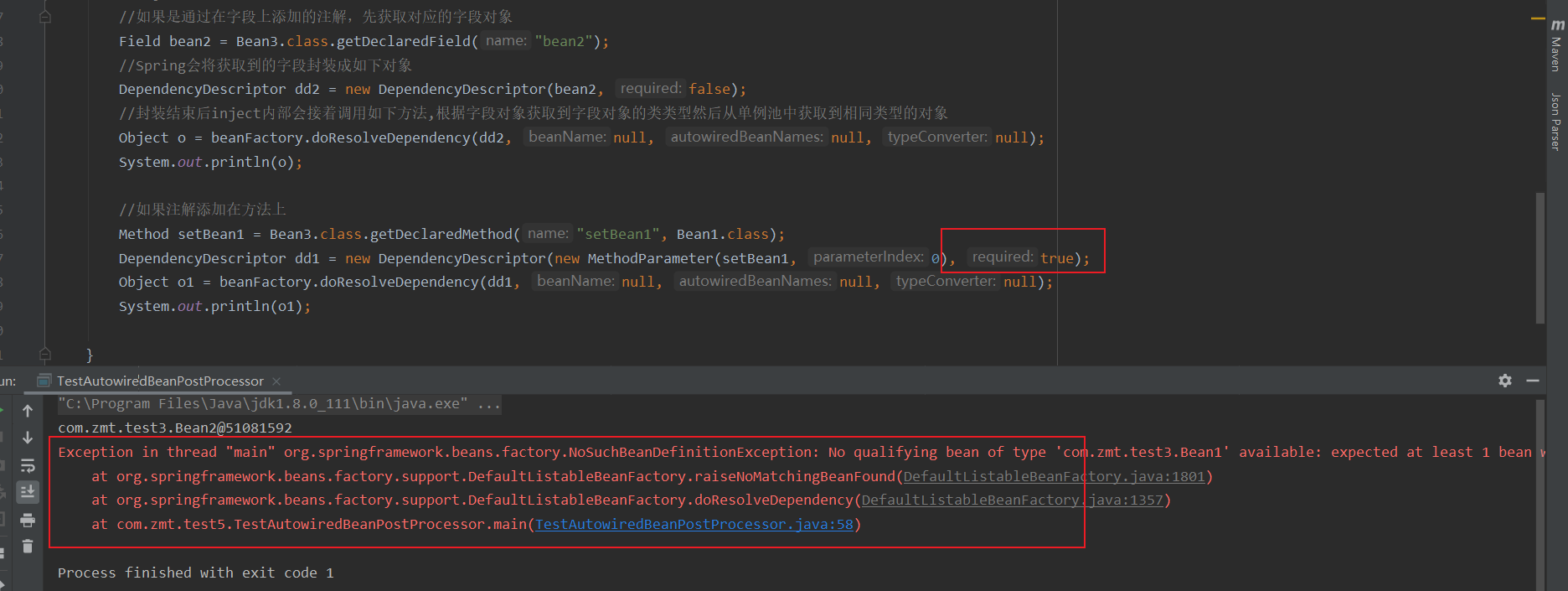
Linux管道是Linux命令行界面中一种强大的工具,它允许用户将多个命令链接起来,使得一个命令的输出可以作为另一个命令的输入。这种机制使得我们可以创建复杂的命令链,并在处理数据时提供了极大的灵活性。在本文中,我们将详细介绍Linux管道的使用方法和实际应用。
管道的基本概念
管道(pipe)是一种特殊的文件类型,它在内存中创建一个缓冲区,用于存储一种命令的输出和另一种命令的输入。
管道的创建和使用非常简单,只需要使用|符号即可。
例如,我们可以使用ll命令列出当前目录中的所有文件,然后通过管道将这些文件的列表传递给grep命令,以搜索某个特定的文件:
$ ll | grep ooxx
-rw-rw-r-- 1 vagrant vagrant 7 Dec 21 06:07 ooxx.txt
在这个例子中,ls命令的输出成为了grep命令的输入,这就是管道的基本用法。
管道的工作原理
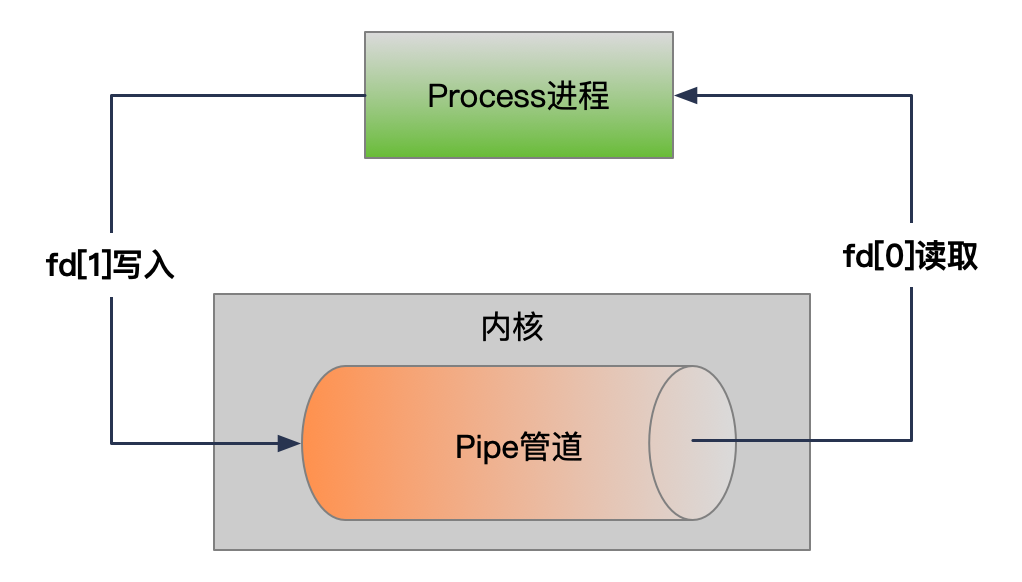
管道背后的主要思想是“生产者-消费者”模型,其中一个进程产生数据,而另一个进程消费这些数据。
创建管道的系统调用是pipe(),它创建了一对文件描述符:一个用于读,一个用于写。当在shell中使用管道时,shell会自动调用pipe()以及其他一些系统调用来设置进程间的数据流。
以下是管道创建和数据流动的基本步骤:
-
创建管道:当用户在shell中输入一个包含管道的命令(如
cmd1 | cmd2)时,shell会使用pipe()系统调用创建一个管道。pipe()系统调用返回两个文件描述符:一个用于管道的读端,一个用于管道的写端。 -
创建进程:接下来,shell使用
fork()系统调用创建两个子进程。每个子进程将执行命令链中的一个命令(cmd1和cmd2)。 -
设置文件描述符:在执行命令之前,shell会对子进程的文件描述符进行操作,确保cmd1的标准输出(stdout)连接到管道的写端,而cmd2的标准输入(stdin)连接到管道的读端。这通常通过 dup2() 或 close() 系统调用来完成。
-
执行命令:然后,shell使用
exec()系统调用来替换子进程的内存空间,运行相应的命令。cmd1 进程写入数据到管道的写端,而 cmd2 进程从管道的读端读取数据。 -
数据流动:当 cmd1 进程向管道写入数据时,这些数据被缓存在内核中,直到 cmd2 进程从管道读取它们。
如果管道的写端没有数据可写,cmd2 进程在尝试读取时会阻塞(等待),直到有数据可读。
如果管道的读端没有进程读取数据,cmd1 进程在写入时会收到一个 SIGPIPE 信号,通常会导致写入进程终止。 -
清理:当两个命令都执行完毕后,shell会关闭所有打开的文件描述符,并回收子进程的资源。
通过这种方式,管道能够将不同命令的输出和输入无缝连接起来,创建一个数据处理的流水线,极大地增强了shell脚本和命令行的功能性和灵活性。
管道产生进程的演示
查看当前bash的PID:
$ echo $$
2514
使用管道连接下面的两个命令:
$ { echo $BASHPID; read a; } | { cat; read b; }
5610
我们发现5610的进程阻塞住了,在等待输入。
查看父进程生成的两个子进程的PID:
$ ps -ef|grep 2514
vagrant 5610 2514 0 08:07 pts/0 00:00:00 -bash
vagrant 5611 2514 0 08:07 pts/0 00:00:00 -bash
两个子进场的PID分别为5610(第一个命令)和5611(第二个命令)。
再来看看管道是怎么将两个进程的输入和输出连接在一起的:
5610(第一个命令)的文件描述符目录如下:
$ ll /proc/5610/fd
lrwx------ 1 vagrant vagrant 64 Dec 26 08:08 0 -> /dev/pts/0
l-wx------ 1 vagrant vagrant 64 Dec 26 08:08 1 -> 'pipe:[103565]'
lrwx------ 1 vagrant vagrant 64 Dec 26 08:08 2 -> /dev/pts/0
5610(第一个命令)的输出流连接到管道pipe:[103565]上。
5611(第二个命令)的文件描述符目录如下:
$ ll /proc/5611/fd
lr-x------ 1 vagrant vagrant 64 Dec 26 08:08 0 -> 'pipe:[103565]'
lrwx------ 1 vagrant vagrant 64 Dec 26 08:08 1 -> /dev/pts/0
lrwx------ 1 vagrant vagrant 64 Dec 26 08:08 2 -> /dev/pts/0
5611(第二个命令)的输入流连接到管道pipe:[103565]上,这样就将两个进程的输入和输出连接在一起了。
$ 和 和 和BASHPID的区别
在上面的例子中,我们演示了$$和$BASHPID这两个变量都能获取当前进程的ID(PID),那么他们直接有什么区别呢?
先将上面管道的的例子中的$BASHPID替换为$$执行:
$ { echo $$; read a; } | { cat; read b; }
2514
发现打印的是父进程的PID(2514),而不是子进程的PID,这是为什么呢?
$ 和 和 和BASHPID的区别:
-
$$:$$的优先级高于子shell(在脚本中通过括号创建的子shell(command)或者在管道中
|),在执行命令的时候会先将$$替换为父进程的PID(2514),再创建子进程执行shell。 -
** B A S H P I D ∗ ∗ : BASHPID**: BASHPID∗∗:BASHPID的优先级低于子shell,所以在执行命令的时候会先创建子进程,然后在执行命令,这样打印的就是子进程的PID。
下面是一个例子来展示它们之间的区别
下面的例子也是同样的道理:
$ echo "PID of the current shell: $$"
PID of the current shell: 2514
$ echo "BASHPID of the current shell: $BASHPID"
BASHPID of the current shell: 2514
$ ( echo "PID of the subshell: $$"; echo "BASHPID of the subshell: $BASHPID" )
PID of the subshell: 2514
BASHPID of the subshell: 6050
在不涉及子shell的情况下,$ 和 和 和BASHPID通常会返回相同的值,因为当前Bash实例就是当前shell。但是在涉及子shell的复杂脚本中,理解这两个变量之间的区别非常重要,以便正确地获取所需的PID。
管道的效率与限制
以下是管道的效率特点:
-
内核级操作:管道的数据传输是在内核空间进行的,没有涉及用户空间和内核空间之间的数据拷贝,这使得管道非常高效。
-
无需临时文件:管道允许直接在进程间传递数据,不需要写入到临时文件中再读取,减少了磁盘I/O操作,提高了数据处理速度。
-
并发执行:管道连接的命令可以同时执行,不需要等待前一个命令完成后才开始下一个命令,这样可以更充分地利用CPU资源。
-
缓冲机制:管道本身具有一定的缓冲区,这可以减少读写操作的次数,提高效率。
以下是管道的限制:
-
单向数据流:管道是单向的,数据只能从管道的一端流向另一端。如果需要双向通信,则需要使用两个管道或其他通信机制,如套接字。
-
固定大小的缓冲区:管道的缓冲区大小是固定的,通常取决于系统内核。一旦缓冲区满了,写操作就会阻塞,直到有进程读取数据为止。同样,如果缓冲区为空,读操作也会阻塞。
-
数据完整性:管道不保证消息边界,如果需要传递结构化的数据,发送和接收进程需要约定数据格式或使用特定的协议来确保数据的完整性。
-
阻塞问题:如果管道的读端没有进程读取数据,写端的进程在写入数据时将会收到 SIGPIPE 信号。如果管道的写端没有进程写入数据,读端的进程会读取到文件结束符(EOF),这可能导致进程阻塞或终止。
-
资源限制:每个用户和系统都有打开文件描述符的数量限制,大量使用管道可能会耗尽可用的文件描述符。
-
错误处理:管道中的错误可能不会直接传递给前一个命令。例如,如果 cmd1 | cmd2 中的 cmd2 失败了,cmd1 可能仍然在不知情的情况下继续运行,除非它试图写入更多数据到已经因为 cmd2 的终止而关闭的管道。
管道的实际应用
Linux管道在实际应用中非常广泛,可以用于各种数据处理和工作流程的构建。以下是一些常见的应用场景和例子:
-
文本处理和过滤器:管道非常适合处理文本数据。可以使用各种文本过滤器(如grep、sed、awk等)组合起来进行文本搜索、替换、提取等操作。例如,可以通过将ls命令的输出传递给grep来搜索特定的文件:
ls | grep .txt。 -
数据转换和格式化:可以使用管道将一个命令的输出传递给另一个命令进行数据转换和格式化。例如,可以使用cat命令将一个文件的内容输出到管道,然后使用tr命令将其中的大写字母转换为小写字母:
cat file.txt | tr 'A-Z' 'a-z'。 -
进程监控和管理:可以使用管道来监控和管理系统中的进程。例如,可以使用ps命令获取进程列表,并将其传递给grep命令来筛选特定的进程:
ps aux | grep nginx。 -
多命令串联:可以使用管道将多个命令串联在一起,形成更复杂的工作流程。例如,可以使用find命令查找特定类型的文件,并将结果传递给xargs命令来执行后续的操作:
find . -name "*.txt" | xargs rm。 -
日志分析和处理:管道可以用于实时分析和处理日志数据。例如,可以使用tail命令实时监视日志文件,并将其输出传递给grep命令来筛选感兴趣的日志条目:tail -f logfile.txt | grep “error”。
-
数据流分析和统计:可以使用管道将数据流传递给统计命令进行数据分析和统计。例如,可以使用cat命令将一个文件的内容输出到管道,然后使用wc命令统计行数、单词数和字符数:
cat file.txt | wc。
这只是一小部分管道的应用场景和例子,实际上,几乎任何需要将多个命令或工具组合起来进行数据处理和操作的情况下,都可以考虑使用管道。通过灵活地组合各种命令和工具,可以构建出强大而高效的数据处理流程。
结语
总的来说,Linux管道是一个非常强大的工具,它可以帮助我们在处理数据时提供极大的灵活性。通过学习和掌握管道的使用,我们可以更有效地使用Linux命令行,更好地完成各种复杂的数据处理任务。