作品展示:
0-5: 21题,正确21题,错误21题=42题 。小于44格子,都写上,哪怕输入2:8,实际也是5:5

0-10 66题,正确66题,错误66题=132题 大于44格子,正确66题抽取44*20%=8.8=8题,错误题66题*80%=44-8=36题
背景需求:
很多大班孩子很熟练做“0-5,0-10的加法、或减法题目,需要新的题型来换花样。除了”比大小“,我能想起的就是”判断加法题答案是否正确。
1.0模板是所有的题目都是错误答案,2.0模板能控制一定比例的正确题目出现
WORD模板





代码展示:
'''
X-Y 之间的所有加法题的判断题2.0(随机生成错误答案,考虑正确和不正确题的比例,如正确数量20%,错误数量80%),
时间:2023年12月25日 21:46
作者:阿夏
'''
import random
from win32com.client import constants,gencache
from win32com.client.gencache import EnsureDispatch
from win32com.client import constants # 导入枚举常数模块
import os,time
import docx
from docx import Document
from docx.shared import Pt
from docx.shared import RGBColor
from docx.enum.text import WD_PARAGRAPH_ALIGNMENT
from docx.oxml.ns import qn
from docxtpl import DocxTemplate
import pandas as pd
from docx2pdf import convert
from docx.shared import RGBColor
# 第一步:制作不重复所有“+”、不重复所有减法
# 不重复的数字题
num=int(input('打印几份(必须双数,根据人数,如32人)\n'))
classroom=input('班级(输入中、大)\n')
bl=int(input('正确题的比例,如2,就是20%的正确题,80%的错误题\n'))
size=20
height1=11
weight1=4
gz=height1*weight1 # 115
sum1=int(input('X-Y以内的“+” 最小数字X(0)\n'))
sum2=int(input('X-Y以内的“+” 最大数字Y(0-99)\n'))
# 5以内“+”题共21题
P1=[]# 正确
for a in range(0,sum2+1): # 起始数字就是10,就是排除掉0-10之间的数字
for b in range(0,sum2+1): # 起始数字为0,
if 0<=a+b<sum2+1:
w=random.randint(sum1,sum2) # 随机生成错误数字
# print('{}+{}='.format(a,b))
P1.append('{}+{}={}'.format('%02d'%a,'%02d'%b,'%02d'%(a+b)))
if 0<=b+a<sum2+1:
# print('{}+{}='.format(a,b))
P1.append('{}+{}={}'.format('%02d'%b,'%02d'%a,'%02d'%(a+b)))
else:
pass
P1 =list(set(P1)) # 排除重复,但随机打乱
P1.sort() # 小到大排序
print(P1)
# 正确的答案
# ['00+00=00', '00+01=01', '00+02=02', '00+03=03', '00+04=04', '00+05=05', '01+00=01', '01+01=02', '01+02=03', '01+03=04', '01+04=05', '02+00=02', '02+01=03', '02+02=04', '02+03=05', '03+00=03', '03+01=04', '03+02=05', '04+00=04', '04+01=05', '05+00=05']
# 新建一个”装N份word和PDF“的临时文件夹
imagePath1=r'C:\Users\jg2yXRZ\OneDrive\桌面\加减法\零时Word'
if not os.path.exists(imagePath1): # 判断存放图片的文件夹是否存在
os.makedirs(imagePath1) # 若图片文件夹不存在就创建
D=[]
for z in range(0,num): #多少份
# 标题说明
# 新建word
doc = Document(r'C:\Users\jg2yXRZ\OneDrive\桌面\加减法\04判断模板一页两份.docx')
for j in range(2):
P2=[]# 不正确的答案随机抽取
for p in P1:
w=random.randint(sum1,sum2) # 随机生成错误数字
P2.append(p[0:6]+'{}'.format('%02d'%(w)))
print(P2)
# ['00+00=10', '00+01=10', '00+02=10', '00+03=10', '00+04=10', '00+05=10', '01+00=10', '01+01=10', '01+02=10', '01+03=10', '01+04=10', '02+00=10', '02+01=10', '02+02=10', '02+03=10', '03+00=10', '03+01=10', '03+02=10', '04+00=10', '04+01=10', '05+00=10']
P3=P1+P2
# [[],[]]
print('P3长度{}'.format(len(P3)))
# 二位数去0
P4=[]
for i in P3: # 每个内容是00+00=00,一共6个字符
# print(i)
if i[0]=='0'and i[3]=='0' and i[6]=='0':
P4.append(i[1:3]+i[4:6]+i[7])
if i[0]=='0'and i[3]=='0'and i[6]!='0':
P4.append(i[1:3]+i[4:])
if i[0]=='0'and i[3]!='0'and i[6]!='0':
P4.append(i[1:])
if i[0]=='0'and i[3]!='0'and i[6]=='0':
P4.append(i[1:6]+i[7])
if i[0]!='0'and i[3]=='0'and i[6]=='0':
P4.append(i[0:3]+i[4:6]+i[7])
if i[0]!='0'and i[3]!='0'and i[6]=='0':
P4.append(i[0:6]+i[7])
if i[0]!='0'and i[3]=='0'and i[6]!='0':
P4.append(i[0:3]+i[4:])
if i[0]!='0'and i[3]!='0'and i[6]!='0':
P4.append(i)
print(P4)
print('{}-{}之间的加法判断题共有 {} 题'.format(sum1,sum2,len(P4)) ) # 42
# 如果正确题+错误题大于44题
P=[]
if len(P4)>gz:
# 正确题在前,错误题在后
P5=[]
f=int(len(P4)/2) # 21
for e in range(int(len(P4)/f)):
P5.append(P4[e*f:e*f+f])
print(P5)
# 随机抽取比例 共44题
zq=int(gz*(bl*10/100))
cw=gz-zq
# 从P5[0]随机抽取20%, 从P5[1]随机抽取80%,组成P
a1=P5[0]
a2=P5[1]
t1=random.sample (a1,zq)
t2=random.sample (a2,cw)
for t3 in t1:
P.append(t3)
for t4 in t2:
P.append(t4)
# 暂时不打乱
if len(P4)<=gz:
for t5 in P4:
P.append(t5)
# print(P)
# print('{}-{}之间的加法判断题共有 {} 题'.format(sum1,sum2,len(P)) ) # 42
# 第一行的班级和项目
A=[]
c='{}'.format(classroom)
if len(P) <=gz:
title='{}-{}“+”判断{}抽{}题{}:{}'.format(sum1,sum2,len(P1),len(P),bl,10-bl)
if len(P) >gz:
title='{}-{}“+”判断{}抽{}题{}:{}'.format(sum1,sum2,len(P1),gz,bl,10-bl)
d=['0003','0006']
# 表格0 表格2的 03 05单元格里写入标题信息c
A.append(c)
A.append(title)
print(A)
# 制作"单元格"
bg=[]
for x in range(0,weight1*3,3): # 5 #数列 先宽 后高
for y in range(1,height1+1): # 23
s1='{}{}'.format('%02d'%y,'%02d'%x) #数列 先y 后x
bg.append(s1)
print(bg)
print(len(bg))
bg.insert(0,d[1])
bg.insert(0,d[0])
print(bg)
print(len(bg))
# 如果题目总数小于155,就提取
# 例如:0-5 21题,P的第一部分是21题全部,第2部分就21题里面的随机抽屉,第3部分13也是随机抽取,可能会重复
PP=[]
PPP=[]
PP.clear()
# P.clear()
if len(P)<=gz:
for l in P : # 先写入固定的21题
PP.append(l)
print(PP)
print('第1组长度{}'.format(len(PP)))
# 0-0只有1题,所以批量155次
for e in range(gz):
PP.append('') # 预留一个空行做分割线
v=random.sample(P,len(P)) # 从21题随机抽取不重复21
for u in v: # 遍历提取
PP.append(u) # 添加到P
PPP=PP[:gz] # 提取前55个
print('把21题批量55次后,总数量 实际提取{}格{}'.format(len(PP),len(PPP)))
print(PPP)
else:
w=random.sample(P,len(P)) # 从21题随机抽取不重复21
PPP=w
PPP.insert(0,title)
PPP.insert(0,classroom)
print(PPP)
print(len(PPP))
# # 房间模板(第一个表格)要写入的门牌号列表
table = doc.tables[j] # 表0,表2 写标题用的
# 标题写入3、5单元格
for t in range(0,len(bg)): # 0-5是最下面一行,用来写卡片数字
pp=int(bg[t][0:2]) #
qq=int(bg[t][2:4])
k=str(PPP[t]) # 提取list图案列表里面每个图形 t=索引数字
print(pp,qq,k)
# 图案符号的字体、大小参数
run=table.cell(pp,qq).paragraphs[0].add_run(k) # 在单元格0,0(第1行第1列)输入第0个图图案
run.font.name = '黑体'#输入时默认华文彩云字体
# run.font.size = Pt(46) #输入字体大小默认30号 换行(一页一份大卡片
run.font.size = Pt(size) #是否加粗
# run.font.color.rgb = RGBColor(150,150,150) #数字小,颜色深0-255
run.font.color.rgb = RGBColor(150,150,150) #数字小,颜色深0-255
run.bold=True
# paragraph.paragraph_format.line_spacing = Pt(180) #数字段间距
r = run._element
r.rPr.rFonts.set(qn('w:eastAsia'), '黑体')#将输入语句中的中文部分字体变为华文行楷
table.cell(pp,qq).paragraphs[0].alignment = WD_PARAGRAPH_ALIGNMENT.LEFT #居中
#
#
doc.save(r'C:\Users\jg2yXRZ\OneDrive\桌面\加减法\零时Word\{}.docx'.format('%02d'%(z+1)))#保存为XX学号的电话号码word
time.sleep(1)
from docx2pdf import convert
# docx 文件另存为PDF文件
inputFile = r"C:/Users/jg2yXRZ/OneDrive/桌面/加减法/零时Word/{}.docx".format('%02d'%(z+1))# 要转换的文件:已存在
outputFile = r"C:/Users/jg2yXRZ/OneDrive/桌面/加减法/零时Word/{}.pdf".format('%02d'%(z+1)) # 要生成的文件:不存在
# 先创建 不存在的 文件
f1 = open(outputFile, 'w')
f1.close()
# 再转换往PDF中写入内容
convert(inputFile, outputFile)
print('----------第4步:把都有PDF合并为一个打印用PDF------------')
# 多个PDF合并(CSDN博主「红色小小螃蟹」,https://blog.csdn.net/yangcunbiao/article/details/125248205)
import os
from PyPDF2 import PdfMerger
target_path = 'C:/Users/jg2yXRZ/OneDrive/桌面/加减法/零时Word'
pdf_lst = [f for f in os.listdir(target_path) if f.endswith('.pdf')]
pdf_lst = [os.path.join(target_path, filename) for filename in pdf_lst]
pdf_lst.sort()
file_merger = PdfMerger()
for pdf in pdf_lst:
print(pdf)
file_merger.append(pdf)
if len(P) <=gz:
file_merger.write("C:/Users/jg2yXRZ/OneDrive/桌面/加减法/(打印合集)05(一页两份 ){}题{}-{}加法判断题“+”共{}题抽{}题{}比{}({}共{}人打印{}张).pdf" .format(gz,'%02d'%sum1,'%02d'%sum2,'%03d'%len(P1),'%02d'%len(P), bl,int(10-bl),c,num,num))
else:
file_merger.write("C:/Users/jg2yXRZ/OneDrive/桌面/加减法/(打印合集)05(一页两份 ){}题{}-{}加法判断题“+”共{}题抽{}题{}比{}({}共{}人打印{}张).pdf".format(gz,'%02d'%sum1,'%02d'%sum2,'%03d'%len(P1),gz, bl,int(10-bl),c,num,num))
#
file_merger.close()
# doc.Close()
# # print('----------第5步:删除临时文件夹------------')
import shutil
shutil.rmtree('C:/Users/jg2yXRZ/OneDrive/桌面/加减法/零时Word') #递归删除文件夹,即:删除非空文件夹
终端展示
2.0版判断题说明:
以0-5为例,21题,按比例抽取正确题20%和错误题80%。因为21正确题+21错误题总数42题,小于44格子,所以默认都写入表格,先正确题,后错误题,不考虑20%和80%的比例。
以0-10为例,66题,按比例抽取正确题20%和错误题80%。因为66正确题+66错误题总数132题,大于44格子,所以考虑按正确题20%和错误题80%的比例随机打乱抽取

以上为了演示正确错误题目的数量正确性,,而“先正确题”“后错误题。”
打乱时,只要把这两个取消隐藏,显示出来,就能够做出正确与错误题混合的效果

'''
X-Y 之间的所有加法题的判断题2.0(打乱版 随机生成错误答案,考虑正确和不正确题的比例,如正确数量20%,错误数量80%),
时间:2023年12月25日 21:46
作者:阿夏
'''
import random
from win32com.client import constants,gencache
from win32com.client.gencache import EnsureDispatch
from win32com.client import constants # 导入枚举常数模块
import os,time
import docx
from docx import Document
from docx.shared import Pt
from docx.shared import RGBColor
from docx.enum.text import WD_PARAGRAPH_ALIGNMENT
from docx.oxml.ns import qn
from docxtpl import DocxTemplate
import pandas as pd
from docx2pdf import convert
from docx.shared import RGBColor
# 第一步:制作不重复所有“+”、不重复所有减法
# 不重复的数字题
num=int(input('打印几份(必须双数,根据人数,如32人)\n'))
classroom=input('班级(输入中、大)\n')
bl=int(input('正确题的比例,如2,就是20%的正确题,80%的错误题\n'))
size=20
height1=11
weight1=4
gz=height1*weight1 # 115
sum1=int(input('X-Y以内的“+” 最小数字X(0)\n'))
sum2=int(input('X-Y以内的“+” 最大数字Y(0-99)\n'))
# 5以内“+”题共21题
P1=[]# 正确
for a in range(0,sum2+1): # 起始数字就是10,就是排除掉0-10之间的数字
for b in range(0,sum2+1): # 起始数字为0,
if 0<=a+b<sum2+1:
w=random.randint(sum1,sum2) # 随机生成错误数字
# print('{}+{}='.format(a,b))
P1.append('{}+{}={}'.format('%02d'%a,'%02d'%b,'%02d'%(a+b)))
if 0<=b+a<sum2+1:
# print('{}+{}='.format(a,b))
P1.append('{}+{}={}'.format('%02d'%b,'%02d'%a,'%02d'%(a+b)))
else:
pass
P1 =list(set(P1)) # 排除重复,但随机打乱
P1.sort() # 小到大排序
print(P1)
# 正确的答案
# ['00+00=00', '00+01=01', '00+02=02', '00+03=03', '00+04=04', '00+05=05', '01+00=01', '01+01=02', '01+02=03', '01+03=04', '01+04=05', '02+00=02', '02+01=03', '02+02=04', '02+03=05', '03+00=03', '03+01=04', '03+02=05', '04+00=04', '04+01=05', '05+00=05']
# 新建一个”装N份word和PDF“的临时文件夹
imagePath1=r'C:\Users\jg2yXRZ\OneDrive\桌面\加减法\零时Word'
if not os.path.exists(imagePath1): # 判断存放图片的文件夹是否存在
os.makedirs(imagePath1) # 若图片文件夹不存在就创建
D=[]
for z in range(0,num): #多少份
# 标题说明
# 新建word
doc = Document(r'C:\Users\jg2yXRZ\OneDrive\桌面\加减法\04判断模板一页两份.docx')
for j in range(2):
P2=[]# 不正确的答案随机抽取
for p in P1:
w=random.randint(sum1,sum2) # 随机生成错误数字
P2.append(p[0:6]+'{}'.format('%02d'%(w)))
print(P2)
# ['00+00=10', '00+01=10', '00+02=10', '00+03=10', '00+04=10', '00+05=10', '01+00=10', '01+01=10', '01+02=10', '01+03=10', '01+04=10', '02+00=10', '02+01=10', '02+02=10', '02+03=10', '03+00=10', '03+01=10', '03+02=10', '04+00=10', '04+01=10', '05+00=10']
P3=P1+P2
# [[],[]]
print('P3长度{}'.format(len(P3)))
# 二位数去0
P4=[]
for i in P3: # 每个内容是00+00=00,一共6个字符
# print(i)
if i[0]=='0'and i[3]=='0' and i[6]=='0':
P4.append(i[1:3]+i[4:6]+i[7])
if i[0]=='0'and i[3]=='0'and i[6]!='0':
P4.append(i[1:3]+i[4:])
if i[0]=='0'and i[3]!='0'and i[6]!='0':
P4.append(i[1:])
if i[0]=='0'and i[3]!='0'and i[6]=='0':
P4.append(i[1:6]+i[7])
if i[0]!='0'and i[3]=='0'and i[6]=='0':
P4.append(i[0:3]+i[4:6]+i[7])
if i[0]!='0'and i[3]!='0'and i[6]=='0':
P4.append(i[0:6]+i[7])
if i[0]!='0'and i[3]=='0'and i[6]!='0':
P4.append(i[0:3]+i[4:])
if i[0]!='0'and i[3]!='0'and i[6]!='0':
P4.append(i)
print(P4)
print('{}-{}之间的加法判断题共有 {} 题'.format(sum1,sum2,len(P4)) ) # 42
# 如果正确题+错误题大于44题
P=[]
if len(P4)>gz:
# 正确题在前,错误题在后
P5=[]
f=int(len(P4)/2) # 21
for e in range(int(len(P4)/f)):
P5.append(P4[e*f:e*f+f])
print(P5)
# 随机抽取比例 共44题
zq=int(gz*(bl*10/100))
cw=gz-zq
# 从P5[0]随机抽取20%, 从P5[1]随机抽取80%,组成P
a1=P5[0]
a2=P5[1]
t1=random.sample (a1,zq)
t2=random.sample (a2,cw)
for t3 in t1:
P.append(t3)
for t4 in t2:
P.append(t4)
random.shuffle(P) # 随机打乱
# 暂时不打乱
if len(P4)<=gz:
for t5 in P4:
P.append(t5)
random.shuffle(P) # 随机打乱
# print(P)
# print('{}-{}之间的加法判断题共有 {} 题'.format(sum1,sum2,len(P)) ) # 42
# 第一行的班级和项目
A=[]
c='{}'.format(classroom)
if len(P) <=gz:
title='{}-{}“+”判断{}抽{}题5:5'.format(sum1,sum2,len(P1),len(P),bl,10-bl)
if len(P) >gz:
title='{}-{}“+”判断{}抽{}题{}:{}'.format(sum1,sum2,len(P1),gz,bl,10-bl)
d=['0003','0006']
# 表格0 表格2的 03 05单元格里写入标题信息c
A.append(c)
A.append(title)
print(A)
# 制作"单元格"
bg=[]
for x in range(0,weight1*3,3): # 5 #数列 先宽 后高
for y in range(1,height1+1): # 23
s1='{}{}'.format('%02d'%y,'%02d'%x) #数列 先y 后x
bg.append(s1)
print(bg)
print(len(bg))
bg.insert(0,d[1])
bg.insert(0,d[0])
print(bg)
print(len(bg))
# 如果题目总数小于155,就提取
# 例如:0-5 21题,P的第一部分是21题全部,第2部分就21题里面的随机抽屉,第3部分13也是随机抽取,可能会重复
PP=[]
PPP=[]
PP.clear()
# P.clear()
if len(P)<=gz:
for l in P : # 先写入固定的21题
PP.append(l)
print(PP)
print('第1组长度{}'.format(len(PP)))
# 0-0只有1题,所以批量155次
for e in range(gz):
PP.append('') # 预留一个空行做分割线
v=random.sample(P,len(P)) # 从21题随机抽取不重复21
for u in v: # 遍历提取
PP.append(u) # 添加到P
PPP=PP[:gz] # 提取前55个
print('把21题批量55次后,总数量 实际提取{}格{}'.format(len(PP),len(PPP)))
print(PPP)
else:
w=random.sample(P,len(P)) # 从21题随机抽取不重复21
PPP=w
PPP.insert(0,title)
PPP.insert(0,classroom)
print(PPP)
print(len(PPP))
# # 房间模板(第一个表格)要写入的门牌号列表
table = doc.tables[j] # 表0,表2 写标题用的
# 标题写入3、5单元格
for t in range(0,len(bg)): # 0-5是最下面一行,用来写卡片数字
pp=int(bg[t][0:2]) #
qq=int(bg[t][2:4])
k=str(PPP[t]) # 提取list图案列表里面每个图形 t=索引数字
print(pp,qq,k)
# 图案符号的字体、大小参数
run=table.cell(pp,qq).paragraphs[0].add_run(k) # 在单元格0,0(第1行第1列)输入第0个图图案
run.font.name = '黑体'#输入时默认华文彩云字体
# run.font.size = Pt(46) #输入字体大小默认30号 换行(一页一份大卡片
run.font.size = Pt(size) #是否加粗
# run.font.color.rgb = RGBColor(150,150,150) #数字小,颜色深0-255
run.font.color.rgb = RGBColor(150,150,150) #数字小,颜色深0-255
run.bold=True
# paragraph.paragraph_format.line_spacing = Pt(180) #数字段间距
r = run._element
r.rPr.rFonts.set(qn('w:eastAsia'), '黑体')#将输入语句中的中文部分字体变为华文行楷
table.cell(pp,qq).paragraphs[0].alignment = WD_PARAGRAPH_ALIGNMENT.LEFT #居中
#
#
doc.save(r'C:\Users\jg2yXRZ\OneDrive\桌面\加减法\零时Word\{}.docx'.format('%02d'%(z+1)))#保存为XX学号的电话号码word
time.sleep(1)
from docx2pdf import convert
# docx 文件另存为PDF文件
inputFile = r"C:/Users/jg2yXRZ/OneDrive/桌面/加减法/零时Word/{}.docx".format('%02d'%(z+1))# 要转换的文件:已存在
outputFile = r"C:/Users/jg2yXRZ/OneDrive/桌面/加减法/零时Word/{}.pdf".format('%02d'%(z+1)) # 要生成的文件:不存在
# 先创建 不存在的 文件
f1 = open(outputFile, 'w')
f1.close()
# 再转换往PDF中写入内容
convert(inputFile, outputFile)
print('----------第4步:把都有PDF合并为一个打印用PDF------------')
# 多个PDF合并(CSDN博主「红色小小螃蟹」,https://blog.csdn.net/yangcunbiao/article/details/125248205)
import os
from PyPDF2 import PdfMerger
target_path = 'C:/Users/jg2yXRZ/OneDrive/桌面/加减法/零时Word'
pdf_lst = [f for f in os.listdir(target_path) if f.endswith('.pdf')]
pdf_lst = [os.path.join(target_path, filename) for filename in pdf_lst]
pdf_lst.sort()
file_merger = PdfMerger()
for pdf in pdf_lst:
print(pdf)
file_merger.append(pdf)
if len(P) <=gz:
file_merger.write("C:/Users/jg2yXRZ/OneDrive/桌面/加减法/(打印合集)05(一页两份 ){}题{}-{}加法判断题打乱“+”共{}题抽{}题{}比{}({}共{}人打印{}张).pdf" .format(gz,'%02d'%sum1,'%02d'%sum2,'%03d'%len(P1),'%02d'%len(P), bl,int(10-bl),c,num,num))
else:
file_merger.write("C:/Users/jg2yXRZ/OneDrive/桌面/加减法/(打印合集)05(一页两份 ){}题{}-{}加法判断题打乱“+”共{}题抽{}题{}比{}({}共{}人打印{}张).pdf".format(gz,'%02d'%sum1,'%02d'%sum2,'%03d'%len(P1),gz, bl,int(10-bl),c,num,num))
#
file_merger.close()
# doc.Close()
# # print('----------第5步:删除临时文件夹------------')
import shutil
shutil.rmtree('C:/Users/jg2yXRZ/OneDrive/桌面/加减法/零时Word') #递归删除文件夹,即:删除非空文件夹


存在问题:
随机生成的错误答案中也会有正确答案(随机抽取数字)。范围越小(0-5),这种情况月明显,正确数量超过21题,。后续需要设计,确保错误题答案不会有正确数字
解决
添加代码,遇到正确答案,就跳过,实现了“”每份0-10 正确题目20%=8题“”的目标
'''
X-Y 之间的所有加法题的判断题2.0(随机生成绝对错误答案,考虑正确和不正确题的比例,如正确数量20%,错误数量80%),
时间:2023年12月25日 21:46
作者:阿夏
'''
import random
from win32com.client import constants,gencache
from win32com.client.gencache import EnsureDispatch
from win32com.client import constants # 导入枚举常数模块
import os,time
import docx
from docx import Document
from docx.shared import Pt
from docx.shared import RGBColor
from docx.enum.text import WD_PARAGRAPH_ALIGNMENT
from docx.oxml.ns import qn
from docxtpl import DocxTemplate
import pandas as pd
from docx2pdf import convert
from docx.shared import RGBColor
# 第一步:制作不重复所有“+”、不重复所有减法
# 不重复的数字题
num=int(input('打印几份(必须双数,根据人数,如32人)\n'))
classroom=input('班级(输入中、大)\n')
bl=int(input('正确题的比例,如2,就是20%的正确题,80%的错误题\n'))
size=20
height1=11
weight1=4
gz=height1*weight1 # 115
sum1=int(input('X-Y以内的“+” 最小数字X(0)\n'))
sum2=int(input('X-Y以内的“+” 最大数字Y(0-99)\n'))
# 5以内“+”题共21题
P1=[]# 正确
for a in range(0,sum2+1): # 起始数字就是10,就是排除掉0-10之间的数字
for b in range(0,sum2+1): # 起始数字为0,
if 0<=a+b<sum2+1:
w=random.randint(sum1,sum2) # 随机生成错误数字
# print('{}+{}='.format(a,b))
P1.append('{}+{}={}'.format('%02d'%a,'%02d'%b,'%02d'%(a+b)))
if 0<=b+a<sum2+1:
# print('{}+{}='.format(a,b))
P1.append('{}+{}={}'.format('%02d'%b,'%02d'%a,'%02d'%(a+b)))
else:
pass
P1 =list(set(P1)) # 排除重复,但随机打乱
P1.sort() # 小到大排序
print(P1)
# 正确的答案
# ['00+00=00', '00+01=01', '00+02=02', '00+03=03', '00+04=04', '00+05=05', '01+00=01', '01+01=02', '01+02=03', '01+03=04', '01+04=05', '02+00=02', '02+01=03', '02+02=04', '02+03=05', '03+00=03', '03+01=04', '03+02=05', '04+00=04', '04+01=05', '05+00=05']
# 新建一个”装N份word和PDF“的临时文件夹
imagePath1=r'C:\Users\jg2yXRZ\OneDrive\桌面\加减法\零时Word'
if not os.path.exists(imagePath1): # 判断存放图片的文件夹是否存在
os.makedirs(imagePath1) # 若图片文件夹不存在就创建
D=[]
for z in range(0,num): #多少份
# 标题说明
# 新建word
doc = Document(r'C:\Users\jg2yXRZ\OneDrive\桌面\加减法\04判断模板一页两份.docx')
for j in range(2):
P2=[]# 不正确的答案随机抽取
for p in P1:
w=random.randint(sum1,sum2) # 随机生成错误数字
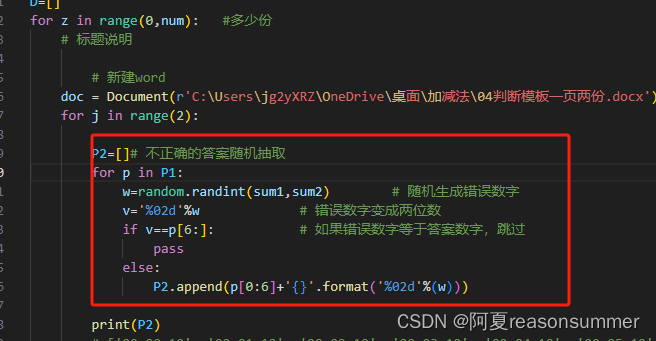
v='%02d'%w # 错误数字变成两位数
if v==p[6:]: # 如果错误数字等于答案数字,跳过
pass
else:
P2.append(p[0:6]+'{}'.format('%02d'%(w)))
print(P2)
# ['00+00=10', '00+01=10', '00+02=10', '00+03=10', '00+04=10', '00+05=10', '01+00=10', '01+01=10', '01+02=10', '01+03=10', '01+04=10', '02+00=10', '02+01=10', '02+02=10', '02+03=10', '03+00=10', '03+01=10', '03+02=10', '04+00=10', '04+01=10', '05+00=10']
P3=P1+P2
# [[],[]]
print('P3长度{}'.format(len(P3)))
# 二位数去0
P4=[]
for i in P3: # 每个内容是00+00=00,一共6个字符
# print(i)
if i[0]=='0'and i[3]=='0' and i[6]=='0':
P4.append(i[1:3]+i[4:6]+i[7])
if i[0]=='0'and i[3]=='0'and i[6]!='0':
P4.append(i[1:3]+i[4:])
if i[0]=='0'and i[3]!='0'and i[6]!='0':
P4.append(i[1:])
if i[0]=='0'and i[3]!='0'and i[6]=='0':
P4.append(i[1:6]+i[7])
if i[0]!='0'and i[3]=='0'and i[6]=='0':
P4.append(i[0:3]+i[4:6]+i[7])
if i[0]!='0'and i[3]!='0'and i[6]=='0':
P4.append(i[0:6]+i[7])
if i[0]!='0'and i[3]=='0'and i[6]!='0':
P4.append(i[0:3]+i[4:])
if i[0]!='0'and i[3]!='0'and i[6]!='0':
P4.append(i)
print(P4)
print('{}-{}之间的加法判断题共有 {} 题'.format(sum1,sum2,len(P4)) ) # 42
# 如果正确题+错误题大于44题
P=[]
if len(P4)>gz:
# 正确题在前,错误题在后
P5=[]
f=int(len(P4)/2) # 21
for e in range(int(len(P4)/f)):
P5.append(P4[e*f:e*f+f])
print(P5)
# 随机抽取比例 共44题
zq=int(gz*(bl*10/100))
cw=gz-zq
# 从P5[0]随机抽取20%, 从P5[1]随机抽取80%,组成P
a1=P5[0]
a2=P5[1]
t1=random.sample (a1,zq)
t2=random.sample (a2,cw)
for t3 in t1:
P.append(t3)
for t4 in t2:
P.append(t4)
random.shuffle(P) # 随机打乱
# 暂时不打乱
if len(P4)<=gz:
for t5 in P4:
P.append(t5)
random.shuffle(P) # 随机打乱
# print(P)
# print('{}-{}之间的加法判断题共有 {} 题'.format(sum1,sum2,len(P)) ) # 42
# 第一行的班级和项目
A=[]
c='{}'.format(classroom)
if len(P1) <=gz:
title='{}-{}“+”判断{}抽{}题5:5'.format(sum1,sum2,len(P1),len(P),bl,10-bl)
if len(P1) >gz:
title='{}-{}“+”判断{}抽{}题{}:{}'.format(sum1,sum2,len(P1),gz,bl,10-bl)
d=['0003','0006']
# 表格0 表格2的 03 05单元格里写入标题信息c
A.append(c)
A.append(title)
print(A)
# 制作"单元格"
bg=[]
for x in range(0,weight1*3,3): # 5 #数列 先宽 后高
for y in range(1,height1+1): # 23
s1='{}{}'.format('%02d'%y,'%02d'%x) #数列 先y 后x
bg.append(s1)
print(bg)
print(len(bg))
bg.insert(0,d[1])
bg.insert(0,d[0])
print(bg)
print(len(bg))
# 如果题目总数小于155,就提取
# 例如:0-5 21题,P的第一部分是21题全部,第2部分就21题里面的随机抽屉,第3部分13也是随机抽取,可能会重复
PP=[]
PPP=[]
PP.clear()
# P.clear()
if len(P)<=gz:
for l in P : # 先写入固定的21题
PP.append(l)
print(PP)
print('第1组长度{}'.format(len(PP)))
# 0-0只有1题,所以批量155次
for e in range(gz):
PP.append('') # 预留一个空行做分割线
v=random.sample(P,len(P)) # 从21题随机抽取不重复21
for u in v: # 遍历提取
PP.append(u) # 添加到P
PPP=PP[:gz] # 提取前55个
print('把21题批量55次后,总数量 实际提取{}格{}'.format(len(PP),len(PPP)))
print(PPP)
else:
w=random.sample(P,len(P)) # 从21题随机抽取不重复21
PPP=w
PPP.insert(0,title)
PPP.insert(0,classroom)
print(PPP)
print(len(PPP))
# # 房间模板(第一个表格)要写入的门牌号列表
table = doc.tables[j] # 表0,表2 写标题用的
# 标题写入3、5单元格
for t in range(0,len(bg)): # 0-5是最下面一行,用来写卡片数字
pp=int(bg[t][0:2]) #
qq=int(bg[t][2:4])
k=str(PPP[t]) # 提取list图案列表里面每个图形 t=索引数字
print(pp,qq,k)
# 图案符号的字体、大小参数
run=table.cell(pp,qq).paragraphs[0].add_run(k) # 在单元格0,0(第1行第1列)输入第0个图图案
run.font.name = '黑体'#输入时默认华文彩云字体
# run.font.size = Pt(46) #输入字体大小默认30号 换行(一页一份大卡片
run.font.size = Pt(size) #是否加粗
# run.font.color.rgb = RGBColor(150,150,150) #数字小,颜色深0-255
run.font.color.rgb = RGBColor(150,150,150) #数字小,颜色深0-255
run.bold=True
# paragraph.paragraph_format.line_spacing = Pt(180) #数字段间距
r = run._element
r.rPr.rFonts.set(qn('w:eastAsia'), '黑体')#将输入语句中的中文部分字体变为华文行楷
table.cell(pp,qq).paragraphs[0].alignment = WD_PARAGRAPH_ALIGNMENT.LEFT #居中
#
#
doc.save(r'C:\Users\jg2yXRZ\OneDrive\桌面\加减法\零时Word\{}.docx'.format('%02d'%(z+1)))#保存为XX学号的电话号码word
time.sleep(1)
from docx2pdf import convert
# docx 文件另存为PDF文件
inputFile = r"C:/Users/jg2yXRZ/OneDrive/桌面/加减法/零时Word/{}.docx".format('%02d'%(z+1))# 要转换的文件:已存在
outputFile = r"C:/Users/jg2yXRZ/OneDrive/桌面/加减法/零时Word/{}.pdf".format('%02d'%(z+1)) # 要生成的文件:不存在
# 先创建 不存在的 文件
f1 = open(outputFile, 'w')
f1.close()
# 再转换往PDF中写入内容
convert(inputFile, outputFile)
print('----------第4步:把都有PDF合并为一个打印用PDF------------')
# 多个PDF合并(CSDN博主「红色小小螃蟹」,https://blog.csdn.net/yangcunbiao/article/details/125248205)
import os
from PyPDF2 import PdfMerger
target_path = 'C:/Users/jg2yXRZ/OneDrive/桌面/加减法/零时Word'
pdf_lst = [f for f in os.listdir(target_path) if f.endswith('.pdf')]
pdf_lst = [os.path.join(target_path, filename) for filename in pdf_lst]
pdf_lst.sort()
file_merger = PdfMerger()
for pdf in pdf_lst:
print(pdf)
file_merger.append(pdf)
if len(P) <=gz:
file_merger.write("C:/Users/jg2yXRZ/OneDrive/桌面/加减法/(打印合集)05(一页两份 ){}题{}-{}加法判断题打乱“+”共{}题抽{}题{}比{}({}共{}人打印{}张).pdf" .format(gz,'%02d'%sum1,'%02d'%sum2,'%03d'%len(P1),'%02d'%len(P), bl,int(10-bl),c,num,num))
else:
file_merger.write("C:/Users/jg2yXRZ/OneDrive/桌面/加减法/(打印合集)05(一页两份 ){}题{}-{}加法判断题打乱“+”共{}题抽{}题{}比{}({}共{}人打印{}张).pdf".format(gz,'%02d'%sum1,'%02d'%sum2,'%03d'%len(P1),gz, bl,int(10-bl),c,num,num))
#
file_merger.close()
# doc.Close()
# # print('----------第5步:删除临时文件夹------------')
import shutil
shutil.rmtree('C:/Users/jg2yXRZ/OneDrive/桌面/加减法/零时Word') #递归删除文件夹,即:删除非空文件夹










![[java] 注释](https://img-blog.csdnimg.cn/direct/ebe19bc21cff4b48b0eb0c5630347477.png)
![[论文阅读笔记28] 对比学习在多目标跟踪中的应用](https://img-blog.csdnimg.cn/direct/3a1ab023cdd74b8e904cea1382db8e64.png)