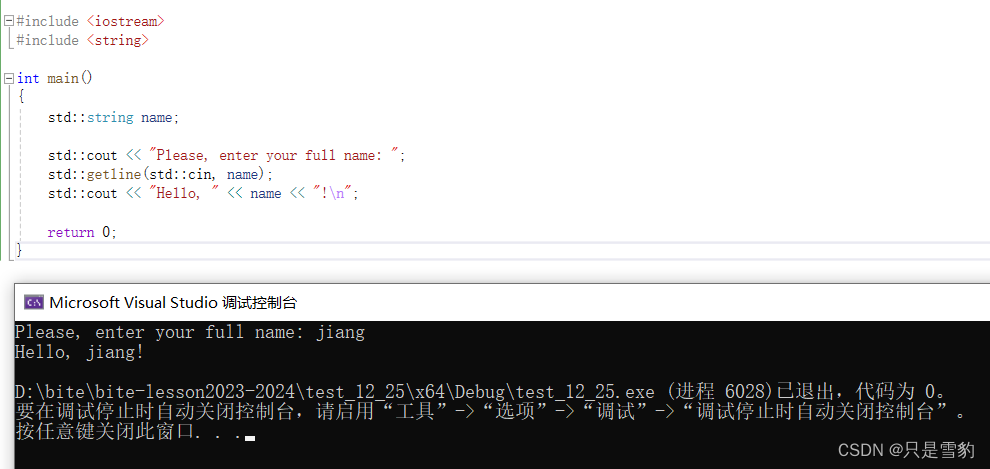
目标:对于拿到的一个任意数据集,编写类似数据加载程序,以适应深度学习的研究。
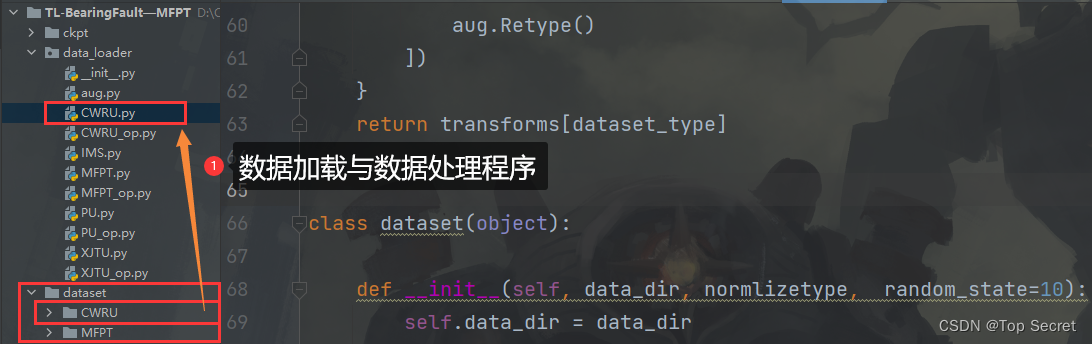
框架:
针对不同的时间序列数据集,可以总结如下关键步骤,以编写类似上述代码的深度学习数据处理流程:
1. **了解数据集:**
- 了解新数据集的特性,包括时间序列的长度、采样频率、数据格式和标签信息等。
2. **数据加载:**
- 实现加载时间序列数据的函数,可以使用常见的数据处理库(例如`pandas`、`numpy`)。
```python
# 例如,对CSV格式的时间序列数据进行加载
import pandas as pd
def load_time_series_data(file_path):
return pd.read_csv(file_path)
```
3. **数据预处理:**
- 根据时间序列数据的特点进行预处理,包括但不限于:
- 缺失值处理
- 平滑处理(如滤波)
- 标准化或归一化
- 特征工程(提取有用的特征)
```python
# 例如,简单的归一化处理
def normalize_time_series_data(data):
return (data - data.mean()) / data.std()
```
4. **数据分割:**
- 将时间序列数据集划分为训练集、验证集和测试集。
```python
# 例如,基于时间的分割
def split_time_series_data(data, train_ratio=0.8, val_ratio=0.1):
train_size = int(len(data) * train_ratio)
val_size = int(len(data) * val_ratio)
test_size = len(data) - train_size - val_size
train_data, val_data, test_data = data[:train_size], data[train_size:train_size + val_size], data[-test_size:]
return train_data, val_data, test_data
```
5. **序列切割:**
- 如果时间序列较长,可以将其切割成固定长度的序列,以便输入深度学习模型。
```python
# 例如,将时间序列切割成固定长度的子序列
def segment_time_series(data, segment_length):
segments = []
for i in range(0, len(data) - segment_length + 1, segment_length):
segments.append(data[i:i+segment_length])
return segments
```
6. **数据增强:**
- 根据需要,实现时间序列数据的数据增强方法,例如引入噪声、随机缩放等。
```python
# 例如,简单的添加噪声
import numpy as np
def add_noise_to_time_series(data, noise_level=0.1):
noise = np.random.normal(0, noise_level, len(data))
return data + noise
```
7. **构建数据集类:**
- 设计一个数据集类,整合加载、预处理、分割等操作,以便于在深度学习模型中使用。
```python
class TimeSeriesDataset:
def __init__(self, file_path, segment_length=256, train_ratio=0.8, val_ratio=0.1):
self.data = load_time_series_data(file_path)
self.data = normalize_time_series_data(self.data)
self.train_data, self.val_data, self.test_data = split_time_series_data(self.data, train_ratio, val_ratio)
self.train_segments = segment_time_series(self.train_data, segment_length)
# ...其他初始化步骤...
# 示例用法
time_series_dataset = TimeSeriesDataset('path/to/your/time_series_data.csv')
```
8. **数据管道:**
- 建立一个数据管道,确保数据有效地输入到深度学习模型中。
```python
# 例如,使用 TensorFlow 的数据管道
import tensorflow as tf
def create_data_pipeline(data, batch_size=32):
dataset = tf.data.Dataset.from_tensor_slices(data)
dataset = dataset.shuffle(buffer_size=len(data))
dataset = dataset.batch(batch_size)
return dataset
```
通过按照这些步骤组织代码,您可以更容易地处理不同时间序列数据集,并确保数据准备流程适应您的深度学习任务。
案例一:将如下LSTM的时间预测项目代码改为由数据加载和处理(data_loader)、模型(models) 、训练代码(train.py)三部分组成。
1.1 整体代码(修改前)
import torch
import torch.nn as nn
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 读取数据集
dataset = pd.read_csv(r'D:\datasets\预测模型实验\PRZ liquid space leak 0.8.csv')
# 将行数做成一列显式的索引列
dataset.insert(0, 'Index_Column', dataset.index)
all_data = dataset['主回路1热管段冷却剂温度(℃)306.852814'].values
# 数据预处理
# 定义划分比例
train_ratio = 0.8 # 80%的数据作为训练集
# 计算划分索引
split_index = int(len(dataset) * train_ratio)
# 划分数据
train_data = dataset.iloc[:split_index]
test_data = dataset.iloc[split_index:]
# 标准化
from sklearn.preprocessing import MinMaxScaler
# '主回路1热管段冷却剂温度(℃)306.852814' 是要归一化的列名
column_name = '主回路1热管段冷却剂温度(℃)306.852814'
# 将 DataFrame 转换为 NumPy 数组
train_data_array = train_data[column_name].values.reshape(-1, 1)
# 使用 MinMaxScaler 进行归一化
scaler = MinMaxScaler(feature_range=(-1, 1))
train_data_normalized = scaler.fit_transform(train_data_array)
# 数据张量化
train_data_normalized = torch.FloatTensor(train_data_normalized).view(-1)
# 训练数据转换为序列和相应的标签
train_window = 30
def create_inout_sequences(input_data, tw):
inout_seq = []
L = len(input_data)
for i in range(L-tw):
train_seq = input_data[i:i+tw]
train_label = input_data[i+tw:i+tw+1]
inout_seq.append((train_seq ,train_label))
return inout_seq
train_inout_seq = create_inout_sequences(train_data_normalized, train_window)
# 创建模型
import torch.nn as nn
class LSTM(nn.Module):
def __init__(self, input_size=1, hidden_layer_size=100, output_size=1):
super().__init__()
self.hidden_layer_size = hidden_layer_size
self.lstm = nn.LSTM(input_size, hidden_layer_size)
self.linear = nn.Linear(hidden_layer_size, output_size)
def forward(self, input_seq):
lstm_out, self.hidden_cell = self.lstm(input_seq.view(len(input_seq), 1, -1), self.hidden_cell)
predictions = self.linear(lstm_out.view(len(input_seq), -1))
return predictions[-1]
# 构建模型对象
model = LSTM()
loss_function = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
import matplotlib.pyplot as plt
epochs = 50
losses = [] # 用于存储每个 epoch 的损失值
for i in range(epochs):
epoch_loss = 0.0 # 用于累积每个 epoch 的损失值
for seq, labels in train_inout_seq:
optimizer.zero_grad()
model.hidden_cell = (torch.zeros(1, 1, model.hidden_layer_size),
torch.zeros(1, 1, model.hidden_layer_size))
y_pred = model(seq)
single_loss = loss_function(y_pred, labels)
single_loss.backward()
optimizer.step()
epoch_loss += single_loss.item()
losses.append(epoch_loss) # 记录每个 epoch 的损失值
if i % 5 == 0: # 每5个 epoch 打印一次损失值
print(f'Epoch [{i}/{epochs}], Loss: {epoch_loss:.8f}')
# 绘制损失曲线
plt.plot(losses)
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Training Loss Over Epochs')
plt.show()
# 进行预测
fut_pred = 30
test_inputs = train_data_normalized[-train_window:].tolist()
#print(test_inputs)
model.eval()
for i in range(fut_pred):
seq = torch.FloatTensor(test_inputs[-train_window:])
with torch.no_grad():
model.hidden = (torch.zeros(1, 1, model.hidden_layer_size),
torch.zeros(1, 1, model.hidden_layer_size))
test_inputs.append(model(seq).item())
# 将归一化后的预测值转换为实际预测值
actual_predictions = scaler.inverse_transform(np.array(test_inputs[train_window:] ).reshape(-1, 1))
# 可视化预测值与实际值
x = np.arange(437, 467, 1)
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei'] # 使用中文字体(例如:黑体)
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
plt.title('主回路1热管段冷却剂温度')
plt.ylabel('温度值')
plt.grid(True)
plt.autoscale(axis='x', tight=True)
plt.plot(dataset['主回路1热管段冷却剂温度(℃)306.852814'],label='实际温度')
plt.plot(x,actual_predictions, label='预测温度')
# 添加图例
plt.legend()
plt.show()将如上LSTM的时间预测项目代码改为由数据加载和处理(data_loader)、模型(models) 、训练代码(train.py)三部分组成。

1.2 数据加载和处理(data_loader)
将被用于深度学习的数据集定义为一个数据集类,数据的加载和预处理都通过这个类来实现。编写该类时,主要关注两个方面,其一是构造函数(详情如下),其二就是
构造函数:
初始化可控参数,包括加载数据(导入数据),初始化超参数,实例化某种工具(比如归一化实例)。
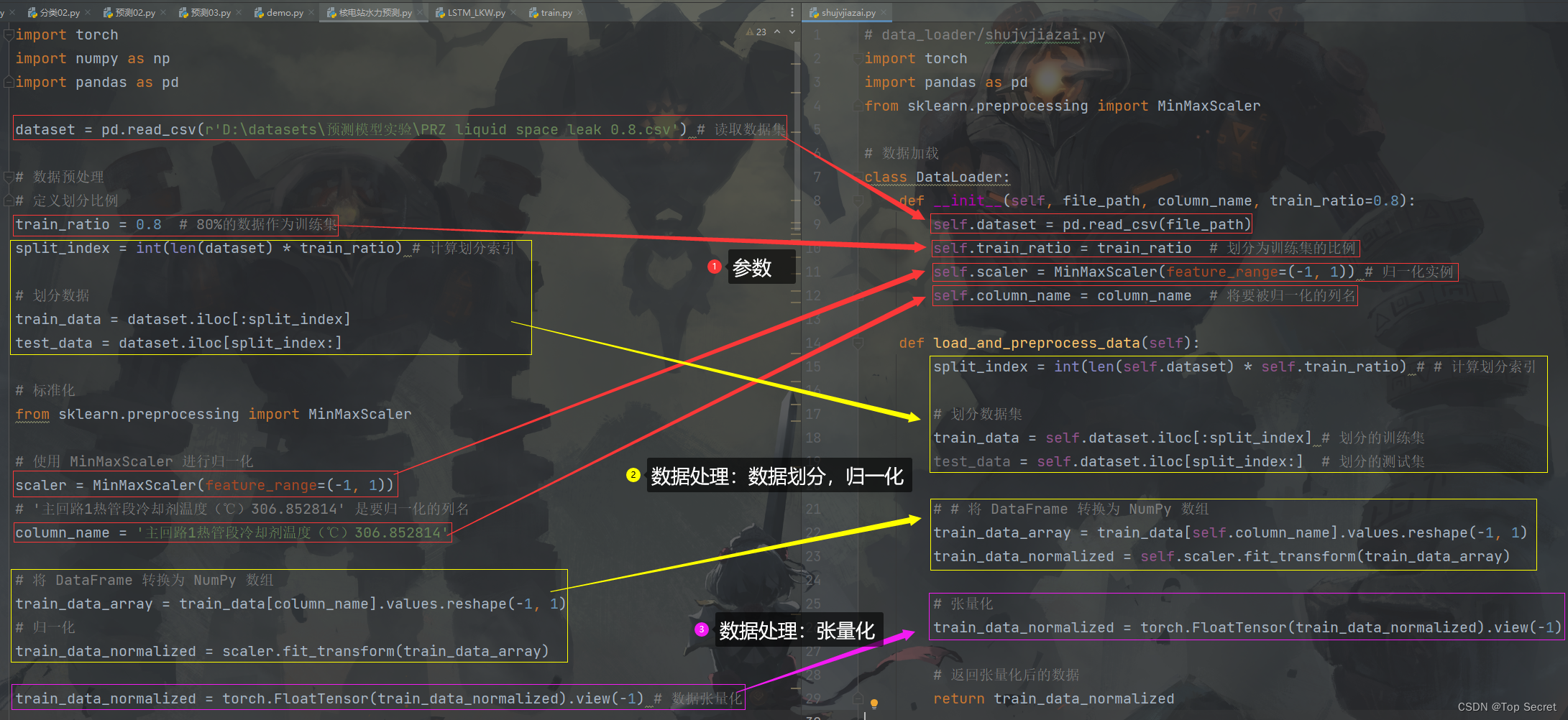
data_loader部分的代码:
# data_loader/shujvjiazai.py
import torch
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
# 数据加载
class DataLoader:
def __init__(self, file_path, column_name, train_ratio=0.8):
self.dataset = pd.read_csv(file_path)
self.train_ratio = train_ratio # 划分为训练集的比例
self.scaler = MinMaxScaler(feature_range=(-1, 1)) # 归一化实例
self.column_name = column_name # 将要被归一化的列名
def load_and_preprocess_data(self):
split_index = int(len(self.dataset) * self.train_ratio) # # 计算划分索引
# 划分数据集
train_data = self.dataset.iloc[:split_index] # 划分的训练集
test_data = self.dataset.iloc[split_index:] # 划分的测试集
# # 将 DataFrame 转换为 NumPy 数组
train_data_array = train_data[self.column_name].values.reshape(-1, 1)
train_data_normalized = self.scaler.fit_transform(train_data_array)
# 张量化
train_data_normalized = torch.FloatTensor(train_data_normalized).view(-1)
# 返回张量化后的数据
return train_data_normalized要点:
(1)构造函数负责加载数据和声明(初始化)可控参数。
(2)在函数中定义数据预处理的步骤,比如数据划分,归一化,张量化等。
1.3 模型(model)
整体代码中和将代码分写,关于model部分并无变化。
1.4 训练脚本(train.py)
在训练脚本train.py中,需要导入前面编写好的数据加载代码,比如要导入
data_loader/shujvjiazai.py中的数据处理类DataLoader
那就在train.py中做导入,即:
from data_loader.shujvjiazai import DataLoader
由上可知,也可以在shujvjiazai.py文件中写下多个不同的数据集处理类,比如class DataLoader1,class DataLoader2,class DataLoader3
这样当train中需要对某个数据集做训练时,只要在train.py中导入该数据集类即可。比如:
from data_loader.shujvjiazai import DataLoader2 # 应用数据集DataLoader2



关于创建模型实例,以及迭代训练模型的代码,train.py中好“一体化”代码并没有什么两样。
总结
若想改变原来写“一体化”代码的习惯,养成将代码分块,其实就是python中模块化的思想。
(1)首先,编写好数据加载和预处理模块(例如:data_loader/shujvjiazai.py ),导入数据,设置好一些超参数。
(2)然后再根据数据预处理的基本步骤,将各个步骤写成函数,于数据集类中。
(3)编写好模型代码(例如:models/LSTM_LKW.py )。
(4)编写好模型训练代码(train.py)。主要在于导入包部分,其他的训练代码的写法其实和“一体化”代码一样。导入如上(1)(3)中的数据和模型,所以在train.py中。需要导入这两个模块。