今日to do list:
- 做kaggle上面的流量预测项目☠️
- 学习时不刷手机🤡
okkkkkkkkkkkkkk
开始👍🍎

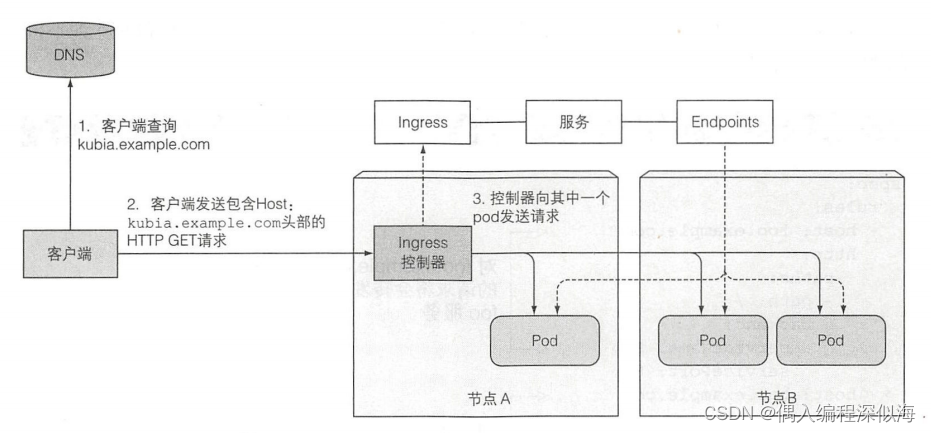
0、我在干什么?
我在预测一个名字叫做elborn基站的下行链路流量,用过去29天的数据预测未来10天的数据
1、import libararies
一般必须都要导入的库有
- import pandas as pd : data processing, like pd.read.csv…
- import numpy as np :线性代数
- import matplotlib.pyplot as plt :画图
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import numpy as np # linear algebra
import warnings
warnings.filterwarnings('ignore') # 忽略警告信息
import matplotlib.pyplot as plt
2、加载数据load data
对csv数据使用pandas.read_csv函数读取
一些参数:
- filepath_or_buffer: 文件路径或缓冲区。可以是本地文件路径,也可以是文件对象、URL等
- header: 列名索引。指定数据文件中列名的索引。默认为None,表示没有列名。取值可以是整数,表示第几行为列名;也可以是None,表示自动检测列名;还可以是列表,表示指定列名的位置。
- na_values: 缺失值。指定用于替换缺失值的字符或列表。默认为[‘NA’, ‘null’, ‘NaN’]。
- index_col: 索引列。指定数据文件中用于索引的列。默认为None,表示没有索引列。取值可以是整数,表示第几列用于索引;也可以是列名,表示指定列用于索引。
- sep: 分隔符。用于分隔数据行的字段。默认为逗号,。
- delimiter: 分隔符。与sep类似,但它是更通用的参数,可以用于其他类型的分隔符,如制表符\t等。
elborn_df = pd.read_csv('dataset/ElBorn.csv')
elborn_test_df = pd.read_csv('dataset/ElBorn_test.csv')
3、独家观察数据函数 💓
💥basic_eda💥
- 前五行
- 显示DataFrame的详细信息,包括列名、数据类型、缺失值
- 显示DataFrame的统计摘要信息,包括每列的平均值、标准差、最小值、最大值等
- 显示列名
- 各列的数据类型
- 是否有缺失值
- 是否有NULL值
- 数据的形状
def basic_eda(df):
print("-------------------------------TOP 5 RECORDS-----------------------------")
print(df.head(5))
print("-------------------------------INFO--------------------------------------")
print(df.info())
print("-------------------------------Describe----------------------------------")
print(df.describe())
print("-------------------------------Columns-----------------------------------")
print(df.columns)
print("-------------------------------Data Types--------------------------------")
print(df.dtypes)
print("----------------------------Missing Values-------------------------------")
print(df.isnull().sum())
print("----------------------------NULL values----------------------------------")
print(df.isna().sum())
print("--------------------------Shape Of Data---------------------------------")
print(df.shape)
print("============================================================================ \n")
basic_eda(elborn_df)
basic_eda(elborn_test_df)
然后画图看一下💥
# 我现在想把elborn_df画出来,横坐标是时间,纵坐标是down,并且横坐标的标签要旋转45度书写
plt.plot(elborn_df.index, elborn_df.down)
plt.xlabel('Time')
plt.ylabel('Down')
plt.title('Down')
# 我想把横坐标的日期标签旋转45
plt.xticks(rotation=45)

在这里面的Python小知识总结(纯小白哈🌸)
- DataFrame.index:将得到DataFrame的索引(日期),作为Series对象
- 如果DataFrame的index是整数,则返回一个从0开始的整数序列
- 0 0
1 1
2 2
3 3
4 4
5 5
6 6
7 7
8 8
9 9
Name: index, dtype: int64
- plt.plot():绘制折线的基本函数
以下是一些参数- x: x轴数据,可以是列表、元组、NumPy数组等。
- y: y轴数据,可以是列表、元组、NumPy数组等。
- fmt: 折线图的样式和颜色。
- 例如,'ro-'表示红色圆圈加短横线,
- 'b–'表示蓝色虚线。
- label:为折线图添加一个标签,可以在plt.legend()函数中使用该标签(用于显示图例)。
- linewidth: 折线图的宽度。
- color: 折线图的颜色。
- marker: 折线图的标记形状,例如圆圈、叉号等。
- markeredgecolor: 标记的边缘颜色。
- markerfacecolor: 标记的填充颜色。
- markevery: 标记的间隔,例如每隔10个数据点标记一次。
- plt.xticks(rotation=45):设置x轴刻度标签的位置和显示方式
4、数据预处理pre-processing
(1)将时间戳转换为一个日期时间索引
elborn_df.set_index(pd.DatetimeIndex(elborn_df["time"]), inplace=True)
elborn_df.drop(["time"], axis=1, inplace=True)
(2)填充所有缺失的值
不填充的话后续fit模型的时候会出现loss全部为NAN的情况
elborn_df.down.fillna(elborn_df.down.mean(), inplace=True)
print(elborn_df.isna().sum())
(3)将时间序列数据转换成监督学习数据
在训练监督学习(深度学习)模型前,要把time series数据转化成samples的形式
那什么是sample?有一个输入组件
X
X
X和一个输出组件
y
y
y
深度学习模型就是一个映射函数:
y
=
f
(
X
)
y=f(X)
y=f(X)
对于一个单变量的one-step预测:输入组件就是前一个时间步的滞后数据,输出组件就是当前时间步的数据,如下:
X, y
[1, 2, 3], [4]
[2, 3, 4], [5]
[3, 4, 5], [6]
…
这里就是手动转换啦,之前写过使用TimeseriesGenerator自动转换的方法,看看对比
手动转换
def series_to_supervised(data, window=3, lag=1, dropnan=True):
cols, names = list(), list()
# Input sequence (t-n, ... t-1)
for i in range(window, 0, -1):
cols.append(data.shift(i))
names += [('%s(t-%d)' % (col, i)) for col in data.columns]
# Current timestep (t=0)
cols.append(data)
names += [('%s(t)' % (col)) for col in data.columns]
# Target timestep (t=lag)
cols.append(data.shift(-lag))
names += [('%s(t+%d)' % (col, lag)) for col in data.columns]
# Put it all together
agg = pd.concat(cols, axis=1)
agg.columns = names
return agg
window =29
lag = 10
elborn_df_supervised = series_to_supervised(elborn_df, window, lag)
(4)数据集划分(split)为训练集和验证集
-
训练集和测试集的区别
- 使用验证集是为了快速调参,也就是用验证集选择超参数(网络层数,网络节点数,迭代次数,学习率这些)。另外用验证集还可以监控模型是否异常(过拟合啦什么的),然后决定是不是要提前停止训练。
- 验证集的关键在于选择超参数,我们手动调参是为了让模型在验证集上的表现越来越好,如果把测试集作为验证集,调参去拟合测试集,就有点像作弊了。
- 而测试集既不参与参数的学习过程,也不参与参数的选择过程,仅仅用于模型评价。
-
训练集在建模过程中会被大量经常使用,验证集用于对模型少量偶尔的调整,而测试集只作为最终模型的评价出现,因此训练集,验证集和测试集所需的数据量也是不一致的,在数据量不是特别大的情况下一般遵循6:2:2的划分比例
-
为了使模型“训练”效果能合理泛化至“测试”效果,从而推广应用至现实世界中,因此一般要求训练集,验证集和测试集数据分布近似。但需要注意,三个数据集所用数据是不同的。
from sklearn.model_selection import train_test_split
label_name = 'down(t+%d)' % (lag)
label = elborn_df_supervised[label_name]
elborn_df_supervised = elborn_df_supervised.drop(label_name, axis=1)
X_train, X_valid, Y_train, Y_valid = train_test_split(elborn_df_supervised, label, test_size=0.4, random_state=0)
print('Train set shape', X_train.shape)
print('Validation set shape', X_valid.shape)
4、创建MLP模型
(1)设置超参数
epochs = 40
batch = 256
lr = 0.0003
adam = optimizers.Adam(lr)
(2)创建模型(keras)
model_mlp = Sequential()
model_mlp.add(Dense(100, activation='relu', input_dim=X_train.shape[1]))
model_mlp.add(Dense(1))
model_mlp.compile(loss='mse', optimizer=adam)
model_mlp.summary()

(3)训练模型
mlp_hitstory = model_mlp.fit(X_train.values, Y_train, epochs=epochs, batch_size=batch, validation_data=(X_valid.values, Y_valid), verbose=2)
(4)画随epoch变化的loss图
# 画图,横坐标是epochs,纵坐标是loss,分别画出train loss和validation loss
import matplotlib.pyplot as plt
plt.plot(mlp_hitstory.history['loss'])
plt.plot(mlp_hitstory.history['val_loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train', 'validation'], loc='upper left')
plt.show()

(5)计算预测值和实际值之间的均方误差
from sklearn.metrics import mean_squared_error
mlp_train_pred = model_mlp.predict(X_train.values)
mlp_valid_pred = model_mlp.predict(X_valid.values)
print('Train rmse:', np.sqrt(mean_squared_error(Y_train, mlp_train_pred)))
print('Validation rmse:', np.sqrt(mean_squared_error(Y_valid, mlp_valid_pred)))
接写到这里吧,今天效率太低了,明天继续



![[Linux] Mysql数据库中的用户管理与授权](https://img-blog.csdnimg.cn/direct/0f28bbd1403641038ff0fcd625bc018b.png)