C/C++面试题集合四
目录
1、什么是C++中的类?如何定义和实例化一个类?
2、请解释C++中的继承和多态性。
3、什么是虚函数?为什么在基类中使用虚函数?
4、解释封装、继承和多态的概念,并提供相应的代码示例
5、如何处理内存泄漏问题?提供一些常见的内存管理技术
6、解释堆与栈之间的区别
7、C++中动态内存分配是如何工作的?如何使用new和delete操作符来进行动态内存管理?
8、什么是析构函数?它有什么作用?
9、请解释const关键字在C++中的作用
10、请解释引用(Reference)与指针(Pointer)之间的区别。
11、解释浅拷贝和深拷贝,并提供相应代码示例
12、解释运算符重载及其在C++中的使用场景
13、解释模板类和模板函数,并给出一个模板类或模板函数的示例代码。
14、C++中异常处理机制是如何工作的?解释try-catch块及其语法。
15、列举并解释STL库中常用容器,例如vector、list、map等。
16、STL迭代器是什么?请给出一个使用迭代器的示例。
17、解释C++中的命名空间(Namespace)概念及其作用。
18、解释静态成员变量和静态成员函数,并提供相应代码示例。
19、请解释预处理器(Preprocessor)在C++中的作用,并举例说明其常见用法。
20、C++中如何进行文件读写操作?
21、解释指针与数组之间的关系,如何通过指针遍历数组?
22、列举C++中常见的排序算法,并选择一个进行实现。
23、列举并解释C++中常见的设计模式,例如单例模式、观察者模式等。
24、如何进行线程创建和同步操作?解释互斥锁和条件变量。
25、什么是Lambda表达式?它有什么作用?
26、C++11引入了哪些新特性?请列举几个重要的特性并简要解释它们。
27、解释auto关键字在C++11中的作用及其使用场景。
28、什么是智能指针?列举几种常见的智能指针类型,并解释其特点和适用场景。
29、C++异常处理机制允许抛出任意类型的异常吗?为什么?
30、请解释动态绑定(Dynamic Binding)的概念及其作用。
1、什么是C++中的类?如何定义和实例化一个类?
在C++中,类是一种用户自定义的数据类型,用于封装数据和相关操作。它可以看作是一个模板或蓝图,描述了对象的属性(成员变量)和行为(成员函数)。
要定义一个类,可以使用class关键字后跟类名,并在大括号中定义类的成员变量和成员函数。例如:
class MyClass {
private:
int myVariable; // 成员变量
public:
void myFunction(); // 成员函数
};上述代码定义了一个名为 MyClass 的类,包含一个私有的整型成员变量 myVariable 和一个公有的成员函数 myFunction()。
要实例化一个类,需要创建该类的对象。可以通过使用类名后跟空括号来调用默认构造函数来实现。例如:
MyClass obj; // 实例化一个 MyClass 对象这将创建一个名为 obj 的 MyClass 类型的对象。
除了默认构造函数外,还可以根据需要编写其他构造函数,并在创建对象时传递参数进行初始化。
class MyClass {
private:
int myVariable;
public:
MyClass(int value) { // 构造函数
myVariable = value;
}
};
// 创建对象并传递参数进行初始化
MyClass obj(10);这样就会调用带有整数参数的构造函数,并将值 10 赋给 myVariable 成员变量。
通过定义和实例化类,你可以创建多个对象来访问和操作类中定义的成员变量和成员函数。
2、请解释C++中的继承和多态性。
在C++中,继承是一种机制,允许一个类(称为子类或派生类)从另一个已存在的类(称为基类或父类)继承属性和行为。子类可以继承基类的成员变量和成员函数,并且还可以添加自己特有的成员变量和成员函数。
通过使用冒号(:)来指定继承关系,并指定要从哪个基类继承,以及继承类型(公有、私有或保护)。例如:
class BaseClass {
// 基类定义
};
class DerivedClass : access-specifier BaseClass {
// 派生类定义
};其中,access-specifier 可以是 public、private 或 protected,表示派生类对基类的访问权限。
多态性是面向对象编程中的一个概念,它允许同样的函数接口在不同的对象上表现出不同的行为。C++ 中实现多态性主要依靠虚函数(virtual functions)和动态绑定。
虚函数是在基类中声明并用 virtual 关键字进行标记的成员函数。派生类可以覆盖该虚函数,并根据需要提供自己的实现。通过使用指向基类对象的指针或引用调用虚函数时,程序将根据运行时实际对象类型来确定要调用的函数。
例如:
class Shape {
public:
virtual void draw() {
// 基类虚函数的默认实现
cout << "绘制图形" << endl;
}
};
class Circle : public Shape {
public:
void draw() {
// 派生类对虚函数的覆盖实现
cout << "绘制圆形" << endl;
}
};
class Rectangle : public Shape {
public:
void draw() {
cout << "绘制矩形" << endl;
}
};在上述代码中,Shape 类具有一个名为 draw() 的虚函数。派生类 Circle 和 Rectangle 都对该函数进行了覆盖。
通过使用基类指针或引用来调用 draw() 函数时,可以根据指向的对象类型来决定实际执行哪个版本的函数:
Shape* shapePtr;
Circle circle;
Rectangle rectangle;
shapePtr = &circle;
shapePtr->draw(); // 调用 Circle 类中的 draw() 函数
shapePtr = &rectangle;
shapePtr->draw(); // 调用 Rectangle 类中的 draw() 函数这种动态绑定机制使得程序能够根据实际运行时对象类型来选择相应的函数,实现了多态性。
3、什么是虚函数?为什么在基类中使用虚函数?
虚函数是在基类中声明并用 virtual 关键字进行标记的成员函数。它在面向对象编程中扮演重要角色,允许派生类对该函数进行覆盖,并根据实际运行时对象类型来确定要调用的函数。
使用虚函数的主要目的是实现多态性。多态性允许同样的函数接口在不同的对象上表现出不同的行为。通过将函数声明为虚函数,可以在基类中定义一个通用的接口,并且允许派生类根据自己特定需求提供不同的实现。
当我们使用指向基类对象的指针或引用调用一个虚函数时,程序会根据运行时实际对象类型来确定要调用哪个版本的函数。这种动态绑定机制使得程序能够在运行时根据实际对象类型选择相应的函数,而不是在编译时就静态地决定。
使用虚函数有以下几个优点:
-
实现多态性:通过使用虚函数,可以创建一个统一接口,以便处理具有不同类型但具有相似功能和行为的对象。
-
简化代码逻辑:通过将通用操作放在基类中定义,并使用派生类覆盖特定功能,可以减少代码冗余并提高可维护性。
-
扩展性和灵活性:通过添加新的派生类并覆盖虚函数,可以轻松地扩展和修改现有的代码结构。
4、解释封装、继承和多态的概念,并提供相应的代码示例
封装、继承和多态是面向对象编程的三个重要概念。
封装(Encapsulation):封装是将数据和操作(方法)包装在一个单元(类)中,以实现数据的隐藏和保护。通过封装,我们可以将数据隐藏在类内部,并提供公共接口来访问和操作这些数据,从而实现了信息隐藏、数据安全性和代码模块化的目标。
示例代码:
class Circle {
private:
double radius;
public:
void setRadius(double r) {
if (r > 0) {
radius = r;
}
}
double getRadius() {
return radius;
}
double calculateArea() {
return 3.14 * radius * radius;
}
};在上述代码中,radius 是私有成员变量,外部无法直接访问。通过 setRadius() 和 getRadius() 方法,可以对半径进行设置和获取。同时,calculateArea() 方法用于计算圆的面积。
继承(Inheritance):继承允许一个类派生出子类,并从父类继承其属性和行为。子类可以使用父类已有的特性,并根据需要添加自己独特的属性和方法。通过继承机制,可以实现代码重用、层次结构组织等目标。
示例代码:
class Shape {
protected: // 使用 protected 访问修饰符
double width;
double height;
public:
void setDimensions(double w, double h) {
width = w;
height = h;
}
};
class Rectangle : public Shape {
public:
double calculateArea() {
return width * height;
}
};
class Triangle : public Shape {
public:
double calculateArea() {
return (width * height) / 2;
}
};在上述代码中,Shape 是基类,定义了 width 和 height 属性以及设置它们的方法。Rectangle 和 Triangle 是派生类,它们继承了 Shape 的属性,并添加了自己的计算面积的方法。
多态(Polymorphism):多态允许使用一个基类类型的指针或引用来调用派生类对象的特定方法。这样做可以根据实际运行时对象类型来确定要调用的函数版本,实现动态绑定和多态性。
示例代码:
class Animal {
public:
virtual void makeSound() {
cout << "Animal makes a sound." << endl;
}
};
class Dog : public Animal {
public:
void makeSound() override {
cout << "Dog barks." << endl;
}
};
class Cat : public Animal {
public:
void makeSound() override {
cout << "Cat meows." << endl;
}
};
int main() {
Animal* animal1 = new Dog();
Animal* animal2 = new Cat();
animal1->makeSound(); // 输出: "Dog barks."
animal2->makeSound(); // 输出: "Cat meows."
delete animal1;
delete animal2;
}在上述代码中,Animal 是基类,定义了虚函数 makeSound()。Dog 和 Cat 是派生类,它们覆盖了基类的虚函数。在 main() 函数中,我们使用基类指针调用不同派生类对象的 makeSound() 方法,根据实际运行时类型来确定要调用的函数版本。这就是多态性的体现。
综上所述,封装、继承和多态是面向对象编程的核心概念,通过合理应用它们可以实现代码的模块化、重用性和灵活性。
5、如何处理内存泄漏问题?提供一些常见的内存管理技术
-
显式释放内存:在使用动态分配的内存(如new、malloc)后,务必及时使用相应的释放操作(如delete、free)来手动释放已分配的内存。确保每次动态分配都有相应的释放操作与之对应。
-
智能指针(Smart Pointers):使用智能指针可以自动管理内存资源,避免显式地调用释放操作。C++中提供了 std::shared_ptr 和 std::unique_ptr 两种智能指针,它们可以在对象不再被引用时自动释放相关内存。
-
RAII(Resource Acquisition Is Initialization):RAII 是一种编程范式,在对象构造函数中获取资源,在析构函数中进行资源的释放。通过利用栈上对象生命周期结束时自动调用析构函数的特性,可以确保资源得到正确和及时地释放。
-
定期检查和测试:定期进行代码审查和测试,尤其关注内存分配和释放部分是否正确。使用工具或手动方法检测潜在的内存泄漏情况,并进行修复。
-
使用容器类和标准库:使用现代化的容器类和标准库算法可以简化内存管理工作。例如,使用 std::vector 替代手动管理数组内存,使用 std::string 替代手动管理字符串内存等。
-
遵循编码规范:良好的编码规范和设计原则有助于避免内存泄漏问题。例如,避免多层级的指针引用、避免过度复杂的嵌套结构、合理地处理异常情况等。
-
内存分析工具:使用专门的内存分析工具(如Valgrind、AddressSanitizer)来检测和诊断程序中的内存泄漏问题。这些工具可以帮助发现潜在的资源未释放或访问无效内存等情况。
6、解释堆与栈之间的区别
-
内存分配方式:栈上的变量由编译器自动分配和释放,而堆上的变量需要手动进行分配和释放。
-
空间大小限制:栈的大小通常是固定的,并且相对较小,由操作系统或编译器决定。而堆则可以根据需求动态地增加或减少空间。
-
分配速度:栈上的变量分配速度比较快,只需移动指针即可完成。而堆上的变量分配需要在运行时进行内存管理,所以相对较慢。
-
生命周期:栈上的变量具有局部性,在函数执行结束后会被自动销毁。而堆上的变量则可以在不同函数之间共享,并且需要手动释放,否则可能导致内存泄漏。
-
数据访问方式:栈上的数据访问更快,因为它们保存在连续的内存块中。而堆上的数据通过指针访问,并且可能散布在不同的内存位置。
-
使用场景:栈主要用于保存局部变量、函数调用过程中参数传递等。而堆一般用于动态创建对象、大型数据结构、全局变量等。
7、C++中动态内存分配是如何工作的?如何使用new和delete操作符来进行动态内存管理?
在C++中,动态内存分配通过new和delete操作符来实现。具体使用方式如下:
1. 使用new进行动态内存分配:
int* ptr = new int; // 分配一个整型变量的内存空间
double* arr = new double[10]; // 分配一个包含10个双精度浮点数的数组的内存空间2. 使用delete释放动态分配的内存:
delete ptr; // 释放之前通过new分配的单个变量的内存空间
delete[] arr; // 释放之前通过new[]分配的数组的内存空间在使用new操作符时,它会根据类型动态地为对象或数组分配合适大小的内存,并返回指向该内存块起始地址的指针。对于基本类型或自定义对象,可以使用相应类型的指针来接收这个返回值。
当不再需要动态分配的内存时,应使用delete操作符将其释放。对于通过new[]操作符创建的数组,必须使用delete[]进行释放。
需要注意以下几点:
-
必须确保在不再使用动态分配的内存时及时释放,以避免出现内存泄漏。
-
不要对同一个指针多次调用delete/delete[],否则会导致未定义行为。
-
对于每个new操作都应该有相应的delete操作来匹配。
此外,C++11引入了智能指针(如std::unique_ptr、std::shared_ptr等),它们提供了更安全和方便的动态内存管理方式,可以自动处理资源释放问题。推荐在可能的情况下使用智能指针来替代显式使用new/delete操作符。
8、什么是析构函数?它有什么作用?
析构函数是在C++类中的一个特殊成员函数,它与类名相同但前面加上波浪号(~),用于在对象生命周期结束时进行清理和资源释放。作用:
-
资源释放:析构函数可以用来释放对象所占有的资源,如动态分配的内存、打开的文件、建立的连接等。这样可以确保在对象销毁时相关资源得到正确释放,避免内存泄漏或资源泄漏。
-
清理操作:如果对象在创建过程中进行了一些初始化操作,在析构函数中可以进行相应的清理操作,将对象恢复到初始状态。
-
继承关系下的调用顺序:当存在继承关系时,派生类的析构函数会自动调用基类的析构函数,以便逐层清理各个父类的资源。
注意事项:
-
每个类只能有一个析构函数,且没有参数和返回值。
-
析构函数由编译器自动生成默认版本,如果不需要额外处理资源释放等操作,可以省略显式定义。
-
如果需要手动管理资源,通常需要显式定义析构函数,并在其中编写合适的代码来释放相关资源。
-
在使用指针类型成员变量时,在析构函数中要小心处理指针是否为空避免空指针解引用错误。
示例:
class MyClass {
public:
// 构造函数
MyClass() {
// 初始化操作
}
// 析构函数
~MyClass() {
// 资源释放或清理操作
}
};9、请解释const关键字在C++中的作用
在C++中,`const`关键字用于声明常量。它可以应用于变量、函数参数、函数返回值和成员函数。
1. 声明常量变量:使用`const`修饰的变量表示其值不能被修改。一旦初始化后,它们的值就不能再改变。
const int MAX_VALUE = 100;2. 函数参数中的常量:在函数定义时,如果将参数声明为`const`,则表示该参数在函数内部不可被修改。
void printName(const std::string& name) {
// 无法修改name的值
std::cout << "Name: " << name << std::endl;
}3. 常量引用:将对象作为常量引用传递给函数时,可以防止对该对象进行修改。
void modifyValue(const int& value) {
// 无法修改value的值
// ...
}4. 常成员函数:在类中声明成员函数时,如果希望该成员函数不会修改对象的状态,则需要将其声明为`const`。这样,在一个常对象上调用该成员函数是合法的。
class MyClass {
public:
void printData() const {
// 无法修改数据成员
// ...
}
int getData() const {
// 可以读取数据成员但无法修改
return data;
}
private:
int data;
};
int main() {
const MyClass obj;
obj.printData(); // 调用常成员函数
int value = obj.getData(); // 读取数据成员
}总的来说,`const`关键字可以用于确保变量、函数参数、函数返回值或成员函数在使用过程中不被修改,从而增加代码的可靠性和安全性。
10、请解释引用(Reference)与指针(Pointer)之间的区别。
引用和指针都是C++中用于间接访问对象的概念,但它们之间有几个重要的区别:
-
语法:声明一个引用使用&符号,而声明一个指针使用*符号。int num = 10; int& ref = num; // 引用 int* ptr = # // 指针
-
初始化:引用必须在声明时进行初始化,并且一旦初始化后不能改变其绑定的对象;指针可以在任何时候进行初始化,并且可以修改指向的对象。int num = 10; int& ref = num; // 引用初始化 int* ptr; // 指针声明 ptr = # // 指针赋值 ref = 20; // 正确,修改了num的值 *ptr = 30; // 正确,也会修改num的值
-
空值(null):指针可以具有空值(nullptr),表示未指向任何有效对象;引用没有空值,必须在初始化时绑定到一个有效对象上。
-
内存地址操作:指针可以进行内存地址的算术运算(如加法、减法等),并且可以通过解引用操作符(*)访问所指向的对象;引用不直接支持内存地址操作和解引用操作符,它是被绑定对象的别名。int num = 10; int* ptr = # // 指针 ptr++; // 正确,指针进行地址运算 *ptr = 20; // 正确,通过解引用修改所指向的对象 int& ref = num; // 引用 // ref++; // 错误,引用不支持地址运算 ref = 30; // 正确,直接修改了num的值
11、解释浅拷贝和深拷贝,并提供相应代码示例
浅拷贝(Shallow Copy)和深拷贝(Deep Copy)是在对象复制过程中的两种不同方式:
1 在未定义拷贝构造函数的情况下,系统会调用默认的拷贝函数——即浅拷贝(不用自己构造),它能够完成成员的简单的值的拷贝一一复制。当数据成员中没有指针时,浅拷贝是可行的;但当数据成员中有指针时,如果采用简单的浅拷贝,则两类中的两个指针将指向同一个地址(同一个堆区),当对象快结束时,会调用两次析构函数(析构函数也无需自己构造,但想要知道析构函数的工作可以自己构造析构函数用输出来记录),而导致指针悬挂现象,所以,此时,必须采用深拷贝。
2 深拷贝与浅拷贝的区别就在于深拷贝会在堆内存中另外申请空间来储存数据(新的堆区空间进行拷贝),从而也就解决了指针悬挂的问题。简而言之,当数据成员中有指针时,必须要用深拷贝。
注意浅拷贝会引起内存的重复释放,引起错误,这种错误一般会出现在类中有指针成员;
深拷贝需要单独构造拷贝构造函数,即对于指针成员需要在对象的实例化时,动态申请内存空间,而且不会引起内存的重复释放。
直接上代码说明:
#include <iostream>
#include <cstring>
#include <string>
using namespace std;
#define DEEP_CPY
namespace DAY11_SHALLOW_CPY
{
class Employee {
public:
char* name;
int age;
char* position;
string objName;
public:
Employee(const char* n, int a, const char* p,const string str) : name(new char[strlen(n) + 1]), age(a), position(new char[strlen(p) + 1]) ,objName(str){
strcpy(name, n);
strcpy(position, p);
cout << "构造函数 初始化参数" << endl;
}
// 浅拷贝构造函数
Employee(const Employee& other) : name(other.name), age(other.age), position(other.position) ,objName(other.objName) {cout << "构造函数 浅拷贝" << endl;}
~Employee() {
delete[] this->name;
delete[] this->position;
cout << this->objName << "析构函数" << endl;
}
void print() const
{
cout << "name: " << this->name << " age:" << this->age << " position: " << this->position << endl;
}
};
};
namespace DAY11_DEEP_CPY
{
class Employee {
public:
char* name;
int age;
char* position;
string objName;
public:
Employee(const char* n, int a, const char* p,string objname){
this->name = new char[strlen(n) + 1];
this->position = new char[strlen(p) + 1];
this->age = a;
this->objName = objname;
strcpy(name, n);
strcpy(position, p);
cout << "构造函数 初始化参数" << endl;
}
// 深拷贝构造函数
Employee(const Employee& other) : age(other.age), name(new char[strlen(other.name) + 1]), position(new char[strlen(other.position) + 1]),objName(other.objName) {
strcpy(name, other.name);
strcpy(position, other.position);
cout << "构造函数 深拷贝" << endl;
}
~Employee() {
delete[] this->name;
delete[] this->position;
cout << this->objName << "析构函数" << endl;
}
void print() const
{
cout << "name: " << this->name << " age:" << this->age << " position: " << this->position << endl;
}
};
};
int main(int argc, char *argv[])
{
#ifndef DEEP_CPY
cout << "\n \n \n";
cout << "***************************************************浅拷贝解析***************************************************" << endl;
cout << "\n \n \n";
// 浅拷贝
{
using namespace DAY11_SHALLOW_CPY;
char hu1[] = "Tom";
char hu2[] = "ShangHai";
int ku1 = 23;
char hu11[] = "Hubery";
char hu22[] = "BeiJing";
int ku11 = 28;
cout << "*******step1*******" << endl;
Employee t1(hu1,ku1,hu2,"t1");
cout << "*******step2*******" << endl;
Employee t2 = t1;
cout << "*******step3*******" << endl;
strcpy(t2.name,hu11);
strcpy(t2.position,hu22);
t2.objName = "t2";
t2.age = ku11;
cout << "t1:********* " << endl;
t1.print();
cout << "t2:********* " << endl;
t2.print();
cout << "*******step4*******" << endl;
}
#else
cout << "\n \n \n";
cout << "***************************************************深拷贝解析***************************************************" << endl;
cout << "\n \n \n";
// 深拷贝
{
using namespace DAY11_DEEP_CPY;
char hu1[] = "Tom";
char hu2[] = "ShangHai";
int ku1 = 23;
char hu11[] = "Hubery";
char hu22[] = "BeiJing";
int ku11 = 28;
cout << "*******step1*******" << endl;
Employee t1(hu1,ku1,hu2,"t1");
cout << "*******step2*******" << endl;
Employee t2 = t1;
cout << "*******step3*******" << endl;
strcpy(t2.name,hu11);
strcpy(t2.position,hu22);
t2.objName = "t2";
t2.age = ku11;
cout << "t1:********* " << endl;
t1.print();
cout << "t2:********* " << endl;
t2.print();
cout << "*******step4*******" << endl;
}
#endif
return 0;
}如上代码:
(1)浅拷贝
#define DEEP_CPY 没有被定义时,是一个典型的浅拷贝,结果如下:
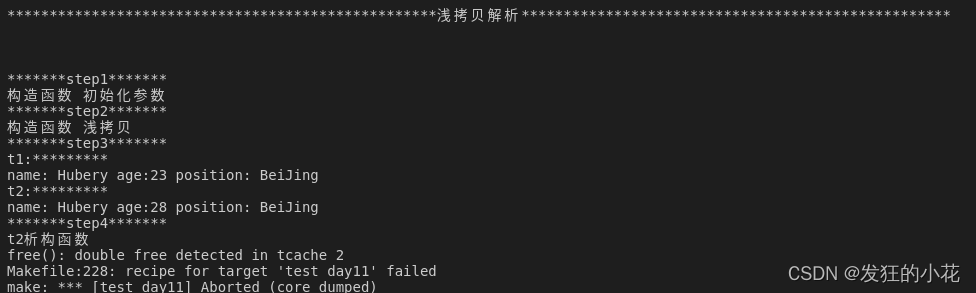
很明显修改t2中的一些值,改变了t1中在堆中的变量,最后释放空间时有重复释放的报错,因此是浅拷贝。
(2)深拷贝
#define DEEP_CPY 被定义时,是一个典型的浅拷贝,结果如下:

明显修改t2的值,t1中的值都没有改变,且程序运行结束后,调用了各自的析构函数,因此是深拷贝
12、解释运算符重载及其在C++中的使用场景
运算符重载是指在C++中,可以通过定义自定义的类成员函数或全局函数来改变操作符(如+、-、*、/等)的行为。通过重载运算符,我们可以使自定义类型的对象支持类似于内置类型的操作。
运算符重载在C++中有广泛的应用场景,包括但不限于:
-
自定义类型的数学运算:通过重载加减乘除等数学运算符,可以实现对自定义类型进行相应的数值计算操作。
-
容器类和迭代器:例如STL中的vector、list、map等容器类都使用了运算符重载来提供方便的元素访问和操作方式。
-
输入输出流操作:通过重载流插入(<<)和流提取(>>)运算符,可以实现自定义类型对象与输入输出流之间的转换。
-
比较和排序:通过重载比较运算符(如==、<、>等),可以使得自定义类型对象能够进行比较和排序。
-
实现迭代器功能:通过重载递增(++)、递减(--)等运算符,可以实现自定义类型对象作为迭代器进行遍历操作。
例如:
OpenCV中的Mat类型,Eigen中的一些矩阵库
13、解释模板类和模板函数,并给出一个模板类或模板函数的示例代码。
函数模板和类模板是C++中的两种模板,它们都可以用于实现泛型编程。
函数模板是一种将函数作为参数传递的模板,它可以接受任意类型的参数,并返回一个值。函数模板的定义以关键字template开始,后面跟着尖括号括起来的模板参数列表和函数声明。例如:
template<typename T>
T max(T a, T b) {
return a > b ? a : b;
}这个函数模板接受两个类型为T的参数a和b,并返回它们中的最大值。在使用该函数时,编译器会根据实际传入的参数类型来生成相应的函数实例。
类模板也是一种将类型作为参数传递的模板,它可以定义一个通用类型的类,该类可以用于处理不同类型的数据。类模板的定义也以关键字template开始,后面跟着尖括号括起来的模板参数列表和类声明。例如:
template<typename T>
class Stack {
private:
T data[100];
int top;
public:
void push(T item);
T pop();
T peek();
};这个类模板定义了一个通用类型的栈,可以用于存储任意类型的数据。在使用该类时,编译器会根据实际传入的类型来生成相应的类实例。
14、C++中异常处理机制是如何工作的?解释try-catch块及其语法。
C++中的异常处理机制允许我们在程序运行时检测和处理可能发生的异常情况。异常是指在程序执行期间出现的意外或不正常的情况,例如除以零、无效的输入等。异常处理机制可以帮助我们优雅地处理这些异常,避免程序崩溃或产生未定义行为。
在C++中,使用try-catch块来捕获和处理异常。try块用于包含可能引发异常的代码段,而catch块则用于捕获并处理这些异常。
以下是try-catch块的基本语法:
try {
// 可能引发异常的代码
}
catch (ExceptionType1 e1) {
// 处理 ExceptionType1 类型的异常
}
catch (ExceptionType2 e2) {
// 处理 ExceptionType2 类型的异常
}
// ...
catch (...) {
// 处理其他类型的异常(通配符)
}在上述语法中,我们将可能引发异常的代码放置在try块内。如果在该代码段中抛出了一个匹配某个 catch 块中定义的异常类型(或其派生类),那么控制流就会跳转到相应的 catch 块,并执行其中定义的操作。
可以使用多个 catch 块来捕获不同类型(或其派生类)的异常,并针对每种类型提供相应的处理逻辑。catch 块中的参数(异常对象)用于接收被抛出的异常对象,可以在其中访问异常信息。
最后一个 catch 块使用省略号(...)作为异常类型,充当通配符,可以捕获其他未被前面的 catch 块捕获到的异常。
以下是一个简单示例,展示了 try-catch 块的使用:
#include <iostream>
int divide(int a, int b) {
if (b == 0) {
throw "Divide by zero exception";
}
return a / b;
}
int main() {
try {
int result = divide(10, 0);
std::cout << "Result: " << result << std::endl;
}
catch (const char* exception) {
std::cout << "Exception caught: " << exception << std::endl;
}
return 0;
}在上述示例中,函数 divide() 尝试进行除法操作。如果除数为零,则抛出一个字符串常量作为异常。在 main() 函数中,我们使用 try-catch 块来尝试执行除法操作,并捕获并处理可能发生的异常。
输出结果将显示捕获到的异常信息:"Exception caught: Divide by zero exception"。通过这种方式,我们可以优雅地处理除以零引发的异常情况,而不是程序崩溃或产生未定义行为。
15、列举并解释STL库中常用容器,例如vector、list、map等。
STL(标准模板库)是C++的一个重要组成部分,提供了一系列常用的容器类。下面是STL库中常用的几个容器及其简单解释:
-
vector: vector 是一个动态数组,可以在运行时自动扩展和收缩大小。它以连续的内存块存储元素,支持随机访问、尾部插入和删除等操作。
-
list: list 是一个双向链表,每个节点包含指向前一个节点和后一个节点的指针。相比于 vector,list 在任意位置进行插入和删除操作更高效,但对于随机访问则较慢。
-
deque: deque(双端队列)也是一个动态数组,与 vector 类似,但支持在首尾两端进行高效插入和删除操作。
-
stack: stack 是一个后进先出(LIFO)的容器适配器,基于其他底层容器实现。它只允许在末尾进行元素插入和删除,并且只能访问最顶端的元素。
-
queue: queue 是一个先进先出(FIFO)的容器适配器,在尾部插入数据,在头部移除数据。与 stack 类似,它也基于其他底层容器实现。
-
map: map 是一种关联容器,存储一对键-值对。它根据键来进行排序和查找,具有较快的插入和删除操作。每个键在容器中是唯一的。
-
set: set 是另一种关联容器,存储唯一的值(不重复)。它自动将元素排序,并支持高效地插入、查找和删除操作。
-
unordered_map: unordered_map 是基于哈希表实现的关联容器,通过哈希函数来存储和访问元素。相比于 map,它的插入和查找操作通常更快,但不保证元素的顺序。
-
unordered_set: unordered_set 也是基于哈希表实现的集合容器,存储唯一的值并支持高效地插入、查找和删除操作。
16、STL迭代器是什么?请给出一个使用迭代器的示例。
STL(标准模板库)迭代器是一种用于遍历容器中元素的抽象概念,可以让我们以统一的方式访问容器中的元素,而不依赖于容器的具体实现。迭代器类似于指针,提供了对容器中元素的访问、遍历和操作功能。
以下是一个使用迭代器的示例,演示如何遍历并打印 vector 容器中的元素:
#include <iostream>
#include <vector>
int main() {
std::vector<int> numbers = {1, 2, 3, 4, 5};
// 使用迭代器进行遍历
std::vector<int>::iterator it; // 声明一个迭代器变量
for (it = numbers.begin(); it != numbers.end(); ++it) {
std::cout << *it << " "; // 通过解引用操作符 * 访问当前迭代位置的元素
}
std::cout << std::endl;
return 0;
}在这个示例中,我们创建了一个名为 numbers 的 vector 容器,并初始化了一些整数值。然后,我们声明了一个 std::vector<int>::iterator 类型的迭代器 it 来遍历该容器。
使用 begin() 函数获取第一个元素的迭代器,使用 end() 函数获取表示末尾位置(最后一个元素之后)的迭代器。在循环中,我们通过 *it 解引用迭代器获取当前位置的元素,并打印出来。
这样,我们就可以利用迭代器遍历容器中的元素,无论是 vector、list 还是其他容器类型都可以使用类似的方式进行遍历和操作。
17、解释C++中的命名空间(Namespace)概念及其作用。
在C++中,命名空间是一种组织代码的机制,用于防止不同代码之间的名称冲突。它提供了一种将相关的函数、类、变量等标识符分组的方式。
命名空间可以理解为一个容器,用于包含各种实体(如变量、函数、类等),并确保这些实体在整个程序中具有唯一性。通过使用命名空间,我们可以将代码模块化,并使其更易于维护和重用。
以下是命名空间的作用:
-
避免名称冲突:当多个库或模块中存在相同名称的函数、类或变量时,使用命名空间可以避免冲突,因为每个命名空间内部的标识符都是唯一的。
-
代码组织:通过将相关功能的实体放入同一个命名空间中,可以更好地组织和管理代码。这样做可以提高可读性和可维护性,并使团队协作更加简单。
-
全局声明隔离:在命名空间中定义的实体默认情况下只对该命名空间内部可见。这样可以减少全局污染,并且只有显式使用限定符才能访问特定的命名空间。
例如,我们可以创建一个命名空间来包含一些数学相关的函数和类:
namespace Math {
int add(int a, int b) {
return a + b;
}
class Calculator {
// ...
}
}然后,我们可以通过使用命名空间限定符来访问其中的实体:
int result = Math::add(2, 3);
Math::Calculator calc;这样,命名空间帮助我们将相关的功能组织在一起,并避免了名称冲突问题。
18、解释静态成员变量和静态成员函数,并提供相应代码示例。
在C++中,静态成员变量和静态成员函数是属于类的特殊成员。它们与类的实例无关,而是与整个类相关联。
静态成员变量(Static Member Variables):静态成员变量是属于类本身的变量,而不是每个对象独有的。所有该类的对象共享同一个静态成员变量的内存空间。可以通过类名加作用域运算符来访问静态成员变量,无需创建对象实例。
以下是一个示例代码:
class MyClass {
public:
static int count; // 静态成员变量
MyClass() {
count++; // 在构造函数中对静态成员变量进行操作
}
};
int MyClass::count = 0; // 静态成员变量初始化
int main() {
MyClass obj1;
MyClass obj2;
cout << "Count: " << MyClass::count << endl; // 访问静态成员变量
}输出结果为:Count: 2。这说明两个对象共享同一个静态成员变量 count,并且通过类名进行访问。
静态成员函数(Static Member Functions):静态成员函数与类相关联,而不是与具体的对象实例相关联。它们可以通过类名直接调用,无需创建对象实例,并且只能访问静态成员变量和其他静态成员函数。
以下是一个示例代码:
class MyClass {
public:
static void printCount() { // 静态成员函数
cout << "Count: " << count << endl; // 访问静态成员变量
}
private:
static int count; // 静态成员变量
};
int MyClass::count = 0; // 静态成员变量初始化
int main() {
MyClass::printCount(); // 调用静态成员函数
}输出结果为:Count: 0。通过类名直接调用静态成员函数,可以访问并操作静态成员变量。
19、请解释预处理器(Preprocessor)在C++中的作用,并举例说明其常见用法。
在C++中,预处理器(Preprocessor)是一个用于代码预处理的工具,它在编译之前对源代码进行一系列的文本替换和指令处理。预处理器指令以井号(#)开头,并且不是真正的C++代码。
预处理器的作用包括:
宏定义(Macro Definition):通过宏定义,在代码中可以使用自定义的标识符来代替一段代码或者常量值。例如:
#define PI 3.14159
#define MAX(a, b) ((a) > (b) ? (a) : (b))
int main() {
double radius = 5.0;
double area = PI * radius * radius; // 使用宏定义的常量
int x = 10;
int y = 20;
int maxNum = MAX(x, y); // 使用宏定义的函数形式
}条件编译(Conditional Compilation):根据条件判断来选择性地编译特定部分的代码。使用#ifdef、#ifndef、#if等指令可以实现条件编译。例如:
#define DEBUG_MODE
...
#ifdef DEBUG_MODE
cout << "Debug mode enabled" << endl;
#endif文件包含(File Inclusion):使用#include指令将其他文件内容包含到当前文件中。可以包含头文件、库文件等。例如:
#include <iostream> // 包含iostream头文件
int main() {
std::cout << "Hello, World!" << std::endl;
return 0;
}预定义宏(Predefined Macros):编译器预定义了一些宏,可以用来获取关于代码、系统环境等信息。例如:
#include <iostream>
int main() {
std::cout << "This is line " << __LINE__ << std::endl; // 输出当前行号
std::cout << "This file is: " << __FILE__ << std::endl; // 输出当前文件名
return 0;
}这些只是预处理器的一部分功能和常见用法,预处理器在C++中还有其他更多的应用。它能够帮助开发者在编译前对代码进行灵活的处理,提高代码的可维护性和复用性。
20、C++中如何进行文件读写操作?
在C++中进行文件读写操作通常使用<fstream>头文件提供的类和函数。以下是一些常见的文件读写操作示例:
文件写入(Write to File):
#include <fstream>
#include <iostream>
int main() {
std::ofstream outfile("example.txt"); // 创建一个输出文件流对象
if (outfile.is_open()) { // 检查文件是否成功打开
outfile << "Hello, World!" << std::endl; // 写入内容到文件
outfile.close(); // 关闭文件流
std::cout << "File written successfully." << std::endl;
} else {
std::cout << "Failed to open the file." << std::endl;
}
return 0;
}文件读取(Read from File):
#include <fstream>
#include <iostream>
#include <string>
int main() {
std::ifstream infile("example.txt"); // 创建一个输入文件流对象
if (infile.is_open()) { // 检查文件是否成功打开
std::string line;
while (std::getline(infile, line)) { // 按行读取文件内容
std::cout << line << std::endl; // 输出每一行内容
}
infile.close(); // 关闭文件流
} else {
std::cout << "Failed to open the file." << std::endl;
}
return 0;
}追加模式写入(Append Mode Write):
#include <fstream>
#include <iostream>
int main() {
std::ofstream outfile("example.txt", std::ios_base::app); // 追加模式打开文件
if (outfile.is_open()) {
outfile << "This line is appended." << std::endl; // 追加内容到文件
outfile.close();
std::cout << "File written successfully." << std::endl;
} else {
std::cout << "Failed to open the file." << std::endl;
}
return 0;
}这些示例演示了如何使用ofstream和ifstream类进行文件写入和读取操作。你可以根据需要选择适当的打开模式(例如:std::ios_base::in、std::ios_base::out、std::ios_base::binary等)来控制文件流的行为。
21、解释指针与数组之间的关系,如何通过指针遍历数组?
指针与数组之间存在紧密的关系。在C++中,数组名可以被视为指向数组首元素的指针。因此,可以通过指针来遍历数组。
以下是一个示例代码,展示了如何使用指针来遍历数组:
#include <iostream>
int main() {
int arr[] = {1, 2, 3, 4, 5}; // 定义一个整型数组
int* ptr = arr; // 将指针ptr指向数组的首元素
for (int i = 0; i < sizeof(arr) / sizeof(arr[0]); i++) {
std::cout << *ptr << " "; // 输出当前指针所指向的元素值
ptr++; // 指针向后移动一位,即指向下一个元素
}
return 0;
}在这个示例中,我们定义了一个整型数组 arr,并将指针 ptr 指向该数组的首元素。然后使用循环来遍历整个数组,并输出每个元素的值。
需要注意的是,在遍历过程中,我们通过 *ptr 来访问当前指针所指向的元素值。然后每次循环结束时,通过 ptr++ 将指针向后移动一位,即将其指向下一个元素。
通过以上方法,我们可以使用指针来方便地遍历数组,并对其中的元素进行操作。
22、列举C++中常见的排序算法,并选择一个进行实现。
-
冒泡排序 (Bubble Sort)
-
选择排序 (Selection Sort)
-
插入排序 (Insertion Sort)
-
快速排序 (Quick Sort)
-
归并排序 (Merge Sort)
-
堆排序 (Heap Sort)
从这些算法中,我选择实现插入排序算法。插入排序的基本思想是将一个元素逐个地插入到已排好序的部分中。
以下是使用C++实现插入排序的示例代码:
#include <iostream>
#include <vector>
void insertionSort(std::vector<int>& arr) {
int n = arr.size();
for (int i = 1; i < n; i++) {
int key = arr[i];
int j = i - 1;
// 将比 key 大的元素向后移动
while (j >= 0 && arr[j] > key) {
arr[j + 1] = arr[j];
j--;
}
arr[j + 1] = key;
}
}
int main() {
std::vector<int> nums = {5, 2, 8, 6, 3, 1};
std::cout << "Before sorting: ";
for(int num : nums) {
std::cout << num << " ";
}
insertionSort(nums);
std::cout << "\nAfter sorting: ";
for(int num : nums) {
std::cout << num << " ";
}
return 0;
}在上述代码中,我们使用了 std::vector 来存储待排序的数组。插入排序算法被实现在 insertionSort 函数中。通过遍历数组,我们将当前元素逐个与已排好序的部分进行比较并插入到正确的位置。
运行以上代码,你会得到以下输出:
Before sorting: 5 2 8 6 3 1
After sorting: 1 2 3 5 6 8可以看到,插入排序算法成功地对数组进行了升序排序。
23、列举并解释C++中常见的设计模式,例如单例模式、观察者模式等。
在C++中,常见的设计模式有很多,以下是其中一些常见的设计模式及其解释:
-
单例模式 (Singleton Pattern): 单例模式确保一个类只能创建一个对象,并提供全局访问点。它通常用于需要全局共享对象实例的情况,例如日志记录器、数据库连接池等。
-
观察者模式 (Observer Pattern): 观察者模式定义了一种对象间的一对多依赖关系,当一个对象的状态发生变化时,其所有依赖者都会收到通知并自动更新。这种模式被广泛应用于事件处理和发布-订阅系统中。
-
工厂模式 (Factory Pattern): 工厂模式通过定义一个公共接口来创建对象,并由子类决定实例化哪个具体类。它将对象的实例化过程封装起来,从而提供更大的灵活性和可扩展性。
-
适配器模式 (Adapter Pattern): 适配器模式将不兼容接口转换为可兼容接口,使得两个不同接口之间可以协同工作。它经常用于系统演进、旧代码重构或与第三方库进行集成等场景。
-
策略模式 (Strategy Pattern): 策略模式定义了一族算法,并将每个算法封装成独立的类,使得它们可以互相替换。通过使用策略模式,可以动态地选择、配置和切换算法,而无需修改客户端代码。
-
装饰器模式 (Decorator Pattern): 装饰器模式允许在不改变原有对象结构的情况下,通过将对象包装在装饰器对象中来动态地添加新的行为或功能。这种模式常用于扩展现有类的功能。
-
模板方法模式 (Template Method Pattern): 模板方法模式定义了一个抽象类,并将某些步骤延迟到子类中实现。它提供了一个框架或算法的蓝图,子类可以根据需要重写特定步骤以完成具体实现。
24、如何进行线程创建和同步操作?解释互斥锁和条件变量。
在C++中,可以使用标准库提供的线程相关类和同步机制来进行线程创建和同步操作。
线程创建:C++11引入了std::thread类,可以用于创建和管理线程。以下是一个简单的线程创建示例:
#include <iostream>
#include <thread>
void threadFunction() {
std::cout << "Hello from thread!" << std::endl;
}
int main() {
std::thread myThread(threadFunction); // 创建线程并指定要执行的函数
myThread.join(); // 等待线程执行完毕
return 0;
}互斥锁 (Mutex):互斥锁是一种同步原语,用于保护共享资源免受多个线程同时访问而导致的数据竞争。只有拥有互斥锁的线程才能访问被保护的共享资源。以下是一个简单示例:
#include <iostream>
#include <thread>
#include <mutex>
std::mutex mtx;
void threadFunction() {
std::lock_guard<std::mutex> lock(mtx); // 加锁
// 访问共享资源
std::cout << "Hello from thread!" << std::endl;
// 解锁发生在lock_guard对象销毁时
}
int main() {
std::thread myThread(threadFunction);
// 主线程也可以尝试加锁并访问共享资源
myThread.join();
return 0;
}条件变量 (Condition Variable):条件变量用于线程间的通信和同步。一个线程可以等待某个条件满足,而另一个线程在满足条件时发出通知。以下是一个简单示例:
#include <iostream>
#include <thread>
#include <mutex>
#include <condition_variable>
std::mutex mtx;
std::condition_variable cv;
bool condition = false;
void threadFunction()
{
std::unique_lock<std::mutex> lock(mtx);
cv.wait(lock, []{ return condition; }); // 等待条件满足
// 执行某些操作
lock.unlock();
}
int main()
{
std::thread myThread(threadFunction);
// 主线程执行一些操作
{
std::lock_guard<std::mutex> lock(mtx);
condition = true; // 修改条件
cv.notify_one(); // 发送通知唤醒等待的线程
}
myThread.join();
return 0;
}通过互斥锁和条件变量的组合使用,可以实现复杂的线程同步和通信机制,确保多个线程之间安全地共享数据并按照预期顺序执行操作。
25、什么是Lambda表达式?它有什么作用?
Lambda表达式是C++11引入的一种匿名函数形式,它可以在需要函数对象的地方使用,并且具有非常简洁和灵活的语法。Lambda表达式可以用于简化代码、提高可读性,并且在某些情况下能够替代传统的函数对象或函数指针。
Lambda表达式的基本语法如下:
[capture list](parameters) -> return_type {
// 函数体
}
-
capture list:捕获列表,用于指定lambda表达式中所使用的外部变量。
-
parameters:参数列表,与普通函数一样,在括号内指定参数名称及其类型。
-
return_type:返回类型,如果省略,则根据返回值推导。
Lambda表达式具有以下作用:
-
简化代码:Lambda表达式允许我们在需要函数对象的地方直接定义匿名函数,避免了编写额外的命名函数或类。这使得代码更加紧凑和易读。
-
方便传递和使用闭包:通过捕获列表,我们可以轻松地将外部变量引入到lambda表达式中,形成一个闭包(Closure)。这使得我们可以在lambda内部操作并共享外部作用域中的变量。
-
支持函数对象和算法:标准库中很多算法都接受可调用对象作为参数。Lambda表达式提供了一种简单方便的方式来创建这些可调用对象,从而更好地配合标准库算法使用。
26、C++11引入了哪些新特性?请列举几个重要的特性并简要解释它们。
-
Lambda表达式:Lambda表达式允许在需要函数对象的地方定义匿名函数,简化了代码,并支持捕获外部变量形成闭包。
-
自动类型推导(auto):使用auto关键字可以自动推导变量的类型,减少冗长的类型声明,提高代码可读性和灵活性。
-
智能指针:引入了shared_ptr、unique_ptr和weak_ptr等智能指针,帮助管理资源的生命周期,避免内存泄漏和悬空指针问题。
-
范围基于for循环:通过简洁明确的语法,可以更便捷地遍历容器或其他序列中的元素。
-
移动语义(移动构造函数和移动赋值运算符):通过std::move和右值引用(&&)来实现资源的高效转移,提高程序性能。
-
列表初始化和统一初始化语法:引入了大括号{}进行列表初始化,并且扩展了构造函数的使用方式,使得初始化更加简单明了。
-
线程库(std::thread):标准库中添加了线程相关的头文件和类,方便开发并发程序。
-
异常处理改进:引入了新的异常规范机制(noexcept),使异常处理更加灵活和高效。
27、解释auto关键字在C++11中的作用及其使用场景。
在C++11中,auto关键字用于自动推导变量的类型。它可以根据变量的初始化表达式来确定其类型,减少了冗长的类型声明,提高了代码的可读性和灵活性。
使用auto关键字有以下几个常见的使用场景:
1. 声明变量时进行类型推导:当初始化表达式已经明确了变量的类型时,可以使用auto来声明该变量。例如:
auto x = 10; // 推导出x为int类型
auto str = "Hello"; // 推导出str为const char*类型2. 迭代器类型推导:在使用迭代器遍历容器或序列时,可以利用auto关键字简化代码。例如:
std::vector<int> vec{1, 2, 3, 4};
for (auto it = vec.begin(); it != vec.end(); ++it) {
// 使用auto推导出迭代器类型为std::vector<int>::iterator
// ...
}3. 函数返回值类型推导:在函数定义时,可以使用auto作为返回值的占位符,在实际返回结果时根据具体情况推导出返回值的类型。例如:
auto add(int a, int b) -> decltype(a + b) {
return a + b;
}28、什么是智能指针?列举几种常见的智能指针类型,并解释其特点和适用场景。
智能指针是C++中的一个类模板,用于管理动态分配的资源(如堆上的对象),自动进行资源的释放,避免内存泄漏等问题。它们提供了一种更安全和方便的方式来操作动态分配的内存,并减少手动处理资源释放的工作。
以下是几种常见的智能指针类型及其特点和适用场景:
-
unique_ptr:unique_ptr 是独占所有权的智能指针,它保证在任意时刻只有一个 unique_ptr 指向同一个对象或者没有对象。它在析构时会自动释放所管理的资源。适用于需要独占式拥有某个资源,并希望确保只有一个指针可以访问该资源的情况。
-
shared_ptr:shared_ptr 是共享所有权的智能指针,可以多个 shared_ptr 共同拥有同一个对象,并且会对引用计数进行追踪。当最后一个 shared_ptr 被销毁时,才会自动释放所管理的资源。适用于需要多个指针共享同一个资源,并且需要灵活地增加、减少共享拥有者数量的情况。
-
weak_ptr:weak_ptr 也是一种共享所有权的智能指针,但不会增加引用计数。weak_ptr 可以被用来解决 shared_ptr 的循环引用问题。适用于需要共享资源,但又希望避免循环引用导致的资源无法释放的情况。
-
auto_ptr(在C++11中已被废弃):auto_ptr 是一种独占所有权的智能指针,类似于 unique_ptr,但它具有不完善的拷贝和赋值语义,并且存在一些潜在的问题。建议使用 unique_ptr 替代 auto_ptr。
这些智能指针类型都是通过 RAII(资源获取即初始化)技术实现的,在对象生命周期结束时自动释放所管理的资源。正确使用智能指针可以大大减少内存泄漏和悬挂指针等错误,并提高代码的可靠性和安全性。
29、C++异常处理机制允许抛出任意类型的异常吗?为什么?
C++异常处理机制允许抛出任意类型的异常。这是因为在C++中,异常是通过抛出和捕获特定类型的对象来实现的,而不限于特定的基本类型或预定义的异常类型。这种设计灵活性给予了程序员更大的自由度,可以根据具体情况选择合适的异常类型。
当发生错误或异常情况时,我们可以创建自定义的异常类,并将其实例作为异常对象抛出。通过使用自定义异常类,我们可以传递更多有关错误/异常信息的上下文,并提供更好的代码可读性和维护性。
同时,C++也提供了一些预定义的异常类(如 std::exception 及其子类),用于处理常见的错误情况。这些预定义的异常类既可以直接使用,也可以通过继承并添加额外信息来创建自定义异常类。
30、请解释动态绑定(Dynamic Binding)的概念及其作用。
动态绑定(Dynamic Binding),也称为运行时多态性,是面向对象编程中的一个重要概念。它指的是在程序运行时根据实际对象的类型来确定调用哪个方法或函数的过程。
具体而言,在使用动态绑定时,如果基类定义了一个虚函数,并且派生类对该虚函数进行了重写(覆盖),那么在通过基类指针或引用调用该函数时,将根据实际对象的类型来决定执行哪个版本的函数。
这种机制的作用在于提供了多态性和灵活性。通过动态绑定,可以让程序在不同对象上表现出不同的行为,同时允许通过统一的接口对不同类型的对象进行操作。这有助于编写更加可扩展和可复用的代码,使得代码更具灵活性和适应性。


![概率中的50个具有挑战性的问题[02/50]:连续获胜](https://img-blog.csdnimg.cn/img_convert/fab2aae23fd92fec5d5018ff37b32af2.png)
![[c]扫雷](https://img-blog.csdnimg.cn/img_convert/b1a6522aec2533493b917d7ee6d245cd.png)