文章目录
- 一.架构说明与资源准备
- 二.部署prometheus
- 1.上传软件包
- 2.解压软件包并移动到指定位置
- 3.修改配置文件
- 4.编写启动脚本
- 5.启动prometheus服务
- 三.部署node-exporter
- 1.上传和解压软件包
- 2.设置systemctl启动
- 3.启动服务
- 四.部署grafana
- 1.安装和启动grafana
- 2.设置prometheus数据源
- 3.新增监控模板
- 4.修改模板的变量和配置信息
一.架构说明与资源准备
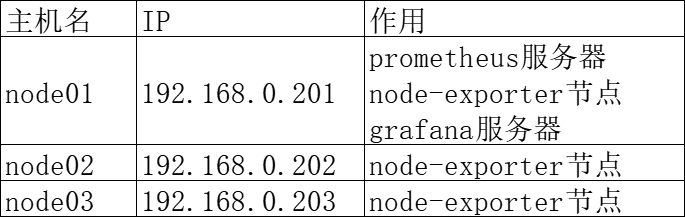
需要准备的软件包:
node_exporter-1.2.0.tar.gz
grafana-7.3.0-1.x86_64.rpm
prometheus-2.45.1.linux-amd64.tar.gz
以上软件版本可以有一定的差异,只要兼容RHEL7的操作系统,本次部署的3台虚拟机操作系统是 CentOS Linux release 7.9.2009 (Core) 。
软件包下载地址参考:
https://rpmfind.net/linux/rpm2html/search.php
https://sourceforge.net/projects/infozip/files/
https://centos.pkgs.org/7/centos-x86_64/
https://access.redhat.com/downloads
二.部署prometheus
本章操作都在node01进行。
1.上传软件包
首先将软件包上传到/root目录下

2.解压软件包并移动到指定位置
接着创建/data目录,准备将后续解压后的软件文件放在/data目录
mkdir /data
tar zxf prometheus-2.45.1.linux-amd64.tar.gz
mv prometheus-2.45.1.linux-amd64 /data/prometheus
3.修改配置文件
针对配置文件 /data/prometheus/prometheus.yml 进行修改
global:
scrape_interval: 15s
evaluation_interval: 15s
scrape_timeout: 15s
alerting:
alertmanagers:
- static_configs:
- targets:
- 192.168.0.201:9093
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
- rules/*.yml
scrape_configs:
- job_name: "node_exporter"
static_configs:
# #监控的主机IP和node-exporter端口
- targets: ['192.168.0.201:9100','192.168.0.202:9100','192.168.0.203:9100']
relabel_configs:
- source_labels:
- "__address__"
regex: "(.*):9100"
target_label: "instance"
action: replace
replacement: "$1"
remote_write:
- url: "http://192.168.0.201:8086/api/v1/prom/write?db=prometheus&u=root&p=123456"
但一般情况下,由于公司负责的业务较多,我们会后期制作不同的grafana监控面板,对于监控的主机也需要进行分类。从实际需求角度,将所有的监控主机IP写在一个配置文件是不合适的,我们需要根据项目新增监控IP的yaml文件。
global:
scrape_interval: 15s
evaluation_interval: 15s
scrape_timeout: 15s
alerting:
alertmanagers:
- static_configs:
- targets:
- 192.168.0.201:9093
rule_files:
- rules/*.yml
#我们在当前目录下,新建一个目录hostlist,将所有新增项目的监控IP信息加到hostlist文件下。
scrape_configs:
- job_name: "other"
static_configs:
file_sd_configs:
- files:
- hostlist/*.yml
refresh_interval: 1m
relabel_configs:
- source_labels:
- "__address__"
regex: "(.*):9100"
target_label: "instance"
action: replace
replacement: "$1"
remote_write:
- url: "http://192.168.0.201:8086/api/v1/prom/write?db=prometheus&u=root&p=123456"
在当前目录 /data/prometheus 下新建hostlist目录
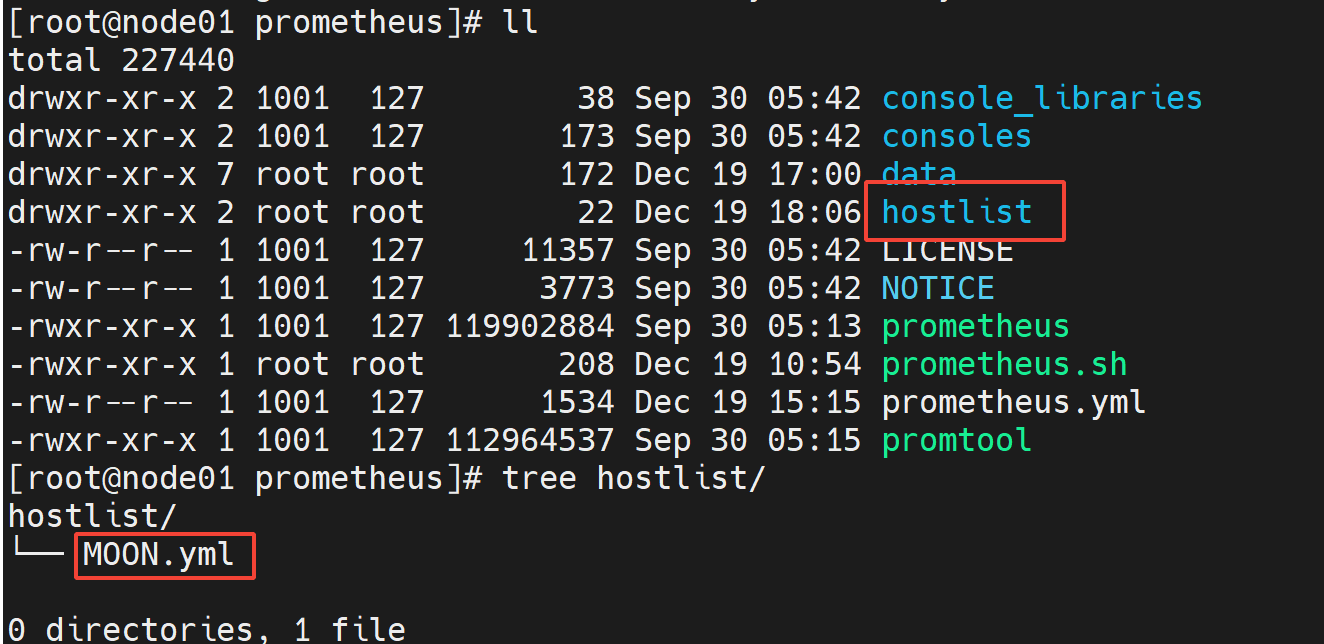
在hostlist目录下新建一个yaml文件,后缀必须是 yml
我们给该项目起名为MOON,被监控主机的端口都是9100.
分别定义变量htname job proj,填写主机名、监控对象和项目信息,这些变量可以自由定义。
[root@node01 prometheus]# cat hostlist/MOON.yml
- targets: ['192.168.0.201:9100']
labels:
htname: node01
job: linux
proj: MOON
- targets: ['192.168.0.202:9100']
labels:
htname: node02
job: linux
proj: MOON
- targets: ['192.168.0.203:9100']
labels:
htname: node03
job: linux
proj: MOON
这样,以后如果新增一个SUN项目,对应服务器资源监控的yaml文件就可以写为SUN.yml,以此类推,而新增项目的监控,yaml文件的增加,需要重新加载prometheus配置文件,才能让新配置生效并监控到新项目的资源。
#新增或更改监控资源后的重启服务命令
curl -X POST http://localhost:9090/-/reload
4.编写启动脚本
先编写一个启动prometheus服务的脚本,放在/data/prometheus目录下
[root@node01 prometheus]# cat prometheus.sh
#!/bin/bash
/data/prometheus/prometheus --web.enable-lifecycle --config.file=/data/prometheus/prometheus.yml --storage.tsdb.path=/data/prometheus/data --storage.tsdb.retention.time=20d --web.enable-admin-api
接着授予脚本执行权限。
chmod 755 prometheus.sh
再设置systemctl可以启动服务
[root@node01 prometheus]# cat /usr/lib/systemd/system/prometheus.service
[Unit]
Description=Prometheus
Documentation=https://prometheus.io/docs/introduction/overview/
Wants=network-online.target
After=network-online.target
[Service]
User=root
Group=root
Type=simple
# 启动脚本
ExecStart=/data/prometheus/prometheus.sh
[Install]
WantedBy=multi-user.target
5.启动prometheus服务
启动并设置开机自动启动
systemctl start prometheus.service
systemctl enable prometheus.service
systemctl status prometheus.service
检查端口,服务已启动

三.部署node-exporter
本章操作需要在3台服务器上都完成,此处只演示在node01的步骤,node02和node03同理。
1.上传和解压软件包
将上传的node-exporter解压并移动到/data
tar xzf node_exporter-1.2.0.tar.gz
mv node_exporter /data
2.设置systemctl启动
此处不改动配置文件,服务启动后的默认端口是9100
cp /data/node_exporter/node_exporter.service /usr/lib/systemd/system/
3.启动服务
使用systemctl直接启动服务
systemctl start node_exporter.service
systemctl enable node_exporter.service
systemctl status node_exporter.service
检查端口,node-exporter已经启动。

四.部署grafana
本章操作在node01进行。
1.安装和启动grafana
将下载好的grafana的rpm包上传至/root后,直接yum安装即可,自动安装依赖。
yum install -y grafana-7.3.0-1.x86_64.rpm
安装后直接启动服务。
systemctl start grafana-server.service
systemctl enable grafana-server.service
systemctl status grafana-server.service
检查3000端口打开,表示服务已启动。

2.设置prometheus数据源
首先打开本地浏览器,输入 192.168.0.201:3000 进入grafana页面,初始账号和密码都是admin,直接登录并修改密码,进入grafana首页。
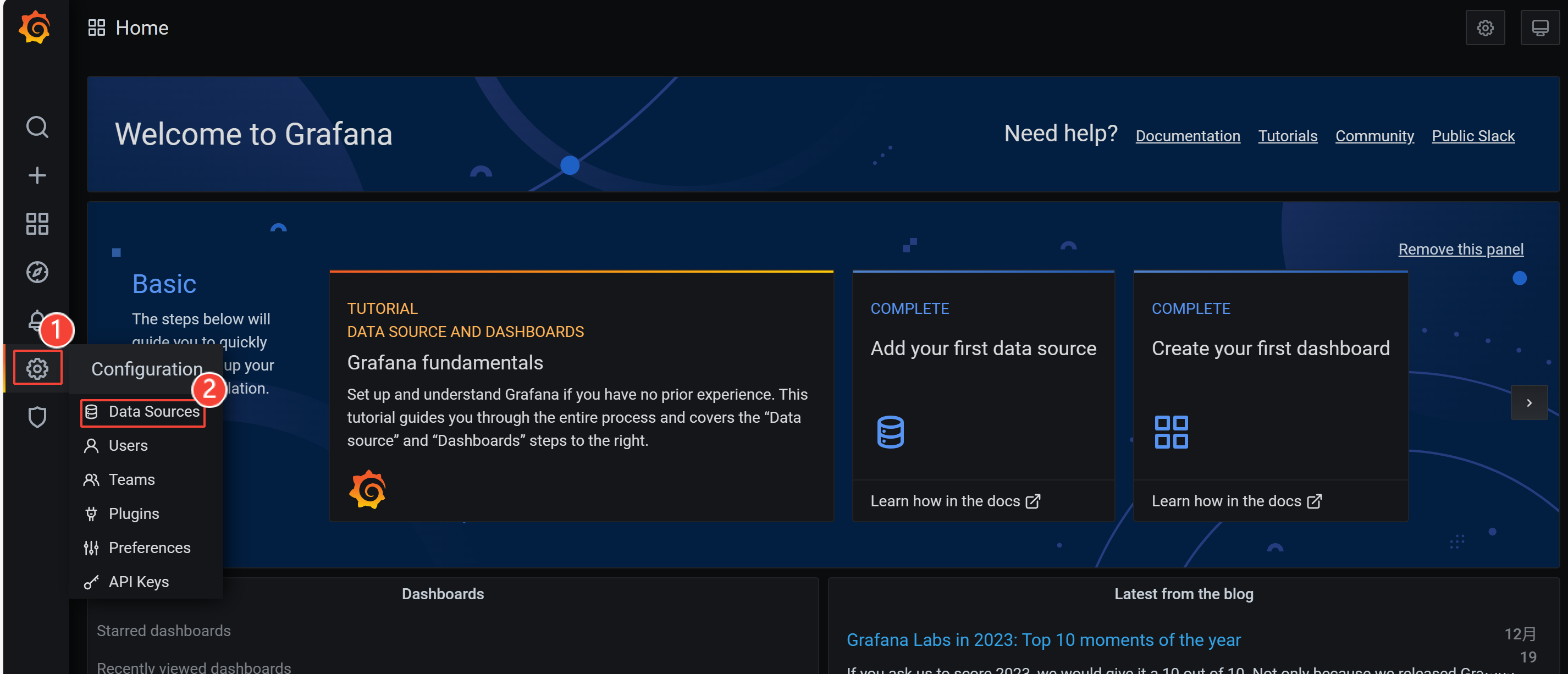
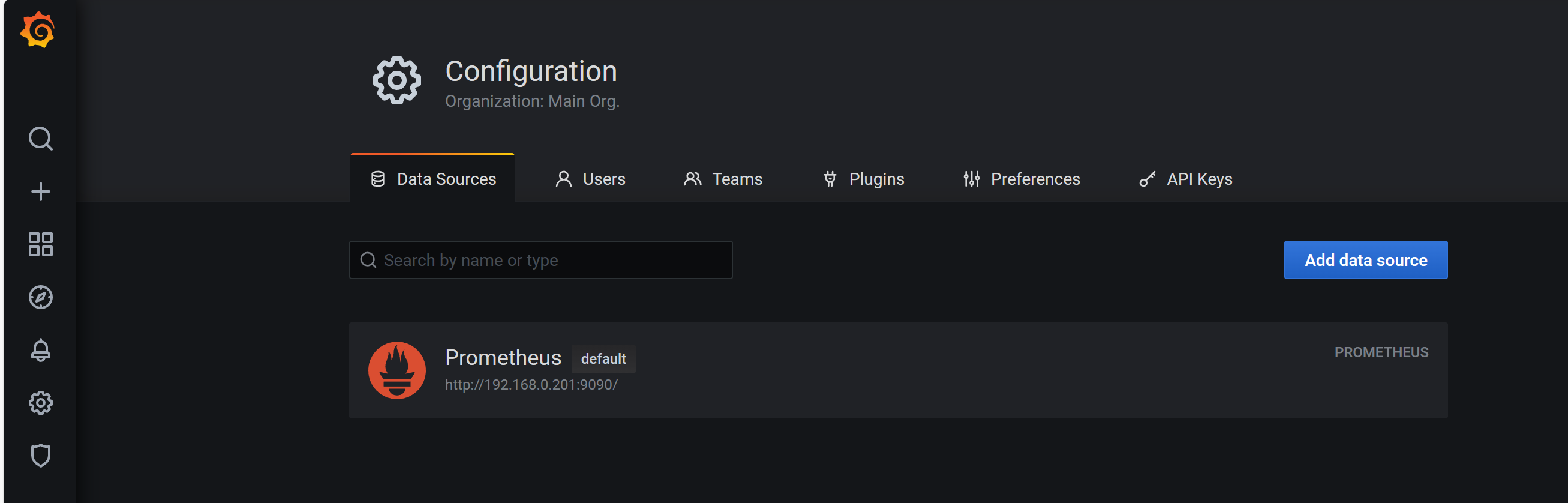
接着按照下图顺序,找到 设置---数据源 的位置进行配置
在数据源的URL框中输入node01的prometheus服务IP和端口 http://192.168.0.201:9090/
然后保存退出即可。
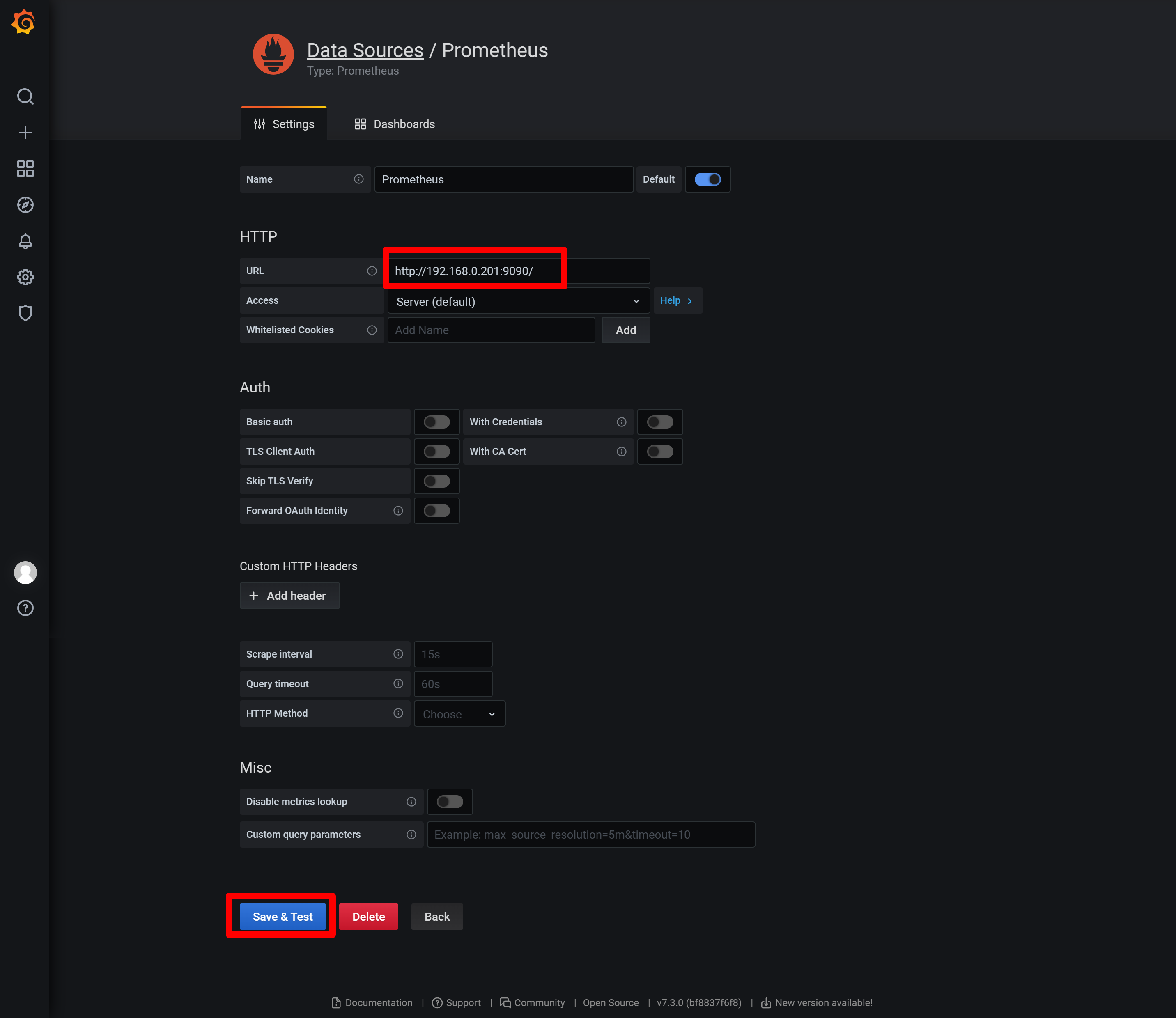
设置成功后,数据源是prometheus。
3.新增监控模板
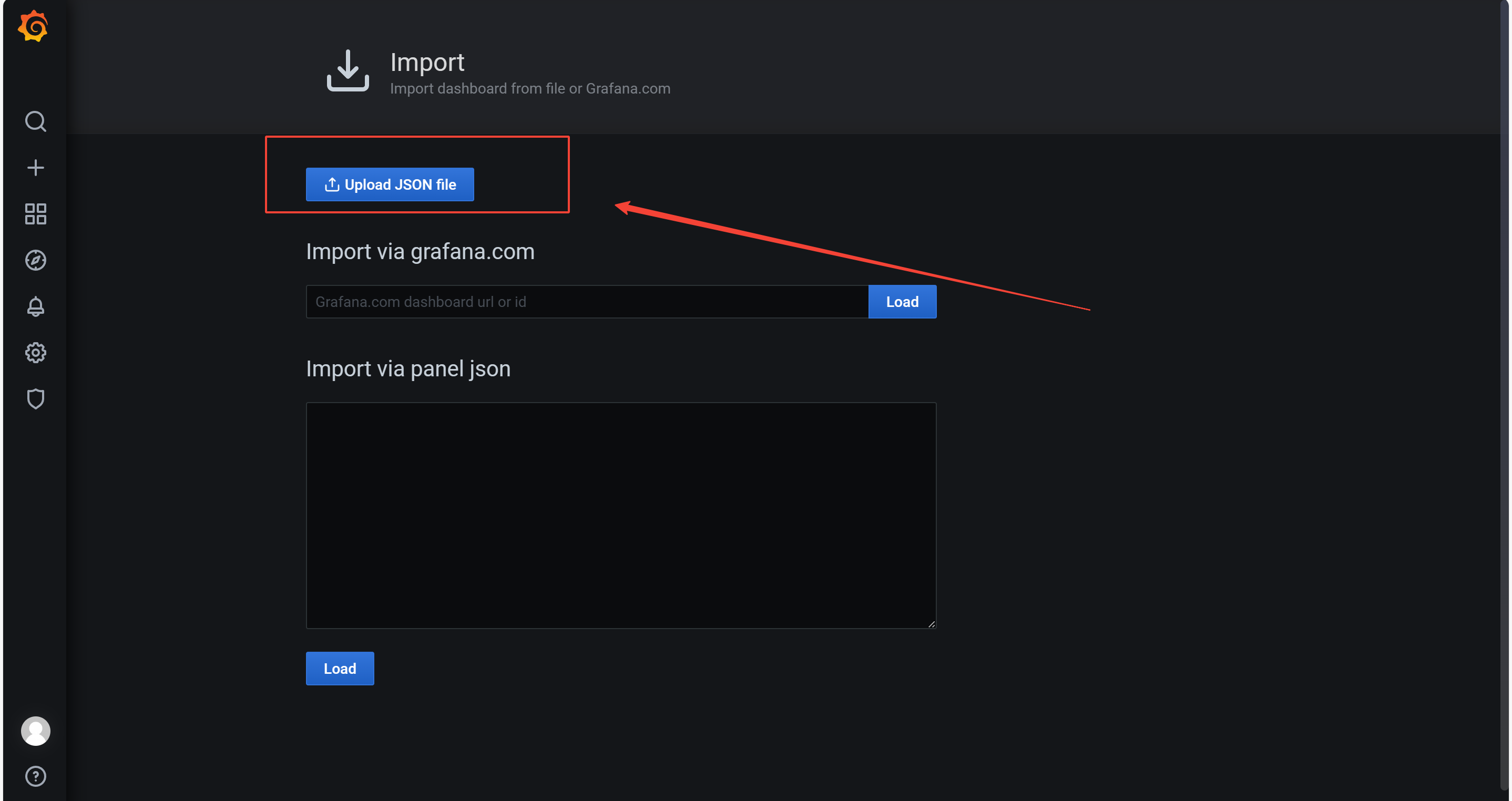
从网络上搜索Linux服务器的grafana监控模板,导入进去。

然后上传json文件,选择本地文件导入即可。
4.修改模板的变量和配置信息
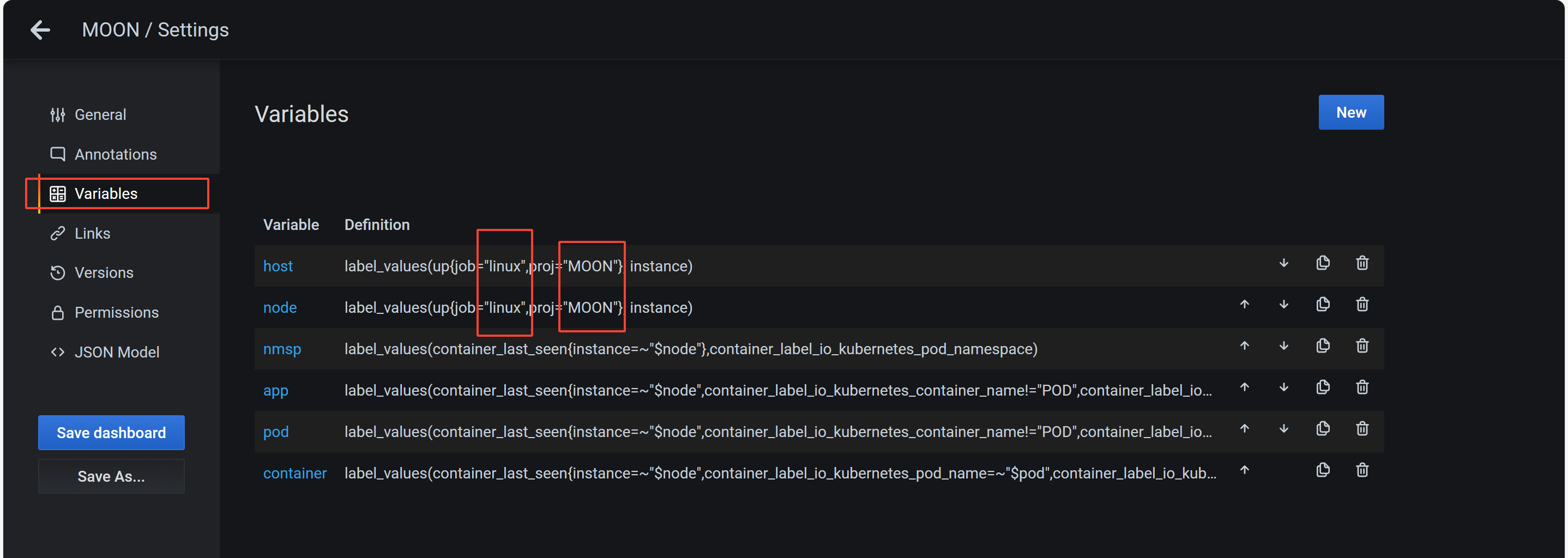
一般情况下,直接导入的模板无法使用,因为它使用了自定义的变量。
例如别人的项目名proj变量使用了 apple 指定其监控的所有资源;我们项目名proj变量使用了MOON表示监控的所有资源。
我们若要使用模板来查看监控资源的信息,需要修改变量以及prometheus查询语句的某些具体值,才能显示自己的资源监控数据。

进入配置页面后,选择变量修改,修改后的键值与hostlist下面的yml配置文件中的内容一样即可。
每一次对面板的修改都需要手动保存才能生效。
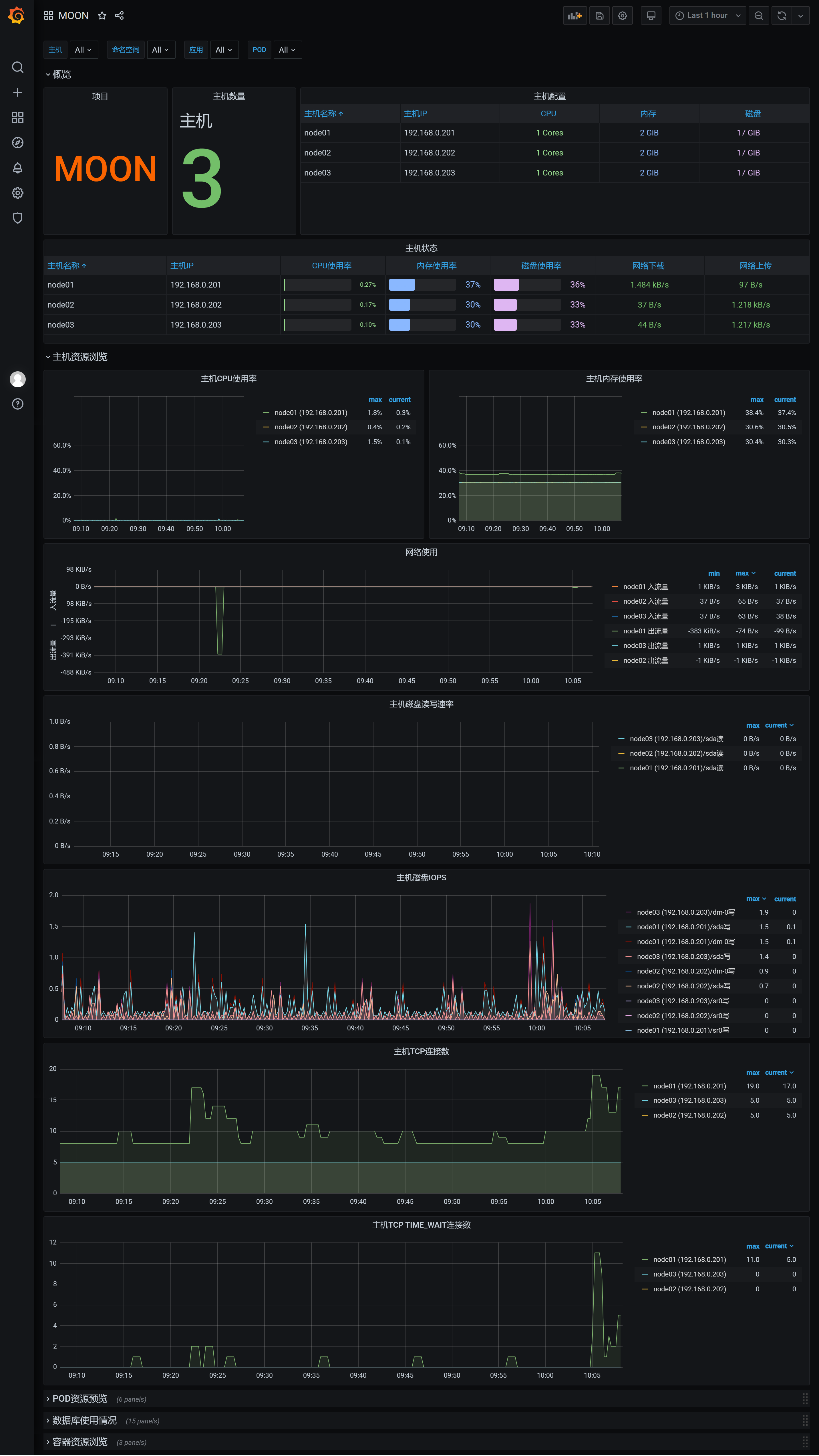
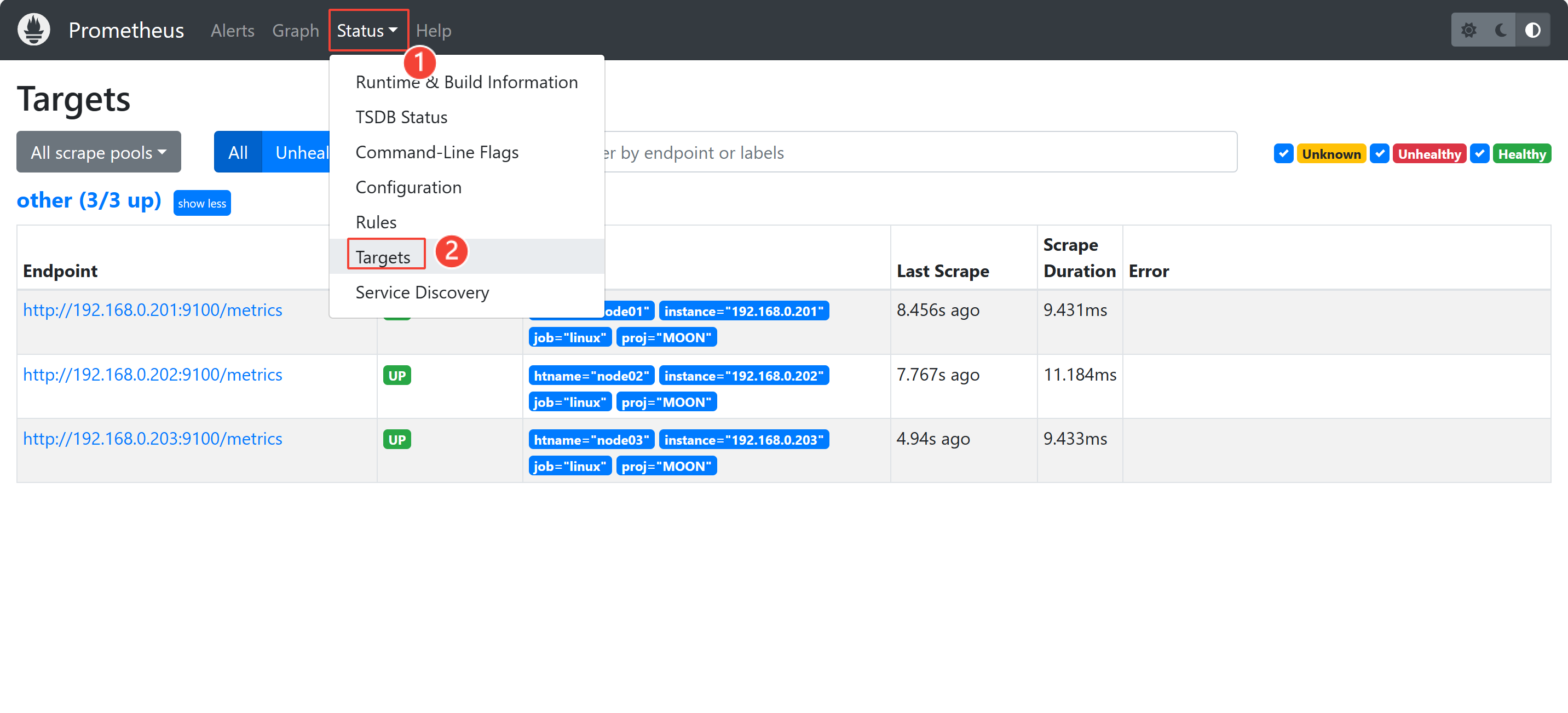
如果无法接收到数据,在浏览器输入 192.168.0.201:9090 进入prometheus服务器界面,进入 “状态”—“目标”,检查是否有监控数据。状态都是 UP 表示资源已被正常监控。
至此,Linux服务器的prometheus-grafana主机资源监控已经基本搭建完成,Windows服务器的监控只需要安装对应的node-exporter即可。