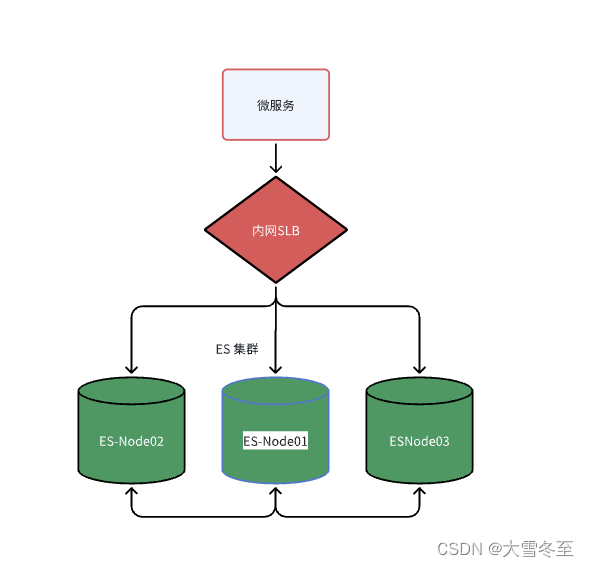
线上环境Es三节点集群搭建部署方案
1. 目标
!
2. 搭建步骤
- 官网教程: https://elasticsearch.bookhub.tech/set_up_elasticsearch/installing_elasticsearch/
| 机器名 | 内网IP | Es 版本 | 重点目录 | ||
|---|---|---|---|---|---|
| es-node01 | 192.18.233.240 | 7.15.1 | 安装目录: /home/work/elasticsearch/ 数据目录: /mnt/es/esdata 快照仓库: /mnt/es/snapshot 日志目录: /mnt/logs/eslogs | ||
| es-node02 | 192.18.233.229 | ||||
| es-node03 | 192.18.233.230 |
- es下载:
- https://mirrors.huaweicloud.com/elasticsearch/
- 目前Es8.x 处于开发阶段, 目前最新的稳定版本是 Elasticsearch 7.15.1
- https://mirrors.huaweicloud.com/elasticsearch/7.15.1/elasticsearch-7.15.1-linux-x86_64.tar.gz
- kibana下载:
- https://mirrors.huaweicloud.com/kibana/
# 下载,解压即可
cd /home/work/elasticsearch
wget https://mirrors.huaweicloud.com/elasticsearch/7.15.1/elasticsearch-7.15.1-linux-x86_64.tar.gz
# 解压
tar -zxvf elasticsearch-7.15.1-linux-x86_64.tar.gz
- 解压后的文件目录结构

#创建账号esadmin
useradd esadmin
#初始化密码
passwd esadmin
es1#user
#对esadmin授权目录
chown -R esadmin /home/work/elasticsearch/
chown -R esadmin /mnt/es/esdata
chown -R esadmin /mnt/logs/eslogs
chown -R esadmin /mnt/es/snapshot
chmod 777 /home/work/
- 官方参考:
- https://elasticsearch.bookhub.tech/set_up_elasticsearch/configuring_elasticsearch/
- 重点配置设置:
- https://elasticsearch.bookhub.tech/set_up_elasticsearch/configuring_elasticsearch/import_elasticsearch_configuration
- 在生产中,我们强烈建议你设置
elasticsearch.yml中的path.data和path.logs在$ES_HOME之外的位置。 - 断路器设置: https://elasticsearch.bookhub.tech/set_up_elasticsearch/configuring_elasticsearch/circuit_breaker_settings
- Elasticsearch有三个配置文件:(这些文件位于 config 目录中)
elasticsearch.yml用于配置 Elasticsearchjvm.options用于配置 Elasticsearch JVM 设置log4j2.properties用于配置 Elasticsearch 日志记录
- 示例如下: 以 node01(192.18.233.240) 为例,其他节点中可以直接复用这个配置,只修改
-
node.name 值即可。
-
elasticsearch.yml-
# 备份默认的配置文件 mv elasticsearch.yml elasticsearch.yml-bak # 编辑一个新文件 vi elasticsearch.yml # 集群名 cluster.name: es-cluster-prod # 节点名称 node.name: es-node01 ## 下面的配置项其他节点都统一内容## # HTTP端口 http.port: 9200 # Transport TCP端口 transport.tcp.port: 9300 # 数据存储路径 path.data: /mnt/es/esdata # 设置快照仓库目录 path.repo: ["/mnt/es/snapshot"] # 日志存储路径(将影响默认的执行日志,gc日志,致命错误日志的输出目录) path.logs: /mnt/logs/eslogs # 监听地址 network.host: 0.0.0.0 # 设置提供群集中其他节点的列表,这些节点具有选主资格 discovery.seed_hosts: ["172.18.233.240:9300", "172.18.233.229:9300", "172.18.233.230:9300"] # 初始主节点列表 cluster.initial_master_nodes: ["es-node01", "es-node02", "es-node03"] # 每隔多长时间ping一个node discovery.zen.fd.ping_interval: 30s # 每次ping的超时时间 discovery.zen.fd.ping_timeout: 120s # 一个node被ping多少次失败就认为是故障了 discovery.zen.fd.ping_retries: 6 # 集群脑裂问题参数配置 # elasticsearch则可以配置返回消息的节点数量, 一般情况下会配置(n/2 + 1)个节点 # 注意:discovery.zen.minimum_master_nodes 已经在Elasticsearch 7.x中被废弃 # 请使用 cluster.initial_master_nodes 参数来指定初始主节点列表 # 节点角色设置(默认就是启用的) node.ingest: true # HTTP跨域设置 http.cors.enabled: true http.cors.allow-origin: "*"
-
-
vi jvm.options
- 官方建议: 默认情况下,Elasticsearch 根据节点的角色和总内存自动设置 JVM 堆大小。我们建议大多数生产环境使用默认大小。
-
cp jvm.options jvm.options-bak vim jvm.options # 限制最大堆3GB -Xms3g -Xmx3g # 默认的HeapDumpPath是输出到安装目录的,因此可以修改。 -XX:HeapDumpPath=/mnt/logs/eslogs/heapdump # 致命错误日志 #-XX:ErrorFile=logs/hs_err_pid%p.log -XX:ErrorFile=/mnt/logs/eslogs/hs_err_pid%p.log # JDK 8 GC 日志 #8:-Xloggc:logs/gc.log 8:-Xloggc:/mnt/logs/eslogs/gc.log # JDK 9 GC 日志 # 将 file=logs/gc.log 改成 file=/mnt/logs/eslogs/gc.log #9-:-Xlog:gc*,gc+age=trace,safepoint:file=logs/gc.log:utctime,pid,tags:filecount=32,filesize=64m 9-:-Xlog:gc*,gc+age=trace,safepoint:file=/mnt/logs/eslogs/gc.log:utctime,pid,tags:filecount=32,filesize=64m
-
# 临时设置临时增加 vm.max_map_count 参数的值:
sysctl -w vm.max_map_count=262144
# 永久设置
vim /etc/sysctl.conf
vm.max_map_count=655360
# 保存后执行这个生效
sysctl -p
- 修改 /etc/security/limits.conf
vim /etc/security/limits.conf
esadmin soft nofile 65536
esadmin hard nofile 131072
esadmin soft nproc 4096
esadmin hard nproc 4096
# 保存退出后,重新登录 esadmin 用户检查效果
ulimit -a
# 进入安装目录
cd /home/work/elasticsearch/elasticsearch-7.15.1/bin
#切换账号
su esadmin
#后台启动命令
./elasticsearch -d
# 启动成功后,验证
curl
- 如果用 esadmin 用户启动时报错 AccessDeniedException: /home/work/elasticsearch/elasticsearch-7.15.1/config/elasticsearch.keystore 。 这个是因为 elasticsearch.keystore 文件默认是启动后才创建的,因此重新设置下文件权限即可
-
sudo chmod -R 755 /home/work/elasticsearch/elasticsearch-7.15.1/config/
-
- 如果启动时报错提示 could not find java in bundled JDK at xxxx
- 解决方案1: elasticsearch 7系列版本以上都是自带的jdk,可以在es的bin目录下找到 elasticsearch-env.bat 这个文件,配置es的jdk。官方推荐使用es自带的jdk。
-
warning: usage of JAVA_HOME is deprecated, use ES_JAVA_HOME
-
sudo vi /etc/profile export ES_JAVA_HOME=/home/work/elasticsearch/elasticsearch-7.15.1/jdk source /etc/profile
-
- 解决方案2: 使用系统安装的JDK
-
首先,确认已经安装了 Java。可以通过运行以下命令来检查 Java 是否已经安装: java -version 如果 Java 尚未安装,请使用以下命令安装 OpenJDK: sudo yum install java-1.8.0-openjdk-devel 打开终端,并使用以下命令编辑 /etc/profile 文件: sudo vi /etc/profile 在文件的末尾添加以下行,设置 JAVA_HOME 环境变量: export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk export PATH=$PATH:$JAVA_HOME/bin # 保存并关闭文件。然后,运行以下命令使更改生效: source /etc/profile 最后,可以通过运行以下命令来验证 JAVA_HOME 是否已正确设置: echo $JAVA_HOME
- 解决方案1: elasticsearch 7系列版本以上都是自带的jdk,可以在es的bin目录下找到 elasticsearch-env.bat 这个文件,配置es的jdk。官方推荐使用es自带的jdk。
- 三个节点都启动后,检查搭建结果
-
[root@iZwz9iqrw0w0p7ry2a8597Z ~]# [root@iZwz9iqrw0w0p7ry2a8597Z ~]# curl -XGET 'localhost:9200/_cat/health?v&pretty' epoch timestamp cluster status node.total node.data shards pri relo init unassign pending_tasks max_task_wait_time active_shards_percent 1701780738 12:52:18 es-cluster-prod green 3 3 2 1 0 0 0 0 - 100.0% [root@iZwz9iqrw0w0p7ry2a8597Z ~]# curl -XGET 'localhost:9200/_cat/nodes?v&pretty' ip heap.percent ram.percent cpu load_1m load_5m load_15m node.role master name 172.18.233.229 6 87 5 0.07 0.27 0.21 cdfhilmrstw - es-node02 172.18.233.230 7 86 4 0.05 0.21 0.19 cdfhilmrstw - es-node03 172.18.233.240 23 60 4 0.03 0.19 0.17 cdfhilmrstw * es-node01
-
附录
-
日常运维注意
-
关于数据目录的管理
-
不要修改数据目录中的任何内容或运行可能会干扰其内容的进程。如果 Elasticsearch 以外的其他内容修改了数据目录的内容,则 Elasticsearch 可能会失败,报告损坏或其他数据不一致,或者可能在默默丢失部分数据后正常工作。不要尝试对数据目录进行文件系统备份;不支持还原此类备份的方法。相反,请使用快照和还原来安全地进行备份。不要在数据目录上运行病毒扫描程序。病毒扫描程序可能会阻止 Elasticsearch 正常工作,并可能会修改数据目录的内容。数据目录不包含可执行文件,因此病毒扫描只会发现误报。
-
-
多数据路径在 7.13 中已被弃用,并将在未来版本中删除。
- 如果需要额外的磁盘空间,建议你添加新节点,而不是其他数据路径。


![[Angular] 笔记 10:服务与依赖注入](https://img-blog.csdnimg.cn/direct/c5f4e7938b7a48cd999fdb21660c4127.png)