文章目录
- 统计语言模型和神经网络语言模型
- 注意力机制和Bert
- 实战Bert
- 配置环境和模型转换
- 格式准备
- 模型构建
- 网络设计
- 模型配置
- 代码实战
统计语言模型和神经网络语言模型
区别:统计语言模型的本质是基于词与词共现频次的统计,而神经网络语言模型则是给每个词赋予了向量空间的位置作为表征,从而计算它们在高维连续空间中的依赖关系。
相对来说,神经网络的表示以及非线性映射,更加适合对自然语言进行建模。
注意力机制和Bert
Attention is all you need 是关于注意力机制最经典的论文,它是机制,准确来说,不是一个算法,而是一个构建网络的思路。
其实 Attention 机制要做:找到最重要的关键内容。它对网络中的输入(或者中间层)的不同位置,给予了不同的注意力或者权重,然后再通过学习,网络就可以逐渐知道哪些是重点,哪些是可以舍弃的内容了。
BERT 的全称是 Bidirectional Encoder Representation from Transformers,即双向 Transformer 的 Encoder。作为一种基于 Attention 方法的模型,它最开始出现的时候可以说是抢尽了风头,在文本分类、自动对话、语义理解等十几项 NLP 任务上拿到了历史最好成绩。BERT 的理论框架主要是基于论文《Attention is all you need》中提出的 Transformer,而后者的原理则是刚才提到的 Attention。
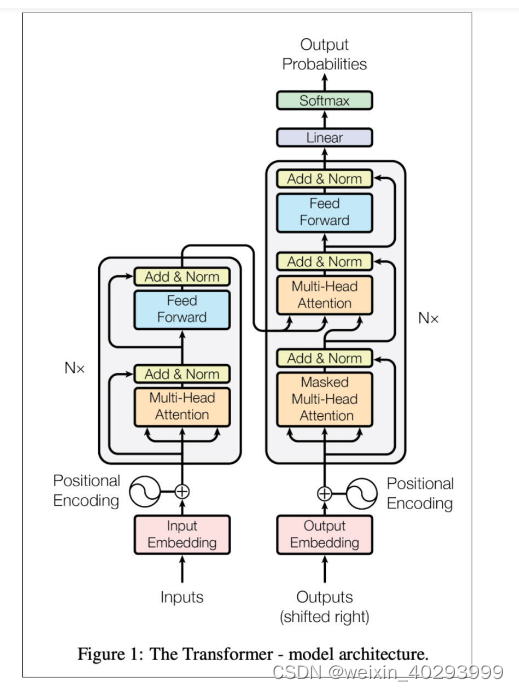
结合上图我们要注意的是,BERT 采用了基于 MLM 的模型训练方式,即 Mask Language Model。因为 BERT 是 Transformer 的一部分,即 encoder 环节,所以没有 decoder 的部分(其实就是 GPT)。
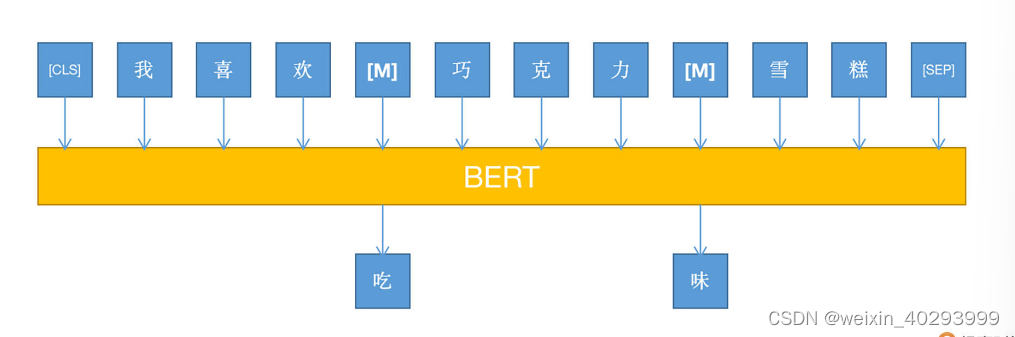
用过 Word2Vec 的小伙伴应该比较清楚,在 Word2Vec 中,对于同一个词语,它的向量表示是固定的,这也就是为什么会有那个经典的“国王-男人+女人=皇后”的计算式了,但有个问题,“苹果”可能是水果,也可能是手机品牌。如果还是用同一个向量表示,就有偏差了,而BERT可以根据上下文的不同,对同一个token给出的词向量是动态变化的,很灵活。
实战Bert
配置环境和模型转换
安装hugging face的Pytorch版本的Transformers包
pip install Transformers
ref:https://github.com/huggingface/transformers

找到这里面很重要的两个文件:
convert_BERT_original_tf_checkpoint_to_PyTorch.py 和 modeling_BERT.py
第一个是将tf2的模型转成pytorch版的
第二个是给咱一个BERT的使用案例
选一个预训练模型Pre-trained Models
ref:https://github.com/google-research/bert
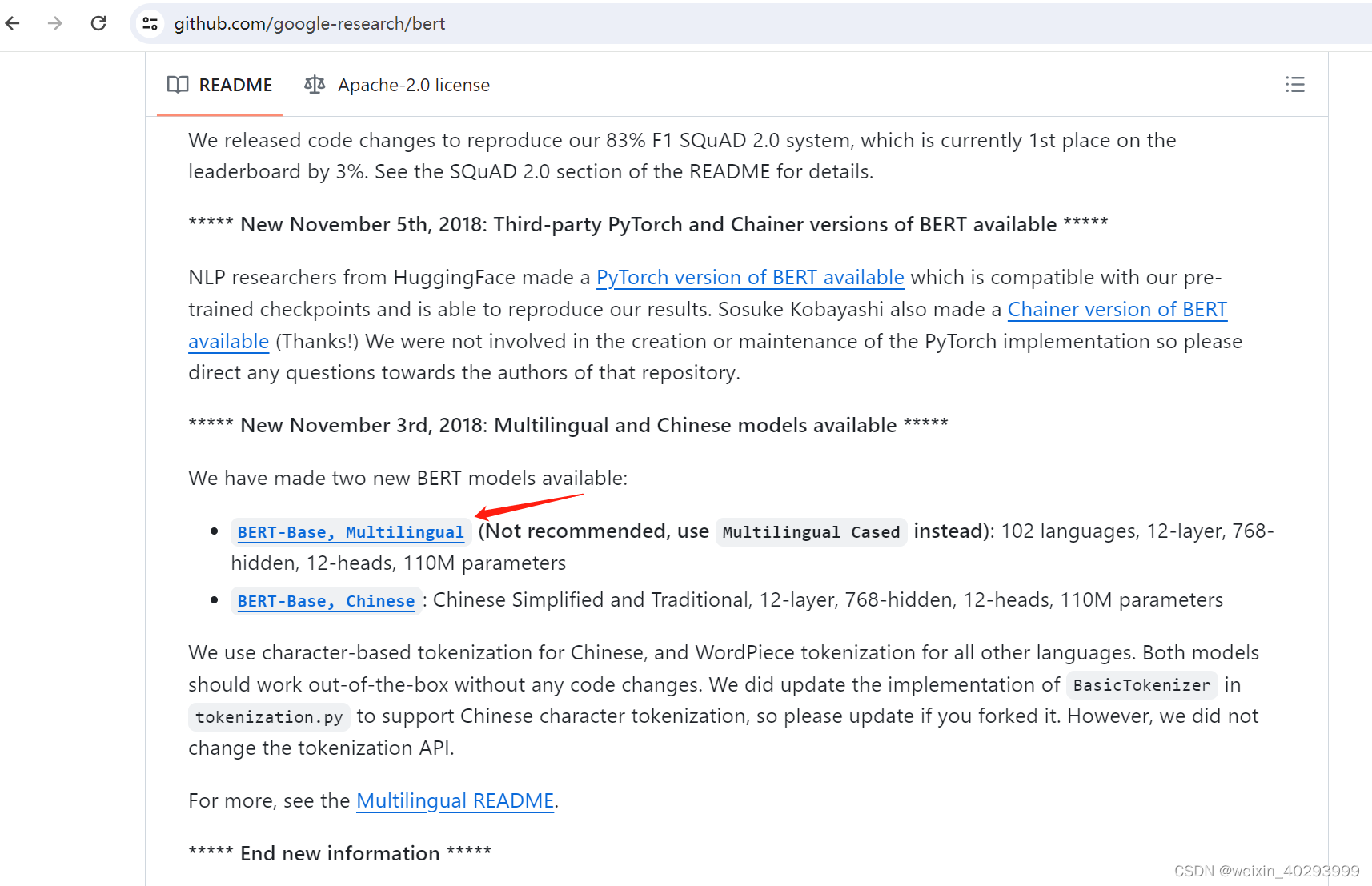
102 languages, 12-layer, 768-hidden, 12-heads, 110M parameters
模型转换:
python convert_tf_checkpoint_to_pytorch.py --tf_checkpoint_path D:\code\python_project\01mlforeveryone\multilingual_L-12_H-768_A-12\multilingual_L-12_H-768_A-12\bert_model.ckpt --bert_config_file D:\code\python_project\01mlforeveryone\multilingual_L-12_H-768_A-12\multilingual_L-12_H-768_A-12\bert_config.json --pytorch_dump_path bert/pytorch_model.bin
转换成功
confiig.json BERT模型的配置文件,记录了所有用于训练的参数设置
PyTorch_model.bin 模型文件
vocab.txt 词表文件 用于识别所支持语言的字符、字符串或者单词
格式准备
输入的数据不能是直接把词输入到模型,需要转换成三种向量:
- Token embeddings: 词向量, [CLS] 开头,用于文本分类等任务
- Segment embeddings: 将两句话进行区分,比如问答任务,问句和答句同时输入,这就需要能够区分两句话的操作。
- Position embeddings 单词的位置信息
模型构建
我们来搭建一个基于BERT的文本分类网络模型,包括:网络的设计、配置、以及数据准备。
网络设计
modeling_BERT.py 文件作者已经给我们提供了很多种类的NLP任务代码。
其中“BERTForSequenceClassification”, 这个分类网络我们可以直接使用,它是最基本的BERT文本分类的流程。
模型配置
config.json
id2label: 类别标签和类别名称的映射关系
label2id:类别名称和列表标签的映射关系
num_labels_cate:类别的数量
修改方式见这里
ref:https://blog.csdn.net/qsx123432/article/details/126159843
ref:https://blog.csdn.net/weixin_42223207/article/details/125024596
代码实战
import numpy as np
import torch
from transformers import BertTokenizer, BertConfig, BertForMaskedLM, BertForNextSentencePrediction
from transformers import BertModel
model_name = "./bert/bert-base-chinese/"
MODEL_PATH = "D:/code/python_project/01mlforeveryone/bert/bert-base-chinese/"
#### 'bert-base-chinese': "https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-chinese-pytorch_model.bin",
#### 'bert-base-chinese': "https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-chinese-config.json",
#### 'bert-base-chinese': "https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-chinese-vocab.txt",
# a. 通过词典导入分词器
tokenizer = BertTokenizer.from_pretrained(model_name)
# b.导入配置文件
model_config = BertConfig.from_pretrained(model_name)
# 修改配置
model_config.output_hidden_states = True
model_config.output_attentions = True
# 通过配置和路径导入模型
bert_model = BertModel.from_pretrained(MODEL_PATH, config = model_config)
print(tokenizer.encode('吾儿莫慌')) # [101, 1434, 1036, 5811, 2707, 102]
sen_code = tokenizer.encode_plus('这个故事没有终点', "正如星空没有彼岸")
print(sen_code)
"""
{'input_ids': [101, 100, 100, 100, 100, 100, 100, 100, 100, 102, 100, 100, 100, 100, 100, 100, 100, 100, 102], 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
"""
# 将input_ids转化回token:
print(tokenizer.convert_ids_to_tokens(sen_code['input_ids']))
"""
['[CLS]', '这', '个', '故', '事', '没', '有', '终', '点', '[SEP]', '正', '如', '星', '空', '没', '有', '彼', '岸', '[SEP]']
"""
# 将分词输入模型,得到编码:
# 对编码进行转换,以便输入Tensor
tokens_tensor = torch.tensor([sen_code['input_ids']]) # 添加batch维度并,转换为tensor,torch.Size([1, 19])
segments_tensors = torch.tensor(sen_code['token_type_ids']) # torch.Size([19])
bert_model.eval()
# 进行编码
with torch.no_grad():
outputs = bert_model(tokens_tensor, token_type_ids = segments_tensors)
encoded_layers = outputs # outputs类型为tuple
print(encoded_layers[0].shape, encoded_layers[1].shape,
encoded_layers[2][0].shape, encoded_layers[3][0].shape)
# torch.Size([1, 19, 768]) torch.Size([1, 768])
# torch.Size([1, 19, 768]) torch.Size([1, 12, 19, 19])
model_name = 'bert-base-chinese' # 指定需下载的预训练模型参数
在下一 篇文章,我们将开始做更多的练习