DeepLearning-Interview-Awesome-2024
本项目涵盖了大模型(LLMs)专题、计算机视觉与感知算法专题、深度学习基础与框架专题、自动驾驶、智慧医疗等行业垂域专题、手撕项目代码专题、优异开源资源推荐专题共计6大专题模块。我们将持续整理汇总最新的面试题并详细解析这些题目,希望能成为大家斩获offer路上一份有效的辅助资料。

2024算法面试题目持续更新,具体请 follow 2024年深度学习算法与大模型面试指南,喜欢本项目的请右上角点个star,同时欢迎大家一起共创该项目。部分题目对应的更深度的解析可至博客查阅
🏆大模型(LLMs)专题
| 01. 大模型常用微调方法LORA和Ptuning的原理 |
|---|
| 02. 介绍一下stable diffusion的原理 |
| 03. 为何现在的大模型大部分是Decoder only结构 |
| 04. 如何缓解 LLMs 复读机问题 |
| 05. 为什么transformer中使用LayerNorm而不是BatchNorm |
| 06. Transformer为何使用多头注意力机制 |
| 07. 监督微调SFT后LLM表现下降的原因 |
| 08. 微调阶段样本量规模增大导致的OOM错误 |
🍳计算机视觉与感知算法专题
| 01. 人脸识别任务中,ArcFace为什么比CosFace效果好 |
|---|
| 02. FCOS如何解决重叠样本,以及centerness的作用 |
| 03. Centernet为什么可以去除NMS,以及正负样本的定义 |
| 04. 介绍CBAM注意力 |
| 05. 介绍mixup及其变体 |
| 06. Yolov5的正负样本定义 |
| 07. Yolov5的一些相关细节 |
| 07. Yolov5与Yolov4相比neck部分有什么不同 |
| 08. Yolov7的正负样本定义 |
| 09. Yolov8的正负样本定义 |
| 10. Yolov5的Foucs层和Passthrough层有什么区别 |
| 11. DETR的检测算法的创新点 |
| 12. CLIP的核心创新点 |
| 13. 目标检测中旋转框IOU的计算方式 |
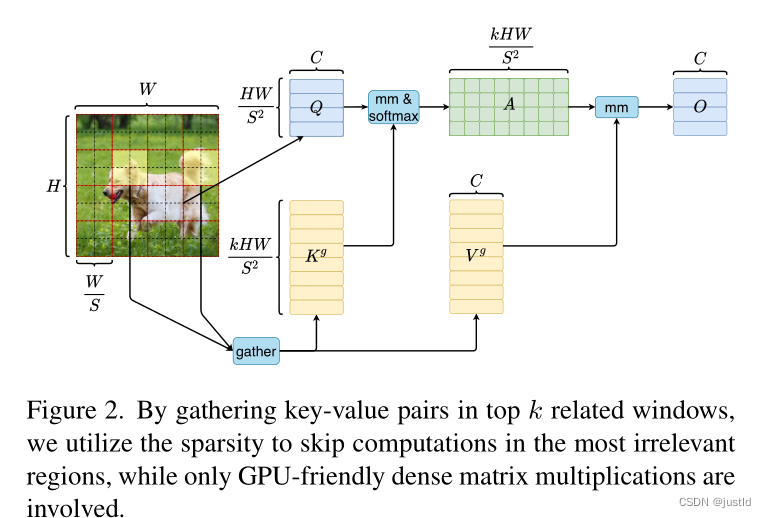
| 14. 局部注意力如何实现 |
| 15. 视觉任务中的长尾问题的常见解决方案 |
| 16. Yolov5中的objectness的作用 |
⏰深度学习基础与框架专题
| 01. 卷积和BN如何融合提升推理速度 |
|---|
| 02. 多卡BN如何处理 |
| 03. TensorRT为什么能让模型跑更快 |
| 04. 损失函数的应用-合页损失 |
| 05. Pytorch DataLoader的主要参数有哪些 |
| 06. 神经网络引入注意力机制后效果降低的原因 |
| 07. 为什么交叉熵可以作为损失函数 |
| 08. 优化算法之异同 SGD/AdaGrad/Adam |
| 09. 有哪些权重初始化的方法 |
| 10. MMengine的一些特性 |
| 11. Modules的一些属性问题 |
| 12. 激活函数的对比与优缺点 |
| 13. Transformer/CNN/RNN的时间复杂度对比 |
| 14. 深度可分离卷积 |
| 15. CNN和MLP的区别 |
| 16. MMCV中Hook机制简介及创建一个新的Hook |
| 17. 深度学习训练中如何区分错误样本和难例样本 |
| 18. PyTorch 节省显存的常用策略 |
| 19. 深度学习模型训练时的Warmup预热学习率作用 |
🛺自动驾驶、智慧医疗等行业垂域专题
| 01. 相机内外参数 |
|---|
| 02. 坐标系的变换 |
| 03. 放射变换与逆投影变换分别是什么 |
| 04. 卡尔曼滤波Q和R怎么调 |
| 05. 如何理解BEV空间及生成BEV特征 |
🏳🌈手撕项目代码专题
| 01. Pytorch实现注意力机制、多头注意力 |
|---|
| 02. Numpy广播机制实现矩阵间L2距离的计算 |
| 03. Conv2D卷积的Python和C++实现 |
| 04. Numpy实现bbox_iou的计算 |
| 05. Numpy实现Focalloss |
| 06. Python实现非极大值抑制nms、softnms |
| 07. Python实现BN批量归一化 |
🚩优异开源资源推荐专题
| 01. 多个优异的数据结构与算法项目推荐 |
|---|
| 02. 大模型岗位面试总结:共24家,9个offer |
| 03. 视觉检测分割一切源码及在线Demo |
| 04. 动手学深度学习Pytorch |