大模型系统优化:怎么计算模型所需的算力、内存带宽、内存容量和通信数据量?
- 大模型需要多少算力?
- 大模型需要几块GPU?
- 预训练、领域微调区别?
- 预训练需要多少数据?
- 怎么做数据去重?
- 怎么做数据增强?
- 训练多少epochs?
- 推理和训练的区别?
- 怎么计算通信数据量?
- 中文训练数据去哪里找?
- 通用数据
- 多模态数据
- 预训练数据集
- RLHF 强化数据集
- 数学微调数据
- 代码微调数据
- 对话微调数据
- 医学开源数据
- 中文医疗数据集
- 通用SFT数据集
- 中文指令Guanaco数据集
- 多轮对话数据集
- Reward Model数据集
- 通用指令微调数据
- 大模型评估数据集
- 通用知识评估 (General Knowledge Evaluation)
- 推理能力评估 (Reasoning Evaluation)
- 编程能力评估 (Coding Evaluation)
- 安全性评估 (Safety Evaluation)
- 开放集基准 (Open-set Benchmarks)
- 评估方法和评分系统 (Evaluation Methods and Scoring Systems)
- 基于人的评估 (Human-based Evaluation)
- 大型语言模型作为评估者 (Large Language Models as Evaluators)
大模型需要多少算力?
需要的总算力 = 6 ∗ * ∗ 模型的参数量 ∗ * ∗ 训练数据的 token 数
我们可以把神经网络想象成由左边一组神经元和右边一组神经元组成的完全二分图。
- 因为其中的每一层的神经元与相邻层的所有神经元相连,但同层内的神经元之间没有连接。
- 就像一个有规则的接力赛,每个跑步的小朋友(神经元)只能把接力棒(信息)传给下一排的小朋友,而不能传给自己这一排的其他人。
选出其中任意一个左边的神经元 l l l 和右边的神经元 r r r:
- 正向传播:
- 左边的神经元 l l l 将其输出 * 与其连接的权重 w w w,并将结果发送给右边的神经元 r r r。
- 右边的神经元 r r r 通常连接多个左边的神经元,因此需要将收到的多个 l l l 的输出进行求和操作。
- 反向传播:
- 右边的神经元 r r r 将收到的梯度 * 与其连接的权重 w w w,并将结果发送给左边的神经元 l l l。
- 左边的神经元 l l l 也通常连接多个右边的神经元,因此需要将收到的多个 r r r 的梯度进行求和操作,并计算权重 w w w 的梯度。
- 最后,权重 w w w 的更新需要将一个批次中所有样本的梯度进行求和。
总共涉及到 3 3 3 次乘法和 3 3 3 次加法的计算操作。
大模型是数据的压缩版本:
- 模型的参数量太小,就吃不下训练数据里面所有的知识
- 模型的参数量如果大于训练数据的 token 数,容易导致过拟合。
大模型需要几块GPU?

预训练、领域微调区别?
区别:
- 从随机权重开始学习,从海量数据中枚举出人类的语言、逻辑、情感范式(像人),用参数保存这种范式(微调学习的是专业领域的知识、回答范式)
- 喂的是整个文档,一字不落的学习(微调基本是一问一答,因为应用场景是问答型的)
- 预训练就像学校的基础功课,微调就像课外辅导
预训练需要多少数据?
openai提出最优训练数据和模型参数配比:
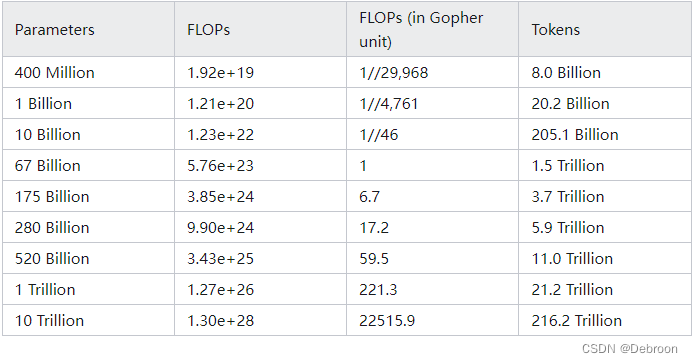
比如模型参数 1 B(1B = 10亿参数),最优的训练数据量是 20.2 B 的 token。
怎么做数据去重?
请猛击:MinHash-LSH 大规模数据去重优化
怎么做数据增强?
采用前沿对齐,低资源收集技术:
- 自驱、蒸馏方法 + 同行大模型,获取高质量数据集
- 数据增强:深化、异化扩展多样性
- 引入explanation tuning和逐步解释数据:激发模型性能
训练多少epochs?
论文地址:https://arxiv.org/pdf/2305.13230.pdf
在CNN、Vit 这样的模型中,模型训练的epochs可高达300次,而大语言模型的训练 epochs 通常都是 1-4 次。
用重复的tokens训练大语言模型会让模型降低性能。
模型参数规模的增长与模型需要的tokens数量基本是呈线性:

推理和训练的区别?
训练需要存储模型参数、存储梯度、优化器状态、正向传播每一层的中间状态,后面几个比参数更大,对模型内存的需求量也更大。
推理的各个输入数据之间并没有关系,不需要存储梯度和优化器状态,正向传播每一层的中间状态也不需要保存下来。
大模型的训练用 4090 是不行的,但推理用 4090 不仅可行,在性价比上还能比 H100 稍高。
4090 如果极致优化,性价比甚至可以达到 H100 的 2 倍。
H100 和 4090 最大的区别就在通信和内存上,算力差距不大。
- 通信带宽:H100 是 4090 的 16倍
- 通信时延:H100 是 4090 的 10分之1
- 内存带宽:H100 是 4090 的 3倍
怎么计算通信数据量?
计算通信数据量的目标是确定在多GPU环境中,数据在不同GPU之间传输时的总量。
在分布式训练或使用多GPU训练时,需要考虑通信开销。通信数据量依赖于:
- 分布式策略(如数据并行、模型并行、流水线并行等)
- 同步频率(每个batch、每个epoch等)
- 模型参数的大小
- 数据的大小(数据并行时)。
例如,在数据并行中,每次同步时,每个GPU需要发送其梯度到其他GPU或参数服务器,所以通信数据量大约为 梯度大小乘以GPU数量。
例如,在张量并行中,分布式计算场景,其中包含了多个注意力头,每个头处理一部分数据,并且有必要在GPU之间交换信息以合成最终的结果。
以下是一个简化的方法来估算通信数据量:
首先,我们需要确定每个GPU需要发送或接收的数据量。
这通常涉及到输入和输出矩阵的大小,以及模型的结构。
假设我们有:
- Batch size: ( B )
- Token长度: ( T )
- Embedding size: ( E )
- Attention heads数量: ( H )
- Key和Value的维度(通常等于 ( E H \frac{E}{H} HE )): ( D k = D v = E H ( D_k = D_v = \frac{E}{H} (Dk=Dv=HE )
- 每个参数的字节大小(例如,如果参数是 32 位浮点数,那么字节大小为 4): ( b y t e s p a r a m ) ( bytes_{param} ) (bytesparam)
- GPU数量: ( G )
在多头注意力机制中,每个头计算得到一个输出矩阵 ( Z h e a d ) ( Z_{head} ) (Zhead),大小为 ( B × T × E H ) ( B \times T \times \frac{E}{H} ) (B×T×HE)。
对于所有头,输出矩阵 ( Z ) ( Z ) (Z) 的大小是所有 ( Z h e a d ) ( Z_{head} ) (Zhead) 拼接起来的,因此大小为 ( B × T × E ) ( B \times T \times E ) (B×T×E)。
如果每个GPU处理 ( H G ) ( \frac{H}{G} ) (GH) 个头,那么每个GPU计算得到的 ( Z h e a d ) ( Z_{head} ) (Zhead) 的总大小将是:
[ Z_{GPU} = B \times T \times \frac{E}{H} \times \frac{H}{G} = B \times T \times \frac{E}{G} ]
通信发生在每个GPU需要汇总所有其他GPU上计算的 ( Z h e a d ) ( Z_{head} ) (Zhead)时。
假设每个GPU都需要从其他 ( G − 1 ) ( G - 1 ) (G−1) 个GPU接收数据以构建完整的输出矩阵( Z )。
那么每个GPU需要接收的数据量大概是:
[ D a t a r e c v = Z G P U × ( G − 1 ) = B × T × E G × ( G − 1 ) ] [ Data_{recv} = Z_{GPU} \times (G - 1) = B \times T \times \frac{E}{G} \times (G - 1) ] [Datarecv=ZGPU×(G−1)=B×T×GE×(G−1)]
同样,每个GPU需要发送它计算的 ( Z G P U ) ( Z_{GPU} ) (ZGPU) 给其他( G - 1 )个GPU:
[ D a t a s e n d = Z G P U × ( G − 1 ) = B × T × E G × ( G − 1 ) ] [ Data_{send} = Z_{GPU} \times (G - 1) = B \times T \times \frac{E}{G} \times (G - 1) ] [Datasend=ZGPU×(G−1)=B×T×GE×(G−1)]
因此,每个GPU的总通信量(发送加接收)将是:
[ D a t a t o t a l = D a t a r e c v + D a t a s e n d = 2 × Z G P U × ( G − 1 ) ] [ Data_{total} = Data_{recv} + Data_{send} = 2 \times Z_{GPU} \times (G - 1) ] [Datatotal=Datarecv+Datasend=2×ZGPU×(G−1)]
把 ( Z G P U ) ( Z_{GPU} ) (ZGPU) 代入:
[ D a t a t o t a l = 2 × B × T × E G × ( G − 1 ) ] [ Data_{total} = 2 \times B \times T \times \frac{E}{G} \times (G - 1) ] [Datatotal=2×B×T×GE×(G−1)]
最后,我们需要把每个参数的大小也考虑进去,所以总的通信数据量(以字节为单位)是:
[ D a t a b y t e s = D a t a t o t a l × b y t e s p a r a m = 2 × B × T × E G × ( G − 1 ) × b y t e s p a r a m ] [ Data_{bytes} = Data_{total} \times bytes_{param} = 2 \times B \times T \times \frac{E}{G} \times (G - 1) \times bytes_{param} ] [Databytes=Datatotal×bytesparam=2×B×T×GE×(G−1)×bytesparam]
这就是在所有GPU之间总共需要传输的数据量。
如果你想要单向通信的数据量,只需要使用 ( D a t a r e c v ) ( Data_{recv} ) (Datarecv) 或 ( D a t a s e n d ) ( Data_{send} ) (Datasend) 的值乘以 ( b y t e s p a r a m ) ( bytes_{param} ) (bytesparam) 即可。
中文训练数据去哪里找?
通用数据
- AI 开源数据社区:opendatalab.org.cn
- DuReader 数据集: 200K 问题、420K 答案组成,迄今为止最大的中文 MRC 数据集,基于百度搜索和百度知道
- WuDaoCorpora 数据集:用 20 多种规则从 100TB 原始网页数据中清洗得出最终数据集,注重隐私数据信息的去除
- CLUECorpus2020 数据集:有 100G 的原始语料库,包含 350 亿个汉字
- DRCD 数据集:传统中文机器阅读理解数据集,包含来自 2108 篇维基百科文章的 10014 个段落和由注释者生成的33,941 个问答对
- E-KAR 数据集:包含来自公务员考试的 1,655 个(中文)和 1,251 个(英文)问题,这些问题需要深入的背景知识才能解决
- Douban Conversation Corpus 数据集:豆瓣会话语料库,包含 1000 个对话上下文
- ODSQA 数据集:用于中文问答的口语数据集 MATINF 数据集:用于中文母婴护理领域的分类、问答和总结
多模态数据
- WuDaoMM 数据集、MUGE 数据集、 Noah-Wukong 数据集
- Zero 数据集、 COCO-CN 数据集、 Flickr8k-CN & Flickr30k-CN 数据集
- Product1M 数据集、 AI Challenger 图像中文描述数据集
预训练数据集
-
RedPajama开源的复刻llama的预训练数据集,1.21万亿Token
-
news-commentary 中英平行语料,用于中英间知识迁移: https://data.statmt.org/news-commentary/v15/training/
-
MNBVC 对标ChatGPT的40T:https://github.com/esbatmop/MNBVC
-
Pile 基于RedPajama进行清洗去重后得到的高质量数据集 6270亿Token:https://huggingface.co/datasets/cerebras/SlimPajama-627B/tree/main/train
-
CSL 首个中文科学文献数据集CSL,也有多种NLP任务数据:https://github.com/ydli-ai/CSL
RLHF 强化数据集
-
问答偏好数据集:https://huggingface.co/datasets/liyucheng/zhihu_rlhf_3k
-
OpenAssistant Conversations:https://huggingface.co/datasets/OpenAssistant/oasst1
-
河狸开源RLHF:https://huggingface.co/datasets/PKU-Alignment/PKU-SafeRLHF-10K
-
Anthropic hh-rlhf:https://huggingface.co/datasets/Anthropic/hh-rlhf
-
Facebook Bot Adversarial Dialogues:https://github.com/facebookresearch/ParlAI
-
AllenAI Real Toxicity prompts:https://github.com/facebookresearch/ParlAI
-
Stack-exchange:https://huggingface.co/datasets/HuggingFaceH4/stack-exchange-preferences/tree/main
-
hh-rlhf:https://huggingface.co/datasets/liswei/rm-static-zhTW
数学微调数据
-
AMC竞赛数学题:https://huggingface.co/datasets/competition_math
-
猿辅导开源小学应用题:https://github.com/SCNU203/Math23k/tree/main
-
APE210k腾讯爬取的数学问题:https://github.com/Chenny0808/ape210k
-
线性代数等纯数学计算题:https://huggingface.co/datasets/math_dataset
-
有推理过程和多项选择的数学问答数据集:https://huggingface.co/datasets/math_qa/viewer/default/test?row=2
-
高中数学题2-8步推理过程:https://huggingface.co/datasets/qwedsacf/grade-school-math-instructions
代码微调数据
-
Conala来自StackOverflow问题:https://opendatalab.org.cn/CoNaLa/download
-
code-alpacaGPT生成:https://github.com/sahil280114/codealpaca.git
-
APPS编程网站收集:https://opendatalab.org.cn/APPS
-
Lyra Python操作数据库:https://opendatalab.org.cn/Lyra
对话微调数据
-
LAION:https://github.com/LAION-AI/Open-Instruction-Generalist
-
Ultra Chat 俩个gpt对话:https://github.com/thunlp/UltraChat
-
Baize:https://github.com/project-baize/baize-chatbot/tree/main/data
-
InstructDial:https://github.com/prakharguptaz/Instructdial
-
BlenderBot:https://huggingface.co/datasets/blended_skill_talk
-
Awesome Open-domain Dialogue Models:https://github.com/cingtiye/Awesome-Open-domain-Dialogue-Models#%E4%B8%AD%E6%96%87%E5%BC%80%E6%94%BE%E5%9F%9F%E5%AF%B9%E8%AF%9D%E6%95%B0%E6%8D%AE%E9%9B%86
-
SODA:https://realtoxicityprompts.apps.allenai.org/
医学开源数据
- 中文医学命名实体识别CMedEE
- 中文医学文本实体关系抽取CMedIE
- 临床术语标准化任务CHIP-CDN
- 临床试验筛选标准短文本分类CHIP-CTC
- 平安医疗科技疾病问答迁移学习CHIP-STS
- 医疗搜索检索词意图分类KUAKE-QIC
- 医疗搜索查询词—页面标题相关性KUAKE-QTR
- 医疗搜索查询词—查询词相关性KUAKE-QQR
- 中文医学命名实体识别CMedEE
- 中文医学文本实体关系抽取CMedIE
- 临床术语标准化任务CHIP-CDN
- 临床试验筛选标准短文本分类CHIP-CTC
- 平安医疗科技疾病问答迁移学习CHIP-STS
- 医疗搜索检索词—意图分类KUAKE-QIC
- 医疗搜索查询词—页面标题相关性KUAKE-QTR
- 医疗搜索查询词—查询词相关性KUAKE-QQR
- 医疗搜索查询词—相关性检索KUAKE-IR
- 阴阳性实体判别CHIP-MDCFNPC
- 对话实体抽取IMCS-V2-NER
- 意图标签分类IMCS-V2-DAC
- 智能诊疗对话症状识别IMCS-V2-SR
- 诊疗报告生成IMCS-V2-MRG
- 医疗对话生成MedDG
- MedDialog-CN https://github.com/UCSD-AI4H/Medical-Dialogue-System
- IMCS-V2 https://github.com/lemuria-wchen/imcs21
- CHIP-MDCFNPC https://tianchi.aliyun.com/dataset/95414
- MedDG https://tianchi.aliyun.com/dataset/95414
- cMedQA2 https://github.com/zhangsheng93/cMedQA2
- Toyhom https://github.com/Toyhom/Chinese-medical-dialogue-data
- michaelwzhu/ChatMed-Consult michaelwzhu/ChatMed-Consult · Hugging Face
- Huatuo-26M https://github.com/FreedomIntelligence/Huatuo-26M
- Medical https://huggingface.co/datasets/shibing624/medical
- 复旦DISC-MedLLM https://github.com/FudanDISC/DISC-MedLLM
- DoctorGLM https://zhuanlan.zhihu.com/p/657058443
- MedicalGPT https://zhuanlan.zhihu.com/p/657058443
- ChatMed:https://zhuanlan.zhihu.com/p/657058443
- MedQA-ChatGLM:https://zhuanlan.zhihu.com/p/657058443
- 神农中医药大模型:https://zhuanlan.zhihu.com/p/657058443
- 70B医学大模型:https://huggingface.co/datasets/epfl-llm/guidelines
- 澳门理工caregpt:https://github.com/WangRongsheng/CareGPT
以下是整理后的中文和英文医疗、对话以及Reward数据集列表,包括数据集的名称、链接和数据条目数:
中文医疗数据集
- 240万条中文医疗数据集(包括预训练、指令微调和奖励数据)
- 链接: huggingface.co/datasets/hinf24/medical
- 22万条中文医疗对话数据集(华伦项目)
- 链接: huggingface.co/datasets/FreedomIntelligence/uatuoGPT-sh-da
通用SFT数据集
- 50万条中文ChatGPT指令Belle数据集
- 链接: huggingface.co/datasets/BelleGroup/rain_0.5M_CN
- 100万条中文ChatGPT指令Belle数据集
- 链接: huggingface.co/datasets/BelleGroup/train_1M_CN
- 5万条英文ChatGPT指令Alpaca数据集
- 链接: github.com/tsu-lab/stanford-alpaca
- 2万条中文ChatGPT指令Alpaca数据集
- 链接: huggingface.co/datasets/shibing624/alpaca-ch
中文指令Guanaco数据集
- 69万条中文指令Guanaco数据集(Belle50万条 + Guanaco19万条)
- 链接: huggingface.co/datasets/ChineseVicuna/guanaco_belle_merge_v1.0
多轮对话数据集
- 5万条英文ChatGPT多轮对话数据集
- 链接: huggingface.co/datasets/RyokoAI/ShareGPT52K
- 80万条中文ChatGPT多轮对话数据集
- 链接: huggingface.co/datasets/BelleGroup/multiturn_chat_0.8M
- 116万条中文ChatGPT多轮对话数据集
- 链接: huggingface.co/datasets/fmip/mss-002-sh-da
Reward Model数据集
- 原版的oasst1数据集
- 链接: huggingface.co/datasets/OpenAssistant/oasst1
- 2万条多语言oasst1的reward数据集
- 链接: huggingface.co/datasets/tasksource/oasst1_pairwise_rlhf_reward
- 11万条英文hh-rlhf的reward数据集
- 链接: huggingface.co/datasets/Dahoas/full-hh-rlhf
- 9万条英文reward数据集(来自Anthropic的Helpful Harmless dataset)
- 链接: huggingface.co/datasets/Dahoas/static-hhl
- 7万条英文reward数据集(来源同上)
- 链接: huggingface.co/datasets/Dahoas/rm-static
- 7万条繁体中文的reward数据集(翻译自mo-static)
- 链接: huggingface.co/datasets/swei/rm-static-mm10-h
- 万条英文Reward数据集
- 链接: huggingface.co/datasets/yitingxie/rlhf-reward-datasets
- 3千条中文知乎问答偏好数据集
- 链接: huggingface.co/datasets/liyucheng/zhihu_rlhf_3k
通用指令微调数据
-
self-instruct:https://github.com/yizhongw/self-instruct
-
Standford Alpaca:https://github.com/tatsu-lab/stanford_alpaca
-
GPT4-for-LLM:https://github.com/Instruction-Tuning-with-GPT-4/GPT-4-LLM
-
中文翻译Alpaca:https://github.com/hikariming/alpaca_chinese_dataset https://github.com/carbonz0/alpaca-chinese-dataset
-
Guanaco数据:https://huggingface.co/datasets/JosephusCheung/GuanacoDataset
-
Vicuna:https://github.com/domeccleston/sharegpt https://huggingface.co/datasets/anon8231489123/ShareGPT_Vicuna_unfiltered/tree/main
-
MOSS:https://huggingface.co/datasets/Hello-SimpleAI/HC3-Chinese/tree/main
-
PromptCLUE:https://github.com/CLUEbenchmark/pCLUE
-
P3:https://huggingface.co/datasets/bigscience/P3
-
alpaca COT:https://github.com/PhoebusSi/Alpaca-CoT
-
中文写作:https://github.com/yangjianxin1/Firefly
-
CSL:https://github.com/ydli-ai/CSL
-
GPTTeacher:https://github.com/teknium1/GPTeacher/tree/main
-
alpaca:https://github.com/Instruction-Tuning-with-GPT-4/GPT-4-LLM/tree/main
-
OIG:https://github.com/BAAI-Zlab/COIG
-
HC3:https://huggingface.co/datasets/Hello-SimpleAI/HC3-Chinese/tree/main
-
InstructWild:https://github.com/XueFuzhao/InstructionWild/tree/main/data
-
BELLE:https://github.com/LianjiaTech/BELLE
-
TK-Instruct:https://instructions.apps.allenai.org/
-
Unnatural Instruction:https://github.com/orhonovich/unnatural-instructions
-
xmtf:https://github.com/bigscience-workshop/xmtf
-
Amazon COT:https://github.com/amazon-science/auto-cot
-
alpaca code 20K:https://github.com/sahil280114/codealpaca#data-release
-
GPT4指令+角色扮演+代码指令:https://github.com/teknium1/GPTeacher
-
Mol-Instructions 2043K :https://github.com/zjunlp/Mol-Instructions
大模型评估数据集
根据功能和用途,以下是各类基准测试和评估方法的分类整理,包括它们的简介和相关链接:
通用知识评估 (General Knowledge Evaluation)
-
MMLU (Measuring Massive Multitask Language Understanding): 测试模型在涵盖数百个任务的广泛领域的理解能力。
Link -
C-MMLU (Measuring massive multitask language understanding in Chinese): MMLU的中文版本,评估中文大型语言模型在多任务上的理解。
Link -
C-Eval (A Multi-Level Multi-Discipline Chinese Evaluation Suite for Foundation Models): 专注于中文的多级别、多学科评估套件,旨在测试基础模型的能力。
Link -
KoLA (Carefully Benchmarking World Knowledge of Large Language Models): 旨在详尽测试大型语言模型对世界知识的理解和记忆。
Link -
M3KE (A Massive Multi-Level Multi-Subject Knowledge Evaluation Benchmark for Chinese Large Language Models): 用于评估中文大型语言模型在多个层次和科目上的知识。
Link -
AGIEval (A Human-Centric Benchmark for Evaluating Foundation Models): 以人为中心的评估基准,用于检验基础模型在多个维度上的性能。
Link
推理能力评估 (Reasoning Evaluation)
-
GSM8K (Training Verifiers to Solve Math Word Problems): 包含8000个数学问题,测试模型的问题解决能力。
Link -
Maths (Measuring Mathematical Problem Solving With the MATH Dataset): 使用MATH数据集来测量数学问题解决能力。
Link -
CSQA (COMMONSENSEQA: A Question Answering Challenge Targeting Commonsense Knowledge): 测试模型在常识知识方面的问答能力。
Link -
StrategyQA (Did Aristotle Use a Laptop? A Question Answering Benchmark with Implicit Reasoning Strategies): 测试模型在处理需要隐式推理策略的问题的能力。
Link
编程能力评估 (Coding Evaluation)
-
MBPP (Program Synthesis with Large Language Models): 用于测试大型语言模型在程序合成方面的能力。
Link -
DS-1000 (A Natural and Reliable Benchmark for Data Science Code Generation): 为数据科学代码生成提供一个自然且可靠的基准。
Link -
HumanEval (Evaluating Large Language Models Trained on Code): 评估在代码上训练的大型语言模型。
Link
安全性评估 (Safety Evaluation)
-
Safety-Prompts: 评估中文大型语言模型的安全性。
Link -
CValues (Measuring the Values of Chinese Large Language Models from Safety to Responsibility): 从安全性到责任性,测量中文大型语言模型的价值观。
Link
开放集基准 (Open-set Benchmarks)
-
Vicuna-80 (Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90% ChatGPT Quality)*: 一个开源的聊天机器人,其质量接近GPT-4级别。
Link -
Open-Assistant-953 (OpenAssistant Conversations – Democratizing Large Language Model Alignment): 旨在民主化大型语言模型校准过程的对话数据集。
Link
评估方法和评分系统 (Evaluation Methods and Scoring Systems)
-
LLMs Bias in Evaluation: 探讨大型语言模型在评估过程中的偏见问题。
Link -
Multi-Elo (Evaluation Biases for Large Language Models): 分析大型语言模型评估中的偏差。
Link -
Reference-Free Evaluation: 不依赖参考答案的评估方法,更多依赖模型的自我评估。
Link
基于人的评估 (Human-based Evaluation)
-
Ordinal Classification: 一种基于序数分类的评估方法。
Link -
Pairwise Comparison: 通过成对比较训练语言模型以遵循指令。
Link
大型语言模型作为评估者 (Large Language Models as Evaluators)
- PandaLM (PandaLM: An Automatic Evaluation Benchmark for LLM Instruction Tuning Optimization): 用于评估大型语言模型指令调优优化的自动评估基准。
Link
请注意,以上链接和介绍是根据您提供的信息整理的,并且可能包含一些重复的链接。此外,由于我的知识截止日期是2023年4月,一些链接或信息可能已经有所更新或更改。