简洁高效的 NLP 入门指南: 200 行实现 Bert 文本分类 Pytorch 版
- 概述
- NLP 的不同任务
- Bert 概述
- MLM 任务 (Masked Language Modeling)
- Tokenize
- MLM 的工作原理
- 为什么使用 MLM
- NSP 任务 (Next Sentence Prediction)
- NSP 任务的工作原理
- NSP 任务栗子
- NSP 任务的调整和局限性
- 安装和环境配置
- PyTorch
- Transformers
- Bert 架构
- Transformer 模型基础
- Transformer 的两个主要组成部分
- Transformer Encoder
- Bert 的 TransformerEncoder 工作流程
- 200 行实现 Bert 文本分类 (Pytorch)
- tokenize
- 训练
- 测试部分
概述
在当今信息时代, 自然语言处理 (NLP, Natural Linguistic Processing) 已经称为人工智能领域的一个关键分支. NLP 的目标是使计算机能够理解, 解释和操作人类语言, 从而在各种应用中发挥作用, 如语音识别, 机器翻译, 情感分析等. 随着技术的进步, NLP 已经从简单的规则和统计方法发展到使用复杂的深度学习模型, 今天我们要来介绍的就是 Bert.

NLP 的不同任务
NLP 的不同任务包含:
- 文本分类 (Text Classification): 根据文本主题, 将文本分为不同的类别, 李儒新闻分类
- 情感分析 (Sentiment Analysis): 根据文本的情感倾向, 输出一个数, 表示文本的情感强度, 例如 0~5
- 机器翻译 (Machine Translation): 根据源语言的文本, 生成目标语言的文本, 例如 zh->en
- 命名实体识别 (Named Entity Recognition): 将文本中的实体 (例如人名, 地名, 组织名等) 进行标注
- 句法分析 (Parsing): 根据句子的句法结构, 将句子分解为句子成分
- 词性标注 (Part-of-speech Tagging): 根据词的语法特征, 给词标注一个词性
今年我们主要介绍的是文本分类任务.
Bert 概述
Bert (Bidirectional Encoder Representations from Transformers) 是一种基于 Transformer 架构的的模型. 在 2018 年由 Google 提出. Bert 采用了双向训练方法, 在模型学习给定的词时, 会考虑其上下文.
Bert 的双向训练方法包括下面两个方面:
- 模型结构: Bert 模型结构采用了双向 Transformer 编码器, 即模型可以从输入两端同时进行编码
- 预训练任务: Bert 的预训练任务包括 MLM (Masked Language Modeling) 任务和 NSP 任务, 这两个任务都需要 Bert 模型能够从文本的两端进行推理
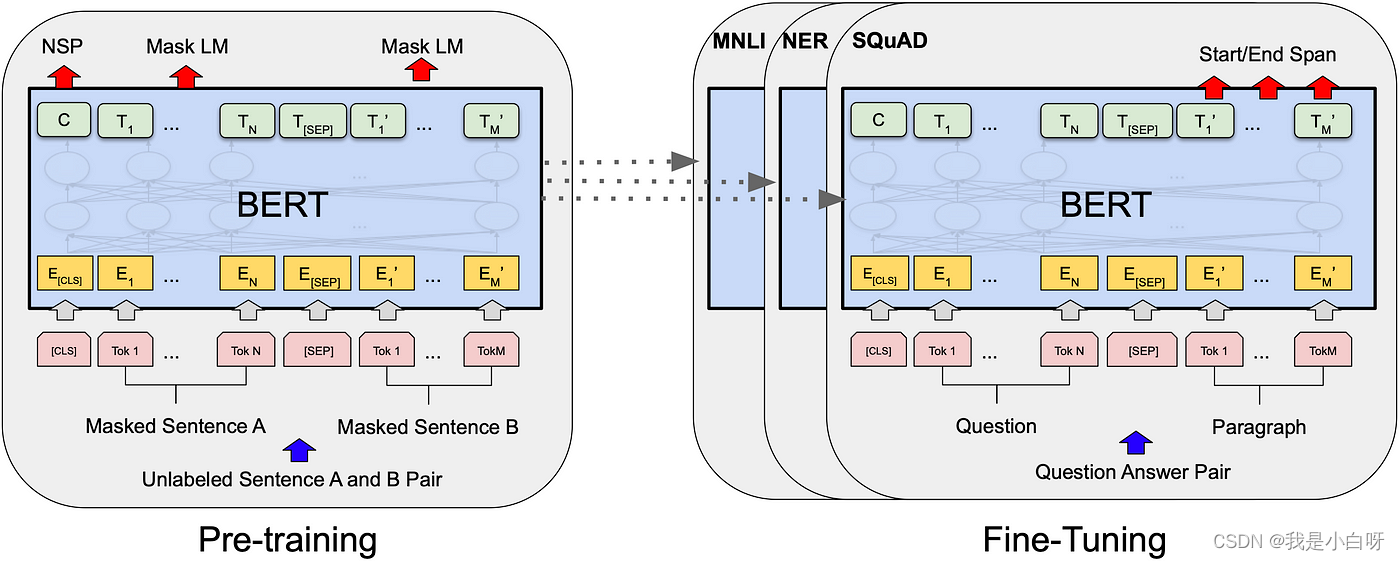
MLM 任务 (Masked Language Modeling)
MLM (Masked Language Modeling) 任务: 在 MLM 任务重, 会在输入文本中随机屏蔽一部分单词, 然后要求 Bert 模型预测被 Masked 单词的正确值.
Tokenize
分词 (Tokenization): 将文本按词 (Word) 为单位进行分割, 并转换为数字数据.
- 常见单词, 例如数据中的人名:
- Rachel对应 token id 5586
- Chandler对应 token id 13814
- Phoebe对应 token id 18188
- 上述 token id 对应 bert 的 vocab 中, roberta 的 vocab 表在服务器上, 懒得找了
- 特殊字符:
- [CLS]: token id 101, 表示句子的开始
- [SEP]: token id 102, 表示分隔句子或文本片段
- [PAD]: token id 0, 表示填充 (Padding), 当文本为达到指定长度时, 例如 512, 会用[PAD]进行填充
- [MASK]: token id 0, 表示填充 (Padding), 当文本为达到指定长度时, 例如 512, 会用[PAD]进行填充
上述字符在 Bert & Bert-like 模型中扮演着至关重要的角色, 在不同的任务重, 这些 Token ID 都是固定的, 例如 Bert 为 30522 个.
FYI: 上面的超链接是 jieba 分词的一个简单示例.
MLM 的工作原理
在 MLM 任务重, 输入文本首先被 Tokenize (分词), 词被转换为一个个数字数据, 文本由常见单词和特殊字符组成. 在处理过程中, 模型随机选择文本中的一定比例的 token (栗如: 15%). 并将这些标记替换为一个特定的特殊标记, 如[MASK](token id 0). 模型的任务是啥预测这些 mask token 的原始值.
为什么使用 MLM
MLM 的主要目的是使模型能够更好的理解语言的上下文和语义. 在传统的语言模型 (如 N-gram, 隐马可夫模型 HMM, 循环神经网络 RNN) 训练中模型都是单向的, 即模型只能考虑单词的前面或后面的上下文. 通过 MLM, 模型被迫学习使用一个单词前后的上下文来预测这个单词, 从而获得更全面的语言理解能力.
NSP 任务 (Next Sentence Prediction)
NSP (Next Sentence Prediction) 是 Bert 模型中的一个关键组成部分. NSP 用于改善模型对句子关系的理解, 特别是在理解段落或文档中句子关系方面. 这种能力对许多 NLP 任务至关重要, 例如: 问答系统, 文本摘要, 对话系统等.
NSP 任务的工作原理
在 NSP 任务重, 模型被训练来预测两个句子是否在原始文本中相邻. 这个过程涉及对句子间和语义关系的深入理解. 个栗子: A & B 俩句子, 模型需要判断 B 是否是紧跟在 A 后面的下一句. 在 Training 过冲中, Half time B 确实是 A 的下一句, 另一半时间 B 则是从语料库中随机选取的与 A 无关的句子. NSP 就是基于这些句子判断他们是否是连续的, 强迫模型学习识别句子的连贯性和上下文关系.
NSP 任务栗子
连续:
- 句子 A: “我是小白呀今年才 18 岁”
- 句子 B: “真年轻”
- NSP: 连续, B 是对 A 的回应 (年龄), 表达了作者 “我” 十分年轻
不连续:
- 句子 A: “意大利面要拌”
- 句子 B: “42 号混凝土”
- NSP: 不连续, B 和 A 内容完全无关
NSP 任务的调整和局限性
尽管在 NSP 和 Bert 的初期奔波中被广泛使用, 但是 NSP 也存在一些局限性. NSP 任务有时可能过于简化, 无法完全捕捉复杂文本中的细微关系.
随着 NLP 模型的发展, 一些研究发现去除 NSP 对某些模型的性能影响不大, 例如: Roberta, Xlnet, 和 Deberta 等后续模型都去除了 NSP 任务. 因为这些模型的底层双向结构已经足够强大, 能欧在没有 NSP 的情况下理解句子间的复杂关系.
安装和环境配置
PyTorch
pip install pytorch
Transformers
pip install transformers
Bert 架构
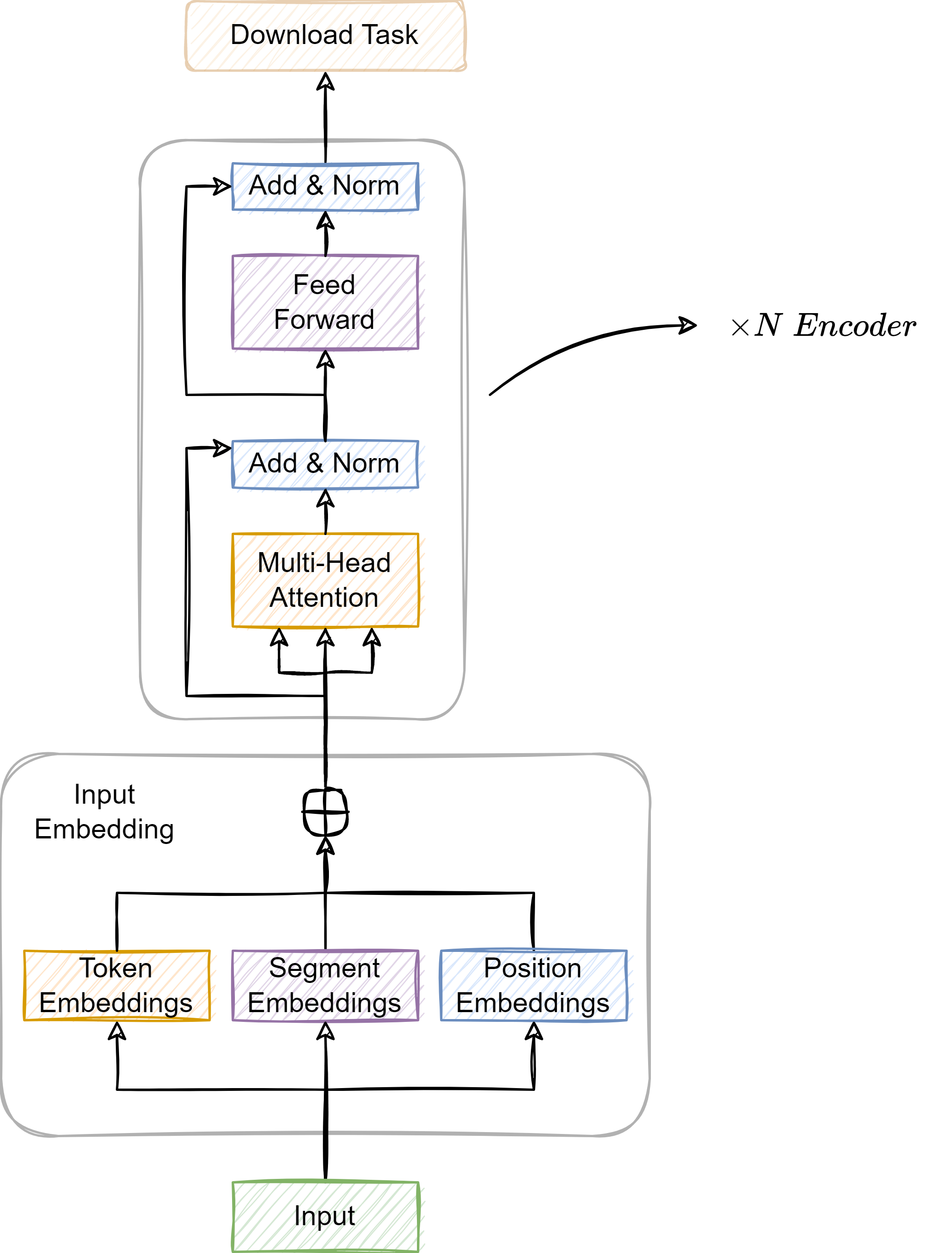
Transformer 模型基础
Transformer 模型在 2017 年被提出, 是一种基于注意力机制 (Attention) 的架构, 用于处理序列数据. 与之前的序列处理模型 (RNN 和 LSTM) 不同, Transformer 完全依赖于注意力机制来捕获序列的全局依赖关系, 这使得模型在处理长距离依赖时更加有效.
Transformer 的两个主要组成部分
- Encoder (编码器): 负责处理输入数据
- Decoder (解码器): 负责生成输出数据
Transformer Encoder
Bert 的核心组成部分之一是基于 Transformer 的编码器, 即 TrasnformerEncoder.
class TransformerEncoder(Layer):
def __init__(self, encoder_layer, num_layers, norm=None):
super(TransformerEncoder, self).__init__()
# 由多层encoder_layer组成,论文中给出,bert-base是12层,bert-large是24层,一层结构就如上图中蓝色框里的结构
# num_layers = 12 or 24
# LayerList称之为容器,使用方法和python里的list类似
self.layers = LayerList([(encoder_layer if i == 0 else type(encoder_layer)(**encoder_layer._config)) for i in range(num_layers)])
self.num_layers = num_layers
TransformerEncoder 由多个相同的层堆叠而成, 每层包含两个主要子层:
- 多头自注意力机制 (Multi-Head Self-Attention): 这个机制允许模型在处理每个单词时考虑到句子中的所有其他单词, 从而捕获复杂的内部依赖关系. Multi-Head 的设计使得模型能够同时从不同的表示子空间中学习信息
- 前馈神经网络 (Feed-Forward Neural Network): 每个注意力层后面都跟着一个简单的前馈神经网络, 这个网络对每个位置的输出进行独立处理
每个子层后面有一个残差链接 (Residual Connection) 和层归一化 (Layer Normalization). 残差连接有助于避免在深层网络中出现的梯度消失 (Vanishing Gradient) 问题, 而层归一化则有助于稳定训练过程.
Bert 的 TransformerEncoder 工作流程
- 输入表示: 输入文本首先被转换成词嵌入向量, 然后加上位置编码 (Positional Encoding), 以提供位置信息
- 通过多头自注意力 (Multi-Head Self-Attention) 层, 模型学习如何更加其他单词信息调整每个单词的表示
- 前馈网络: 每个位置的输出被送入前馈网络, 进一步处理每个单词的表示
- 重复多层处理: 过程在多个
TransformersEncoder层中重复进行, 每一层都进一步增强了模型对文本的理解
200 行实现 Bert 文本分类 (Pytorch)
tokenize
"""
@Module Name: bert.py
@Author: CSDN@我是小白呀
@Date: December 14, 2023
Description:
200 行实现 Bert 文本分类 (tokenize 部分)
"""
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from transformers import BertTokenizer
import pickle
bert_tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
MAX_LENGTH = 512
def load_data_raw():
# 读取数据
train = pd.read_csv("../../data/train.csv")
test = pd.read_csv("../../data/test.csv")
# 类别对应的数量
print(train.groupby(["category"])["category"].count())
# label 进行 one-hot
train["label"] = pd.get_dummies(train["label"]).to_numpy().tolist()
return train, test
def custom_truncate(text):
text_list = text.split(' ')
length = len(text_list)
if length <= 512:
return text
# 自定义截断函数
half_max_len = MAX_LENGTH // 2
first_half = ' '.join(text_list[:half_max_len])
last_half = ' '.join(text_list[-half_max_len:])
return first_half + ' ' + last_half
def tokenize_raw():
train, test = load_data_raw()
train_feature = train["text"].tolist()
train_label = train["label"].tolist()
test_feature = test["text"].tolist()
# 分割数据
X_train, X_valid, y_train, y_valid = train_test_split(train_feature, train_label, stratify=train_label,
random_state=0, test_size=0.1)
y_train = np.asarray(y_train, dtype=np.float32)
y_valid = np.asarray(y_valid, dtype=np.float32)
# 应用自定义截断
X_train = [custom_truncate(i) for i in X_train]
X_valid = [custom_truncate(i) for i in X_valid]
X_test = [custom_truncate(i) for i in test_feature]
# Tokenizer
X_train = bert_tokenizer(X_train, padding=True, truncation=True, max_length=MAX_LENGTH)
X_valid = bert_tokenizer(X_valid, padding=True, truncation=True, max_length=MAX_LENGTH)
X_test = bert_tokenizer(X_test, padding=True, truncation=True, max_length=MAX_LENGTH)
train_data = {
'X_train': X_train,
'X_valid': X_valid,
'y_train': y_train,
'y_valid': y_valid
}
# 保存
with open('../../save/raw/train_raw_cut.pkl', 'wb') as f:
pickle.dump(train_data, f)
with open('../../save/raw/test_raw_cut.pkl', 'wb') as f:
pickle.dump(X_test, f)
if __name__ == '__main__':
tokenize_raw()
训练
"""
@Module Name: bert.py
@Author: CSDN@我是小白呀
@Date: December 14, 2023
Description:
200 行实现 Bert 文本分类 (训练部分)
"""
import numpy as np
import torch
from torch.utils.data import DataLoader, TensorDataset
from transformers import BertModel, AdamW
import pickle
import time
from tqdm import tqdm
class BertForSingleInput(torch.nn.Module):
"""
Bert 单输入模型
"""
def __init__(self):
super(BertForSingleInput, self).__init__()
self.bert = BertModel.from_pretrained("bert-large-uncased")
self.classifier = torch.nn.Linear(self.bert.config.hidden_size, 24)
def forward(self, input_ids, attention_mask):
outputs = self.bert(input_ids, attention_mask=attention_mask)
pooled_output = outputs.pooler_output
logits = self.classifier(pooled_output)
return logits
# 超参数
EPOCHS = 20 # 迭代次数
BATCH_SIZE = 8 # 批次样本数
learning_rate = 3e-6 # 学习率
MAX_LENGTH = 512 # 最大长度
model = BertForSingleInput() # 实例化模型
optimizer = AdamW(model.parameters(), lr=learning_rate) # 优化器
loss_fn = torch.nn.CrossEntropyLoss() # 损失函数
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device) # 到 GPU
print("GPU 加速:", torch.cuda.is_available())
def get_data():
"""
读取 tokenize 后的数据
:return: 返回分批完的训练集和测试集
"""
with open('train.pkl', 'rb') as f:
combined_data = pickle.load(f)
X_train = combined_data['X_train']
X_valid = combined_data['X_valid']
y_train = combined_data['y_train']
y_valid = combined_data['y_valid']
# 获取input/mask
train_input = X_train["input_ids"]
train_mask = X_train["attention_mask"]
train_input = np.asarray(train_input)
train_mask = np.asarray(train_mask)
val_input = X_valid["input_ids"]
val_mask = X_valid["attention_mask"]
val_input = np.asarray(val_input)
val_mask = np.asarray(val_mask)
return train_input, val_input, train_mask, val_mask, y_train, y_valid
def main():
train_input, val_input, train_mask, val_mask, y_train, y_valid = get_data()
# 如果 y_train 和 y_valid 是独热编码的,需要转换为类别索引
y_train = np.argmax(y_train, axis=1)
y_valid = np.argmax(y_valid, axis=1)
# 数据转换为 PyTorch 张量
train_data = TensorDataset(torch.tensor(train_input), torch.tensor(train_mask), torch.tensor(y_train))
val_data = TensorDataset(torch.tensor(val_input), torch.tensor(val_mask), torch.tensor(y_valid))
train_dataloader = DataLoader(train_data, batch_size=BATCH_SIZE, shuffle=True)
val_dataloader = DataLoader(val_data, batch_size=BATCH_SIZE)
best_valid_loss = float('inf')
# 训练和验证模型
for epoch in range(EPOCHS):
start_time = time.time()
total_loss, total_accuracy = 0, 0
total_val_loss, total_val_accuracy = 0, 0
# 训练循环
model.train()
train_loop = tqdm(train_dataloader, desc=f'Epoch {epoch+1}/{EPOCHS} [Training]', leave=False)
for batch in train_loop:
input_ids, attention_mask, labels = [b.to(device) for b in batch]
optimizer.zero_grad()
outputs = model(input_ids, attention_mask)
loss = loss_fn(outputs, labels)
total_loss += loss.item()
_, predicted = torch.max(outputs, dim=1)
total_accuracy += (predicted == labels).sum().item()
loss.backward()
optimizer.step()
# 实时更新平均损失和准确率
current_avg_loss = total_loss / len(train_loop)
current_avg_accuracy = total_accuracy / (len(train_loop) * BATCH_SIZE)
train_loop.set_postfix(loss=current_avg_loss, accuracy=current_avg_accuracy)
avg_train_loss = total_loss / len(train_dataloader)
avg_train_accuracy = total_accuracy / (len(train_dataloader) * BATCH_SIZE)
# 验证循环
model.eval()
valid_loop = tqdm(val_dataloader, desc=f'Epoch {epoch+1}/{EPOCHS} [Validation]', leave=False)
with torch.no_grad():
for batch in valid_loop:
input_ids, attention_mask, labels = [b.to(device) for b in batch]
outputs = model(input_ids, attention_mask)
loss = loss_fn(outputs, labels)
total_val_loss += loss.item()
_, predicted = torch.max(outputs, 1)
total_val_accuracy += (predicted == labels).sum().item()
# 实时更新平均损失和准确率
current_avg_val_loss = total_val_loss / len(valid_loop)
current_avg_val_accuracy = total_val_accuracy / (len(valid_loop) * BATCH_SIZE)
valid_loop.set_postfix(loss=current_avg_val_loss, accuracy=current_avg_val_accuracy)
avg_valid_loss = total_val_loss / len(val_dataloader)
avg_valid_accuracy = total_val_accuracy / (len(val_dataloader) * BATCH_SIZE)
# 打印训练和验证结果
end_time = time.time()
epoch_mins, epoch_secs = divmod(end_time - start_time, 60)
print(f'Epoch: {epoch+1:02}/{EPOCHS} | Epoch Time: {epoch_mins:.0f}m {epoch_secs:.0f}s')
print(f'\tTrain Loss: {avg_train_loss:.4f} | Train Acc: {avg_train_accuracy*100:.2f}%')
print(f'\t Val. Loss: {avg_valid_loss:.4f} | Val. Acc: {avg_valid_accuracy*100:.2f}%')
# 保存最佳模型
if avg_valid_loss < best_valid_loss:
best_valid_loss = avg_valid_loss
torch.save(model.state_dict(), 'bert_large.pth')
print(f'Epoch {epoch+1}: Validation loss improved, saving model to bert_large.pth')
# 打印当前学习率
for param_group in optimizer.param_groups:
print(f'lr: {param_group["lr"]:.10f}')
if __name__ == '__main__':
main()
测试部分
"""
@Module Name: bert.py
@Author: CSDN@我是小白呀
@Date: December 14, 2023
Description:
200 行实现 Bert 文本分类 (测试部分)
"""
import pandas as pd
import torch
from torch.utils.data import DataLoader, TensorDataset
from transformers import BertModel
import pickle
from tqdm import tqdm
class BertForSingleInput(torch.nn.Module):
def __init__(self):
super(BertForSingleInput, self).__init__()
self.bert = BertModel.from_pretrained("bert-large-uncased")
self.classifier = torch.nn.Linear(self.bert.config.hidden_size, 24)
def forward(self, input_ids, attention_mask):
outputs = self.bert(input_ids, attention_mask=attention_mask)
pooled_output = outputs.pooler_output
logits = self.classifier(pooled_output)
return logits
# 加载模型
BATCH_SIZE = 128
model = BertForSingleInput()
model.load_state_dict(torch.load('../parallel/bert_large.pth'))
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
model.eval()
# 准备测试数据
def get_test_data():
with open('../../save/raw/test.pkl', 'rb') as f:
X_test = pickle.load(f)
test_data = TensorDataset(torch.tensor(X_test['input_ids']), torch.tensor(X_test['attention_mask']))
return test_data
test_data = get_test_data()
test_loader = DataLoader(test_data, batch_size=BATCH_SIZE, num_workers=14)
# 进行预测
predictions = []
with torch.no_grad():
for batch in tqdm(test_loader, desc="Predicting"): # 使用 tqdm 包装数据加载器
b_input_ids, b_input_mask = [t.to(device) for t in batch]
outputs = model(b_input_ids, b_input_mask)
_, predicted = torch.max(outputs, dim=1)
predictions.extend(predicted.cpu().numpy())
# 处理预测结果
test_df = pd.read_csv("../../data/test.csv")
test_df['label'] = predictions
test_df = test_df[['node_id', 'label']]
test_df.to_csv("submission.csv", index=False)