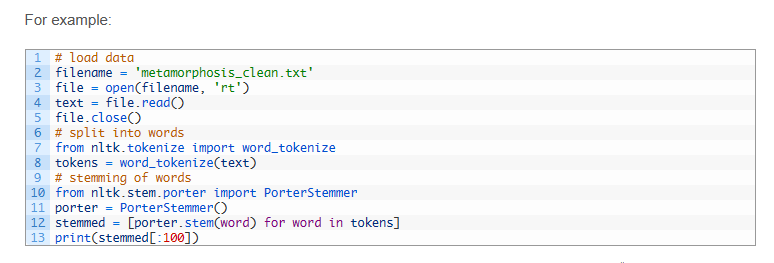
docker-compose.yml配置
version: "3"
services:
kafka:
image: 'bitnami/kafka:latest'
ports:
- '7050:7050'
environment:
- KAFKA_ENABLE_KRAFT=yes
- KAFKA_CFG_PROCESS_ROLES=broker,controller
- KAFKA_CFG_CONTROLLER_LISTENER_NAMES=CONTROLLER
- KAFKA_CFG_LISTENERS=PLAINTEXT://:7050,CONTROLLER://:7051
- KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP=CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT
- KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://183.56.203.157:7050
- KAFKA_BROKER_ID=1
- KAFKA_CFG_CONTROLLER_QUORUM_VOTERS=1@0.0.0.0:7051
- ALLOW_PLAINTEXT_LISTENER=yes
kafka UI界面
docker run -d --name kafka-map -p 8049:8080 -e DEFAULT_USERNAME=admin -e DEFAULT_PASSWORD=admin dushixiang/kafka-map:latest
docker run -p 8080:8080 -e KAFKA_BROKERS=host.docker.internal:9092 docker.redpanda.com/vectorized/console:master-173596f
UI界面总览
https://towardsdatascience.com/overview-of-ui-tools-for-monitoring-and-management-of-apache-kafka-clusters-8c383f897e80
kafka学习
生产者
import org.apache.kafka.clients.producer.Callback
import org.apache.kafka.clients.producer.KafkaProducer
import org.apache.kafka.clients.producer.ProducerConfig
import org.apache.kafka.clients.producer.ProducerRecord
import org.apache.kafka.common.serialization.StringSerializer
import org.junit.Test
import java.util.*
/**
* @Description :
* @Author xiaomh
* @date 2022/8/5 15:58
*/
class CustomProducer {
//异步发送
@Test
fun customProducer() {
//配置
val properties = Properties()
//链接kafka
properties[ProducerConfig.BOOTSTRAP_SERVERS_CONFIG] = "183.56.218.28:8000"
//指定对应key和value的序列化类型(二选一)
// properties[ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG] = "org.apache.kafka.common.serialization.StringSerializer"
properties[ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG] = StringSerializer::class.java.name
properties[ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG] = StringSerializer::class.java.name
//创建kafka生产者对象
val kafkaProducer = KafkaProducer<String, String>(properties)
//发送数据
for (i in 0 until 5) {
//黏性发送,达到设置的数据最大值/时间后,切换分区(不会是当前分区)
kafkaProducer.send(ProducerRecord("xiao1", "customProducer,count::$i"))
}
//关闭资源
kafkaProducer.close()
}
//同步发送
@Test
fun customProducerSync() {
//配置
val properties = Properties()
//链接kafka
properties[ProducerConfig.BOOTSTRAP_SERVERS_CONFIG] = "183.56.218.28:8000"
//指定对应key和value的序列化类型(二选一)
// properties[ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG] = "org.apache.kafka.common.serialization.StringSerializer"
properties[ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG] = StringSerializer::class.java.name
properties[ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG] = StringSerializer::class.java.name
//创建kafka生产者对象
val kafkaProducer = KafkaProducer<String, String>(properties)
//发送数据
for (i in 0 until 5) {
//黏性发送,达到设置的数据最大值/时间后,切换分区(不会是当前分区)
kafkaProducer.send(ProducerRecord("xiao1", "customProducerSync,count::$i")).get()
}
//关闭资源
kafkaProducer.close()
}
//回调异步发送
@Test
fun customProducerCallback() {
//配置
val properties = Properties()
//链接kafka
properties[ProducerConfig.BOOTSTRAP_SERVERS_CONFIG] = "183.56.218.28:8000"
//指定对应key和value的序列化类型(二选一)
// properties[ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG] = "org.apache.kafka.common.serialization.StringSerializer"
properties[ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG] = StringSerializer::class.java.name
properties[ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG] = StringSerializer::class.java.name
//创建kafka生产者对象
val kafkaProducer = KafkaProducer<String, String>(properties)
//发送数据
for (i in 0 until 500) {
//黏性发送,达到设置的数据最大值/时间后,切换分区(不会是当前分区)
kafkaProducer.send(ProducerRecord("xiao1", "customProducerCallback,count::$i"), Callback
{ metadata, exception ->
if (exception == null) {
println("主题:${metadata.topic()},分区:${metadata.partition()}")
}
})
//测试分区策略
Thread.sleep(1)
}
//关闭资源
kafkaProducer.close()
}
//回调异步发送+使用分区
@Test
fun customProducerCallbackPartitions1() {
//配置
val properties = Properties()
//链接kafka
properties[ProducerConfig.BOOTSTRAP_SERVERS_CONFIG] = "183.56.218.28:8000"
//指定对应key和value的序列化类型(二选一)
// properties[ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG] = "org.apache.kafka.common.serialization.StringSerializer"
properties[ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG] = StringSerializer::class.java.name
properties[ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG] = StringSerializer::class.java.name
//创建kafka生产者对象
val kafkaProducer = KafkaProducer<String, String>(properties)
//发送数据
for (i in 0 until 5) {
//1.没有指明partition值但有key的情况下,将key的hash值与topic的partition数进行取余得到partition值
//2.既没有partition值又没有key值的情况下,Kafka采用Sticky Partition(黏性分区器)
//key可以作为producer数据名,让consumer通过key找到
kafkaProducer.send(ProducerRecord("xiao1", 1, "", "customProducerCallbackPartitions,count::$i"), Callback
{ metadata, exception ->
if (exception == null) {
println("主题:${metadata.topic()},分区:${metadata.partition()}")
}
})
}
//关闭资源
kafkaProducer.close()
}
//回调异步发送+自定义分区
@Test
fun customProducerCallbackPartitions2() {
//配置
val properties = Properties()
//链接kafka,集群链接使用"183.56.203.157:7050,183.56.203.157:7051"
properties[ProducerConfig.BOOTSTRAP_SERVERS_CONFIG] = "183.56.218.28:8000"
//指定对应key和value的序列化类型(二选一)
// properties[ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG] = "org.apache.kafka.common.serialization.StringSerializer"
properties[ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG] = StringSerializer::class.java.name
properties[ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG] = StringSerializer::class.java.name
//关联自定义分区器
properties[ProducerConfig.PARTITIONER_CLASS_CONFIG] =
"com.umh.medicalbookingplatform.b2bapi.config.MyPartitioner"
//创建kafka生产者对象
val kafkaProducer = KafkaProducer<String, String>(properties)
//发送数据
for (i in 0 until 50) {
//1.没有指明partition值但有key的情况下,将key的hash值与topic的partition数进行取余得到partition值
//2.既没有partition值又没有key值的情况下,Kafka采用Sticky Partition(黏性分区器)
//key可以作为producer数据名,让consumer通过key找到
kafkaProducer.send(ProducerRecord("xiao1", "felix is strong,count::$i"), Callback
{ metadata, exception ->
if (exception == null) {
println("主题:${metadata.topic()},分区:${metadata.partition()}")
}
})
}
//关闭资源
kafkaProducer.close()
}
//自定义配置缓冲区、批次、等待时间、压缩
@Test
fun customProducerParameters() {
//配置
val properties = Properties()
properties[ProducerConfig.BOOTSTRAP_SERVERS_CONFIG] = "183.56.218.28:8000"
//指定对应key和value的序列化类型(二选一)
// properties[ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG] = "org.apache.kafka.common.serialization.StringSerializer"
properties[ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG] = StringSerializer::class.java.name
properties[ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG] = StringSerializer::class.java.name
//缓冲区大小。默认32,64=33554432x2
properties[ProducerConfig.BUFFER_MEMORY_CONFIG] = 33554432
//批次大小。默认16k
properties[ProducerConfig.BATCH_SIZE_CONFIG] = 16384
//等待时间。默认0
properties[ProducerConfig.LINGER_MS_CONFIG] = 1
//压缩.压缩,默认 none,可配置值 gzip、snappy、lz4 和 zstd
properties[ProducerConfig.COMPRESSION_TYPE_CONFIG] = "snappy"
//创建kafka生产者对象
val kafkaProducer = KafkaProducer<String, String>(properties)
for (i in 0 until 10) {
//1.没有指明partition值但有key的情况下,将key的hash值与topic的partition数进行取余得到partition值
//2.既没有partition值又没有key值的情况下,Kafka采用Sticky Partition(黏性分区器)
//key可以作为producer数据名,让consumer通过key找到
kafkaProducer.send(ProducerRecord("xiao1", "customProducerParameters::$i"), Callback
{ metadata, exception ->
if (exception == null) {
println("主题:${metadata.topic()},分区:${metadata.partition()}")
}
})
}
//关闭资源
kafkaProducer.close()
}
//ack、重试次数配置
@Test
fun customProducerAck() {
//配置
val properties = Properties()
properties[ProducerConfig.BOOTSTRAP_SERVERS_CONFIG] = "183.56.218.28:8000"
//指定对应key和value的序列化类型(二选一)
// properties[ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG] = "org.apache.kafka.common.serialization.StringSerializer"
properties[ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG] = StringSerializer::class.java.name
properties[ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG] = StringSerializer::class.java.name
//ack
properties[ProducerConfig.ACKS_CONFIG] = "1"
//重试次数
properties[ProducerConfig.RETRIES_CONFIG] = 30
//创建kafka生产者对象
val kafkaProducer = KafkaProducer<String, String>(properties)
for (i in 0 until 10) {
//1.没有指明partition值但有key的情况下,将key的hash值与topic的partition数进行取余得到partition值
//2.既没有partition值又没有key值的情况下,Kafka采用Sticky Partition(黏性分区器)
//key可以作为producer数据名,让consumer通过key找到
kafkaProducer.send(ProducerRecord("xiao1", "customProducerAck::$i"), Callback
{ metadata, exception ->
if (exception == null) {
println("主题:${metadata.topic()},分区:${metadata.partition()}")
}
})
}
//关闭资源
kafkaProducer.close()
}
//事物
@Test
fun customProducerTransaction() {
//配置
val properties = Properties()
properties[ProducerConfig.BOOTSTRAP_SERVERS_CONFIG] = "183.56.218.28:8000"
//指定对应key和value的序列化类型(二选一)
// properties[ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG] = "org.apache.kafka.common.serialization.StringSerializer"
properties[ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG] = StringSerializer::class.java.name
properties[ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG] = StringSerializer::class.java.name
//指定事务id,一定要指定!!
properties[ProducerConfig.TRANSACTIONAL_ID_CONFIG] = UUID.randomUUID().toString()
//创建kafka生产者对象
val kafkaProducer = KafkaProducer<String, String>(properties)
//开启事务
kafkaProducer.initTransactions()
kafkaProducer.beginTransaction()
try {
for (i in 0 until 10) {
//1.没有指明partition值但有key的情况下,将key的hash值与topic的partition数进行取余得到partition值
//2.既没有partition值又没有key值的情况下,Kafka采用Sticky Partition(黏性分区器)
//key可以作为producer数据名,让consumer通过key找到
kafkaProducer.send(ProducerRecord("xiao1", "customProducerTransaction::$i"), Callback
{ metadata, exception ->
if (exception == null) {
println("主题:${metadata.topic()},分区:${metadata.partition()}")
}
})
}
// val test: Int = 1 / 0
kafkaProducer.commitTransaction()
} catch (e: Exception) {
kafkaProducer.abortTransaction()
} finally {
//关闭资源
kafkaProducer.close()
}
}
}
消费者
1、一个consumer group中有多个consumer组成,一个 topic有多个partition组成,现在的问题是,到底由哪个consumer来消费哪个 partition的数据。
2、Kafka有四种主流的分区分配策略: Range、RoundRobin、Sticky、CooperativeSticky。 可以通过配置参数partition.assignment.strategy,修改分区的分配策略。默认策略是Range + CooperativeSticky。Kafka可以同时使用 多个分区分配策略。
3、每个消费者都会和coordinator保持心跳(默认3s),一旦超时 (session.timeout.ms=45s),该消费者会被移除,并触发再平衡; 或者消费者处理消息的过长(max.poll.interval.ms5分钟),也会触发再 平衡
package com.umh.medicalbookingplatform.api
import com.alibaba.fastjson.parser.ParserConfig
import com.fasterxml.jackson.databind.MapperFeature
import com.umh.medicalbookingplatform.core.audit.SpringSecurityAuditorAware
import com.umh.medicalbookingplatform.core.config.CoreConfiguration
import com.umh.medicalbookingplatform.core.jsonview.JsonViews
import com.umh.medicalbookingplatform.core.properties.ApplicationProperties
import com.umh.medicalbookingplatform.core.utils.ApplicationJsonObjectMapper
import org.jboss.resteasy.client.jaxrs.ResteasyClientBuilder
import org.keycloak.OAuth2Constants
import org.keycloak.admin.client.Keycloak
import org.keycloak.admin.client.KeycloakBuilder
import io.swagger.v3.oas.models.Components
import io.swagger.v3.oas.models.OpenAPI
import org.springframework.beans.factory.annotation.Autowired
import org.springframework.boot.autoconfigure.SpringBootApplication
import org.springframework.boot.runApplication
import org.springframework.boot.web.servlet.ServletComponentScan
import org.springframework.cache.annotation.EnableCaching
import org.springframework.context.annotation.Bean
import org.springframework.context.annotation.Import
import org.springframework.data.domain.AuditorAware
import org.springframework.data.jpa.repository.config.EnableJpaAuditing
import org.springframework.http.MediaType
import org.springframework.http.converter.HttpMessageConverter
import org.springframework.http.converter.ResourceHttpMessageConverter
import org.springframework.http.converter.json.MappingJackson2HttpMessageConverter
import org.springframework.scheduling.annotation.EnableScheduling
import org.springframework.web.servlet.config.annotation.WebMvcConfigurer
import java.security.Security
import java.util.*
import io.swagger.v3.oas.models.info.Info
import io.swagger.v3.oas.models.info.License
import org.apache.kafka.clients.consumer.ConsumerConfig
import org.apache.kafka.clients.consumer.ConsumerRecords
import org.apache.kafka.clients.consumer.KafkaConsumer
import org.apache.kafka.common.TopicPartition
import org.apache.kafka.common.serialization.StringDeserializer
import org.keycloak.adapters.KeycloakConfigResolver
import org.keycloak.adapters.springboot.KeycloakSpringBootConfigResolver
import org.keycloak.adapters.springboot.KeycloakSpringBootProperties
import org.springframework.http.converter.StringHttpMessageConverter
import java.time.Duration
import java.util.concurrent.TimeUnit
@EnableJpaAuditing
@EnableCaching
@EnableScheduling
@SpringBootApplication
@Import(CoreConfiguration::class)
@ServletComponentScan("com.umh.medicalbookingplatform")
open class ApiApplication : WebMvcConfigurer {
@Autowired
private lateinit var appProperties: ApplicationProperties
@Autowired
private lateinit var keycloakSpringBootProperties: KeycloakSpringBootProperties
@Bean
fun keycloakConfigResolver(): KeycloakConfigResolver {
return KeycloakSpringBootConfigResolver()
}
@Bean
fun fastJson(){
ParserConfig.getGlobalInstance().isAutoTypeSupport = true
}
@Bean
fun customConsumer() {
//配置
val properties = Properties()
//连接
properties[ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG] = "183.56.218.28:8000"
//反序列化(注意写法:生产者是序列化,消费者是反序列化)
properties[ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG] = StringDeserializer::class.java.name
properties[ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG] = StringDeserializer::class.java.name
//配置消费者组id(就算消费者组只有一个消费者也需要)
//当消费者组ID相同时,表示他们在同一个消费者组
//当有三个分区,而消费者组里又有三个消费者时,消费者会各自自动选取一个分区进行消费
properties[ConsumerConfig.GROUP_ID_CONFIG] = "test"
//1.创建一个消费者
val kafkaConsumer = KafkaConsumer<String, String>(properties)
//2.定义主题 xiao1
val topics = mutableListOf<String>()
topics.add("xiao1")
kafkaConsumer.subscribe(topics)
//3.消费数据
while (true) {
val consumerRecord: ConsumerRecords<String, String> = kafkaConsumer.poll(Duration.ofSeconds(1))
for (msg in consumerRecord) {
println("consumer,msg:::$msg")
}
}
}
// @Bean
fun customConsumerPartition() {
//配置
val properties = Properties()
//连接
properties[ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG] = "183.56.218.28:8000"
//反序列化(注意写法:生产者是序列化,消费者是反序列化)
properties[ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG] = StringDeserializer::class.java.name
properties[ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG] = StringDeserializer::class.java.name
//配置消费者组id(就算消费者组只有一个消费者也需要)
//当消费者组ID相同时,表示他们在同一个消费者组
properties[ConsumerConfig.GROUP_ID_CONFIG] = UUID.randomUUID().toString()
//1.创建一个消费者
val kafkaConsumer = KafkaConsumer<String, String>(properties)
//2.定义主题对应的分区
val topicPartition = mutableListOf<TopicPartition>()
topicPartition.add(TopicPartition("xiao1", 1))
kafkaConsumer.assign(topicPartition)
//3.消费数据
while (true) {
val consumerRecord: ConsumerRecords<String, String> = kafkaConsumer.poll(Duration.ofSeconds(1))
for (msg in consumerRecord) {
println("msg:::$msg")
}
}
}
@Bean(name = ["keycloakGlobalCmsApi"])
fun keycloakGlobalCmsApiInstance(): Keycloak {
return KeycloakBuilder.builder()
.serverUrl(appProperties.keycloakAuthServerUrl)//https://keycloak.umhgp.com/auth
.realm(appProperties.keycloakGlobalCmsRealm)//global_cms
.clientId(appProperties.keycloakGlobalCmsClient)//global-cms
.username(appProperties.keycloakApiUsername)//medical-booking-platform-system-uat
.password(appProperties.keycloakApiPassword)//Kas7aAnC76eGVHv5
.grantType(OAuth2Constants.PASSWORD)
.resteasyClient(
ResteasyClientBuilder()
.connectTimeout(10, TimeUnit.SECONDS)
.readTimeout(10, TimeUnit.SECONDS)
.connectionPoolSize(100).build()
).build()
}
@Bean(name = ["keycloakGlobalProfileApi"])
fun keycloakGlobalProfileApiInstance(): Keycloak {
return KeycloakBuilder.builder()
.serverUrl(appProperties.keycloakAuthServerUrl)
.realm(appProperties.keycloakGlobalProfileRealm)
.clientId(appProperties.keycloakGlobalProfileClient)
.username(appProperties.keycloakApiUsername)
.password(appProperties.keycloakApiPassword)
.grantType(OAuth2Constants.PASSWORD)
.resteasyClient(
ResteasyClientBuilder()
.connectTimeout(10, TimeUnit.SECONDS)
.readTimeout(10, TimeUnit.SECONDS)
.connectionPoolSize(100).build()
).build()
}
@Bean(name = ["keycloakBookingSystemApi"])
fun keycloakBookingSystemApiInstance(): Keycloak {
return KeycloakBuilder.builder()
.serverUrl(appProperties.keycloakAuthServerUrl)
.realm(appProperties.keycloakBookingSystemRealm)
.clientId(appProperties.keycloakBookingSystemClient)
.username(appProperties.keycloakApiUsername)
.password(appProperties.keycloakApiPassword)
.grantType(OAuth2Constants.PASSWORD)
.resteasyClient(
ResteasyClientBuilder()
.connectTimeout(10, TimeUnit.SECONDS)
.readTimeout(10, TimeUnit.SECONDS)
.connectionPoolSize(100).build()
).build()
}
@Bean(name = ["keycloakUmhBookingSystemApi"])
fun keycloakBookingSystemUmhApiInstance(): Keycloak {
return KeycloakBuilder.builder()
.serverUrl(appProperties.keycloakAuthServerUrl)
.realm(appProperties.keycloakUmhBookingSystemRealm)
.clientId(appProperties.keycloakUmhBookingSystemClient)
.username(appProperties.keycloakApiUsername)
.password(appProperties.keycloakApiPassword)
.grantType(OAuth2Constants.PASSWORD)
.resteasyClient(
ResteasyClientBuilder()
.connectTimeout(10, TimeUnit.SECONDS)
.readTimeout(10, TimeUnit.SECONDS)
.connectionPoolSize(100).build()
).build()
}
@Bean
internal fun auditorProvider(): AuditorAware<UUID> {
return SpringSecurityAuditorAware()
}
@Bean
fun customOpenAPI(): OpenAPI? {
return OpenAPI()
.components(Components())
.info(
Info().title("medical-booking-platform").version("1.5.8")
.license(License().name("Apache 2.0").url("http://springdoc.org"))
)
}
override fun configureMessageConverters(converters: MutableList<HttpMessageConverter<*>>) {
// ActuatorMediaTypes()
val supportedMediaTypes = ArrayList<MediaType>()
supportedMediaTypes.add(MediaType.APPLICATION_JSON)
supportedMediaTypes.add(MediaType.valueOf("application/vnd.spring-boot.actuator.v3+json"))
supportedMediaTypes.add(MediaType.TEXT_PLAIN)
val converter = MappingJackson2HttpMessageConverter()
val objectMapper = ApplicationJsonObjectMapper()
objectMapper.setConfig(objectMapper.serializationConfig.withView(JsonViews.Admin::class.java))
objectMapper.configure(MapperFeature.DEFAULT_VIEW_INCLUSION, true)
converter.objectMapper = objectMapper
converter.setPrettyPrint(true)
converter.supportedMediaTypes = supportedMediaTypes
converters.add(0, StringHttpMessageConverter())
converters.add(1, converter)
converters.add(ResourceHttpMessageConverter())
}
}
fun main(args: Array<String>) {
Security.setProperty("crypto.policy", "unlimited")
runApplication<ApiApplication>(*args)
}
range(范围)
Kafka 默认的分区分配策略就是 Range + CooperativeSticky,所以不需要修改策 略。
消费者分区操作:7分区2个消费者时
消费者1:消费分区0123
消费者2:消费分区456

在同一个消费者组,三消费者的情况下,如果其中一个宕机,45秒后会把消费者0需要处理的数据整个搬到消费者1或者消费者2.
结果:Consumer1=01234 或者 Consumer2=01256
随后如果再传输数据,消费者组会根据当前的消费者重新组织分配
Consumer0宕机45秒后再次传数据结果:Consumer1=0123 Consumer2=456
RoundRobin(轮询)
RoundRobin 针对集群中所有Topic而言。 RoundRobin 轮询分区策略,是把所有的 partition 和所有的 consumer 都列出来,然后按照 hashcode 进行排序,最后 通过轮询算法来分配 partition 给到各个消费者。
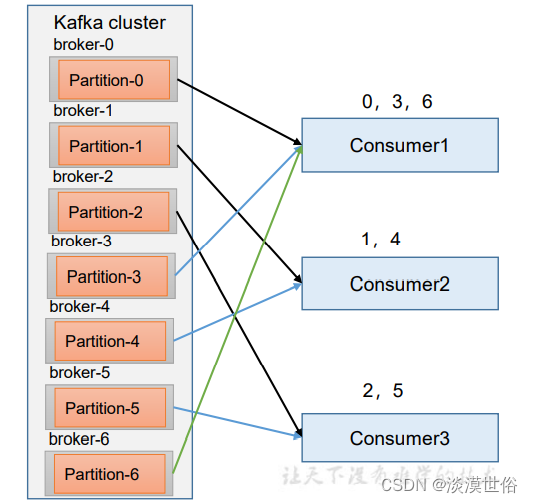
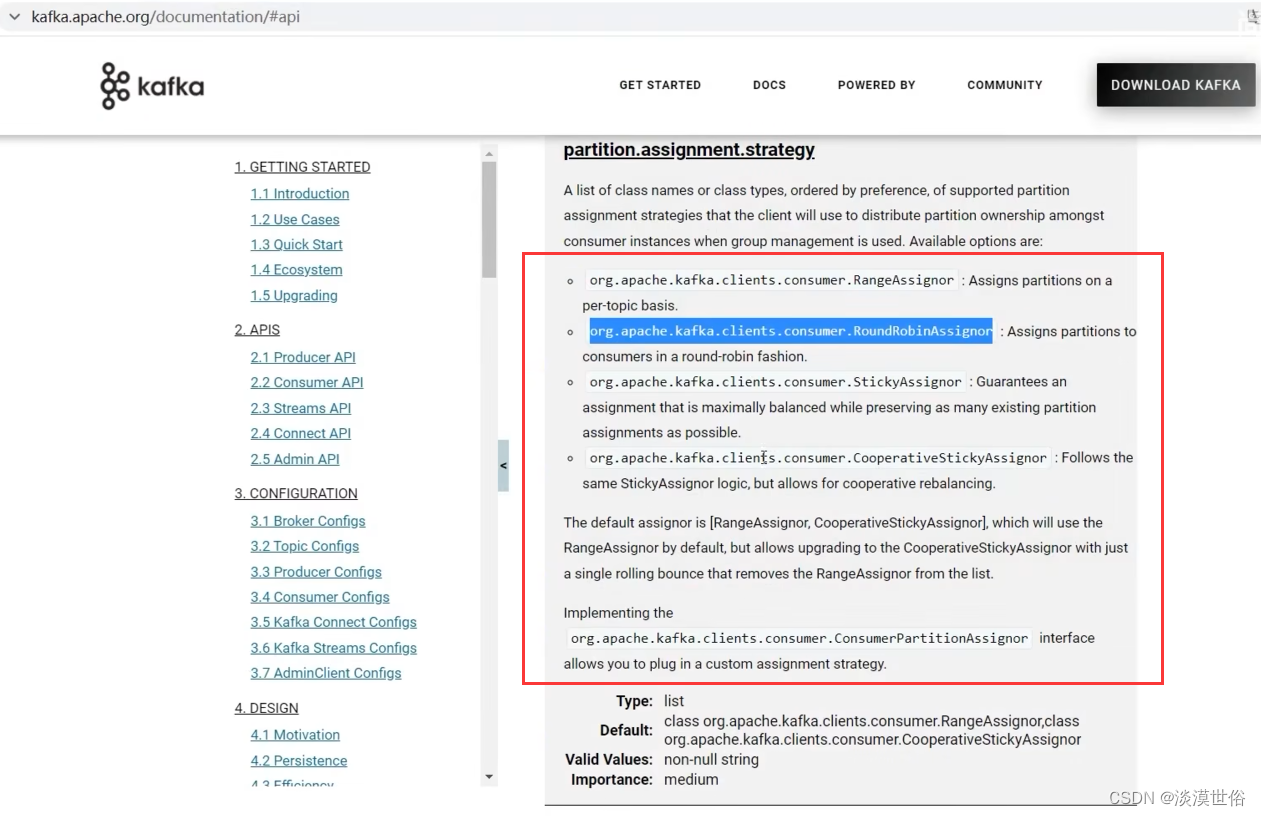
策略分配的修改
@Bean
fun customConsumer() {
//配置
val properties = Properties()
//连接
properties[ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG] = "183.56.218.28:8000"
//反序列化(注意写法:生产者是序列化,消费者是反序列化)
properties[ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG] = StringDeserializer::class.java.name
properties[ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG] = StringDeserializer::class.java.name
//配置消费者组id(就算消费者组只有一个消费者也需要)
//当消费者组ID相同时,表示他们在同一个消费者组
//当有三个分区,而消费者组里又有三个消费者时,消费者会各自自动选取一个分区进行消费
properties[ConsumerConfig.GROUP_ID_CONFIG] = "test"
//设置分区分配策略
properties[ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG] = "org.apache.kafka.clients.consumer.RoundRobinAssignor"
//1.创建一个消费者
val kafkaConsumer = KafkaConsumer<String, String>(properties)
//2.定义主题 xiao1
val topics = mutableListOf<String>()
topics.add("xiao1")
kafkaConsumer.subscribe(topics)
//3.消费数据
while (true) {
val consumerRecord: ConsumerRecords<String, String> = kafkaConsumer.poll(Duration.ofSeconds(1))
for (msg in consumerRecord) {
println("consumer,msg:::$msg")
}
}
}
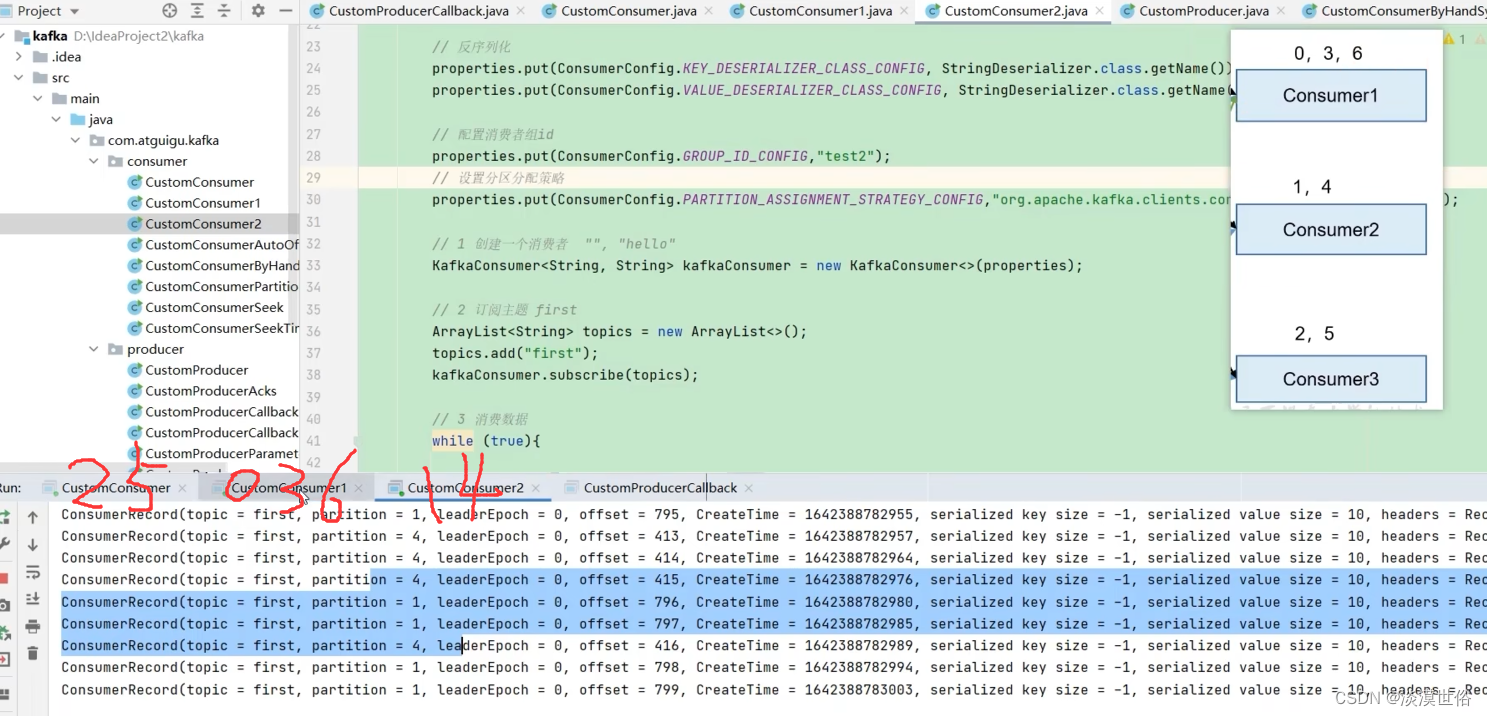

注意:06为一组给到一个消费者,3为一组给到另外一个消费者。45秒后重新发送数据,consumer2:0246,consumer3:135
Sticky (黏性)
(1)停止掉 0 号消费者,快速重新发送消息观看结果(45s 以内,越快越好)。
1 号消费者:消费到 2、5、3 号分区数据。
2 号消费者:消费到 4、6 号分区数据。
0 号消费者的任务会按照粘性规则,尽可能均衡的随机分成 0 和 1 号分区数据,分别 由 1 号消费者或者 2 号消费者消费。
说明:0 号消费者挂掉后,消费者组需要按照超时时间 45s 来判断它是否退出,所以需 要等待,时间到了 45s 后,判断它真的退出就会把任务分配给其他 broker 执行。
(2)再次重新发送消息观看结果(45s 以后)。
1 号消费者:消费到 2、3、5 号分区数据。
2 号消费者:消费到 0、1、4、6 号分区数据。
说明:消费者 0 已经被踢出消费者组,所以重新按照粘性方式分配。
 随机+均匀
随机+均匀
宕机后分配的消费者和45秒后分配消费者一样
宕机(3消费者变2消费者):1403,235
45秒后2消费者:1403,235
本文转自 https://blog.csdn.net/weixin_52925162/article/details/126280062?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522170100111416800225544545%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=170100111416800225544545&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2allfirst_rank_ecpm_v1~rank_v31_ecpm-8-126280062-null-null.142v96pc_search_result_base9&utm_term=keycloak%20docker-compose&spm=1018.2226.3001.4187,如有侵权,请联系删除。