
要点一:培养跨学科思维
在分析时,需要采用多学科的思维方式 结果不重要,重要的是如何提炼现象、分析问题和得出结论的过程。
1. 介绍了锤子精神和多学科思维方式的重要性。指出了只从自身学科出发解决问题的局限性。
2. 提倡跨学科思维方式,将不同学科的理论和思想融入到分析模型中。强调了规避自身学科局限性和构建多学科思维框架的重要性。建议通过多学科思维模型来解决现实问题,培养独特的思考视角。
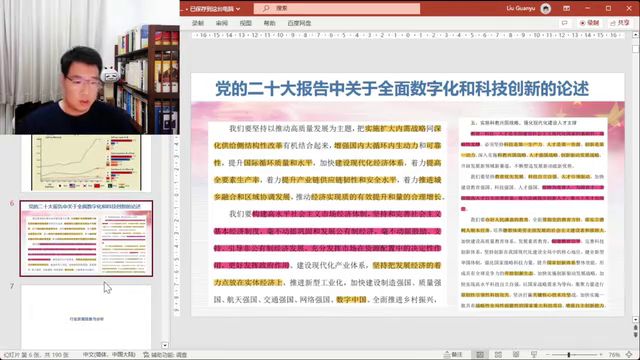
要点二: 同期创业的企业市值差异巨大,阿里和腾讯的市值相差数十亿(why)?
1.信息技术的进步推动商业模式的进步,推动广义数据量的进步,信息技术每一代的进步都没有跟上商业模式的发展。(像创投、风投就是商业模式超前来拉动信息技术和广义数据量超前。)——这个行业的主要问题就是技术端没有办法进行技术突破,需求端没有需求,
2.当前互联网行业的企业走出了统一的趋势,但原因不是国家支持或经济环境,而是信息技术和商业模式的推动力不足。 ——技术端无法进行技术突破,需求端缺乏需求,是当前互联网行业的主要问题。
3.历史周期是无法避免的,但头部企业在行业复苏时可以占据更多市场份额。 未来信息技术行业的发展方向是头部企业依然很好,但中下游企业可能无法享受过去的高薪和福利。
要点三:web1.0-3.0分析
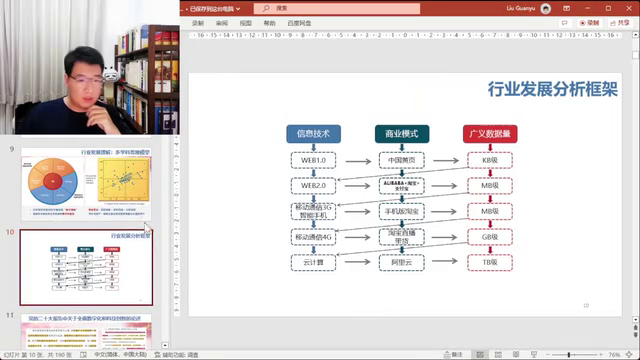
1.网页1.0。就是没办法交互,没办法交互,没办法看视频,没有办法interaction,这就是1.0。
阿里在1.0的时候,推出了一个商业模式的中国黄页,就是把他能联系到的各个企业,一个企业给一张网页,就做出一个网页出来。
2.信息技术发展的2.0阶段可以interaction了。就是说你可以交互了,你输入我给你输出,大家很快就能想到说,中国黄页变成了中国供应商网络,所以就有了阿里巴巴。对个人端可以在网上买东西了。
3.GB级的数据出现了之后,云计算做存储,云计算做计算,5G做处理,这都是顺其自然产生的信息技术进步。阿里云广义的数据量上到了TB级以上。——存储、处理、传输这三条线够现有使用了。

要点四:企业数字化转型的核心
1. 企业和组织进行数字化和数字化转型的核心是使用前沿信息技术完成业务流程和组织架构的转型。
2. 数字化转型的结果是重要的组织间关系的数字化,数字化网络来完成核心业务流程。
核心关系网络的数字化以及组织资产的数字化管理。
3. 前沿信息技术是完成数字化转型的关键,包括人工智能、区块链、云计算和大数据等。
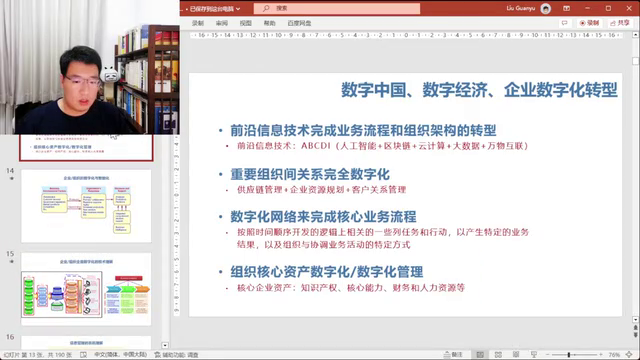
要点四:组织决策为什么使用集成式计算机辅助系统(BI)—商务智能?
1.这段对话讨论了组织和企业环境变化的影响以及如何做出决策。组织环境会产生压力和机遇,对于任何一个组织来说,它都需要响应这种环境变化。制度理论提出了一个观点,认为组织需要适应环境,并达成一个合理化的状态。在决策方面,人的成本高、效率有限,而机器和人的结合可能是一个更好的选择。然而,单独依靠人或机器都有各自的问题。人的决策反应慢、空间和时间有限,而机器的决策可能不够理性。
2.博弈论则提供了解决动态博弈和信息不对称问题的方法。最后,虽然机器可以提供快速自动化决策,但单独使用机器可能不是最好的选择。
囚徒困境这类问题——直接拉矩阵
海盗分赃(1、2、3、4、5)——倒着想
表白的事情——数学期望
3. 人和机器应互补,以AI和数据分析为基础,人自身来定决策。量化投资只能放大波动,不能决定基本面因素,单靠机器做决策不可行。(美股的闪电崩盘)

要点五:企业数据分析全流程介绍?
1. 讲解了数据仓库的架构和组成部分,包括数据来源和ETL process(这个E叫做instruct,t是transform,L是load,叫做提取转换和加载。功能:不同数据来源的数据来了之后,我们在用之前首先要处理一下。)
解释了数据格式不一致的问题,以及如何处理和存储不同数据来源的数据。
2. 提到了数据仓库的索引和备份的重要性,以及如何通过API与前端应用进行数据交互。 处理清洗完之后,我们把它存到uncross data warehouse,叫做企业级的数据仓库。
介绍了数据仓库的作用和用途,可以将历史性的大规模数据存放在其中。(数据仓库存放的是这种历史性的,不经常使用的规模比较大的数据。)你可以把它理解成为图书馆,然后把数据扔到图书馆之后,上面建立一个索引。所以这个索引就是meta data,建立完索引之后,整个复制一下,以后数据万一出问题,我得有备份replication,
3.然后才是数据库。这个东西就是说财务处说跟我相关的数据,给我映射一部分出来。财务处的数据库、教务处的数据库、学生处的数据库。那么数据库到这一步为止就把所有的数据存放好了,然后通过API。Application interface, 就是用通用数据接口,就是前端有需要调用数据的时候,我得透过它去找明白了,有API了之后,我就可以有前端的应用了。
4. 总结了前端应用的用法,包括数据可视化、报表、仪表盘、文本挖掘、网页分析等。
做数据分析determining文本分析test mining网页分析one money等等我做一些在线的实时分析,online analysis process oil AP我也可以直接给一些APP做数据支持,这就是我们中最终在前端用的。

备注:左边是任何一个企业都能够用的数字化的一个通用架构,右边是我们为什么要搞这个数据分析。
要点六:描述、预测与优化?
1.数据可视化是解决过去和现在发生了什么的问题的工具。数据可视化不能预测未来。
第一条主线叫做descriptive,叫做描述。什么叫描述呢?它解决的问题就是对一个企业来讲,对一个个人来讲,what happened? What is happy? 过去和现在发生了什么?
数据可视化,做数据分析的第一个任务是回答过去和现在发生了什么。这个任务怎么处理呢?用到的工具就是数据可视化,就是大家之前学到的怎么用PYTHON作图,怎么用各种各样的网页作图。数据可视化能不能预测?不能。
(有人想说股票K线是不是数据可视化?所有人都学了一本教材,都看到了同样的线,于是所有人都趋同性的交易,这就叫做预言的自我实现。)
2.预测是解决未来会发生什么的问题,可以使用数据分析、文本分析和网页分析等技术。 数据挖掘是实现预测的方法之一。
第二个阶段的任务叫做predict预测。解决的问题是站在过去和现在这个时间节点上往后看what will happen。What will happen就是未来会发生什么,以及为什么它会发生这个事儿。咋回答呢?那就涉及到大家前四天学到的另外一些技能了。数据分析、文本分析、网页分析。他能够用一些算法,比如说分类、聚类、关联里面代表性的机器学习各种算法。
做预测用到的是数据挖掘。
3.优化模拟和专家系统等方法可以用于解决最优的问题。
然后第三项proscriptive规范,这个就是说我要解决的问题是过去、现在和将来。我分别通过,数据可视化和数据分析已经清楚了,我怎么办是最优的?你预测的事情一旦真的发生,我怎么办是最优的那好,
我就需要用到的办法叫做optimization simulation,然后decision modeling,expert system等等,就是所谓的专家系统,计算机仿真,模拟等等。

根根据C端的或者B端的各种分析数据,也可以做预测,用分类、聚类、关联,什么人工神经网络、知识向量机、遗传算法等等做预测。
要点七:信息系统与企业或组织的管理价值链
大家讨论了信息系统的不同形式,包括手机端小程序、APP、网页端应用和客户端应用。它们本质上都是信息系统,通过整合表达形式来处理数据并产生输出。讨论结束后,对话中的人们认为已经清楚了信息系统的基本概念。

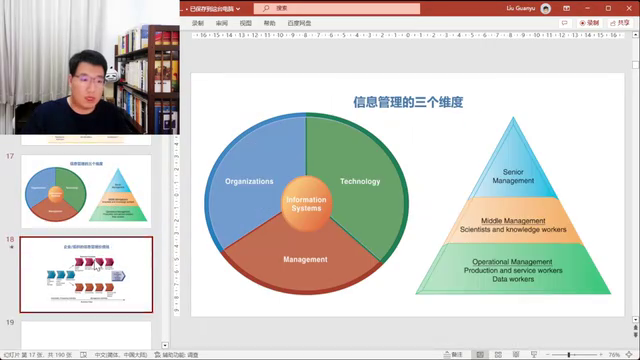
1.讲述了关于大数据和人工智能的主题,但知识内容不仅仅涉及技术,还包括组织和管理问题。给出了一张饼图,命名为“组织、管理和技术MOT management organize和technology”。表明在分析企业技术相关问题时,需要使用思维框架从三个维度,即组织管理和技术三个维度去看待。探讨了这三个维度如何在正常企业中整体性地影响。
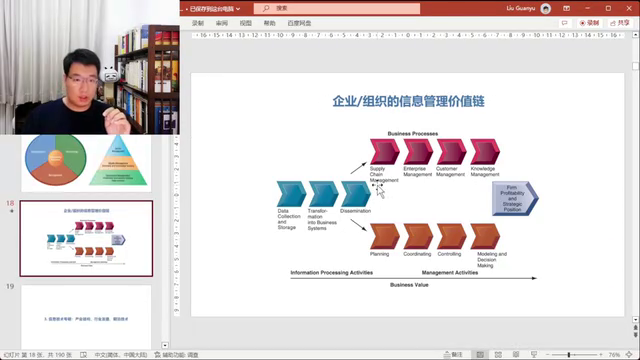
2.这张图叫做企业和组织的信息管理价值链,它包括技术维度和数据处理过程。技术维度包括数据收集、存储和转化,以及数据分发(Data collection、storage, 数据的存储和数据的收集,数据转化,然后determination数据的分发,所以这个是技术维度)。数据处理过程包括数据的整理、分析和应用。
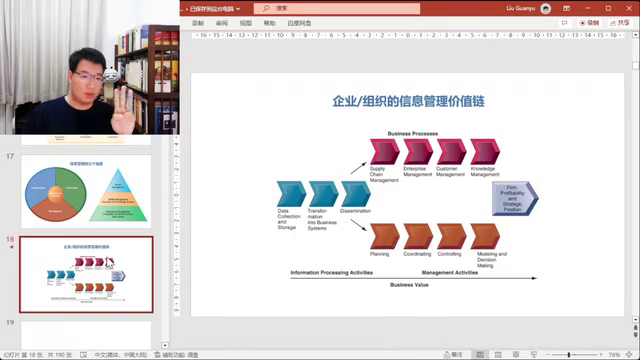
讨论了企业内部信息系统的分布和管理职能的分配。其中,一部分信息发送给管理部门(计划、协调),一部分发送给组织部门,包括供应链管理系统和客户关系管理系统等。同时,提到了管理组织和技术这两个维度,以及大数据和人工智能如何通过技术手段解决问题。
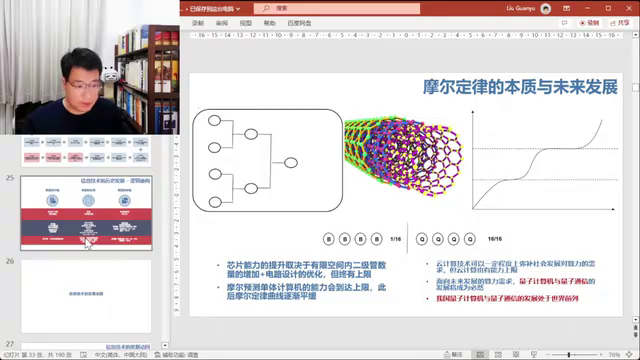
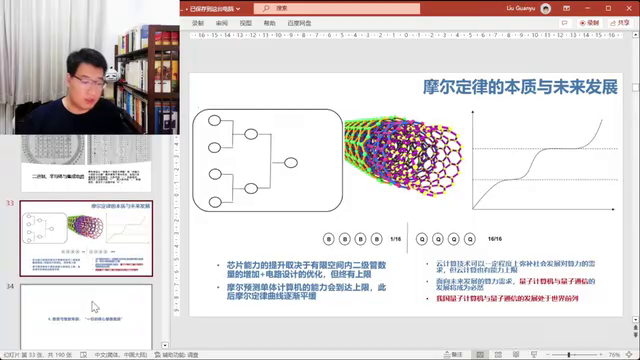
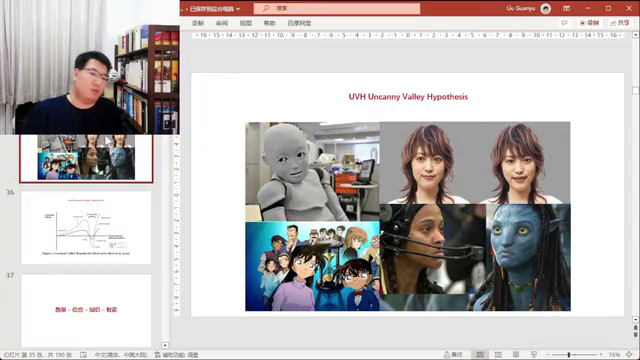
信息技术专题:量子计算机与芯片发展







1. 京东的物流体系为什么能够这么高效? 2. 京东的物流体系不仅仅是技术的问题。 3. 提出问题的同时,要思考问题的本质和背景。 4. 简答题需要用一页纸解释。

1. 京东的物流体系高效,能够在双十一限时内送达。 2. 京东自营,物流快速,适用于今天的场景。 3. 京东能够做到双十一限时送达的原因是组织管理和技术的优势。 4. 淘宝的菜鸟物流没有做出限制,无法实现类似的高效送达。 5. 建议从组织管理和技术的角度进行研究,了解京东是如何做到高效送达的。
金明老师最后一节课讲述比特币趋势与个人发展 1. 建议学生提交笔记和简答题的文档,可以分开提交PDF和Word文件。 2. 老师每天坚持看书1小时,建议学生多看书,可以提升大脑和身体。 3. 老师每天坚持健身1小时,建议学生也坚持锻炼身体。 4. 老师在英国曼彻斯特大学读博士,课程内容对学生有启发作用。 5. 欢迎学生参加暑期课程,有问题可以在群里提问,老师会回复。