1.实操题目:
使用Ascend C实现Addcdiv算子
参考pytorch的Addcdiv算子,实现Ascend C算子Addcdiv,算子命名为AddcdivCustom相关算法:out= x+ y/z*value
要求:
1、完成Kernel侧实现代码和host侧调用算子代码,支持fp16类型输入
2、完成AcInn方式调用编写好的算子
3、根据提供的测试用例,使用aclnn方式调用验证通过,精度偏差小于1e-3
2.环境准备
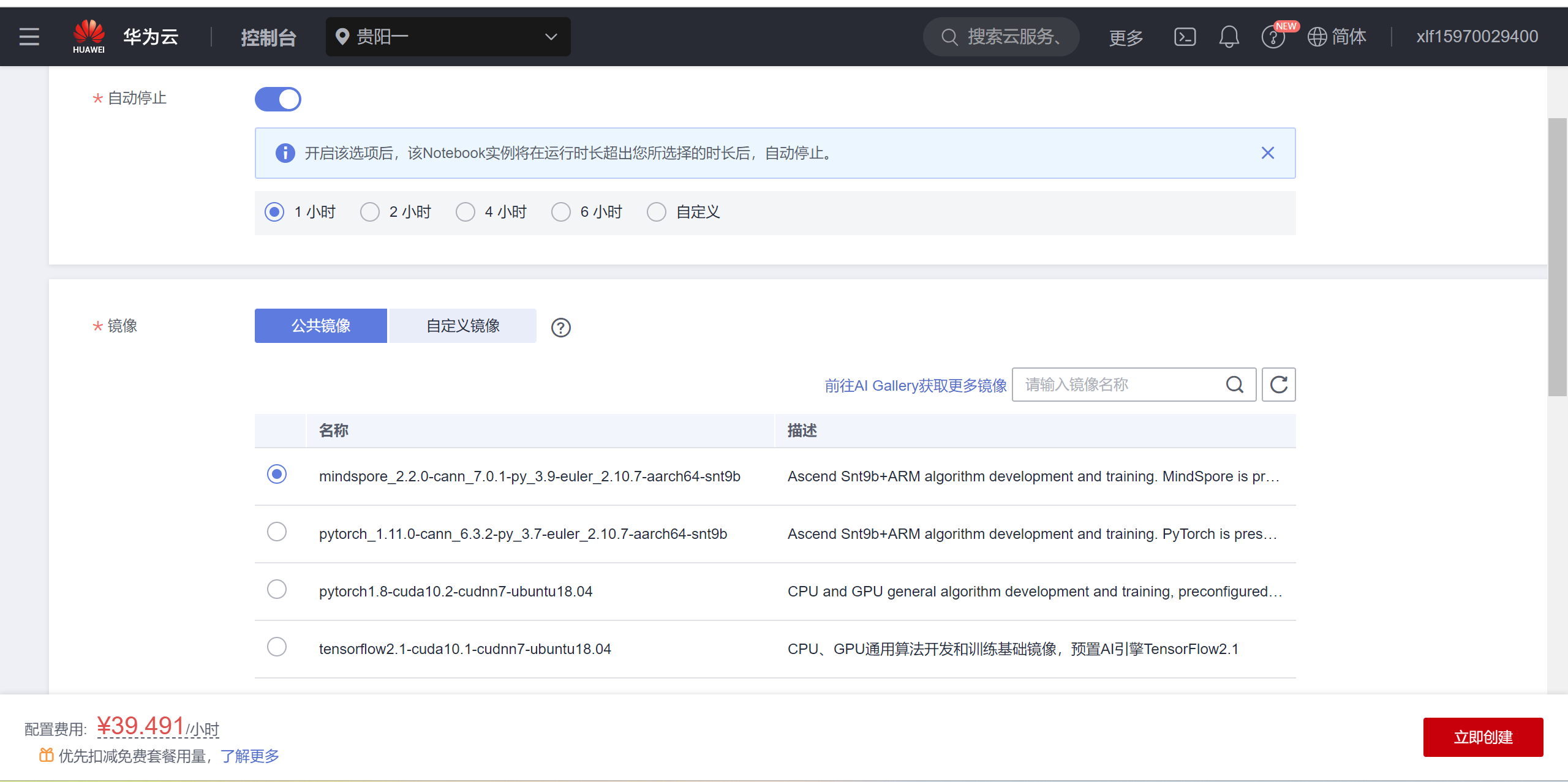
我是在华为云ModelArts西南贵阳一创建的Notebook,镜像为:
mindspore_2.2.0-cann_7.0.1-py_3.9-euler_2.10.7-aarch64-snt9b
3.算子分析
算子分析的流程图如下:
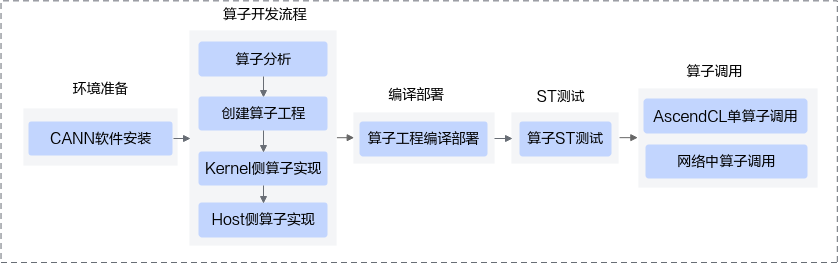
对应题目,本题主要解决的是Kernel侧代码、Host侧代码,单算子调用时的代码。
Addcdiv算子的数学表达式为:out= x+ y/z*value
算子分析表格为
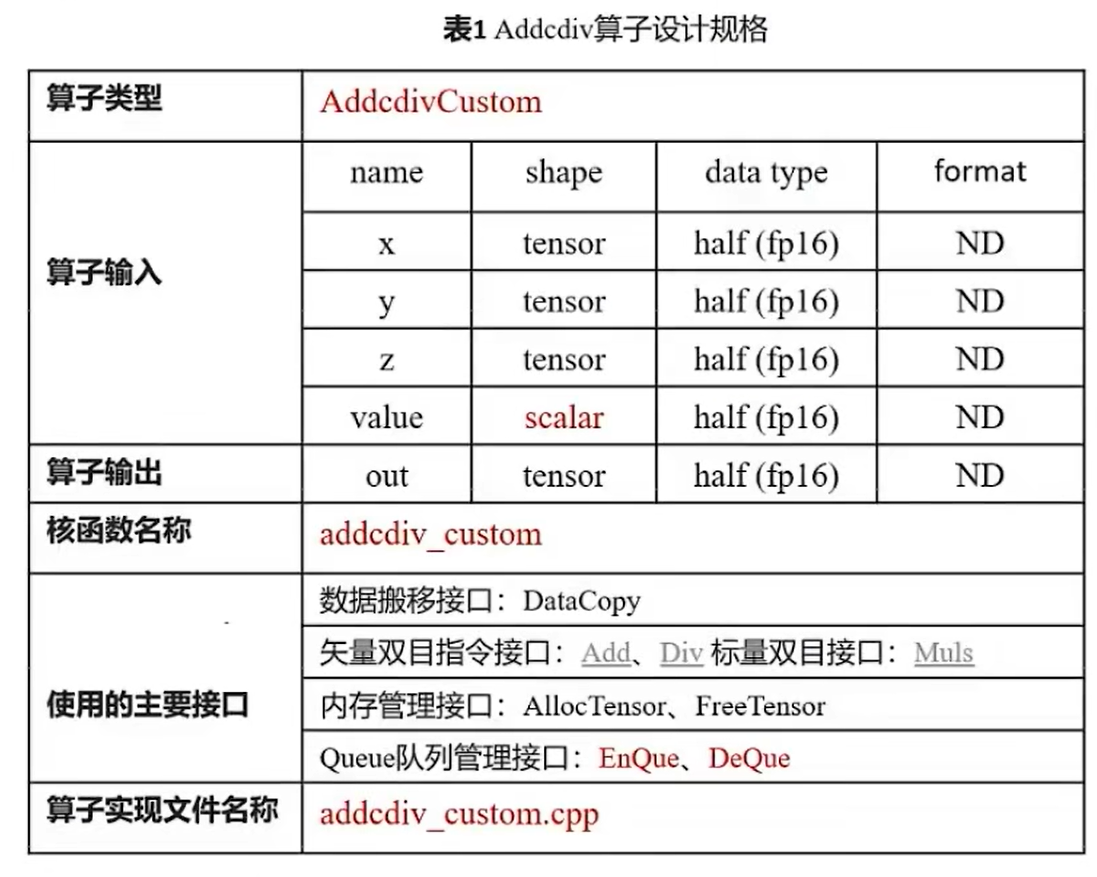
整个算子分析计算过程分为三个阶段:CopyIn,Compute,CopyOut
CopyIn:搬入x,y,z,value到Local内存,其中value是标量,要解决标量怎么传入
Compute:使用Local内存进行计算
CopyOut:搬运Local计算结果到out
这里我打算创建两个临时变量tmpBuf1和tmpBuf2分别用于存放y/z,y/z*value的值。
4.算子开发
4.1创建算子工程
CANN软件包中提供了工程创建工具msopgen,我们可以输入算子原型定义文件生成Ascend C算子开发工程。
编写AddcdivCustom算子的原型定义json文件,如下:
[
{
"op": "AddcdivCustom",
"language": "cpp",
"input_desc": [
{
"name": "x",
"param_type": "required",
"format": ["ND"],
"type": ["fp16"]
},
{
"name": "y",
"param_type": "required",
"format": ["ND"],
"type": ["fp16"]
},
{
"name": "z",
"param_type": "required",
"format": ["ND"],
"type": ["fp16"]
},
{
"name": "value",
"param_type": "required",
"format": ["ND"],
"type": ["fp16"]
}
],
"output_desc": [
{
"name": "out",
"param_type": "required",
"format": ["ND"],
"type": ["fp16"]
}
]
}
]
然后使用以下命令生成算子文件夹:
/usr/local/Ascend/ascend-toolkit/latest/python/site-packages/bin/msopgen gen -i /home/ma-user/work/samples/addcdiv_custom.json -c ai_core-Ascend910B2 -lan cpp -out /home/ma-user/work/samples/AddcdivCustom
生成的AddcdivCustom算子文件夹如下:
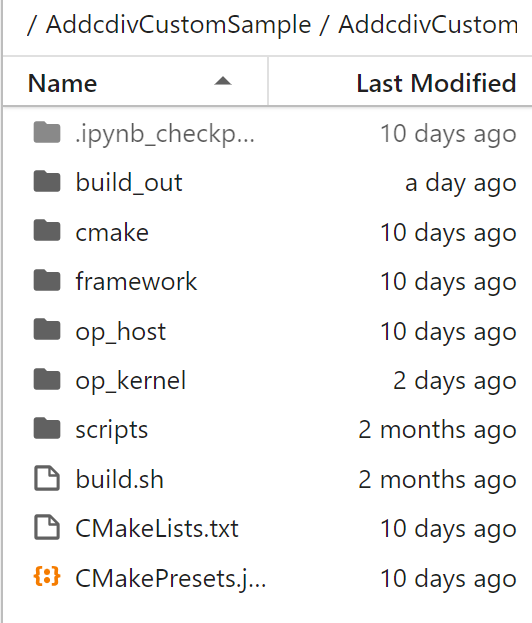
build_out文件夹是后面编译部署生成的,这里我们主要要修改的文件有:CMakePresets.json,op_host目录下的addcdiv_custom_tiling.h、addcdiv_custom.cpp、op_kernel目录下的addcdiv_custom.cpp。
下面分别展开
4.2 op_kernel侧实现
Init()方法实现
可以先把Add_custom算子的kernel侧实现代码复制过来,然后在此基础上进行修改,首先是KernelAddcdiv类的初始化代码,题目有四个输入,一个输出,修改如下:
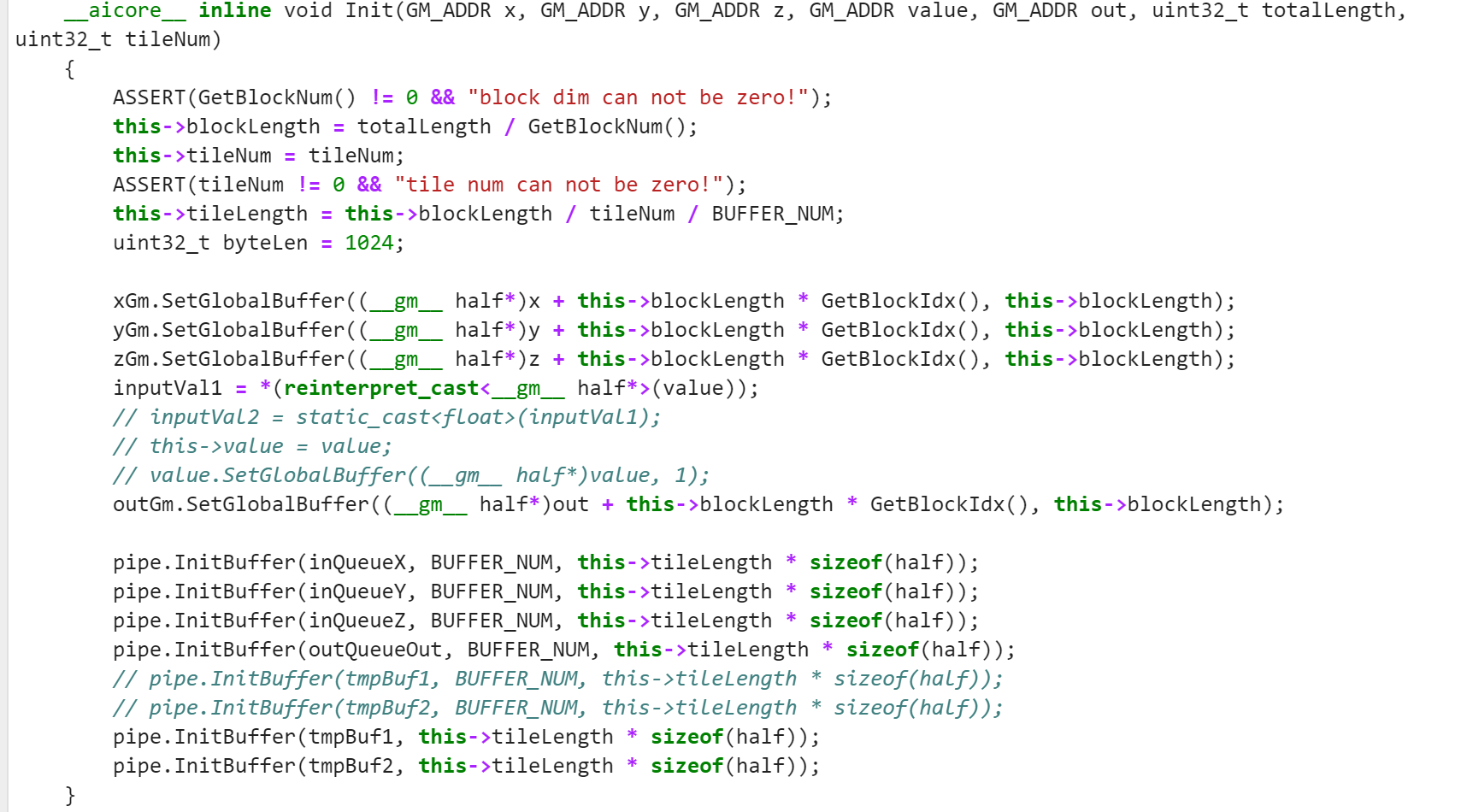
该代码使用GM_ADDR初始化x,y,z,value,out五个变量,x,y,z都是输入矢量,用SetGlobalBuffer()方法分配内存,因为value是标量,这里通过reinterpret_cast将value强制转换为__gm__ half类型,并赋给inputVal1进行运算。后面还初始化了临时变量tmpBuf1,tmpBuf2,这两个变量使用了 TPosition::VECCALC 类型的缓冲区对象,定义如下:
TBuf<TPosition::VECCALC> tmpBuf1, tmpBuf2;
CopyIn()方法实现
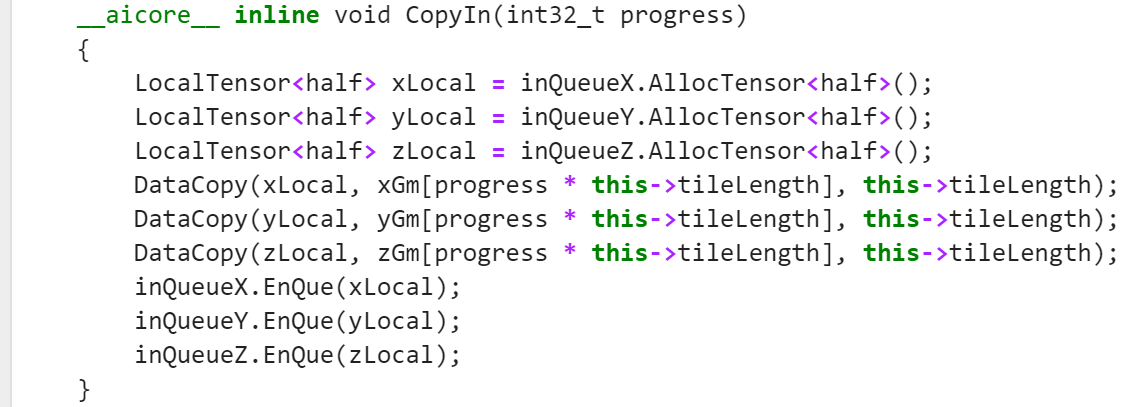
通过 inQueueX.AllocTensor(),inQueueY.AllocTensor() 和 inQueueZ.AllocTensor(),为本地张量(LocalTensor)对象 xLocal、yLocal 和 zLocal 在本地内存中分配空间。这些本地张量对象用于存储从全局内存复制过来的数据。
Compute()方法实现
Compute()函数是算子开发的核心,这里我用到了上述定义的两个临时变量,y/z的值暂时放在tmpBuf1,y/z*value的值放在tmpBuf2。
使用Get()方法从临时变量获取指定长度的Tensor参与计算:
LocalTensor<half> tmp1 = tmpBuf1.Get<half>();
LocalTensor<half> tmp2 = tmpBuf2.Get<half>();
Compute()函数代码如下:

这里用到了Muls()方法用于矢量中每个元素与标量求积
CopyOut()方法实现

4.2 op_host侧实现
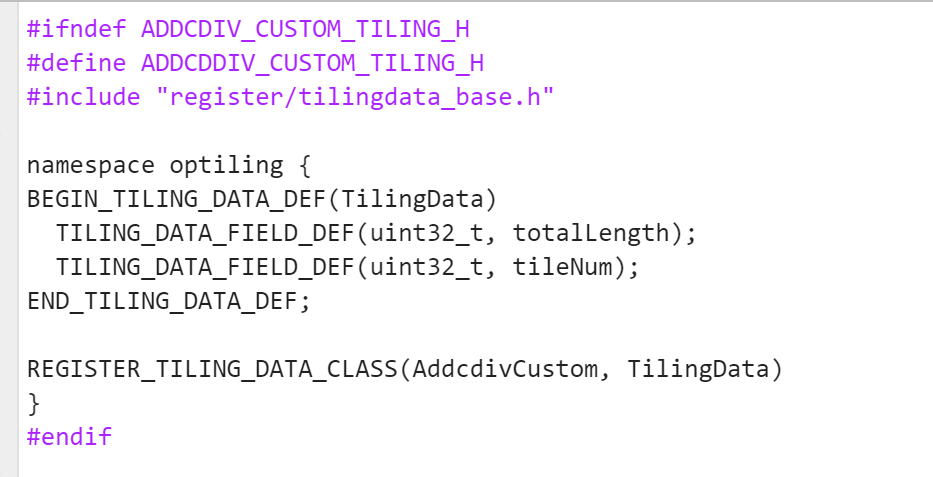
addcdiv_custom_tiling.h文件实现
这个文件要修改的地方是TilingData结构定义头文件的编写
addcdiv_custom.cpp文件实现
该文件是Tiling函数实现代码,主要修改算子原型注册代码,如下

5.算子工程编译和部署
算子kernel侧和host侧代码实现了之后,需要对算子工程进行编译,生成自定义算子安装包*.run
编译之前要修改CMakePresets.json文件下的ASCEND_CANN_PACKAGE_PATH变量,修改成你实际的CANN安装路径,我的修改如下:

修改好之后,切换到AddcdivCustom目录下,执行以下命令:
./build.sh
编译成功截图如下:
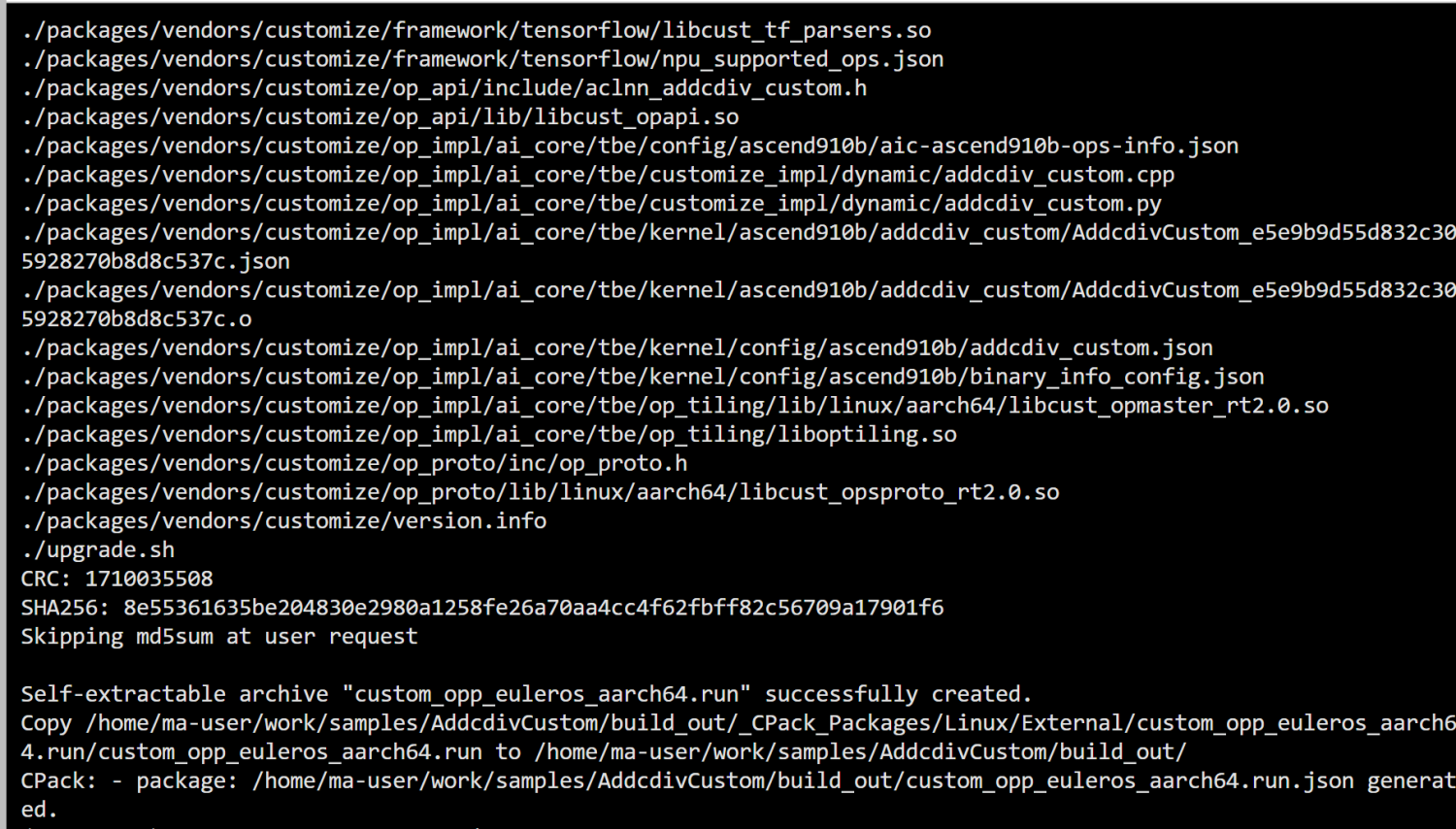
此时会生成一个build_out文件夹,里面有一个文件custom_opp_euleros_aarch64.run,使用以下命令部署
./custom_opp_euleros_aarch64.run
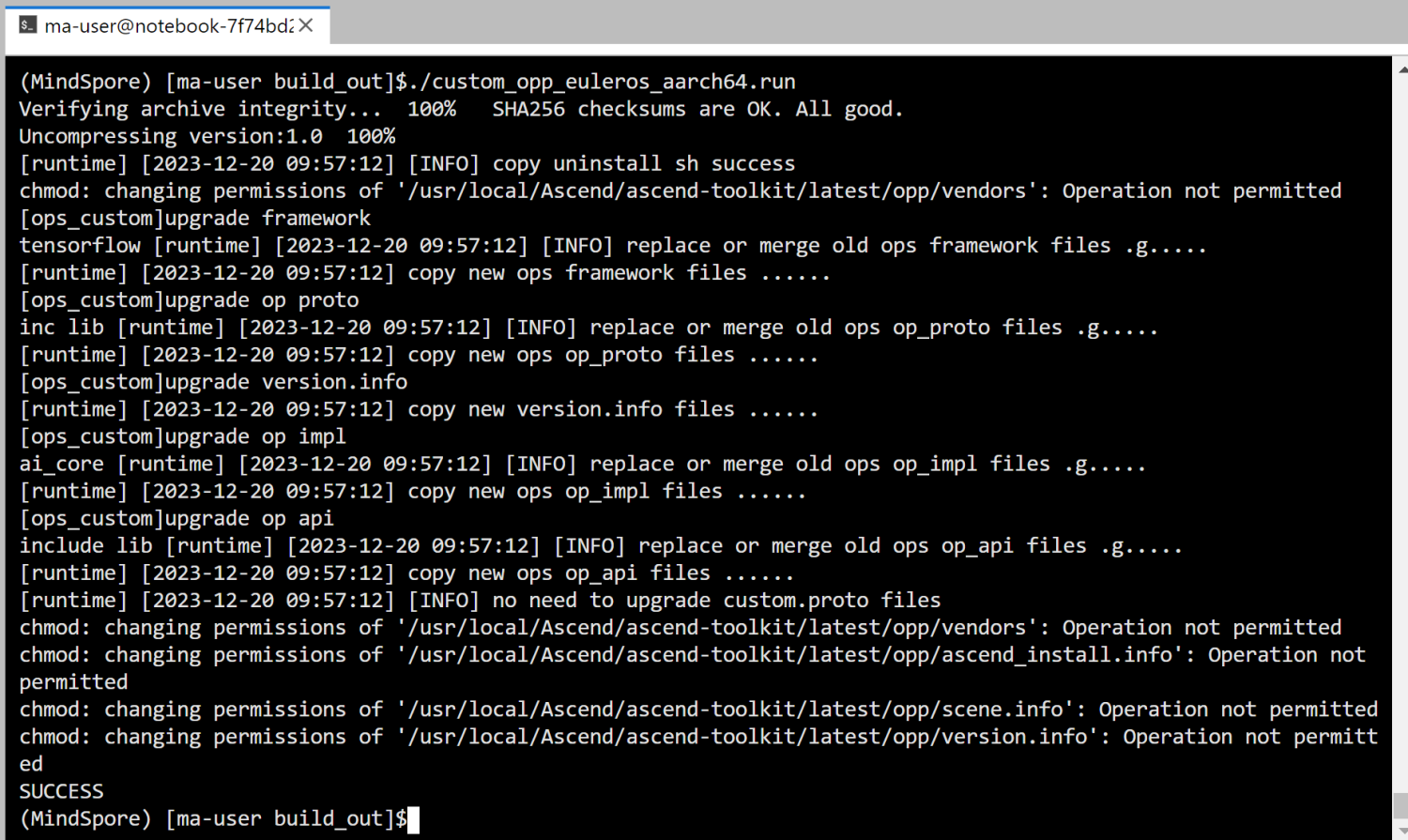
看到SUCCESS代表算子部署成功
6.使用aclnn方式调用
把AddCustom算子的AclNNInvocation文件夹复制一遍,目录位于samples/operator/AddCustomSample / FrameworkLaunch/AclNNInvocation,目录结构如下:

需要修改的文件有scripts文件下的gen_data.py,verify_result.py,src文件下的main.cpp,op_runner.cpp
gen_data.py修改
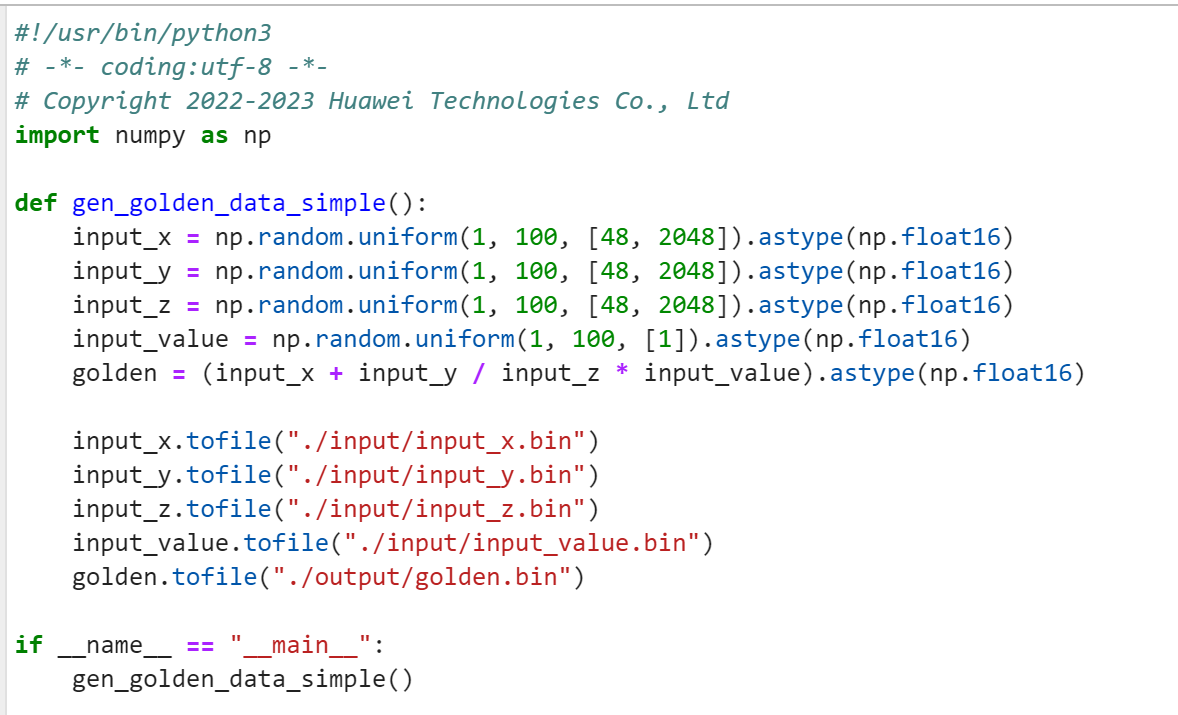
verify_result.py修改

main.cpp修改
要修改输入输出文件的位置
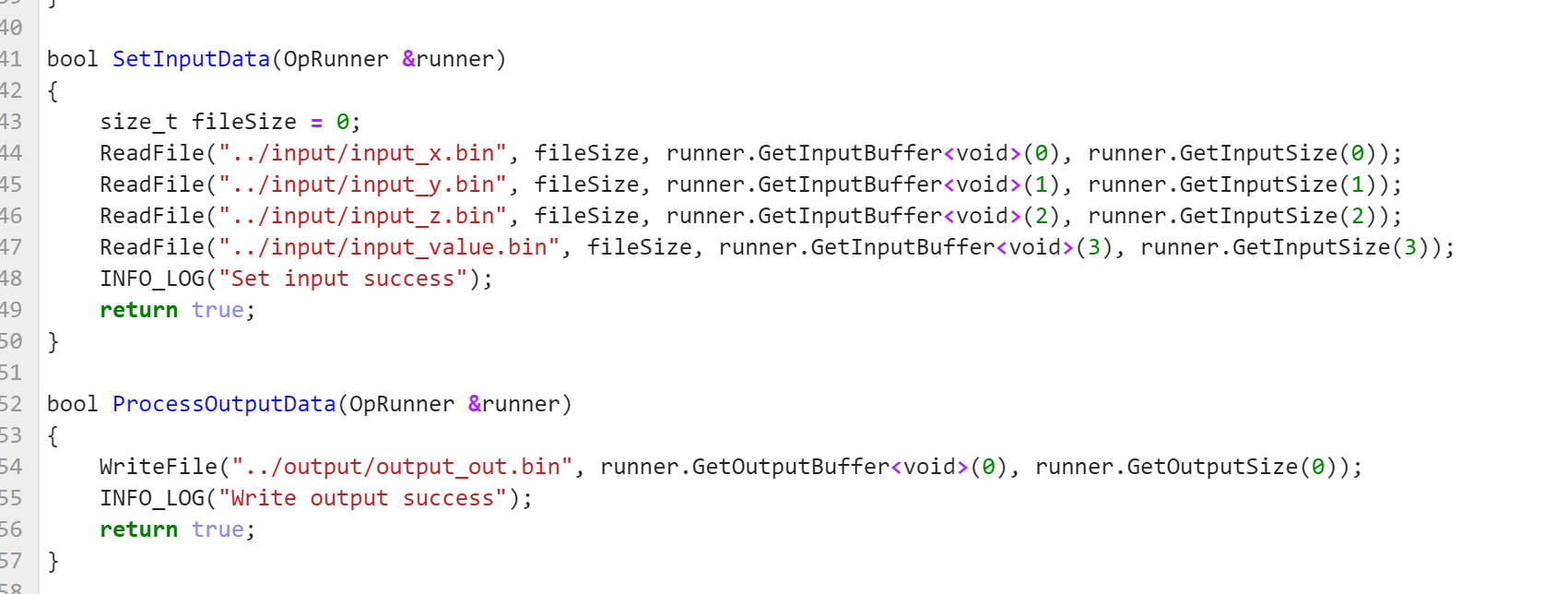
op_runner.cpp修改
要修改调用的算子名称,以及引入aclnn_addcdiv_custom.h头文件
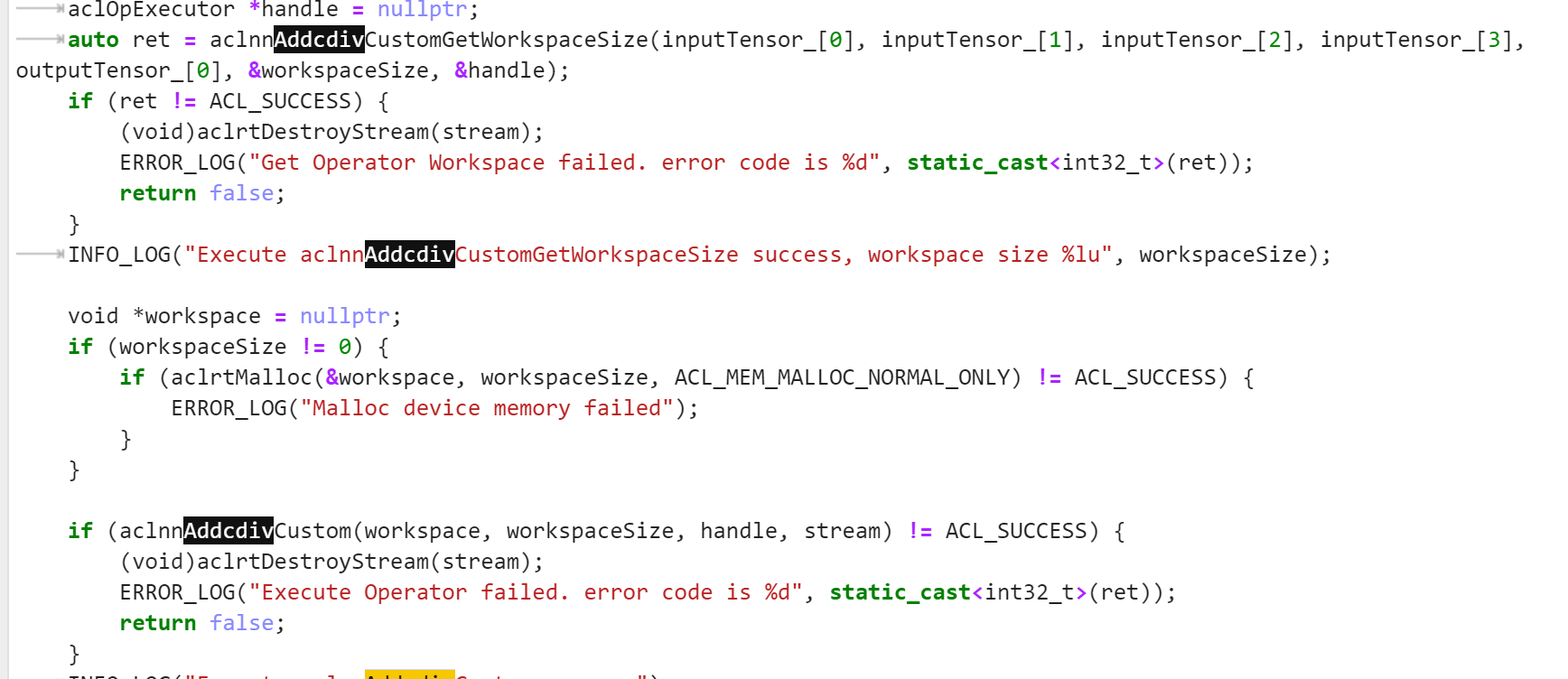
修改完上述文件之后,就可以使用ACLNN的方式调用验证算子,进入AclNNInvocation文件夹,运行以下命令
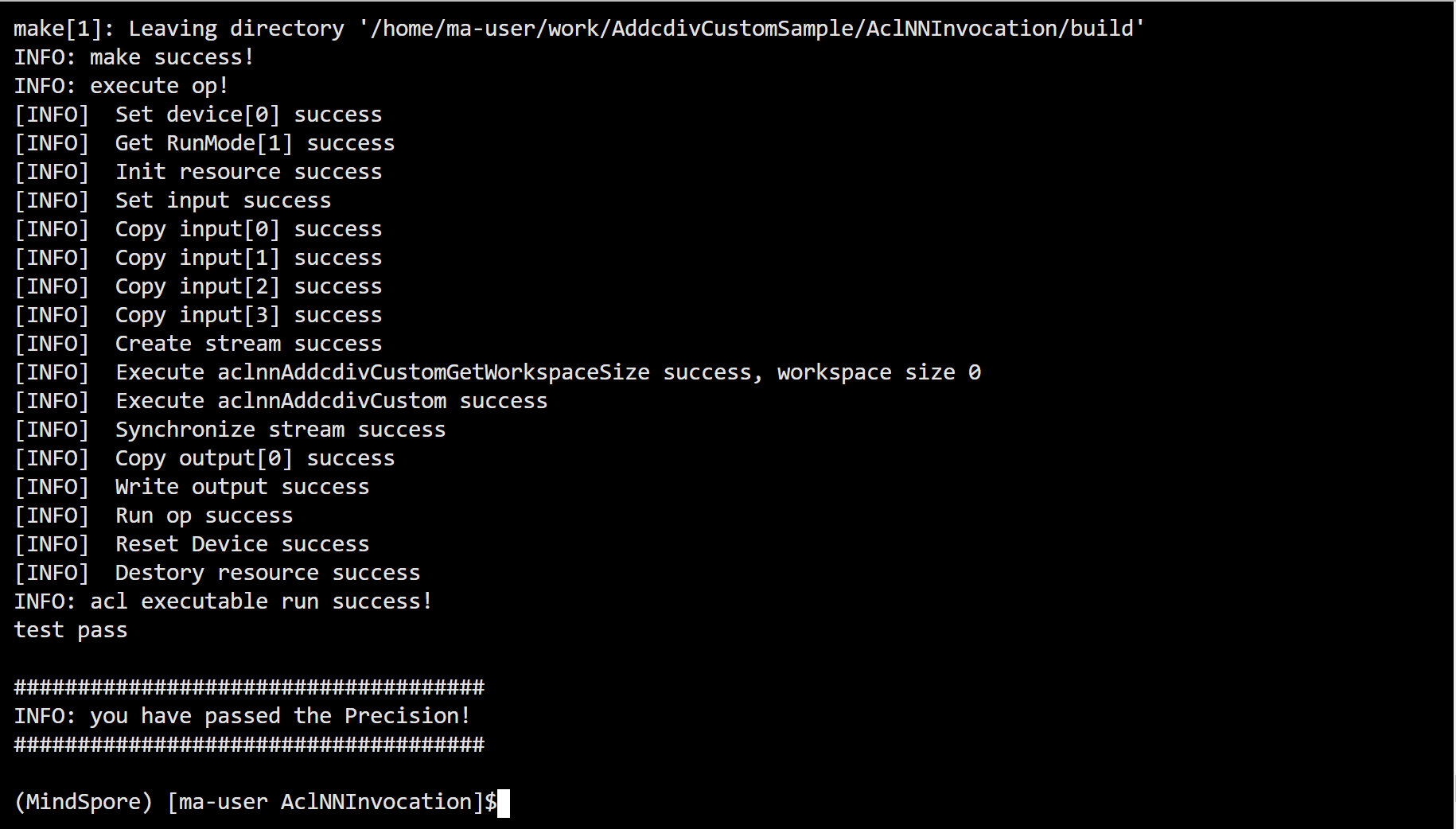
bash run.sh
打印如下图,则代表测试通过!
总结:
以上就是Ascend C代码实操课的作业分享,其实理解了算子开发的流程之后,做起来就没那么吃力了,归纳起来就是先用msopgen工具生成算子工程文件,然后分别修改op_kernel侧和op_host侧的代码,然后进行编译和部署就可以了,后续还可以通过aclnn调用的方式调用AddCustom算子工程。










![vxe-table 修改[表尾数据]footer的高度](https://img-blog.csdnimg.cn/direct/80ac515971c8442fa4c4fecf78ccd923.png)