前言
- 设计的模型叫EMU,通过统一的自回归方式(其预测的输出依赖于过去的输出)训练。
- 参数37B(370亿)。
- 指标在目前多项视觉(图像,视频)问答的SOTA
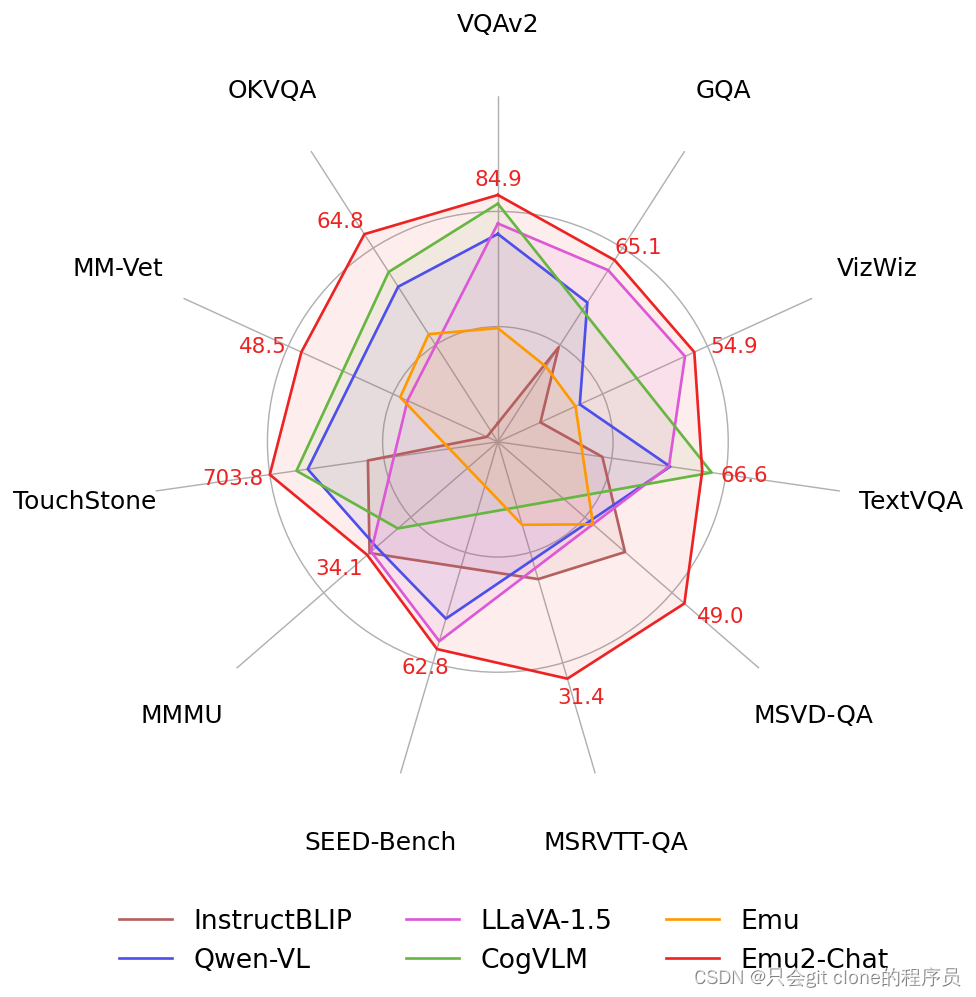
tips: 不过这里吐槽一点啊,我看了下几个数据集指标数据跟cogvlm其实拉的不是很大,然后cogvlm的参数只有17B,这篇论文的参数都38B了,这么看的话对比很不公平。
痛点
- 之前的多模态大模型训练主要依赖于结构化以及大量高质量的监督训练数据,这两者都很难进行规模化。(因此,本文用统一的自回归方式训练多模态大模型,统一这个词很关键,不仅仅是像chatgpt一样只有文本->文本,而是文本对、图像-文本对以及图像-文本-视频对)
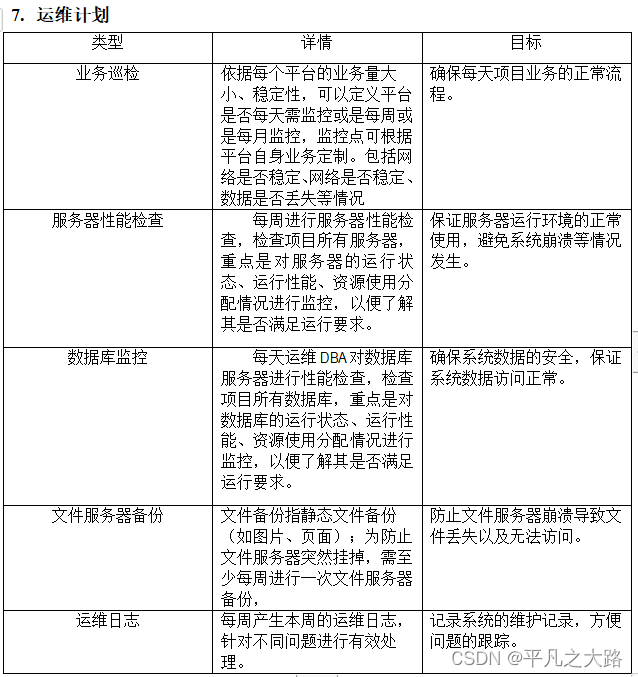
模型结构
| 模型 | |
|---|---|
| Vision | EVA-02-CLIP-E-plus |
| project layer | linear |
| LLM | LLaMA-33B |
| Visual Decoder | SDXL |
模型结构这块真的狠,语言模型直接上了33B的llama,这一下子就可以劝退了99%的用户了。视觉部分也狠,clip-E差不多有5B的参数,快赶上经典的7B的语言模型了。Visual Decoder这个之前没怎么接触过图像生成,不太了解这个模型,不过这个decode的参数倒是不大。
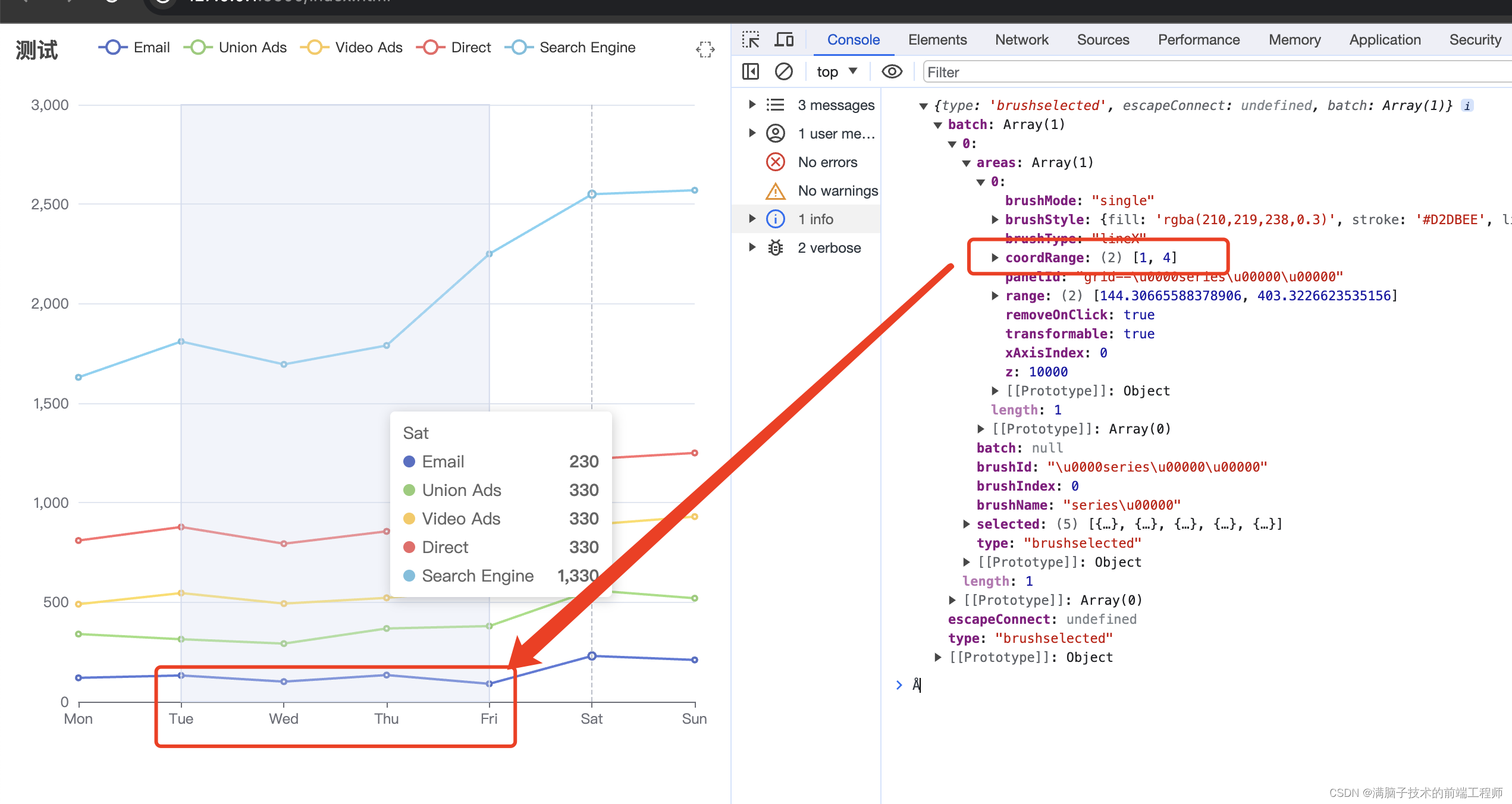
流程这里论文写的不是很清楚,不过看着大概意思就是,输入一个图像,先用Vision抽图像的patch,然后作者说

看着是就做了个简单的mean pooling,每个图只用了8*8个patch,我理解应该是视觉模型EVA-02-CLIP-E-plus输出的tensor应该是一个(b, n, d)的形状,然后通过mean pooling后得到一个(b, 64, d)的tensor给到语言模型,就是一张图变成了64个token(这块有比较多的操作,像minigpt4用了个qformer,minigpt4-v2把qformer砍了,直接用linear层映射到文本需要的维度,llava也是直接用linear层,论文说的emu-v1这里用的c-former)。
整个模型结构就介绍了这么多,可以看到,现在的大模型结构创新显得没有那么必要了,反倒是你的训练策略,训练数据的数量和质量,模型的大小才是重中之重。可以说这篇论文的三个核心的模型结构LLM,Vision,Vision decode都是别人的,自己的结构就是加了个linear层把输出能串起来。hhhhh
下面看看原图吧,画的都很简单。

训练
训练数据

训练数据真狠啊,几个超大型的数据集都被用上了,看作者后面写的预训练视频一共用了700万,图片一共用了1.62 亿。
训练方式
Step 1
一些设置:
- 损失函数只用了文本生成的loss
- 图片大小224 * 224
- 优化器adam
- project layer层的学习率:1×10−4
- LLM的学习率:3×10−5
- vision的学习率: 5×10−5
每个batch的图文对6144个,视频文本对768个,一共训了35200个iter,就是243302400条样本(有卡有钱就是任性)。
Step 2
- 图像尺度扩展到448 * 448。(有钱啊)
- 在step1的基础上接着训了4000个iters。
Step3
- 冻结vision部分,仅训练project layer以及LLM。
- 损失用了文本分类的loss,图片生成的loss。(这里不太理解为啥事文本分类的loss???)
- 然后又补了点数据,看下图吧。
 - 图片训练尺度还是保持448 * 448,学习率变成了1 × 10−5(准备微调了,降了学习率)
- 图片训练尺度还是保持448 * 448,学习率变成了1 × 10−5(准备微调了,降了学习率) - 每个batch的图文对12800个,视频文本对6400个, 3,200个image-text and video-text interleaved data(这个interleaved实在不理解是啥东西),800个文本对数据。训了20,350个iters。
Step4
最后单独训了下vision decode,这块没咋做过图像生成先略了看不太懂。原文贴一下吧:

Step5
最后就是指令微调了,没写啥内容就是用了这些指令微调的数据

一些设置:
- batchsize是768,训了8000个step
- 上下文的最大长度限制到2048
- 图像的尺寸还是448 * 448
- 视频帧随机用了8,12,16帧。
- 图像的token从原来的8 * 8(64个token)变成了16 * 16(256个token)。主打就是能大就大啊
效果
其他乱七八糟的就不写了,效果就是六边形战士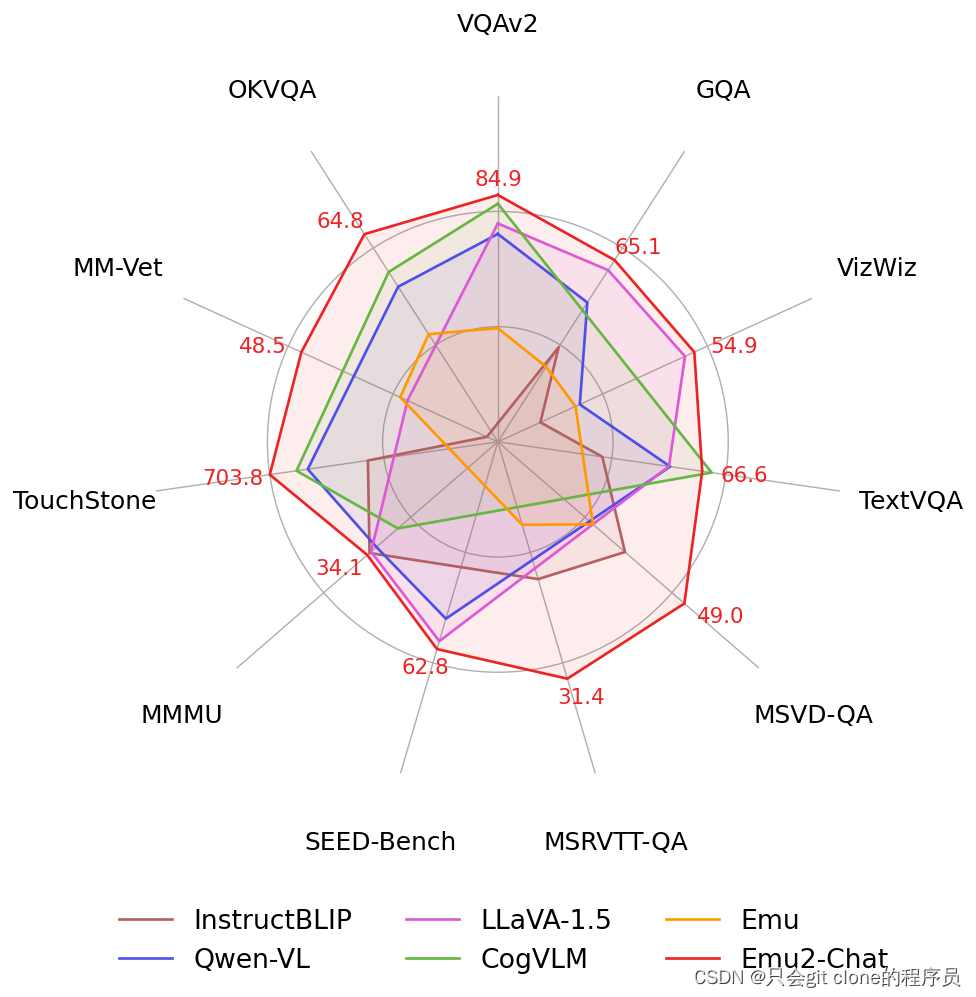
总结
整体论文感觉有些地方写的不是很清楚啊,所以只了解了个大概,总体看就是能大就大…真是有钱经得起折腾。哎,想想也很可悲,上班了之后要担心收益,好多事情都不敢放开手脚做,就这论文的工作,给了我流程和数据说实话也不是很敢搞,训练周期长,训练收益不可预期,短平快的节奏真没法搞。
补一句,测了一些case这个模型效果真的可以。不错的工作。