作者:南宫兰 松下信息系统(上海)有限公司 数据分析部部长
松下集团在中国及东北亚地区拥有有64家法人公司,员工人数约4万人,业务范围涉及研究开发,养老、铸件、汽车、车载、能源、电池等多个方面,这些多元化的业务组合为松下常年可持续性发展提供坚实保障。中国地区的松下已有30多年的历史,集合了研发、生产、制造、流通、销售、服务于一体。
互联网浪潮下,松下作为百年传统制造业企业,在务实的坚实基础上进行创新,本文将围绕数字化改革中所遇挑战,松下数据治理实践及未来期待三部分进行说明。
松下集团在数字化改革中的挑战
多元化的业务组合为松下常年可持续性发展提供了坚实地保障,但也带来了不小的挑战。比如我们的业务种类丰富,体系大,供应链管理复杂,也给我们带来管理层面的各种挑战。PISSH是松下伞下的IT服务公司,包含大家比较了解的前端CRM,以及ERP、智能工厂MES,包括跨整体的数字化的大数据解决方案,这些基本上都是我们的辐射范围。因为我们松下是自带产业的,公司有大量的比较扎实的数字化解决的落地实际。
回顾正题,为什么要进行数字化改革?中国地区的松下已经有30多年的历史,在很长的时间内基本属于全球领先的电器制造商,像我们的骨干业务及研发、生产、制造、流通、销售服务于一体,产业也是涵盖B端、C端,这样的产业链条长,多液态并存的模式直接给我们带来的,特别是在数字化时代,给我们带来的冲击就是内部运营效率低下,对市场的相应速度不够快。市场我们C端主要是消费者,他们喜欢什么、喜欢什么样的设计、颜色、使用方式,这样我们后端的制造部分捕捉信息的能力就比较薄弱,这块也是数字化时代直接显现的课题。具体表现为以下几点:
- Excel是战斗武器
作为传统老牌制造业企业,公司长时间内依然基于Excel进行数字化表格的制作,工作人员需要耗费大量时间成本去完成,没有较好顺应互联网浪潮,因此需要迫切改变这一局面。
- 发展期后遗症
松下中国在发展的30年内组织不断分分合合,这样的过程导致不同时代的IT系统导入保留了它自身的痕迹,加剧了数据的私有化。
- 工作效率较低
公司发展过程中,间接部门沟通效率较低,导致工作效率与投入产出量化困难,员工的工作热情难以调动;
- 以年为单位长周期的PDCA
各部门的改进措施是不断进行中,但无法随时且快速发现整个领域的瓶颈。
- 思维层面与习惯层面的固化
老牌工业企业,历史包袱重,在过去几十年的经营过程当中形成的一种习惯性的思维,是最难解决的。导致运营效率低下,增加经营压力。
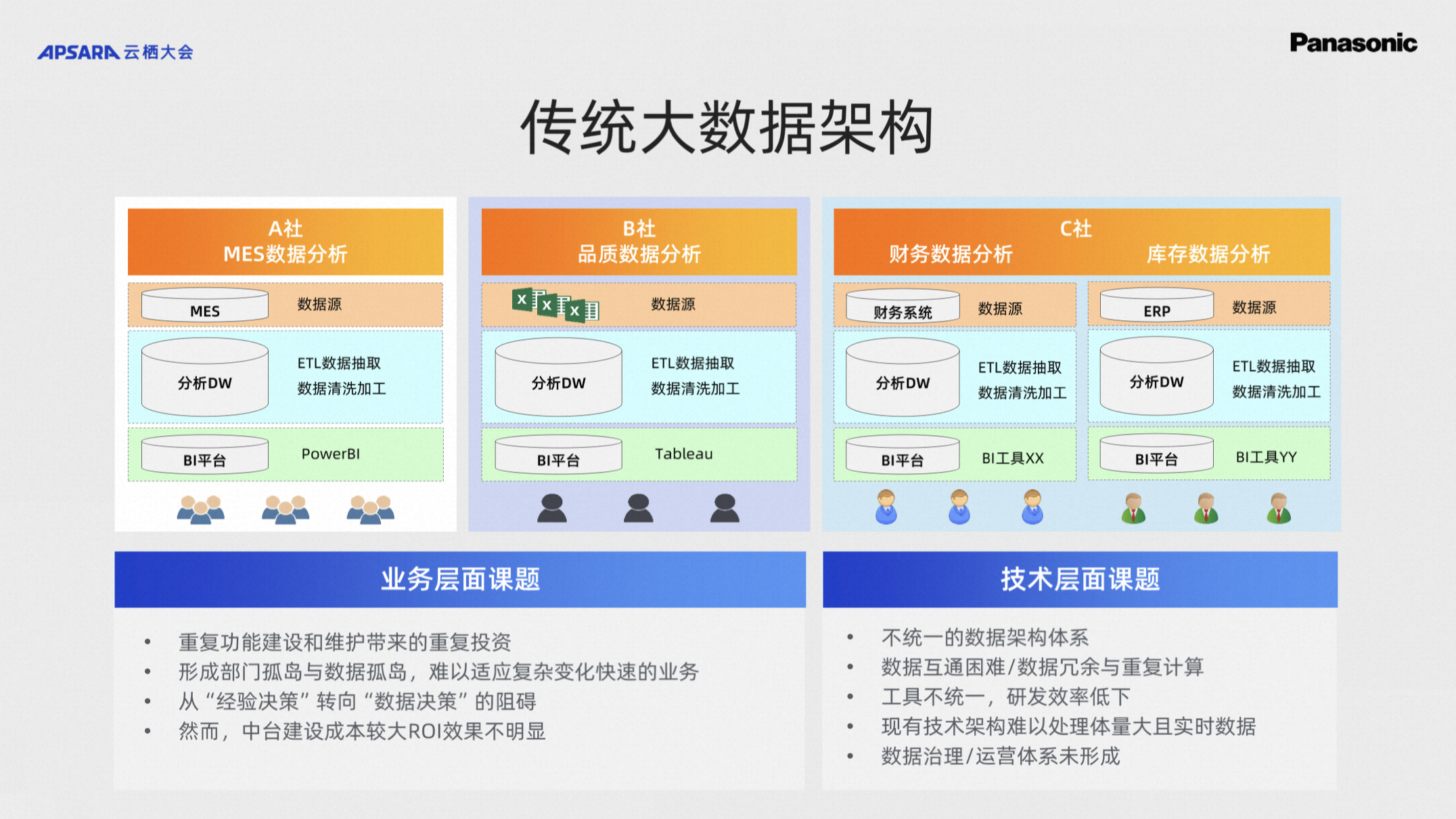
从数据架构层面拆借一下刚刚的问题,以前IT的导入模式,基本上是烟囱型的,典型的一类业务、一个IT系统、一个数据库,这个情况现在觉得应该是比较惨痛的现状,直接带来的是一个数据的孤岛现状,系统和系统之间的数据语言不统一带来的数据无法贯穿,带来的是数据无法分析。像我们的很多主数据,比如产品主数据、客户主数据,有些是在CRM系统里面,有些是在ERP系统里面,有些在Excel的表格里,我们到底分析的时候以哪个数据为准,这也带来了数据分析的准确性。
业务层面是算在决策者层面,作为松下集团旗下的法人公司,重复的IT建筑带来了重复的投资,决策者关注的是投资,重复的IT建设带来了一系列的技术层面的问题,我们的运维成本逐步提升。另外由于每个架构体系不太一样,因此我们要学习很多新技术和工具,给我们技术人员带来了极大的负担。
松下集团数据治理实践
数据治理目标
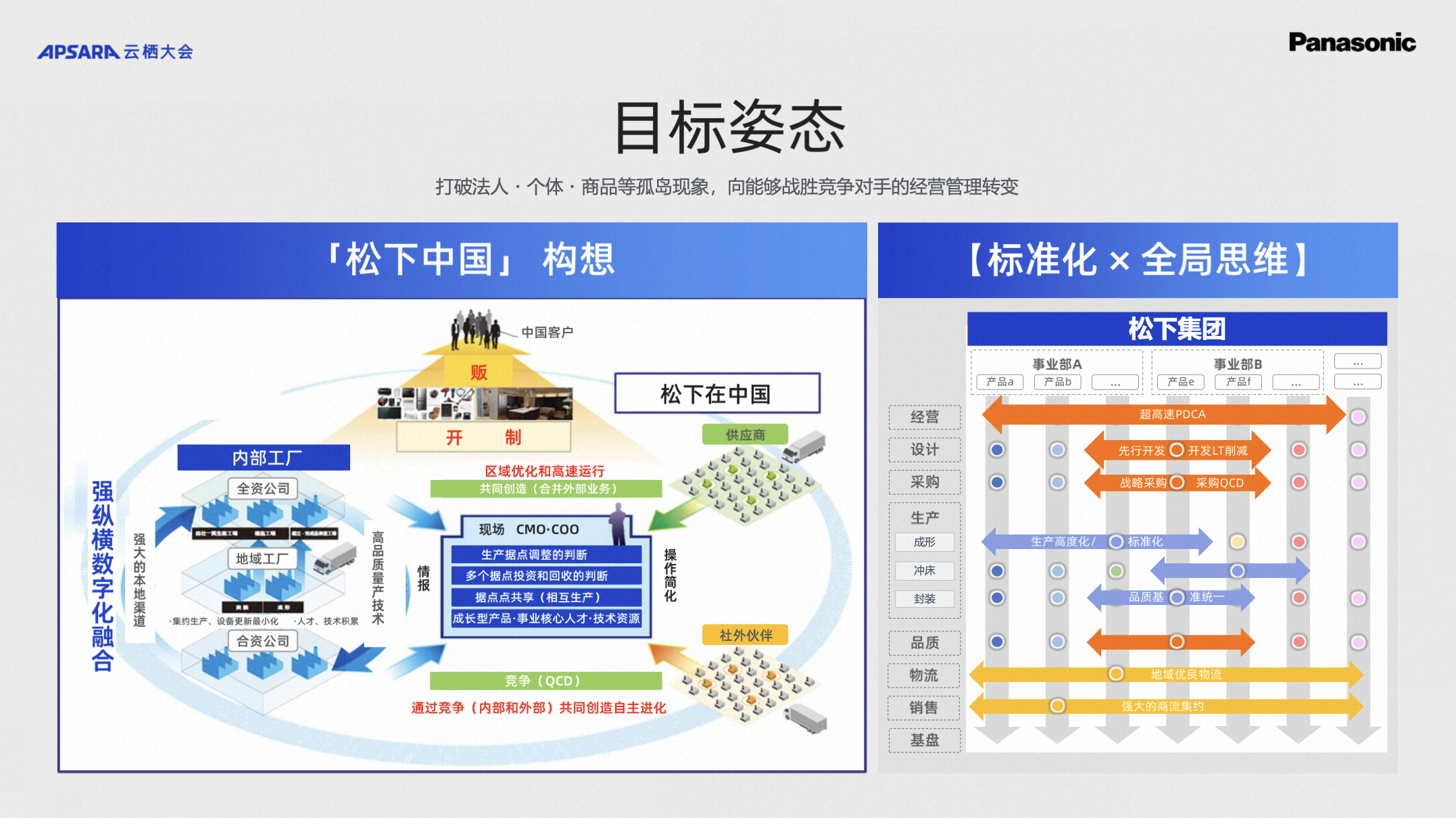
基于刚这几点,接下来简单分享一下松下是如何规划和实施的。首先是站在松下自己的全局视点,我们是以全局最优,不是各自法人最优。我们站在64家法人的视角,打破各自的事业部、法人、产品线,贯穿事业部,纵向打通8项业务场景,规划整体最优的数字化模式。我们的核心目标和刚才的话题也上下贯穿,我们要解决提升自己的运营效率,实现卓越运营。卓越运营现在是我们集团内部的大口号,带来的经营体现就是降本增效。
数据治理历程
分享一下近几年走过来的路,其实还是非常坎坷,松下作为几十年的企业,如今要做数据治理,要动一些根本,动起来是非常艰难的。三年前我们慢慢清晰地认识到这些课题,开始进行蓝图规划实施,
- 2021年我们正式在平台层面搭建了地域,构建了松下地域统一的大数据平台。
- 2022年我们基于大数据平台的基础上,在数据的应用层上面进行工作指标标准化、数据资产盘点,以及我们的开放规划的流程。在最上面的用户层我们进行产品化封装。
- 2023年7月松下得到属于制造业自己的数据中台著作权认证,成功获得软件著作权证书;创办数据分析学院,面向管理/技术/业务人员开展个性课程
- 未来几年,松下将会按照智能化、平台化、集成化这么一个三大轴来进行发展的。

规划统一数据全景图及架构
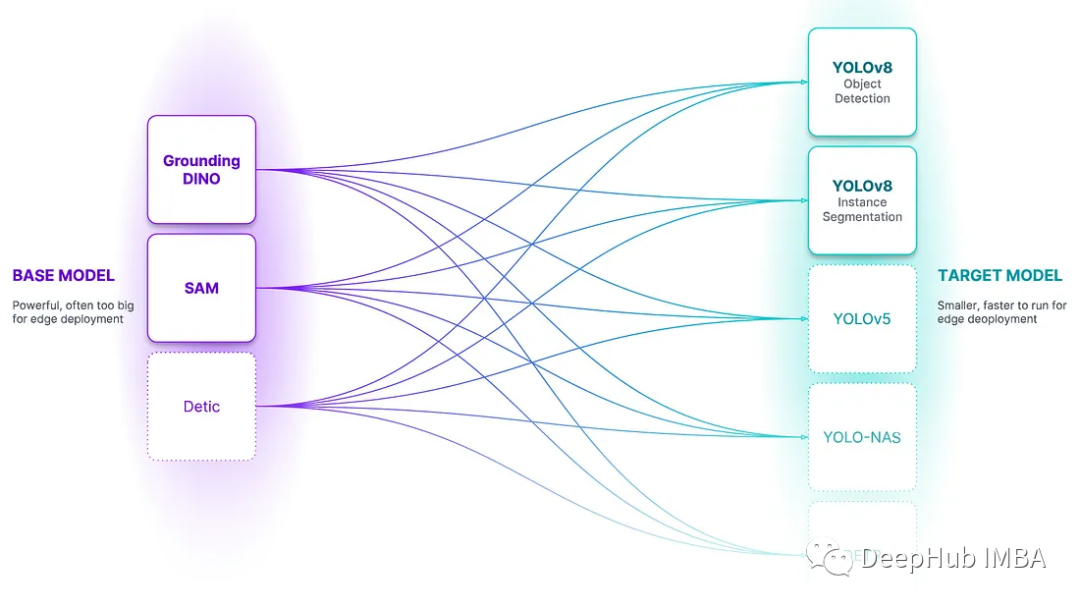
我们所规划的地域统一数据平台,全景图应用架构可以拆解成Serverless架构(数据底座),高度标准化/价值化,人材培养三方面。Serverless架构(数据底座)松下使用阿里云为稳定的基础设施,包含数据治理,计算引擎,数据存储,数据采集等架构。上一层数据应用的层面包括应用模型区,业务域指标体系,数据消费和数据应用区,以高度标准化/价值化进行衡量。业务域指标体系贯穿营销,计划,采购,制造,品质,仓储,物流,售后大业务所有,数据消费会更加满足多元化的数据消费诉求,基于这个基础上,我们有统一的数据应用区,方便用户直接投入使用。最后人材培养也十分重要,松下持续在培育人材投入大量精力,支持公司在未来将持续向智能化、平台化、集成化发力。

数据治理重点举措
1.架构选型-低成本、高性能、高可用Serverless架构
站在公司的角度来说,我们更多是要投入业务的实现,如何把现有的成熟的工具、产品经过组合,更高效地给应用方去使用,就像把现有的药品都拿过来,给用户、病人治病,这个是核心的指标。这样的目标决定了我们需要选择低成本、高性能、高可用Serverless架构。
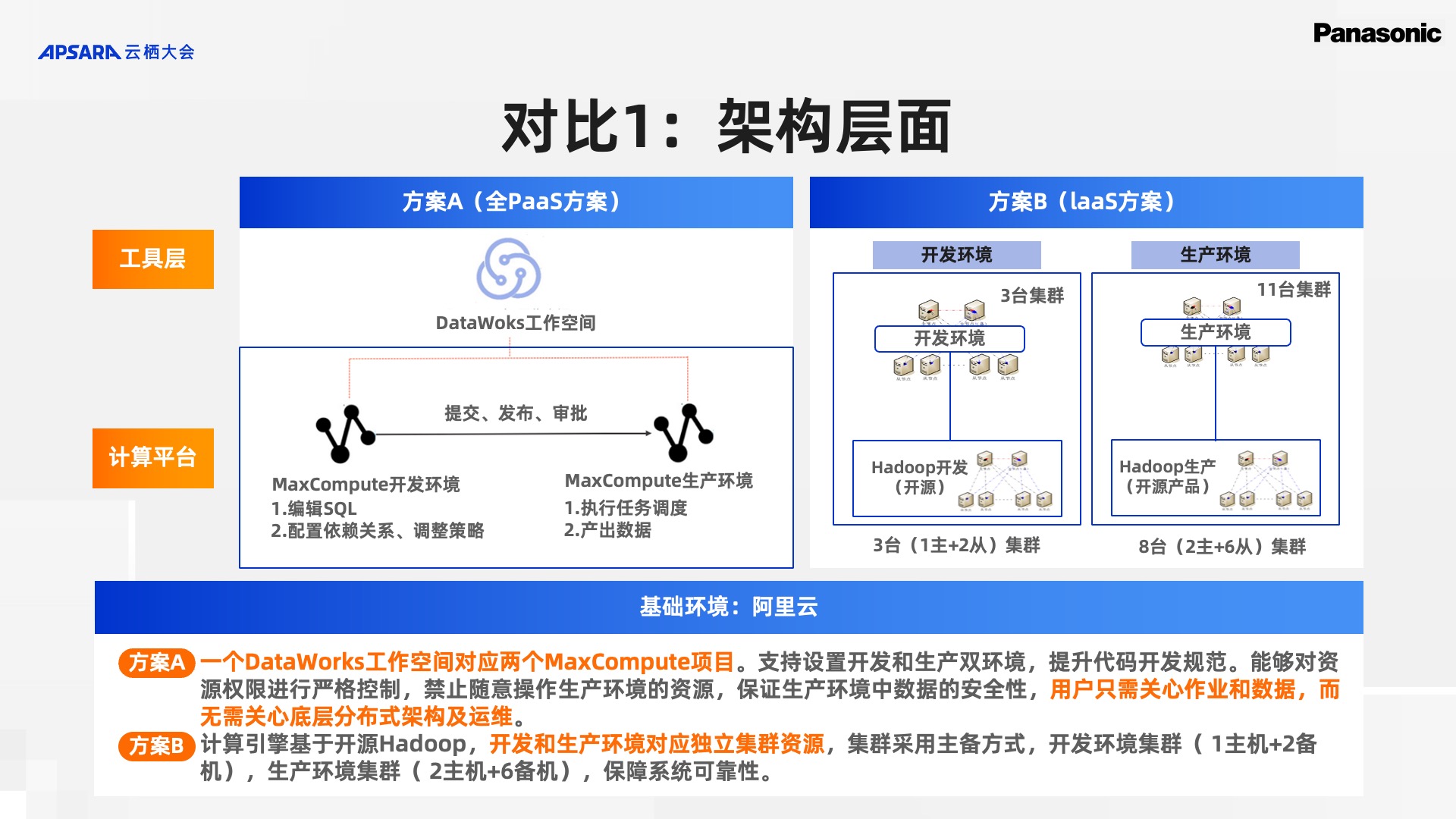
2021年我们架构选型的初期不同的友商给我们提供了不同方案,A是阿里云提供全托管的架构模式。B为友商产品提供的方案,两者方案在架构与核心组件有着不同点,对比如下:

架构层面对比
当我们把架构画出来的时候,基本就有答案了,方案A为阿里云全托管PasS方案,方案B为友商基于服务器的laaS方案,结合实际公司需求,采用阿里云全托管PasS方案,原因如下:
方案B
评估需要拥有16台虚拟机,分成两个环境,一个是开发环境、一个是生产环境。两个环境再切一刀我们就有4个集群。我们需要将有限的精力投入到业务实现上面,没有太多运维人员每天盯着服务器有没有宕机,服务器上面的任务是否正常执行等,没有那么多的资源精力投入做这件事。
方案A
一个DataWorks工作空间对应两个MaxCompute项目。支持设置开发和生产双环境,提升代码开发规范。能够对资源权限进行严格控制,禁止随意操作生产环境的资源,保证生产环境中数据的安全性,用户只需关心作业和数据,而无需关心底层分布式架构及运维。所以架构出来时,我们就选择了DataWorks+MaxCompute的组合。
关于开源平台与阿里云自研平台的思考:
我们的技术人员开源的情节比较深,我们刚开始选型当中也是一样的,因为我们技术人员成长背景、工作背景基本上都是基于开源做的,只有在开源的平台才能体现技术人员的实力。所以在选型的当初我们是比较排斥的MaxCompute,于是在计算引擎层,我们将开源与MaxCompute进行了全面的对比。

开源不是不好,例如更加丰富的组件,统一的元数据管理等等,但是一定要有公司战略、研发体系、研发团队的配备,人力财力物力多方面的支持,你如果这些底层资源能力足够的情况下,开源是可以考虑的方向。但是结合我们刚才提到自身的情况,我们最终是面向业务应用,希望能花更多的时间在提高运营效率上,于是我们最终决定使用阿里云自研的MaxCompute。

工具层对比:
再看一下工具层,我们继续详细拆解了阿里云DataWorks和另一个友商的产品,我将松下核心关注的部分简单列了下,比如说采购的模式、部署的方式、开放性等等,这种看起来比较一目了然。在做工具选型的时候,我们如果只是看PPT层面、其实会发现各家都非常相似,但是当我们实际使用测试之后,就会发现有有很大的不同。

以下是工具层面详细对标与优劣势总结:
友商产品:使用后发现产品过于封闭,比如我们松下有自己的账号体系,无法与松下自研产品进行绑定,不开放API的接口。有时任务失败了技术人员一定要把日志拿过来进行排查,日志的详细程度直接会影响我们解决问题的效果,这块友商没有阿里云DataWorks的详细。另外我们是面向集团内几十家法人提供服务的,并发任务会同时达到数十个、几百个,友商的产品任务并发数量有限,这几点会根本上限制公司产品选型。
阿里云DataWorks:使用一套用户认证体系,集成MyID,管理简单;图形化界面配置,操作简便;集成权限管理平台,可视化申请、审批和审计权限;可以进行全托管,无需管理维护集群,运维人力成本较低,并且拥有数据保护伞的全部功能;天然的多租户系统,适用于企业数据中台建设(数据,权限,计算资源等)。

架构层面总结-松下统一数据底座

上方架构是目前的数据底座,最左边经常会对接的数据源,因为数据源更多的是像工厂用的比较多ECM、CRM的数据源。数据源经过流批一体处理,把处理的结果通过数据服务,再投给最终的用户端。目前平台经过近几年打磨逐步完善规范化,包含数据湖,流批一体,数据应用,多元化数据服务等能力,BI、AI及底层算法能力也基本完备;数据治理能力基于标准化的规范及阿里云DataWorks,已经初步达到及格线。
2.敏捷创新快,高度标准化/价值化
以前我们标准化做的不够,举个例子,松下经常以库存的角度做盘点,比如彩电前端市场、滞留库存有多少,滞留库存的定义,我们每个法人定义都不太一样。比如在仓库呆了3个月算滞留,有些人觉得是6个月算滞留,有些人觉得是从过去的3个月到现在的6个月算滞留。因为集团决策层是要加起来看一些汇总值,计算口径不太一样,没法汇总。因为领导层不太理解底层的细节口径,主要看汇总值,如果看的数据不准确,也会直接影响他的决策。在清晰地认识到这些问题之后,我们再在统一架构的基础上联协了松下各个职能部门进行大刀阔斧的流程化改革。

技术架构只是物理上的统一,还需要在基础上做一些文化、业务流程上的标准。我们切中了两个维度,一个是业务,一个是技术。我们是技术方,不可能直接牵着业务改,后面有一个大的领导团,带着业务帮我们做一些梳理,比如清晰的定义指标,统一它的指标口径。另外我们从规范化建模这块,尽量沉淀公共层,像DWD、DWS等这些公共层。这样哪怕新的法人公司来开发的时候,复用率尽量做到极致。

这些年松下一直在逐迭代与改进,这个过程是一个漫长的过程,需要大家的齐心协力才能解决,近几年取的了一些初步的成效。从公司的战略来看,业务与数据双驱动,不断完善过程与规则数字化/标准化,提升数据服务能力,构筑统一的数据管理规则,确保形成清洁,完整,高效及复用的规范化模型。从平台和数据应用标准化梳理成果看,经过业务不断创新优化,平台整体成本下降30%,并且每年都有持续降本的指标。我们选择全托管开发模式极大提高了开发效率,做出大量标准化实施,并且在今年获得的制造业的软件著作权。

3.人才培养

现在我们是保姆式的服务方式把数据喂给客户端,但是这种方式价值就是有限的,发挥的能量不够大,它的瓶颈在哪?就是人才。我们大批的人对数据不懂,不知道怎么用数据,对于Excel很懂,但换一个模式的情况下对数据就不是懂了。
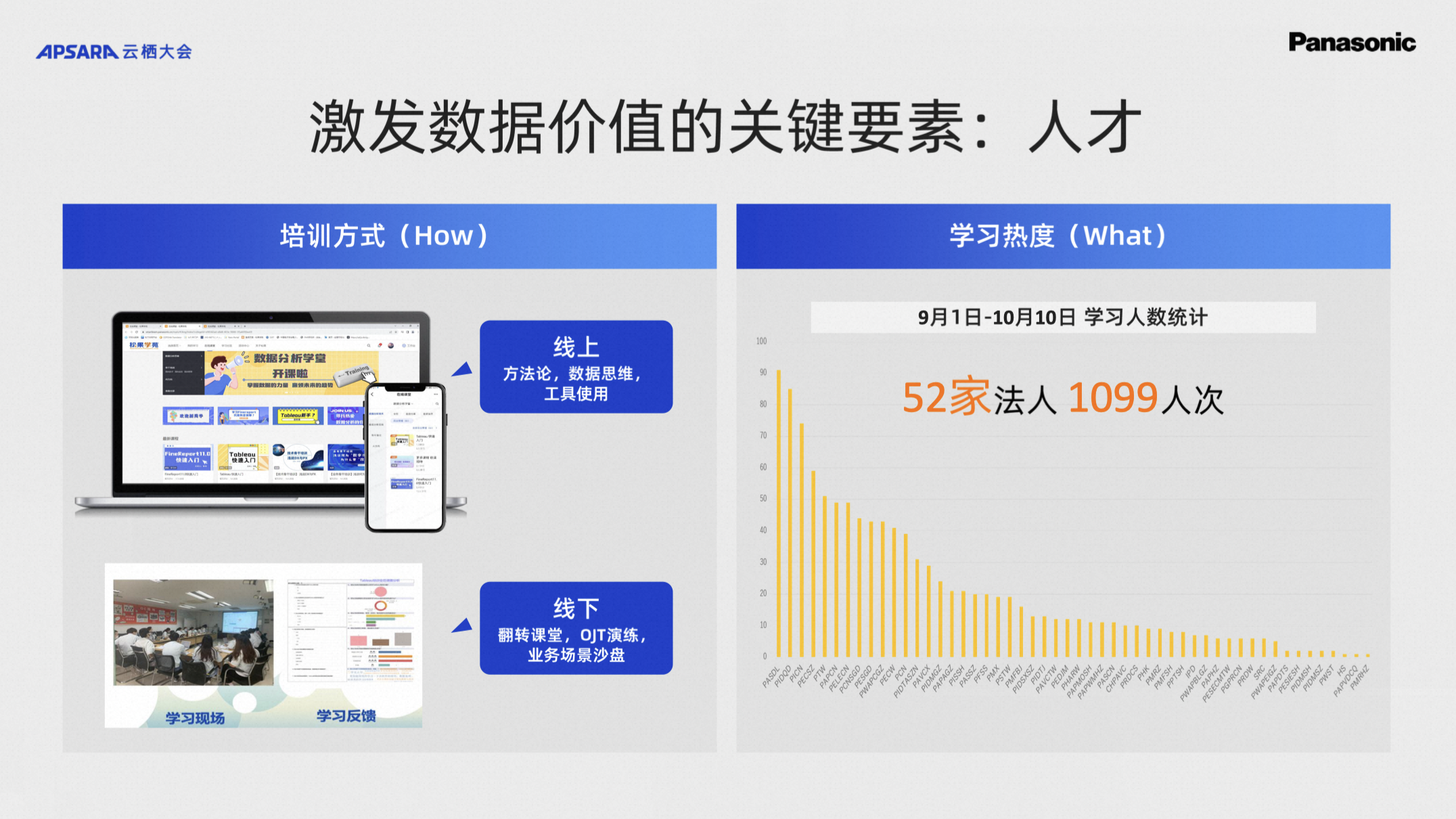
于是松下开设了数据分析学院,基于不同的人员分布,大批量对一线业务人员、IT等同事,集团内部人员进行一系列数据分析、大数据、算法相关的课程培训。本来我们以为这种学习方式没什么新意,就是线上线下的方式都会进行,没想到大家学习的热度非常高,从今年9月1日开学,截止10月10日,松下当前64家法人公司,覆盖了52家法人进行了学习。从侧面也反映了我们正在解决的技术痛点,其实也是大家平时在工作中的痛点。
未来思考
这个时代变化的太快,变和不确定是常态。对于企业未来的发展,万变不离其宗,我们要把握好宗。宗是我们当下基本要有的理念,是我们积极向上的企业文化。“向外看、求简化、促协作、勇挑战、乐成长”是我们松下的五大价值观,未来我们数字化转型的路没有那么好走,需要不断地调整自己战略的方向,基于这5个价值观我们有了一个明确的行动准则与思考路径。
- 向外看
对业务保持高度敏感,运用新技术、新手段、新理念,简化信息获取的复杂度,提供运营效率,不断提升工作幸福感
- 求简化
对业务保持高度敏感,运用新技术、新手段、新理念,简化信息获取的复杂度,提供运营效率,不断提升工作幸福感
- 促协作
积极促成业界的深入探讨,给同行提供借鉴,带来启发,共通推进数字化转型
- 勇挑战
改变思维,勇于跨出认知的局限,勇于走向外部市场,经历更加百花齐放的业态挑战。促使我们的产品化能力日益增强。
- 乐成长
学习能力是重要的核心竞争力,努力摆脱传统的学习方式,不断拓展学习的视野和疆界,提升学习的效率和效能。
最后,将总代表办公室的一句话送给大家,是李白的一首诗“长风破浪会有时、直挂云帆济沧海”。日系企业近几年和我们国内的企业横向对比,感觉它的动力不足,走的很辛苦,不仅仅是松下自己,也是整体行业的趋势。我们既然在这样的环境工作,不希望百年大厦倒在我们这一代的手上,接下来我们团队各位同事,以及公司各个合作方将一起继续合作,坚实地走下数字化转型的每一步路。