭代器 - 通过迭代器可以找到与 A i A_i Ai大小相邻的两个元素,打擂台求最小值即可
时间复杂度
- 遍历每个元素 A i A_i Ai,时间复杂度为 O ( n ) O(n) O(n)
- 在
set中查找 A i A_i Ai,时间复杂度为 O ( l o g n ) O(logn) O(logn)
总的时间复杂度为 O ( n l o g n ) O(nlogn) O(nlogn)
代码实现
#include <iostream>
#include <set>
using namespace std;
const int INF = 0x3f3f3f3f;
typedef pair<int, int> PII;
int main()
{
int n, x;
cin >> n;
set<PII> st;
for(int i = 1; i <= n; i ++)
{
cin >> x;
PII a = {x, i};
st.insert(a);
if(i > 1) {
auto it = st.find(a); //find返回迭代器:set<pair<int, int>>::iterator
int k = INF, p;
if(++ it != st.end()) //通过迭代器找到下一个元素
k = (*it).first - x, p = (*it).second;
-- it; //将迭代器回到之前位置
if(it != st.begin() && x - (*--it).first <= k) //如果和前一个元素的差值不大于k
k = abs((*it).first - x), p = (*it).second;
cout << k << " " << p << endl;
}
}
}
算法思想二
除了使用 std::set实现,这里再介绍一个双链表的实现方法。
- 首先将序列 A A A排序,假设排序后为 A 3 A 4 . . . A n . . . A 2 A_3A_4...A_n...A_2 A3A4...An...A2
- 根据上述序列可以构造出一个双链表,如下图所示

有了双链表之后,如何求
A
i
A_i
Ai左边与它差值最小的元素呢?可以从后向前处理,也就是从
A
n
A_n
An开始,因为
A
n
A_n
An是原序列中最后一个元素,因此其它元素都在它左边。那么:
- 对于元素 A n A_n An来说,假设其在双链表的位置为 k k k,其左边的元素 L [ k ] L[k] L[k]就是小于 A n A_n An的最大值,其右边元素 R [ k ] R[k] R[k]就是大于 A n A_n An的最小值。
- 计算完相邻元素的差值之后,将 A n A_n An从双链表中删除,继续处理前一个元素。
重复这个过程,直到所有元素都处理完。
时间复杂度
- 排序的时间复杂度为 O ( n l o g n ) O(nlogn) O(nlogn)
- 排序后构建双链表的时间复杂度为 O ( n ) O(n) O(n)
- 查找计算相邻元素差值的时间复杂度为 O ( n ) O(n) O(n)
总的时间复杂度为 O ( n l o g n + n + n ) O(nlogn+n+n) O(nlogn+n+n)
代码实现
#include <iostream>
#include <algorithm>
using namespace std;
typedef long long LL;
const int N = 1e5 + 10;
typedef pair<LL, int> PII;
PII a[N], ans[N];
int p[N], L[N], R[N];
int main()
{
int n, x;
cin >> n;
for(int i = 1; i <= n; i ++)
{
cin >> x;
a[i] = {x, i};
}
sort(a + 1, a + n + 1);
//设置链表的首尾的值,避免其差值被选上
a[0].first = -1e10, a[n + 1].first = 1e10;
for(int i = 1; i <= n; i ++)
{
p[a[i].second] = i; //统计每个元素的新位置
L[i] = i - 1, R[i] = i + 1; //建立双链表
}
//从第n个元素开始处理
for(int i = n; i > 1; i --)
{
//第i个元素所在位置k
int k = p[i], left = L[k], right = R[k], v = a[k].first;
LL lv = v - a[left].first; //与左边对应元素的差值
LL rv = a[right].first - v; //与右边对应元素的差值
if(lv <= rv) ans[i] = {lv, a[left].second};
else ans[i] = {rv, a[right].second};
L[right] = left, R[left] = right; //删除k结点
}
//输出结果
for(int i = 2; i <= n; i ++)
cout << ans[i].first << " " << ans[i].second << endl;
}