目录
第一部分:系统安装... 3
1:图形化安装... 3
2:选择中文... 3
3:安装选项... 3
4:软件选项... 4
5:安装位置... 4
6:网络配置... 6
7:开始安装... 7
8:创建用户... 7
9:重启系统... 7
10:登录测试... 8
第二部分:初始化设置... 9
1:SSH远程登录... 9
2:yum 源更新... 9
3:安装vim和wget. 11
4:增加test 用户权限... 12
5:修改主机 /tec/hosts 文件... 14
6:配置test 账户免密ssh 登录... 15
7:防火墙设置开机关闭... 17
第三部分:Java jdk 安装配置... 19
1:检查JAVA状态... 19
2:安装JAVA 1.8. 19
3:配置环境变量... 20
第四部分:Hadoop 集群安装... 22
1:下载hadoop. 22
2:修改环境变量... 23
3:节点配置... 24
1:主节点安装(server1)... 24
2:备节点安装(server2 server3)... 28
第五部分:Hadoop 状态检查和常用命令... 31
1:网页状态查看... 31
2:控制台命令... 32
1:常用排查故障命令... 32
2:常用基础命令... 32
3:HDFS命令(Hadoop分布式文件系统)... 32
4:MapReduce作业运行命令... 33
5:YARN(Yet Another Resource Negotiator)命令... 33
6:Hadoop集群管理命令... 33
7:Hadoop配置文件管理命令... 33
第一部分:系统安装
大致过程:软件安装选择-------磁盘分区-------IP地址设置-----用户名密码设置
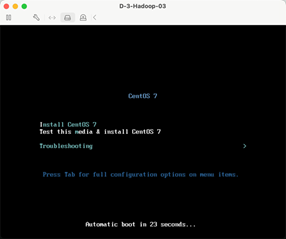
1:图形化安装
这里选择图形化安装。
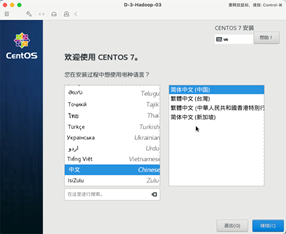
2:选择中文
选择语言为中文。
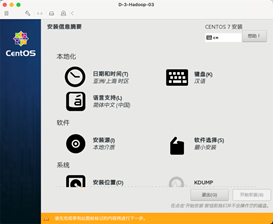
3:安装选项
设置对应的安装选项。
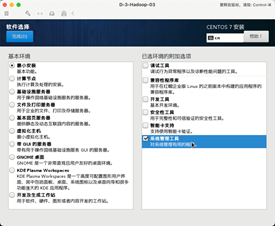
4:软件选项
选择最小安装和系统管理工具。
5:安装位置
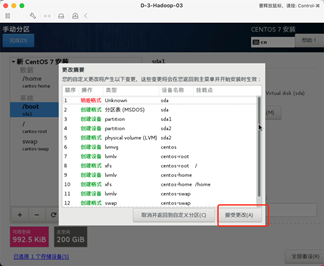
选择对应的磁盘并手动配置磁盘各分区大小。
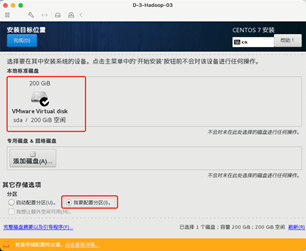
点击自动创建
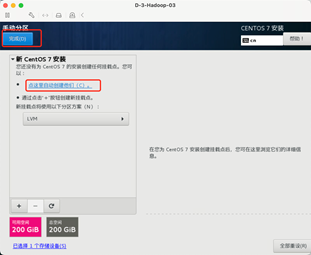
调整 /home 分区和/ 分区的大小,因为Hadoop默认的存储路径是在/目录下,所以/目录需要分配大一点。
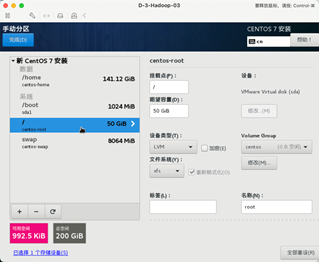
分配后的各部分大小。
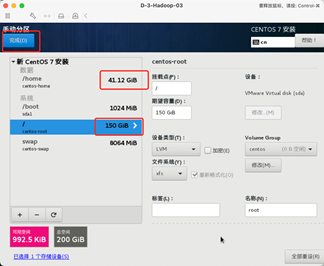
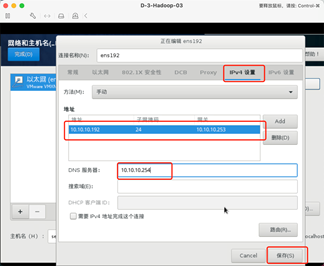
6:网络配置
手动指定IP地址和主机名。
215三台分别是192.168.1.190/191/192
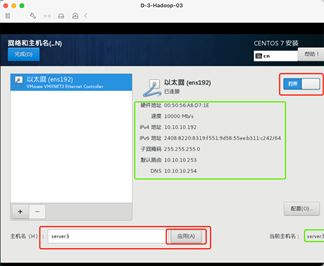
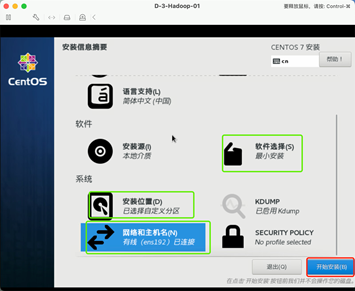
7:开始安装
8:创建用户
创建root密码和用户,简单密码需要保存2次,密码安全测试环境不涉及,
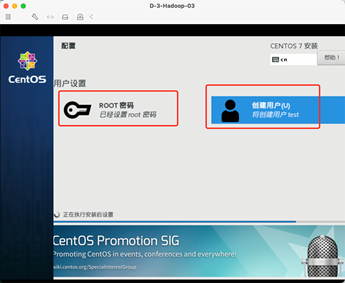
9:重启系统
重启系统后就完成安装了。
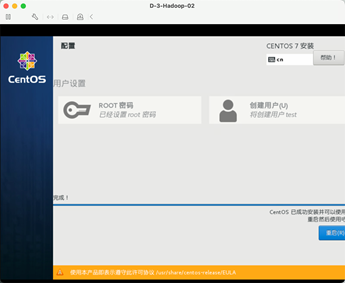
10:登录测试
登录系统检测账号密码是否可以登录:
su -l root 切换到root账户
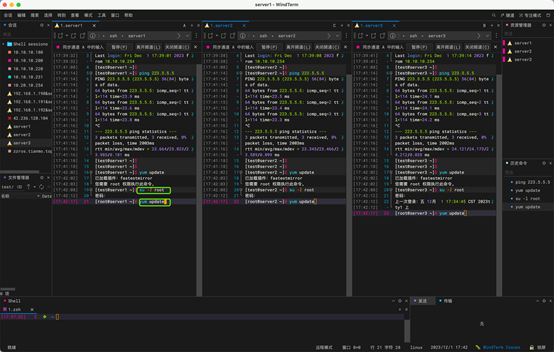
测试网络是否正常:
ping 223.5.5.5(223.5.5.5是阿里的公共DNS服务器地址)
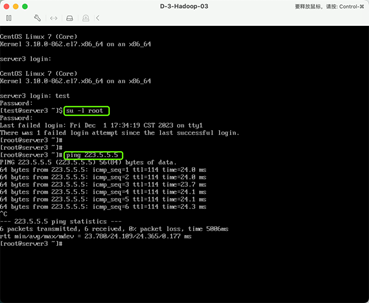
以上完成操作系统的安装。
第二部分:初始化设置
yum update 更新-----vim wget 安装-----sudo 文件增加用户名----/etc/hosts 文件配置3台机器主机名解析---------SSH 免密登录配置------关闭防火墙设置
1:SSH远程登录
使用WindTerm的 窗口水平分割和同步输入进行3台机器同时操作,节省时间。
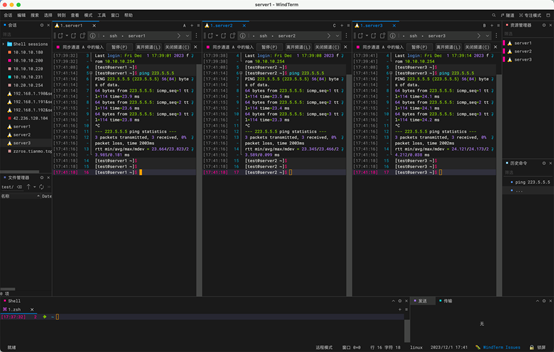
2:yum 源更新
切换到root 账户,使用 yum update, 中间出现确认选项使用 y 确认。
命令:
yum update
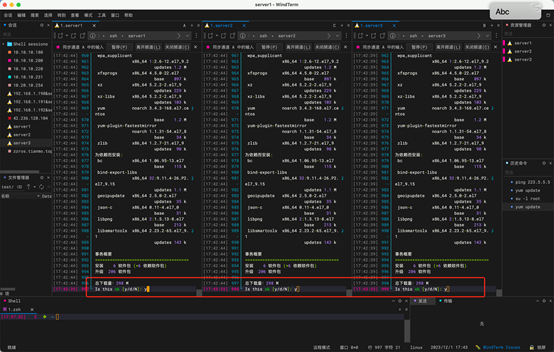
更新完成
3:安装vim和wget
vim是文档编辑工具,wget 是下载HTTP的工具。
命令:(root用户模式下)中间出现确认选项使用 y 确认。
yum install vim
yum install wget
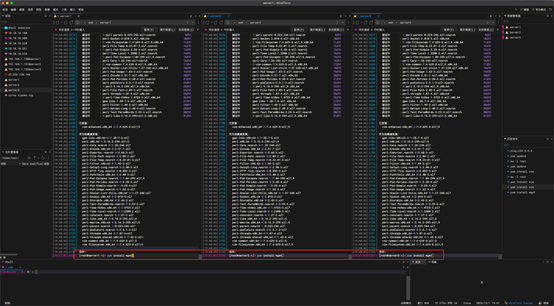
4:增加test 用户权限
vi和vim 基础操作。进入后 i和(insert)按键进入插入模式,esc 进入: 模式
:行数 ===去到某一行
:wq ====保存修改
:wq! ====强制保存修改
:q ====退出
:q: ====强制退出
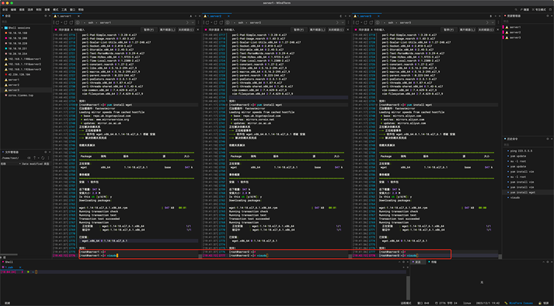
去往第100行。
新增test 用户权限,test 为之前创建的用户。
:wq 进行保存。
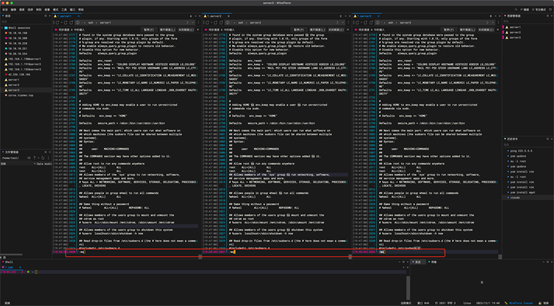
5:修改主机 /tec/hosts 文件
命令:
vim /etc/hosts
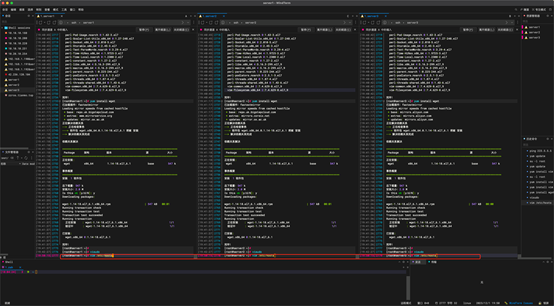
新增主机名和ip地址对应关系,ip地址根据实际地址(这里是我的内网地址)
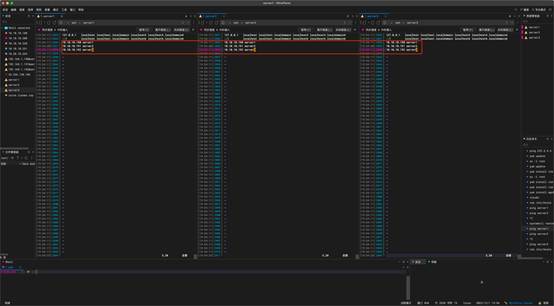
修改完成后直接ping 主机名进行测试,通了代表修改成功。
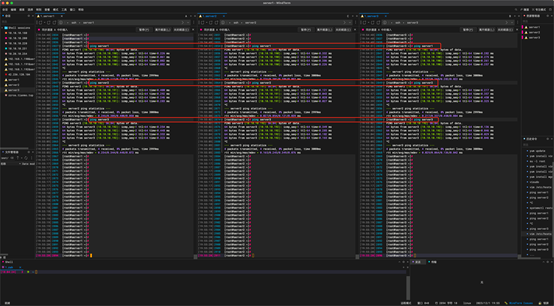
6:配置test 账户免密ssh 登录
Hadoop 默认在非root账户下运行,所以需要返回 test 账户下,使用exit 退出
命令:
cd ~/.ssh/
进入test用户的ssh目录,提示无当前目录,使用ssh 随便远程一台机器即可产生目标目录,使用no 不保存密钥。然后就可以进入~/.ssh/ 目录了
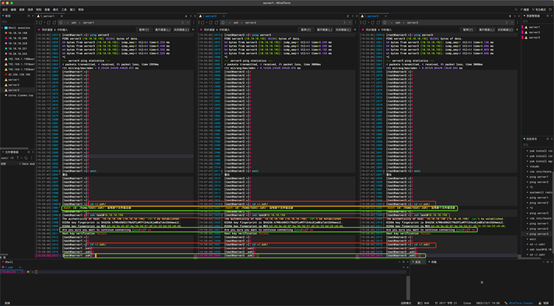
命令:
ssh-keygen -t rsa
生成密钥,会出现一些提示,这里要连续按多次回车,直到它出现一个如下图所示的框框。
cat id_rsa.pub >> authorized_keys
chmod 600 ./authorized_keys
加入授权和修改文件权限。
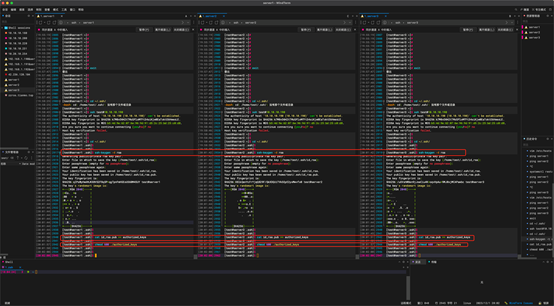
分别使用以下命令拷贝ssh 秘钥,按提示输入 yes 和密码。
命令:
ssh-copy-id test@10.10.10.190
ssh-copy-id test@10.10.10.191
ssh-copy-id test@10.10.10.192
这里是3台机器相互拷贝对方的秘钥,因为我这里使用的是同步输入,每台机器都有自身的秘钥,所以这里有个报错,可以不用管,直接输入密码既可以。(以server3为例server1和server2 需要拷贝server3的密钥,这里提示要是否保存,输入yes 保存,然后输入test 用户密码即可,因为server3不用输入密码,所以这里直接进入了$ 输入模式,这个是正常的,其他2台这里也是一样的)
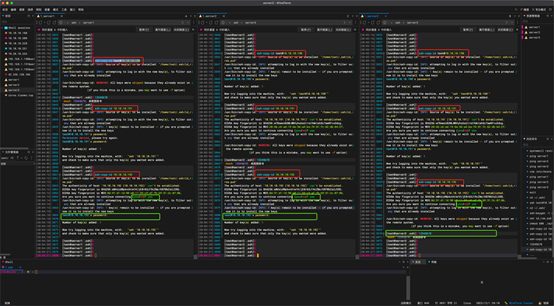
拷贝完成进行测试,分别使用域名和ip地址测试登录其他机器是否需要输入密码。
命令:
ssh test@server1
ssh test@10.10.10.190
我这里是使用的同步输入,每次都进入相同的服务器,这里可以看到每次都成功了。
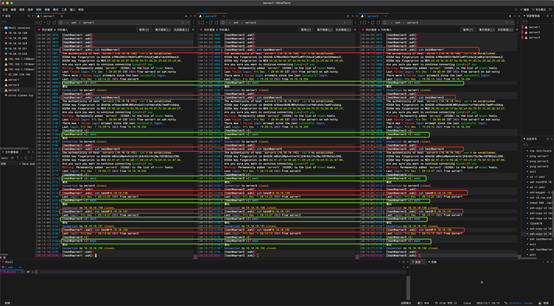
7:防火墙设置开机关闭
命令:
sudo systemctl stop firewalld
sudo systemctl disable firewalld

接下来重启下服务器。准备安装java。
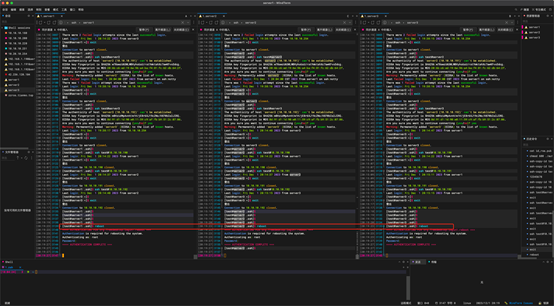
第三部分:Java jdk 安装配置
JAVA 安装------环境变量设置-----安装完成后检查
1:检查JAVA状态
切换root账户,输入命令java -version查看当前Java版本。(注意-)我这里显示未安装。
命令:
java -version
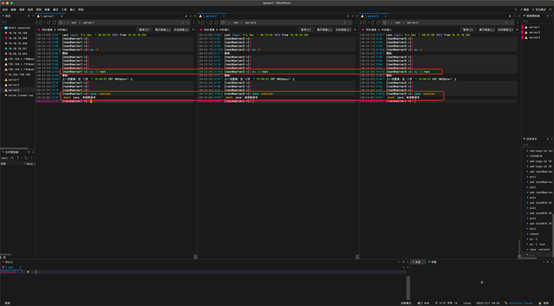
2:安装JAVA 1.8
Hadoop在1.7版本或1.8版本都可以,这是是安装的1.8版本的。
命令:
sudo yum install java-1.8.0-openjdk java-1.8.0-openjdk-devel
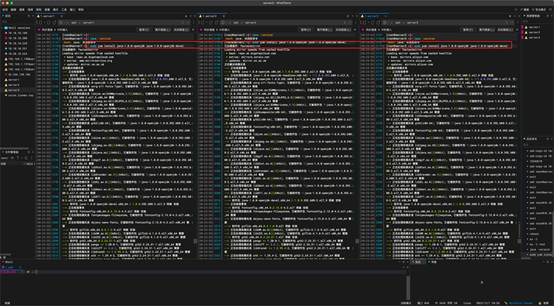
安装完成后检查一下
3:配置环境变量
输入vim ~/.bashrc我们在.bashrc中进行环境变量设置。
命令:
vim ~/.bashrc
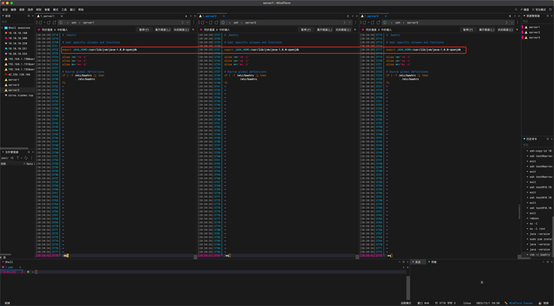
进入文本后,在 # User specific aliases and functions下面加上如下一行:
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk
这里的JAVA_HOME的值是当前JDK的安装位置。添加上后就:wq保存退出。
输入source ~/.bashrc让刚才的变量设置生效。
命令:
source ~/.bashrc
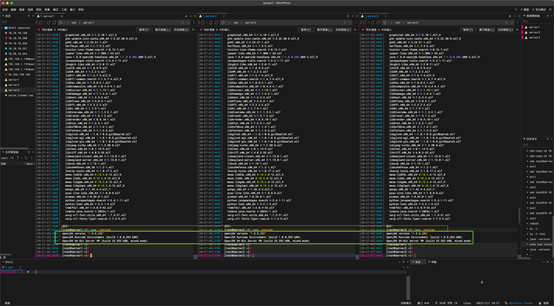
完成以上操作后,我们输入如下命令进行检查。
命令:
java -version
$JAVA_HOME/bin/java –version
如下图所示,两个命令的输出结果一样,就没有问题。
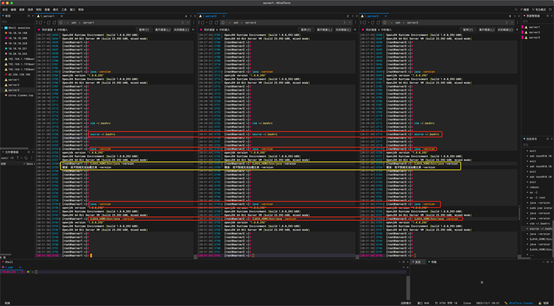
以上显示java 安装成功。黄色地方报错的原因是 -version 的 - 不对,修改后就可以了运行了。
以上完成了java 的安装。
第四部分:Hadoop 集群安装
1:下载hadoop
(此处一定要切换回 test 账户,否则hadoop 启动不了)
退出到test 账户下,下载hadoop。
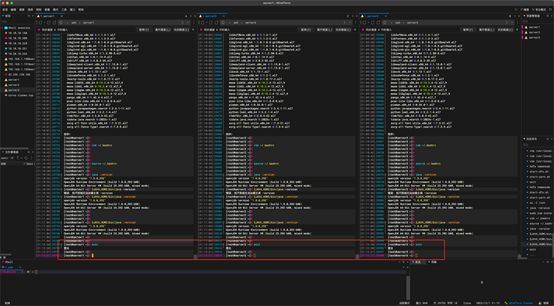
命令:
wget https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-3.3.1/hadoop-3.3.1.tar.gz
tar -xzvf hadoop-3.3.1.tar.gz
sudo mv hadoop-3.3.1 /usr/local/hadoop
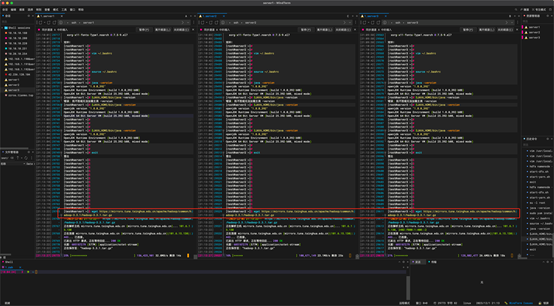
2:修改环境变量
编辑用户的 ~/.bashrc 文件:,在文件末尾添加以下行:
命令:
vim ~/.bashrc
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
保存并退出,然后执行命令:
source ~/.bashrc
3:节点配置
这里主节点和其他节点配置不一样,所以关闭了同步输入
1:主节点安装(server1)
1.1:查询java 的程序位置
命令:
sudo update-alternatives --config java
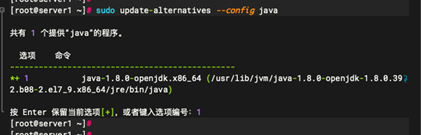
记录当前路径:/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.392.b08-2.el7_9.x86_64/jre
1.2:编辑 Hadoop 环境配置文件:
命令:
vim /usr/local/hadoop/etc/hadoop/hadoop-env.sh
添加以下内容: java 路径替换为上面记录的。
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.392.b08-2.el7_9.x86_64/jre
export HADOOP_HOME_WARN_SUPPRESS=true
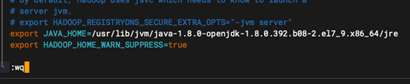
1.3:配置 Hadoop 核心文件
命令:
vim /usr/local/hadoop/etc/hadoop/core-site.xml
添加以下内容: hdfs://10.10.10.190:9000 替换成对应的地址。
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://10.10.10.190:9000</value>
</property>
</configuration>
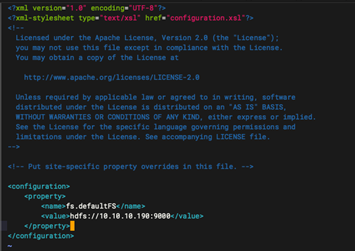
1.4:配置 HDFS 文件系统
命令:
vim /usr/local/hadoop/etc/hadoop/hdfs-site.xml
添加以下内容:
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/usr/local/hadoop/data/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/usr/local/hadoop/data/datanode</value>
</property>
</configuration>
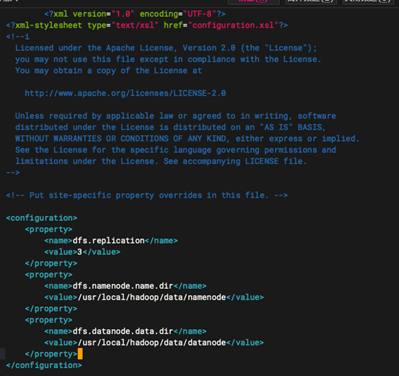
1.5:配置 YARN 资源管理器
命令:
vim /usr/local/hadoop/etc/hadoop/yarn-site.xml
添加以下内容: 10.10.10.190 替换成对应的地址
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>10.10.10.190</value>
</property>
</configuration>
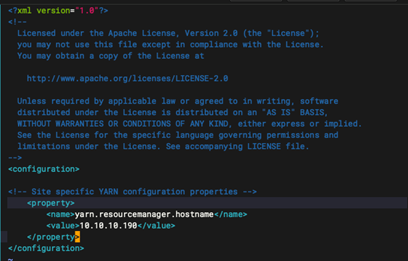
1.6:创建 HDFS 目录
命令:
hdfs namenode -format
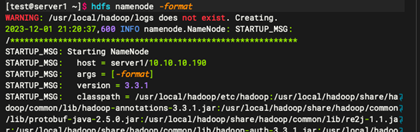
1.7:启动 Hadoop 服务
命令:
start-dfs.sh
start-yarn.sh
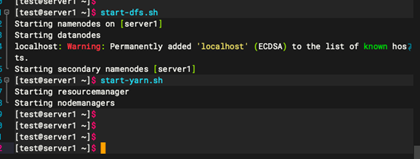
主节点(server1)的hadoop 安装完成。
1.8:查看主节点状态
命名:
hdfs dfsadmin -report
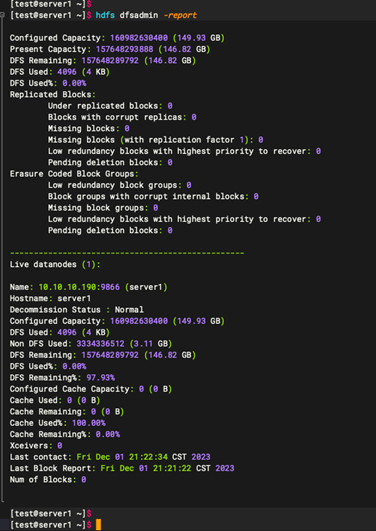
2:备节点安装(server2 server3)
2.1: 从主节点复制 Hadoop 配置到从节点
命令:
scp -r 10.10.10.190:/usr/local/hadoop/etc/hadoop/* /usr/local/hadoop/etc/hadoop/
10.10.10.190修改为对应主节点ip地址
2.2:启动 Hadoop 服务
命令:
start-dfs.sh
start-yarn.sh

2.3:查看主节点状态
命名:
hdfs dfsadmin -report
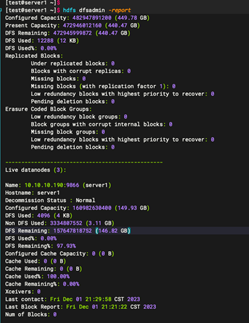
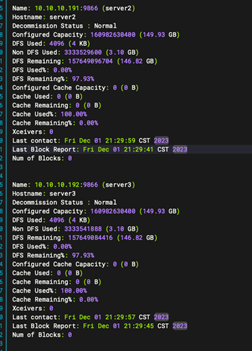
以上就完成hadoop 3台机器集群环境的安装
第五部分:Hadoop 状态检查和常用命令
1:网页状态查看
YARN ResourceManager Web 用户界面 http://10.10.10.190:8088
Hadoop节点信息 http://10.10.10.190:9870


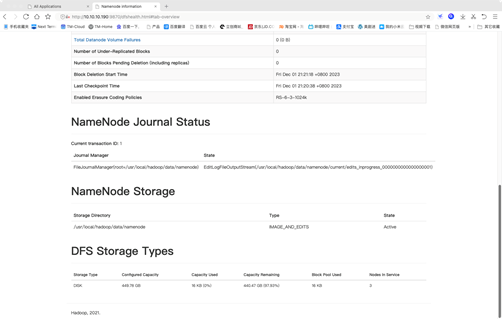
2:控制台命令
1:常用排查故障命令
验证一下集群的状态:hdfs dfsadmin -report
列出 HDFS 上的文件:hdfs dfs -ls
本地文件上传到 HDFS:hdfs dfs -put /path/to/local/file /user/test/
获取节点的主机名或 IP 地址:hdfs dfsadmin -report | grep "Name:"
强制 Hadoop 刷新节点列表: hdfs dfsadmin -refreshNodes
2:常用基础命令
3:HDFS命令(Hadoop分布式文件系统)
上传文件到HDFS:
hdfs dfs -put <local-source> <hdfs-destination>
从HDFS下载文件:
hdfs dfs -get <hdfs-source> <local-destination>
列出HDFS目录内容:
hdfs dfs -ls <hdfs-path>
创建HDFS目录:
hdfs dfs -mkdir <hdfs-directory>
删除HDFS文件或目录:
hdfs dfs -rm <hdfs-path>
复制本地文件到HDFS:
hdfs dfs -copyFromLocal <local-source> <hdfs-destination>
4:MapReduce作业运行命令
提交MapReduce作业:
hadoop jar <jar-file> <main-class> <input-path> <output-path>
查看正在运行的MapReduce作业列表:
yarn application -list
5:YARN(Yet Another Resource Negotiator)命令
查看集群节点资源使用情况:
yarn node -list
查看正在运行的应用程序:
yarn application -list
6:Hadoop集群管理命令
启动Hadoop集群:
start-all.sh
停止Hadoop集群:
stop-all.sh
查看Hadoop集群状态:
hadoop dfsadmin -report
7:Hadoop配置文件管理命令
查看Hadoop配置:
hadoop version
查看Hadoop配置文件内容:
cat $HADOOP_HOME/etc/hadoop/core-site.xml