文章目录
- 设置
- 使用原始文本作为特征
- 使用预训练的文本嵌入
- 同时训练决策树和神经网络
- 构建模型
- 训练和评估模型
欢迎来到 TensorFlow决策森林( TF-DF)的 中级教程。
在本文中,您将学习有关 TF-DF的一些更高级的功能,包括如何处理自然语言特征。
本文假设您已经熟悉在决策森林中介绍的概念,特别是关于TF-DF的安装。
在本文中,您将会:
-
训练一个原生地将文本特征作为分类集合的随机森林。
-
使用TensorFlow Hub模块训练一个使用文本特征的随机森林。在这种情况下(迁移学习),该模块已经在一个大型文本语料库上进行了预训练。
-
同时训练一个梯度提升决策树(GBDT)和一个神经网络。GBDT将使用神经网络的输出作为输入。
设置
# 安装 TensorFlow Decision Forests 库
!pip install tensorflow_decision_forests
Collecting tensorflow_decision_forests
Using cached tensorflow_decision_forests-1.8.1-cp39-cp39-manylinux_2_17_x86_64.manylinux2014_x86_64.whl.metadata (6.0 kB)
Requirement already satisfied: numpy in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from tensorflow_decision_forests) (1.26.2)
Requirement already satisfied: pandas in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from tensorflow_decision_forests) (2.1.3)
Requirement already satisfied: tensorflow~=2.15.0 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from tensorflow_decision_forests) (2.15.0)
Requirement already satisfied: six in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from tensorflow_decision_forests) (1.16.0)
Requirement already satisfied: absl-py in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from tensorflow_decision_forests) (1.4.0)
Requirement already satisfied: wheel in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from tensorflow_decision_forests) (0.41.2)
Collecting wurlitzer (from tensorflow_decision_forests)
Using cached wurlitzer-3.0.3-py3-none-any.whl (7.3 kB)
Requirement already satisfied: astunparse>=1.6.0 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from tensorflow~=2.15.0->tensorflow_decision_forests) (1.6.3)
Requirement already satisfied: flatbuffers>=23.5.26 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from tensorflow~=2.15.0->tensorflow_decision_forests) (23.5.26)
Requirement already satisfied: gast!=0.5.0,!=0.5.1,!=0.5.2,>=0.2.1 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from tensorflow~=2.15.0->tensorflow_decision_forests) (0.5.4)
Requirement already satisfied: google-pasta>=0.1.1 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from tensorflow~=2.15.0->tensorflow_decision_forests) (0.2.0)
Requirement already satisfied: h5py>=2.9.0 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from tensorflow~=2.15.0->tensorflow_decision_forests) (3.10.0)
Requirement already satisfied: libclang>=13.0.0 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from tensorflow~=2.15.0->tensorflow_decision_forests) (16.0.6)
Requirement already satisfied: ml-dtypes~=0.2.0 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from tensorflow~=2.15.0->tensorflow_decision_forests) (0.2.0)
Requirement already satisfied: opt-einsum>=2.3.2 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from tensorflow~=2.15.0->tensorflow_decision_forests) (3.3.0)
Requirement already satisfied: packaging in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from tensorflow~=2.15.0->tensorflow_decision_forests) (23.2)
Requirement already satisfied: protobuf!=4.21.0,!=4.21.1,!=4.21.2,!=4.21.3,!=4.21.4,!=4.21.5,<5.0.0dev,>=3.20.3 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from tensorflow~=2.15.0->tensorflow_decision_forests) (3.20.3)
Requirement already satisfied: setuptools in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from tensorflow~=2.15.0->tensorflow_decision_forests) (68.2.2)
Requirement already satisfied: termcolor>=1.1.0 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from tensorflow~=2.15.0->tensorflow_decision_forests) (2.3.0)
Requirement already satisfied: typing-extensions>=3.6.6 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from tensorflow~=2.15.0->tensorflow_decision_forests) (4.8.0)
Requirement already satisfied: wrapt<1.15,>=1.11.0 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from tensorflow~=2.15.0->tensorflow_decision_forests) (1.14.1)
Requirement already satisfied: tensorflow-io-gcs-filesystem>=0.23.1 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from tensorflow~=2.15.0->tensorflow_decision_forests) (0.34.0)
Requirement already satisfied: grpcio<2.0,>=1.24.3 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from tensorflow~=2.15.0->tensorflow_decision_forests) (1.60.0rc1)
Requirement already satisfied: tensorboard<2.16,>=2.15 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from tensorflow~=2.15.0->tensorflow_decision_forests) (2.15.1)
Requirement already satisfied: tensorflow-estimator<2.16,>=2.15.0 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from tensorflow~=2.15.0->tensorflow_decision_forests) (2.15.0)
Requirement already satisfied: keras<2.16,>=2.15.0 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from tensorflow~=2.15.0->tensorflow_decision_forests) (2.15.0)
Requirement already satisfied: python-dateutil>=2.8.2 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from pandas->tensorflow_decision_forests) (2.8.2)
Requirement already satisfied: pytz>=2020.1 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from pandas->tensorflow_decision_forests) (2023.3.post1)
Requirement already satisfied: tzdata>=2022.1 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from pandas->tensorflow_decision_forests) (2023.3)
Requirement already satisfied: google-auth<3,>=1.6.3 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from tensorboard<2.16,>=2.15->tensorflow~=2.15.0->tensorflow_decision_forests) (2.23.4)
Requirement already satisfied: google-auth-oauthlib<2,>=0.5 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from tensorboard<2.16,>=2.15->tensorflow~=2.15.0->tensorflow_decision_forests) (1.1.0)
Requirement already satisfied: markdown>=2.6.8 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from tensorboard<2.16,>=2.15->tensorflow~=2.15.0->tensorflow_decision_forests) (3.5.1)
Requirement already satisfied: requests<3,>=2.21.0 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from tensorboard<2.16,>=2.15->tensorflow~=2.15.0->tensorflow_decision_forests) (2.31.0)
Requirement already satisfied: tensorboard-data-server<0.8.0,>=0.7.0 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from tensorboard<2.16,>=2.15->tensorflow~=2.15.0->tensorflow_decision_forests) (0.7.2)
Requirement already satisfied: werkzeug>=1.0.1 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from tensorboard<2.16,>=2.15->tensorflow~=2.15.0->tensorflow_decision_forests) (3.0.1)
Requirement already satisfied: cachetools<6.0,>=2.0.0 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from google-auth<3,>=1.6.3->tensorboard<2.16,>=2.15->tensorflow~=2.15.0->tensorflow_decision_forests) (5.3.2)
Requirement already satisfied: pyasn1-modules>=0.2.1 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from google-auth<3,>=1.6.3->tensorboard<2.16,>=2.15->tensorflow~=2.15.0->tensorflow_decision_forests) (0.3.0)
Requirement already satisfied: rsa<5,>=3.1.4 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from google-auth<3,>=1.6.3->tensorboard<2.16,>=2.15->tensorflow~=2.15.0->tensorflow_decision_forests) (4.9)
Requirement already satisfied: requests-oauthlib>=0.7.0 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from google-auth-oauthlib<2,>=0.5->tensorboard<2.16,>=2.15->tensorflow~=2.15.0->tensorflow_decision_forests) (1.3.1)
Requirement already satisfied: importlib-metadata>=4.4 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from markdown>=2.6.8->tensorboard<2.16,>=2.15->tensorflow~=2.15.0->tensorflow_decision_forests) (6.8.0)
Requirement already satisfied: charset-normalizer<4,>=2 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from requests<3,>=2.21.0->tensorboard<2.16,>=2.15->tensorflow~=2.15.0->tensorflow_decision_forests) (3.3.2)
Requirement already satisfied: idna<4,>=2.5 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from requests<3,>=2.21.0->tensorboard<2.16,>=2.15->tensorflow~=2.15.0->tensorflow_decision_forests) (3.4)
Requirement already satisfied: urllib3<3,>=1.21.1 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from requests<3,>=2.21.0->tensorboard<2.16,>=2.15->tensorflow~=2.15.0->tensorflow_decision_forests) (2.1.0)
Requirement already satisfied: certifi>=2017.4.17 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from requests<3,>=2.21.0->tensorboard<2.16,>=2.15->tensorflow~=2.15.0->tensorflow_decision_forests) (2023.11.17)
Requirement already satisfied: MarkupSafe>=2.1.1 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from werkzeug>=1.0.1->tensorboard<2.16,>=2.15->tensorflow~=2.15.0->tensorflow_decision_forests) (2.1.3)
Requirement already satisfied: zipp>=0.5 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from importlib-metadata>=4.4->markdown>=2.6.8->tensorboard<2.16,>=2.15->tensorflow~=2.15.0->tensorflow_decision_forests) (3.17.0)
Requirement already satisfied: pyasn1<0.6.0,>=0.4.6 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from pyasn1-modules>=0.2.1->google-auth<3,>=1.6.3->tensorboard<2.16,>=2.15->tensorflow~=2.15.0->tensorflow_decision_forests) (0.5.0)
Requirement already satisfied: oauthlib>=3.0.0 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from requests-oauthlib>=0.7.0->google-auth-oauthlib<2,>=0.5->tensorboard<2.16,>=2.15->tensorflow~=2.15.0->tensorflow_decision_forests) (3.2.2)
Using cached tensorflow_decision_forests-1.8.1-cp39-cp39-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (15.3 MB)
Installing collected packages: wurlitzer, tensorflow_decision_forests
Successfully installed tensorflow_decision_forests-1.8.1 wurlitzer-3.0.3
Wurlitzer 是在 Colabs 中显示详细的训练日志所需的(当在模型构造函数中使用 verbose=2 时)。
# 安装wurlitzer模块,用于在Jupyter Notebook中显示C语言的输出结果
!pip install wurlitzer
Requirement already satisfied: wurlitzer in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (3.0.3)
导入必要的库。
# 导入所需的库
import tensorflow_decision_forests as tfdf # 导入决策森林库
import os # 导入操作系统库
import numpy as np # 导入数值计算库
import pandas as pd # 导入数据处理库
import tensorflow as tf # 导入深度学习库
import math # 导入数学库
2023-11-20 12:31:20.226021: E external/local_xla/xla/stream_executor/cuda/cuda_dnn.cc:9261] Unable to register cuDNN factory: Attempting to register factory for plugin cuDNN when one has already been registered
2023-11-20 12:31:20.226066: E external/local_xla/xla/stream_executor/cuda/cuda_fft.cc:607] Unable to register cuFFT factory: Attempting to register factory for plugin cuFFT when one has already been registered
2023-11-20 12:31:20.227643: E external/local_xla/xla/stream_executor/cuda/cuda_blas.cc:1515] Unable to register cuBLAS factory: Attempting to register factory for plugin cuBLAS when one has already been registered
隐藏的代码单元格在colab中限制了输出的高度。
#@title
# 导入所需的模块
from IPython.core.magic import register_line_magic
from IPython.display import Javascript
from IPython.display import display as ipy_display
# 定义一个魔术命令,用于设置单元格的最大高度
@register_line_magic
def set_cell_height(size):
# 调用Javascript代码,设置单元格的最大高度
ipy_display(
Javascript("google.colab.output.setIframeHeight(0, true, {maxHeight: " +
str(size) + "})"))
使用原始文本作为特征
TF-DF可以原生地处理categorical-set特征。Categorical-sets将文本特征表示为词袋(或n-grams)。
例如:"The little blue dog" → {"the", "little", "blue", "dog"}
在这个例子中,您将在Stanford Sentiment Treebank(SST)数据集上训练一个随机森林。该数据集的目标是将句子分类为positive或negative情感。您将使用在TensorFlow Datasets中精选的二分类版本的数据集。
注意: 训练categorical-set特征可能会很昂贵。在这本文中,我们将训练一个包含20棵树的小型随机森林。
# 安装 TensorFlow Datasets 包
!pip install tensorflow-datasets -U --quiet
# 导入tensorflow_datasets库
import tensorflow_datasets as tfds
# 加载数据集
all_ds = tfds.load("glue/sst2")
# 显示测试集中的前3个样例
for example in all_ds["test"].take(3):
# 打印每个样例的属性名和属性值
print({attr_name: attr_tensor.numpy() for attr_name, attr_tensor in example.items()})
{'idx': 163, 'label': -1, 'sentence': b'not even the hanson brothers can save it'}
{'idx': 131, 'label': -1, 'sentence': b'strong setup and ambitious goals fade as the film descends into unsophisticated scare tactics and b-film thuggery .'}
{'idx': 1579, 'label': -1, 'sentence': b'too timid to bring a sense of closure to an ugly chapter of the twentieth century .'}
2023-11-20 12:31:28.022927: W tensorflow/core/kernels/data/cache_dataset_ops.cc:858] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead.
数据集的修改如下:
- 原始标签是整数
{-1, 1},但学习算法期望的是正整数标签,例如{0, 1}。因此,标签的转换如下:new_labels = (original_labels + 1) / 2。 - 为了使数据集的读取更加高效,应用了批量大小为64。
sentence属性需要进行分词,即"hello world" -> ["hello", "world"]。
注意: 此示例不使用数据集的test拆分,因为它没有标签。如果test拆分有标签,可以将validation折叠连接到train中(例如all_ds["train"].concatenate(all_ds["validation"]))。
细节: 某些决策森林学习算法不需要验证数据集(例如随机森林),而其他一些算法则需要(例如某些情况下的梯度提升树)。由于TF-DF下的每个学习算法可以以不同的方式使用验证数据,TF-DF在内部处理训练/验证拆分。因此,当您有训练和验证集时,它们可以始终作为学习算法的输入进行连接。
# 定义函数prepare_dataset,用于处理数据集
# 参数example为输入的样本数据
def prepare_dataset(example):
# 将label加1后除以2,得到标签值
label = (example["label"] + 1) // 2
# 将句子按空格进行分割,并返回分割后的结果作为"sentence"键的值
return {"sentence" : tf.strings.split(example["sentence"])}, label
# 将训练数据集all_ds中的"train"部分进行批处理,每批100个样本,并使用prepare_dataset函数进行处理
train_ds = all_ds["train"].batch(100).map(prepare_dataset)
# 将验证数据集all_ds中的"validation"部分进行批处理,每批100个样本,并使用prepare_dataset函数进行处理
test_ds = all_ds["validation"].batch(100).map(prepare_dataset)
最后,像往常一样训练和评估模型。TF-DF会自动将多值分类特征识别为分类集合。
# 设置单元格高度为300
%set_cell_height 300
# 指定模型为随机森林模型,使用30棵树,verbose参数为2表示输出训练过程中的详细信息
model_1 = tfdf.keras.RandomForestModel(num_trees=30, verbose=2)
# 训练模型,使用train_ds作为训练数据集
model_1.fit(x=train_ds)
<IPython.core.display.Javascript object>
Warning: The `num_threads` constructor argument is not set and the number of CPU is os.cpu_count()=32 > 32. Setting num_threads to 32. Set num_threads manually to use more than 32 cpus.
WARNING:absl:The `num_threads` constructor argument is not set and the number of CPU is os.cpu_count()=32 > 32. Setting num_threads to 32. Set num_threads manually to use more than 32 cpus.
Use /tmpfs/tmp/tmpp9alip3z as temporary training directory
Reading training dataset...
Training tensor examples:
Features: {'sentence': tf.RaggedTensor(values=Tensor("data:0", shape=(None,), dtype=string), row_splits=Tensor("data_1:0", shape=(None,), dtype=int64))}
Label: Tensor("data_2:0", shape=(None,), dtype=int64)
Weights: None
Normalized tensor features:
{'sentence': SemanticTensor(semantic=<Semantic.CATEGORICAL_SET: 4>, tensor=tf.RaggedTensor(values=Tensor("data:0", shape=(None,), dtype=string), row_splits=Tensor("data_1:0", shape=(None,), dtype=int64)))}
Training dataset read in 0:00:04.588912. Found 67349 examples.
Training model...
Standard output detected as not visible to the user e.g. running in a notebook. Creating a training log redirection. If training gets stuck, try calling tfdf.keras.set_training_logs_redirection(False).
[INFO 23-11-20 12:31:32.7845 UTC kernel.cc:771] Start Yggdrasil model training
[INFO 23-11-20 12:31:32.7845 UTC kernel.cc:772] Collect training examples
[INFO 23-11-20 12:31:32.7846 UTC kernel.cc:785] Dataspec guide:
column_guides {
column_name_pattern: "^__LABEL$"
type: CATEGORICAL
categorial {
min_vocab_frequency: 0
max_vocab_count: -1
}
}
default_column_guide {
categorial {
max_vocab_count: 2000
}
discretized_numerical {
maximum_num_bins: 255
}
}
ignore_columns_without_guides: false
detect_numerical_as_discretized_numerical: false
[INFO 23-11-20 12:31:32.7849 UTC kernel.cc:391] Number of batches: 674
[INFO 23-11-20 12:31:32.7849 UTC kernel.cc:392] Number of examples: 67349
[INFO 23-11-20 12:31:32.8290 UTC data_spec_inference.cc:305] 12816 item(s) have been pruned (i.e. they are considered out of dictionary) for the column sentence (2000 item(s) left) because min_value_count=5 and max_number_of_unique_values=2000
[INFO 23-11-20 12:31:32.8820 UTC kernel.cc:792] Training dataset:
Number of records: 67349
Number of columns: 2
Number of columns by type:
CATEGORICAL_SET: 1 (50%)
CATEGORICAL: 1 (50%)
Columns:
CATEGORICAL_SET: 1 (50%)
1: "sentence" CATEGORICAL_SET has-dict vocab-size:2001 num-oods:10187 (15.1257%) most-frequent:"the" 27205 (40.3941%)
CATEGORICAL: 1 (50%)
0: "__LABEL" CATEGORICAL integerized vocab-size:3 no-ood-item
Terminology:
nas: Number of non-available (i.e. missing) values.
ood: Out of dictionary.
manually-defined: Attribute whose type is manually defined by the user, i.e., the type was not automatically inferred.
tokenized: The attribute value is obtained through tokenization.
has-dict: The attribute is attached to a string dictionary e.g. a categorical attribute stored as a string.
vocab-size: Number of unique values.
[INFO 23-11-20 12:31:32.8821 UTC kernel.cc:808] Configure learner
[INFO 23-11-20 12:31:32.8823 UTC kernel.cc:822] Training config:
learner: "RANDOM_FOREST"
features: "^sentence$"
label: "^__LABEL$"
task: CLASSIFICATION
random_seed: 123456
metadata {
framework: "TF Keras"
}
pure_serving_model: false
[yggdrasil_decision_forests.model.random_forest.proto.random_forest_config] {
num_trees: 30
decision_tree {
max_depth: 16
min_examples: 5
in_split_min_examples_check: true
keep_non_leaf_label_distribution: true
num_candidate_attributes: 0
missing_value_policy: GLOBAL_IMPUTATION
allow_na_conditions: false
categorical_set_greedy_forward {
sampling: 0.1
max_num_items: -1
min_item_frequency: 1
}
growing_strategy_local {
}
categorical {
cart {
}
}
axis_aligned_split {
}
internal {
sorting_strategy: PRESORTED
}
uplift {
min_examples_in_treatment: 5
split_score: KULLBACK_LEIBLER
}
}
winner_take_all_inference: true
compute_oob_performances: true
compute_oob_variable_importances: false
num_oob_variable_importances_permutations: 1
bootstrap_training_dataset: true
bootstrap_size_ratio: 1
adapt_bootstrap_size_ratio_for_maximum_training_duration: false
sampling_with_replacement: true
}
[INFO 23-11-20 12:31:32.8826 UTC kernel.cc:825] Deployment config:
cache_path: "/tmpfs/tmp/tmpp9alip3z/working_cache"
num_threads: 32
try_resume_training: true
[INFO 23-11-20 12:31:32.8828 UTC kernel.cc:887] Train model
[INFO 23-11-20 12:31:32.8836 UTC random_forest.cc:416] Training random forest on 67349 example(s) and 1 feature(s).
[INFO 23-11-20 12:32:02.2437 UTC random_forest.cc:802] Training of tree 1/30 (tree index:13) done accuracy:0.738731 logloss:9.4171
[INFO 23-11-20 12:32:12.3428 UTC random_forest.cc:802] Training of tree 3/30 (tree index:27) done accuracy:0.754745 logloss:6.47525
[INFO 23-11-20 12:32:17.6546 UTC random_forest.cc:802] Training of tree 13/30 (tree index:20) done accuracy:0.801813 logloss:2.334
[INFO 23-11-20 12:32:18.5584 UTC random_forest.cc:802] Training of tree 23/30 (tree index:15) done accuracy:0.81742 logloss:0.942096
[INFO 23-11-20 12:32:21.9457 UTC random_forest.cc:802] Training of tree 30/30 (tree index:21) done accuracy:0.821274 logloss:0.854486
[INFO 23-11-20 12:32:21.9462 UTC random_forest.cc:882] Final OOB metrics: accuracy:0.821274 logloss:0.854486
[INFO 23-11-20 12:32:21.9558 UTC kernel.cc:919] Export model in log directory: /tmpfs/tmp/tmpp9alip3z with prefix d2f2a624a65443d5
[INFO 23-11-20 12:32:21.9870 UTC kernel.cc:937] Save model in resources
[INFO 23-11-20 12:32:21.9901 UTC abstract_model.cc:881] Model self evaluation:
Number of predictions (without weights): 67349
Number of predictions (with weights): 67349
Task: CLASSIFICATION
Label: __LABEL
Accuracy: 0.821274 CI95[W][0.818828 0.8237]
LogLoss: : 0.854486
ErrorRate: : 0.178726
Default Accuracy: : 0.557826
Default LogLoss: : 0.686445
Default ErrorRate: : 0.442174
Confusion Table:
truth\prediction
1 2
1 19593 10187
2 1850 35719
Total: 67349
[INFO 23-11-20 12:32:22.0155 UTC kernel.cc:1233] Loading model from path /tmpfs/tmp/tmpp9alip3z/model/ with prefix d2f2a624a65443d5
[INFO 23-11-20 12:32:22.3248 UTC decision_forest.cc:660] Model loaded with 30 root(s), 43180 node(s), and 1 input feature(s).
[INFO 23-11-20 12:32:22.3249 UTC abstract_model.cc:1344] Engine "RandomForestGeneric" built
[INFO 23-11-20 12:32:22.3249 UTC kernel.cc:1061] Use fast generic engine
Model trained in 0:00:49.561739
Compiling model...
Model compiled.
<keras.src.callbacks.History at 0x7fd79650ec70>
在之前的日志中,注意到 sentence 是一个 CATEGORICAL_SET 特征。
模型的评估与往常一样:
# 对模型进行编译,指定评估指标为准确率
model_1.compile(metrics=["accuracy"])
# 对测试数据集进行评估,返回损失值和准确率
evaluation = model_1.evaluate(test_ds)
# 打印二元交叉熵损失值
print(f"BinaryCrossentropyloss: {evaluation[0]}")
# 打印准确率
print(f"Accuracy: {evaluation[1]}")
1/9 [==>...........................] - ETA: 4s - loss: 0.0000e+00 - accuracy: 0.8100
9/9 [==============================] - 1s 5ms/step - loss: 0.0000e+00 - accuracy: 0.7638
BinaryCrossentropyloss: 0.0
Accuracy: 0.7637614607810974
训练日志如下所示:
# 导入matplotlib.pyplot模块,用于绘制图表
import matplotlib.pyplot as plt
# 获取模型的训练日志
logs = model_1.make_inspector().training_logs()
# 绘制折线图,横坐标为日志中的树的数量,纵坐标为日志中的评估准确率
plt.plot([log.num_trees for log in logs], [log.evaluation.accuracy for log in logs])
# 设置横坐标的标签为"Number of trees"
plt.xlabel("Number of trees")
# 设置纵坐标的标签为"Out-of-bag accuracy"
plt.ylabel("Out-of-bag accuracy")
# 保持图表的原样,不做任何处理
pass
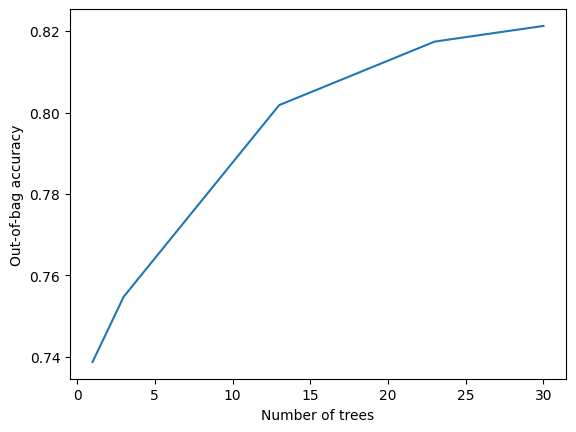
更多的树可能会有益处(我确定,因为我试过:p)。
使用预训练的文本嵌入
前面的例子使用原始文本特征训练了一个随机森林模型。这个例子将使用一个预训练的TF-Hub嵌入将文本特征转换为密集嵌入,并在其上训练一个随机森林模型。在这种情况下,随机森林模型只会“看到”嵌入的数值输出(即它不会看到原始文本)。
在这个实验中,我们将使用Universal-Sentence-Encoder。不同的预训练嵌入可能适用于不同类型的文本(例如不同的语言、不同的任务),也适用于其他类型的结构化特征(例如图像)。
**注意:**这个嵌入模块很大(1GB),因此最终模型的运行速度会比传统的决策树推断慢。
嵌入模块可以应用在两个地方:
- 在数据集准备阶段。
- 在模型的预处理阶段。
通常情况下,第二个选项更可取:将嵌入打包到模型中使得模型更容易使用(也更难被误用)。
首先安装TF-Hub:
# 安装tensorflow-hub库的最新版本
!pip install --upgrade tensorflow-hub
Requirement already satisfied: tensorflow-hub in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (0.15.0)
Requirement already satisfied: numpy>=1.12.0 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from tensorflow-hub) (1.26.2)
Requirement already satisfied: protobuf>=3.19.6 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from tensorflow-hub) (3.20.3)
与以前不同的是,您不需要对文本进行分词。
# 定义函数prepare_dataset,输入参数为example
def prepare_dataset(example):
# 将label加1后除以2,得到label的值
label = (example["label"] + 1) // 2
# 返回一个字典,键为"sentence",值为example中的"sentence"对应的值,以及label的值
return {"sentence" : example["sentence"]}, label
# 将all_ds中的"train"数据集按照batch size为100进行分批,并对每个batch应用prepare_dataset函数进行处理,得到train_ds数据集
train_ds = all_ds["train"].batch(100).map(prepare_dataset)
# 将all_ds中的"validation"数据集按照batch size为100进行分批,并对每个batch应用prepare_dataset函数进行处理,得到test_ds数据集
test_ds = all_ds["validation"].batch(100).map(prepare_dataset)
%set_cell_height 300
# 导入tensorflow_hub模块
import tensorflow_hub as hub
# 定义使用的模型为Universal Sentence Encoder,版本为4
hub_url = "https://tfhub.dev/google/universal-sentence-encoder/4"
# 将模型转换为Keras层
embedding = hub.KerasLayer(hub_url)
# 定义输入层,输入为字符串类型的句子
sentence = tf.keras.layers.Input(shape=(), name="sentence", dtype=tf.string)
# 将句子转换为嵌入向量
embedded_sentence = embedding(sentence)
# 定义原始输入为句子,处理后的输入为嵌入向量
raw_inputs = {"sentence": sentence}
processed_inputs = {"embedded_sentence": embedded_sentence}
# 定义预处理模型,将原始输入转换为处理后的输入
preprocessor = tf.keras.Model(inputs=raw_inputs, outputs=processed_inputs)
# 定义随机森林模型,使用预处理模型进行数据预处理,树的数量为100
model_2 = tfdf.keras.RandomForestModel(
preprocessing=preprocessor,
num_trees=100)
# 使用训练数据进行模型训练
model_2.fit(x=train_ds)
<IPython.core.display.Javascript object>
Warning: The `num_threads` constructor argument is not set and the number of CPU is os.cpu_count()=32 > 32. Setting num_threads to 32. Set num_threads manually to use more than 32 cpus.
WARNING:absl:The `num_threads` constructor argument is not set and the number of CPU is os.cpu_count()=32 > 32. Setting num_threads to 32. Set num_threads manually to use more than 32 cpus.
Use /tmpfs/tmp/tmp2l8qenh8 as temporary training directory
Reading training dataset...
Training dataset read in 0:00:22.682140. Found 67349 examples.
Training model...
[INFO 23-11-20 12:33:16.6995 UTC kernel.cc:1233] Loading model from path /tmpfs/tmp/tmp2l8qenh8/model/ with prefix a883bbf674954d64
Model trained in 0:00:14.090027
Compiling model...
[INFO 23-11-20 12:33:18.4993 UTC decision_forest.cc:660] Model loaded with 100 root(s), 563552 node(s), and 512 input feature(s).
[INFO 23-11-20 12:33:18.4994 UTC abstract_model.cc:1344] Engine "RandomForestOptPred" built
[INFO 23-11-20 12:33:18.4996 UTC kernel.cc:1061] Use fast generic engine
Model compiled.
<keras.src.callbacks.History at 0x7fd690629e50>
# 编译模型
model_2.compile(metrics=["accuracy"])
# 评估模型
evaluation = model_2.evaluate(test_ds)
# 打印二元交叉熵损失
print(f"BinaryCrossentropyloss: {evaluation[0]}")
# 打印准确率
print(f"Accuracy: {evaluation[1]}")
1/9 [==>...........................] - ETA: 13s - loss: 0.0000e+00 - accuracy: 0.7800
4/9 [============>.................] - ETA: 0s - loss: 0.0000e+00 - accuracy: 0.8075
7/9 [======================>.......] - ETA: 0s - loss: 0.0000e+00 - accuracy: 0.7886
9/9 [==============================] - 2s 18ms/step - loss: 0.0000e+00 - accuracy: 0.7798
BinaryCrossentropyloss: 0.0
Accuracy: 0.7798165082931519
注意,分类集合与密集嵌入在表示文本时有所不同,因此同时使用这两种策略可能会很有用。
同时训练决策树和神经网络
前面的例子使用了一个预训练的神经网络(NN)来处理文本特征,然后将它们传递给随机森林。这个例子将从头开始训练神经网络和随机森林。
TF-DF的决策森林不会反向传播梯度(尽管这是正在进行的研究的主题)。因此,训练分为两个阶段:
- 将神经网络作为标准分类任务进行训练:
示例 → [归一化] → [神经网络*] → [分类头] → 预测
*: 训练。
- 用随机森林替换神经网络的头(最后一层和软最大值)。像往常一样训练随机森林:
示例 → [归一化] → [神经网络] → [随机森林*] → 预测
*: 训练。
### 准备数据集
本示例使用[Palmer's Penguins](https://allisonhorst.github.io/palmerpenguins/articles/intro.html)数据集。有关详细信息,请参阅[初学者colab](beginner_colab.ipynb)。
首先,下载原始数据:
```python
# 下载penguins.csv文件并保存到指定路径/tmp/penguins.csv
!wget -q https://storage.googleapis.com/download.tensorflow.org/data/palmer_penguins/penguins.csv -O /tmp/penguins.csv
将数据集加载到Pandas Dataframe中
# 读取csv文件,将数据存储在dataset_df中
dataset_df = pd.read_csv("/tmp/penguins.csv")
# 显示dataset_df中前3个样本的数据
dataset_df.head(3)
| species | island | bill_length_mm | bill_depth_mm | flipper_length_mm | body_mass_g | sex | year | |
|---|---|---|---|---|---|---|---|---|
| 0 | Adelie | Torgersen | 39.1 | 18.7 | 181.0 | 3750.0 | male | 2007 |
| 1 | Adelie | Torgersen | 39.5 | 17.4 | 186.0 | 3800.0 | female | 2007 |
| 2 | Adelie | Torgersen | 40.3 | 18.0 | 195.0 | 3250.0 | female | 2007 |
准备训练数据集。
# 设置标签为"species"
label = "species"
# 将数据集中的数值NaN(表示Pandas Dataframe中的缺失值)替换为0。
# ...神经网络对数值NaN的处理效果不好。
for col in dataset_df.columns:
# 如果数据集中的列的数据类型不是字符串或对象类型
if dataset_df[col].dtype not in [str, object]:
# 将该列中的NaN值替换为0
dataset_df[col] = dataset_df[col].fillna(0)
# 将数据集拆分为训练集和测试集
def split_dataset(dataset, test_ratio=0.30):
"""将panda dataframe拆分为两个部分。"""
# 生成一个与数据集长度相同的随机数组,元素值小于测试比例的为True,大于等于测试比例的为False
test_indices = np.random.rand(len(dataset)) < test_ratio
# 返回训练集和测试集
return dataset[~test_indices], dataset[test_indices]
# 调用split_dataset函数将数据集拆分为训练集和测试集
train_ds_pd, test_ds_pd = split_dataset(dataset_df)
# 打印训练集和测试集的样本数量
print("{} 个样本用于训练,{} 个样本用于测试。".format(
len(train_ds_pd), len(test_ds_pd)))
# 将数据集转换为tensorflow数据集
train_ds = tfdf.keras.pd_dataframe_to_tf_dataset(train_ds_pd, label=label)
test_ds = tfdf.keras.pd_dataframe_to_tf_dataset(test_ds_pd, label=label)
248 examples in training, 96 examples for testing.
构建模型
接下来,使用Keras的函数式风格创建神经网络模型。
为了保持示例简单,该模型仅使用两个输入。
# 创建两个输入层
input_1 = tf.keras.Input(shape=(1,), name="bill_length_mm", dtype="float") # 输入层1,表示企鹅嘴峰的长度,数据类型为浮点数
input_2 = tf.keras.Input(shape=(1,), name="island", dtype="string") # 输入层2,表示企鹅所在的岛屿,数据类型为字符串
# 将两个输入层组合成一个列表
nn_raw_inputs = [input_1, input_2] # 输入层列表,包含两个输入层
使用预处理层将原始输入转换为适合神经网络的输入。
# 正则化
Normalization = tf.keras.layers.Normalization
CategoryEncoding = tf.keras.layers.CategoryEncoding
StringLookup = tf.keras.layers.StringLookup
# 获取"bill_length_mm"列的值,并将其转换为二维数组
values = train_ds_pd["bill_length_mm"].values[:, tf.newaxis]
# 创建Normalization层实例
input_1_normalizer = Normalization()
# 对输入数据进行适应,计算均值和方差
input_1_normalizer.adapt(values)
# 获取"island"列的值
values = train_ds_pd["island"].values
# 创建StringLookup层实例,将字符串转换为整数索引
input_2_indexer = StringLookup(max_tokens=32)
# 对输入数据进行适应,构建索引映射关系
input_2_indexer.adapt(values)
# 创建CategoryEncoding层实例,将整数索引转换为二进制编码
input_2_onehot = CategoryEncoding(output_mode="binary", max_tokens=32)
# 对输入数据进行正则化处理
normalized_input_1 = input_1_normalizer(input_1)
# 将输入数据转换为整数索引,并进行二进制编码
normalized_input_2 = input_2_onehot(input_2_indexer(input_2))
# 组合处理后的输入数据
nn_processed_inputs = [normalized_input_1, normalized_input_2]
WARNING:tensorflow:max_tokens is deprecated, please use num_tokens instead.
WARNING:tensorflow:max_tokens is deprecated, please use num_tokens instead.
构建神经网络的主体部分:
# 创建一个Concatenate层,用于将nn_processed_inputs中的张量连接起来
y = tf.keras.layers.Concatenate()(nn_processed_inputs)
# 创建一个Dense层,输出维度为16,激活函数为relu6
y = tf.keras.layers.Dense(16, activation=tf.nn.relu6)(y)
# 创建一个Dense层,输出维度为8,激活函数为relu,命名为"last"
last_layer = tf.keras.layers.Dense(8, activation=tf.nn.relu, name="last")(y)
# 创建一个Dense层,输出维度为3,用于分类任务
classification_output = tf.keras.layers.Dense(3)(y)
# 创建一个模型,输入为nn_raw_inputs,输出为classification_output
nn_model = tf.keras.models.Model(nn_raw_inputs, classification_output)
这个 nn_model 直接产生分类的 logits。
接下来创建一个决策森林模型。它将在神经网络在分类头之前提取的高级特征上操作。
# 将神经网络模型去掉输出层,得到nn_without_head模型
# 将神经网络模型和决策森林模型组合成一个keras模型,即df_and_nn_model
nn_without_head = tf.keras.models.Model(inputs=nn_model.inputs, outputs=last_layer)
df_and_nn_model = tfdf.keras.RandomForestModel(preprocessing=nn_without_head)
Warning: The `num_threads` constructor argument is not set and the number of CPU is os.cpu_count()=32 > 32. Setting num_threads to 32. Set num_threads manually to use more than 32 cpus.
WARNING:absl:The `num_threads` constructor argument is not set and the number of CPU is os.cpu_count()=32 > 32. Setting num_threads to 32. Set num_threads manually to use more than 32 cpus.
Use /tmpfs/tmp/tmpzwv9a980 as temporary training directory
训练和评估模型
该模型将分为两个阶段进行训练。首先,使用自己的分类头训练神经网络:
# 设置单元格高度为300
# 编译神经网络模型
nn_model.compile(
optimizer=tf.keras.optimizers.Adam(), # 使用Adam优化器
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True), # 使用稀疏分类交叉熵损失函数
metrics=["accuracy"] # 评估指标为准确率
)
# 使用训练数据集进行训练,并使用测试数据集进行验证,训练10个epochs
nn_model.fit(x=train_ds, validation_data=test_ds, epochs=10)
# 打印神经网络模型的概要信息
nn_model.summary()
<IPython.core.display.Javascript object>
Epoch 1/10
/tmpfs/src/tf_docs_env/lib/python3.9/site-packages/keras/src/engine/functional.py:642: UserWarning: Input dict contained keys ['bill_depth_mm', 'flipper_length_mm', 'body_mass_g', 'sex', 'year'] which did not match any model input. They will be ignored by the model.
inputs = self._flatten_to_reference_inputs(inputs)
WARNING: All log messages before absl::InitializeLog() is called are written to STDERR
I0000 00:00:1700483606.110085 457876 device_compiler.h:186] Compiled cluster using XLA! This line is logged at most once for the lifetime of the process.
1/1 [==============================] - ETA: 0s - loss: 1.4043 - accuracy: 0.0161
1/1 [==============================] - 2s 2s/step - loss: 1.4043 - accuracy: 0.0161 - val_loss: 1.3502 - val_accuracy: 0.0208
Epoch 2/10
1/1 [==============================] - ETA: 0s - loss: 1.3963 - accuracy: 0.0161
1/1 [==============================] - 0s 21ms/step - loss: 1.3963 - accuracy: 0.0161 - val_loss: 1.3436 - val_accuracy: 0.0208
Epoch 3/10
1/1 [==============================] - ETA: 0s - loss: 1.3885 - accuracy: 0.0161
1/1 [==============================] - 0s 21ms/step - loss: 1.3885 - accuracy: 0.0161 - val_loss: 1.3371 - val_accuracy: 0.0208
Epoch 4/10
1/1 [==============================] - ETA: 0s - loss: 1.3809 - accuracy: 0.0161
1/1 [==============================] - 0s 21ms/step - loss: 1.3809 - accuracy: 0.0161 - val_loss: 1.3305 - val_accuracy: 0.0208
Epoch 5/10
1/1 [==============================] - ETA: 0s - loss: 1.3733 - accuracy: 0.0161
1/1 [==============================] - 0s 21ms/step - loss: 1.3733 - accuracy: 0.0161 - val_loss: 1.3241 - val_accuracy: 0.0208
Epoch 6/10
1/1 [==============================] - ETA: 0s - loss: 1.3658 - accuracy: 0.0161
1/1 [==============================] - 0s 20ms/step - loss: 1.3658 - accuracy: 0.0161 - val_loss: 1.3177 - val_accuracy: 0.0208
Epoch 7/10
1/1 [==============================] - ETA: 0s - loss: 1.3584 - accuracy: 0.0161
1/1 [==============================] - 0s 20ms/step - loss: 1.3584 - accuracy: 0.0161 - val_loss: 1.3113 - val_accuracy: 0.0208
Epoch 8/10
1/1 [==============================] - ETA: 0s - loss: 1.3511 - accuracy: 0.0081
1/1 [==============================] - 0s 20ms/step - loss: 1.3511 - accuracy: 0.0081 - val_loss: 1.3050 - val_accuracy: 0.0208
Epoch 9/10
1/1 [==============================] - ETA: 0s - loss: 1.3440 - accuracy: 0.0081
1/1 [==============================] - 0s 21ms/step - loss: 1.3440 - accuracy: 0.0081 - val_loss: 1.2988 - val_accuracy: 0.0208
Epoch 10/10
1/1 [==============================] - ETA: 0s - loss: 1.3369 - accuracy: 0.0121
1/1 [==============================] - 0s 21ms/step - loss: 1.3369 - accuracy: 0.0121 - val_loss: 1.2927 - val_accuracy: 0.0312
Model: "model_1"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
island (InputLayer) [(None, 1)] 0 []
bill_length_mm (InputLayer [(None, 1)] 0 []
)
string_lookup (StringLooku (None, 1) 0 ['island[0][0]']
p)
normalization (Normalizati (None, 1) 3 ['bill_length_mm[0][0]']
on)
category_encoding (Categor (None, 32) 0 ['string_lookup[0][0]']
yEncoding)
concatenate (Concatenate) (None, 33) 0 ['normalization[0][0]',
'category_encoding[0][0]']
dense (Dense) (None, 16) 544 ['concatenate[0][0]']
dense_1 (Dense) (None, 3) 51 ['dense[0][0]']
==================================================================================================
Total params: 598 (2.34 KB)
Trainable params: 595 (2.32 KB)
Non-trainable params: 3 (16.00 Byte)
__________________________________________________________________________________________________
神经网络层在两个模型之间共享。因此,现在神经网络已经训练好了,决策森林模型将适应于神经网络层的训练输出。
# 使用df_and_nn_model模型对训练数据集train_ds进行拟合
df_and_nn_model.fit(x=train_ds)
<IPython.core.display.Javascript object>
Reading training dataset...
Training dataset read in 0:00:00.293304. Found 248 examples.
Training model...
Model trained in 0:00:00.045032
Compiling model...
Model compiled.
[INFO 23-11-20 12:33:27.2559 UTC kernel.cc:1233] Loading model from path /tmpfs/tmp/tmpzwv9a980/model/ with prefix 3397b294ee2f42a4
[INFO 23-11-20 12:33:27.2721 UTC decision_forest.cc:660] Model loaded with 300 root(s), 5280 node(s), and 7 input feature(s).
[INFO 23-11-20 12:33:27.2721 UTC kernel.cc:1061] Use fast generic engine
<keras.src.callbacks.History at 0x7fd6a07d5ac0>
现在评估组合模型:
# 编译模型
df_and_nn_model.compile(metrics=["accuracy"])
# 打印模型评估结果
print("Evaluation:", df_and_nn_model.evaluate(test_ds))
1/1 [==============================] - ETA: 0s - loss: 0.0000e+00 - accuracy: 0.9479
1/1 [==============================] - 0s 162ms/step - loss: 0.0000e+00 - accuracy: 0.9479
Evaluation: [0.0, 0.9479166865348816]
与仅使用神经网络相比:
# 打印输出 "Evaluation :",并调用神经网络模型的 evaluate 方法对测试数据集进行评估
print("Evaluation :", nn_model.evaluate(test_ds))
1/1 [==============================] - ETA: 0s - loss: 1.2927 - accuracy: 0.0312
1/1 [==============================] - 0s 13ms/step - loss: 1.2927 - accuracy: 0.0312
Evaluation : [1.2926578521728516, 0.03125]