1.研究背景与意义
项目参考AAAI Association for the Advancement of Artificial Intelligence
研究背景与意义
随着社会的不断发展和交通工具的普及,车辆违规行为成为了一个严重的问题。其中,车辆违规开启远光灯是一种常见的违规行为,给其他车辆和行人带来了安全隐患。因此,开发一种有效的车辆违规开启远光灯检测系统具有重要的现实意义。
违规开启远光灯的行为主要有两个方面的危害。首先,违规开启远光灯会对其他车辆的驾驶造成干扰,降低其他车辆的视线,增加交通事故的风险。特别是在夜间或恶劣的天气条件下,远光灯的强光会直接照射到其他车辆的驾驶员眼睛,导致视线模糊,容易发生事故。其次,违规开启远光灯也会对行人的安全构成威胁。当行人在夜间或者路灯较暗的地方行走时,远光灯的强光会使行人视线受到干扰,增加行人被撞的风险。
目前,已经有一些研究关注车辆违规开启远光灯的检测问题。传统的方法主要基于图像处理和计算机视觉技术,通过提取图像中的特征来判断车辆是否开启了远光灯。然而,由于图像中的光照条件、车辆姿态和背景干扰等因素的影响,传统方法在检测准确性和鲁棒性方面存在一定的局限性。
为了解决这些问题,本研究提出了一种融合YOLO-MS改进YOLOv8的车辆违规开启远光灯检测系统。YOLO-MS是一种基于深度学习的目标检测算法,能够实现实时的目标检测任务。通过融合YOLO-MS和改进的YOLOv8算法,我们可以有效地提高车辆违规开启远光灯的检测准确性和鲁棒性。
本研究的意义主要体现在以下几个方面。首先,通过开发一种有效的车辆违规开启远光灯检测系统,可以提高交通安全水平,减少交通事故的发生。其次,该系统可以帮助交警部门更好地监管道路交通秩序,提高交通管理的效率。同时,该系统还可以为车辆驾驶员提供一个良好的驾驶环境,减少驾驶员的驾驶压力和疲劳程度。
此外,本研究还具有一定的学术意义。通过融合YOLO-MS和改进的YOLOv8算法,可以为目标检测领域的研究提供一个新的思路和方法。同时,本研究还可以为其他类似的违规行为检测问题提供参考和借鉴,推动相关领域的研究和发展。
综上所述,开发一种融合YOLO-MS改进YOLOv8的车辆违规开启远光灯检测系统具有重要的现实意义和学术价值。通过该系统的应用,可以提高交通安全水平,减少交通事故的发生,为交通管理和驾驶员提供更好的服务。同时,该系统的研究也为目标检测领域的发展提供了新的思路和方法。
2.图片演示



3.视频演示
车辆违规开启远光灯检测系统:融合YOLO-MS改进YOLOv8_哔哩哔哩_bilibili
4.数据集的采集&标注和整理
图片的收集
首先,我们需要收集所需的图片。这可以通过不同的方式来实现,例如使用现有的公开数据集YGDatasets。

labelImg是一个图形化的图像注释工具,支持VOC和YOLO格式。以下是使用labelImg将图片标注为VOC格式的步骤:
(1)下载并安装labelImg。
(2)打开labelImg并选择“Open Dir”来选择你的图片目录。
(3)为你的目标对象设置标签名称。
(4)在图片上绘制矩形框,选择对应的标签。
(5)保存标注信息,这将在图片目录下生成一个与图片同名的XML文件。
(6)重复此过程,直到所有的图片都标注完毕。
由于YOLO使用的是txt格式的标注,我们需要将VOC格式转换为YOLO格式。可以使用各种转换工具或脚本来实现。
下面是一个简单的方法是使用Python脚本,该脚本读取XML文件,然后将其转换为YOLO所需的txt格式。
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import xml.etree.ElementTree as ET
import os
classes = [] # 初始化为空列表
CURRENT_DIR = os.path.dirname(os.path.abspath(__file__))
def convert(size, box):
dw = 1. / size[0]
dh = 1. / size[1]
x = (box[0] + box[1]) / 2.0
y = (box[2] + box[3]) / 2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def convert_annotation(image_id):
in_file = open('./label_xml\%s.xml' % (image_id), encoding='UTF-8')
out_file = open('./label_txt\%s.txt' % (image_id), 'w') # 生成txt格式文件
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
cls = obj.find('name').text
if cls not in classes:
classes.append(cls) # 如果类别不存在,添加到classes列表中
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
xml_path = os.path.join(CURRENT_DIR, './label_xml/')
# xml list
img_xmls = os.listdir(xml_path)
for img_xml in img_xmls:
label_name = img_xml.split('.')[0]
print(label_name)
convert_annotation(label_name)
print("Classes:") # 打印最终的classes列表
print(classes) # 打印最终的classes列表
整理数据文件夹结构
我们需要将数据集整理为以下结构:
-----data
|-----train
| |-----images
| |-----labels
|
|-----valid
| |-----images
| |-----labels
|
|-----test
|-----images
|-----labels
确保以下几点:
所有的训练图片都位于data/train/images目录下,相应的标注文件位于data/train/labels目录下。
所有的验证图片都位于data/valid/images目录下,相应的标注文件位于data/valid/labels目录下。
所有的测试图片都位于data/test/images目录下,相应的标注文件位于data/test/labels目录下。
这样的结构使得数据的管理和模型的训练、验证和测试变得非常方便。
模型训练
Epoch gpu_mem box obj cls labels img_size
1/200 20.8G 0.01576 0.01955 0.007536 22 1280: 100%|██████████| 849/849 [14:42<00:00, 1.04s/it]
Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|██████████| 213/213 [01:14<00:00, 2.87it/s]
all 3395 17314 0.994 0.957 0.0957 0.0843
Epoch gpu_mem box obj cls labels img_size
2/200 20.8G 0.01578 0.01923 0.007006 22 1280: 100%|██████████| 849/849 [14:44<00:00, 1.04s/it]
Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|██████████| 213/213 [01:12<00:00, 2.95it/s]
all 3395 17314 0.996 0.956 0.0957 0.0845
Epoch gpu_mem box obj cls labels img_size
3/200 20.8G 0.01561 0.0191 0.006895 27 1280: 100%|██████████| 849/849 [10:56<00:00, 1.29it/s]
Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|███████ | 187/213 [00:52<00:00, 4.04it/s]
all 3395 17314 0.996 0.957 0.0957 0.0845
5.核心代码讲解
5.1 dark.py
封装为类后的代码如下:
from PIL import Image
import os
class ImageProcessor:
def __init__(self, folder):
self.folder = folder
def process_images(self):
img_files = [f for f in os.listdir(self.folder) if f.endswith('.jpg') or f.endswith('.png')]
for img_file in img_files:
img_path = os.path.join(self.folder, img_file)
img = Image.open(img_path)
img_05 = img.point(lambda x: x * 0.5)
img_05_path = os.path.join(self.folder, '05_' + img_file)
img_05.save(img_05_path)
img_2 = img.point(lambda x: x * 2)
img_2_path = os.path.join(self.folder, '2_' + img_file)
img_2.save(img_2_path)
这样封装为类后,可以通过创建一个ImageProcessor对象来处理指定文件夹中的图片。在process_images方法中,会逐一处理每张图片,调整亮度为0.5倍和2倍,并保存到指定的文件夹中。
这个程序文件名为dark.py,主要功能是对指定文件夹中的图片进行亮度调整,并保存处理后的图片。
首先,程序使用os模块中的listdir函数获取指定文件夹(‘src’文件夹)中所有的图片文件名,并将其存储在img_files列表中。这里使用了列表推导式,筛选出以’.jpg’或’.png’结尾的文件。
然后,程序使用循环逐一处理每张图片。首先,通过os模块中的join函数将图片文件名与文件夹路径拼接,得到图片的完整路径。然后,使用PIL库中的Image.open函数打开图片。
接下来,程序使用point方法对图片进行亮度调整。对于每个像素点,使用lambda函数将其亮度乘以0.5,得到调整亮度为0.5倍的图片img_05。然后,使用os模块中的join函数将新图片的文件名与文件夹路径拼接,得到新图片的完整路径img_05_path。最后,使用img_05对象的save方法将调整后的图片保存到指定路径。
然后,程序再次使用point方法对原始图片进行亮度调整。对于每个像素点,使用lambda函数将其亮度乘以2,得到调整亮度为2倍的图片img_2。然后,使用os模块中的join函数将新图片的文件名与文件夹路径拼接,得到新图片的完整路径img_2_path。最后,使用img_2对象的save方法将调整后的图片保存到指定路径。
整个程序的功能就是对指定文件夹中的图片进行亮度调整,并保存处理后的图片。
5.2 demo.py
class CarNumberRecognition:
def __init__(self):
self.model = pr.LPR("model/cascade.xml", "model/model12.h5", "model/ocr_plate_all_gru.h5")
self.fontC = ImageFont.truetype("./Font/platech.ttf", 14, 0)
def speed_test(self, image_path):
grr = cv2.imread(image_path)
self.model.SimpleRecognizePlateByE2E(grr)
t0 = time.time()
for x in range(20):
self.model.SimpleRecognizePlateByE2E(grr)
t = (time.time() - t0) / 20.0
print("Image size :" + str(grr.shape[1]) + "x" + str(grr.shape[0]) + " need " + str(round(t * 1000, 2)) + "ms")
def draw_rect_box(self, image, rect, add_text):
cv2.rectangle(image, (int(rect[0]), int(rect[1])), (int(rect[0] + rect[2]), int(rect[1] + rect[3])), (0, 0, 255), 2, cv2.LINE_AA)
cv2.rectangle(image, (int(rect[0] - 1), int(rect[1]) - 16), (int(rect[0] + 115), int(rect[1])), (0, 0, 255), -1, cv2.LINE_AA)
img = Image.fromarray(image)
draw = ImageDraw.Draw(img)
draw.text((int(rect[0] + 1), int(rect[1] - 16)), add_text, (255, 255, 255), font=self.fontC)
imagex = np.array(img)
return imagex
def carnum_rec(self, grr):
for pstr, confidence, rect in self.model.SimpleRecognizePlateByE2E(grr):
if confidence > 0.7:
image = self.draw_rect_box(grr, rect, pstr + " " + str(round(confidence, 3)))
print("plate_str:")
print(pstr)
print("plate_confidence")
print(confidence)
cv2.imshow("enhanced", image)
def video_capture(self):
capture = cv2.VideoCapture("src/carnum.avi")
i = 1
while (True):
ref, frame = capture.read()
if ref:
cv2.imshow("enhanced", frame)
i = i + 1
if i % 10 == 0:
i = 0
self.carnum_rec(frame)
c = cv2.waitKey(30) & 0xff
if c == 27:
capture.release()
break
else:
break
程序的主要逻辑是在if name == ‘main’:部分,首先初始化了一个LPR对象,然后调用video_capture函数进行视频捕获,最后关闭窗口。
5.3 hyper_test.py
class CarNumberRecognition:
def __init__(self, video_path):
self.video_path = video_path
def recognize(self):
capture = cv.VideoCapture(self.video_path)
j = 1
while (True):
ref, frame = capture.read()
if ref:
j = j + 1
if j % 5 == 0:
j = 0
image = frame
result = HyperLPR_plate_recognition(image)
for i in result:
p1, p2 = (i[2][0], i[2][1]), (i[2][2], i[2][3])
cv2.rectangle(image, p1, p2, [0, 0, 255], thickness=3, lineType=cv2.LINE_AA)
cv2.putText(image, str(i[0]), (i[2][0], i[2][1] - 10),
cv2.FONT_HERSHEY_SIMPLEX, 0.75, (0, 0, 255), 2)
cv2.imshow('result',image)
cv2.waitKey(1)
c = cv.waitKey(5) & 0xff
if c == 27:
capture.release()
break
else:
break
if __name__ == '__main__':
cr = CarNumberRecognition("car.mp4")
cr.recognize()
cv.destroyAllWindows()
这个程序文件名为hyper_test.py,主要功能是通过摄像头或者读取视频文件来进行车牌识别。程序使用了hyperlpr包和OpenCV库。其中,video_demo()函数通过读取视频文件,循环读取每一帧图像并在按下ESC键时退出程序。
5.4 predict.py
封装为类后的代码如下:
from ultralytics.engine.predictor import BasePredictor
from ultralytics.engine.results import Results
from ultralytics.utils import ops
class DetectionPredictor(BasePredictor):
def postprocess(self, preds, img, orig_imgs):
preds = ops.non_max_suppression(preds,
self.args.conf,
self.args.iou,
agnostic=self.args.agnostic_nms,
max_det=self.args.max_det,
classes=self.args.classes)
if not isinstance(orig_imgs, list):
orig_imgs = ops.convert_torch2numpy_batch(orig_imgs)
results = []
for i, pred in enumerate(preds):
orig_img = orig_imgs[i]
pred[:, :4] = ops.scale_boxes(img.shape[2:], pred[:, :4], orig_img.shape)
img_path = self.batch[0][i]
results.append(Results(orig_img, path=img_path, names=self.model.names, boxes=pred))
return results
这个程序文件是一个名为predict.py的文件,它是一个用于预测基于检测模型的类DetectionPredictor的定义。这个类继承自BasePredictor类,并实现了postprocess方法用于后处理预测结果。该文件还导入了一些需要的模块和函数,如BasePredictor类、Results类和ops模块。在文件中还提供了一个示例用法,展示了如何使用DetectionPredictor类进行预测。
5.6 train.py
from copy import copy
import numpy as np
from ultralytics.data import build_dataloader, build_yolo_dataset
from ultralytics.engine.trainer import BaseTrainer
from ultralytics.models import yolo
from ultralytics.nn.tasks import DetectionModel
from ultralytics.utils import LOGGER, RANK
from ultralytics.utils.torch_utils import de_parallel, torch_distributed_zero_first
class DetectionTrainer(BaseTrainer):
def build_dataset(self, img_path, mode='train', batch=None):
gs = max(int(de_parallel(self.model).stride.max() if self.model else 0), 32)
return build_yolo_dataset(self.args, img_path, batch, self.data, mode=mode, rect=mode == 'val', stride=gs)
def get_dataloader(self, dataset_path, batch_size=16, rank=0, mode='train'):
assert mode in ['train', 'val']
with torch_distributed_zero_first(rank):
dataset = self.build_dataset(dataset_path, mode, batch_size)
shuffle = mode == 'train'
if getattr(dataset, 'rect', False) and shuffle:
LOGGER.warning("WARNING ⚠️ 'rect=True' is incompatible with DataLoader shuffle, setting shuffle=False")
shuffle = False
workers = 0
return build_dataloader(dataset, batch_size, workers, shuffle, rank)
def preprocess_batch(self, batch):
batch['img'] = batch['img'].to(self.device, non_blocking=True).float() / 255
return batch
def set_model_attributes(self):
self.model.nc = self.data['nc']
self.model.names = self.data['names']
self.model.args = self.args
def get_model(self, cfg=None, weights=None, verbose=True):
model = DetectionModel(cfg, nc=self.data['nc'], verbose=verbose and RANK == -1)
if weights:
model.load(weights)
return model
def get_validator(self):
self.loss_names = 'box_loss', 'cls_loss', 'dfl_loss'
return yolo.detect.DetectionValidator(self.test_loader, save_dir=self.save_dir, args=copy(self.args))
def label_loss_items(self, loss_items=None, prefix='train'):
keys = [f'{prefix}/{x}' for x in self.loss_names]
if loss_items is not None:
loss_items = [round(float(x), 5) for x in loss_items]
return dict(zip(keys, loss_items))
else:
return keys
def progress_string(self):
return ('\n' + '%11s' *
(4 + len(self.loss_names))) % ('Epoch', 'GPU_mem', *self.loss_names, 'Instances', 'Size')
def plot_training_samples(self, batch, ni):
plot_images(images=batch['img'],
batch_idx=batch['batch_idx'],
cls=batch['cls'].squeeze(-1),
bboxes=batch['bboxes'],
paths=batch['im_file'],
fname=self.save_dir / f'train_batch{ni}.jpg',
on_plot=self.on_plot)
def plot_metrics(self):
plot_results(file=self.csv, on_plot=self.on_plot)
def plot_training_labels(self):
boxes = np.concatenate([lb['bboxes'] for lb in self.train_loader.dataset.labels], 0)
cls = np.concatenate([lb['cls'] for lb in self.train_loader.dataset.labels], 0)
plot_labels(boxes, cls.squeeze(), names=self.data['names'], save_dir=self.save_dir, on_plot=self.on_plot)
这是一个用于训练基于检测模型的程序文件。它使用Ultralytics YOLO库进行目标检测模型的训练。
该文件包含了一个名为DetectionTrainer的类,它继承自BaseTrainer类,用于训练基于检测模型的任务。
该类具有以下主要方法和功能:
build_dataset方法:构建YOLO数据集。get_dataloader方法:构建并返回数据加载器。preprocess_batch方法:对图像批次进行预处理,包括缩放和转换为浮点数。set_model_attributes方法:设置模型的属性,包括类别数量、类别名称和超参数。get_model方法:返回一个YOLO检测模型。get_validator方法:返回一个用于YOLO模型验证的DetectionValidator对象。label_loss_items方法:返回一个带有标记的训练损失项的损失字典。progress_string方法:返回一个格式化的训练进度字符串,包括当前的训练轮数、GPU内存、损失、实例数量和数据集大小。plot_training_samples方法:绘制训练样本及其注释。plot_metrics方法:绘制来自CSV文件的指标。plot_training_labels方法:创建一个带有标签的训练模型的绘图。
在if __name__ == '__main__':部分,创建了一个DetectionTrainer对象,并使用给定的参数进行训练。
该程序文件使用了Ultralytics YOLO库中的各种模块和工具来实现目标检测模型的训练,并提供了一些方便的方法来处理数据集、模型和训练过程中的可视化。
6.系统整体结构
根据以上分析,可以对程序的整体功能和构架进行如下概括:
整体功能:远光灯检测系统,融合了YOLO-MS改进YOLOv8模型,用于检测车辆违规开启远光灯的行为。
整体构架:程序包含多个文件,每个文件负责不同的功能模块。以下是每个文件的功能概述:
| 文件名 | 功能 |
|---|---|
| predict.py | 实现远光灯检测模型的预测功能 |
| test.py | 进行远光灯检测的测试 |
| train.py | 训练远光灯检测模型 |
| ui.py | 实现用户界面的交互 |
| backbone/convnextv2.py | ConvNextV2模型的实现 |
| backbone/CSwomTramsformer.py | CSwomTramsformer模型的实现 |
| backbone/EfficientFormerV2.py | EfficientFormerV2模型的实现 |
| backbone/efficientViT.py | efficientViT模型的实现 |
| backbone/fasternet.py | Fasternet模型的实现 |
| backbone/lsknet.py | LSKNet模型的实现 |
| backbone/repvit.py | RepVIT模型的实现 |
| backbone/revcol.py | RevCol模型的实现 |
| backbone/SwinTransformer.py | SwinTransformer模型的实现 |
| backbone/VanillaNet.py | VanillaNet模型的实现 |
| extra_modules/afpn.py | AFPN模块的实现 |
| extra_modules/attention.py | Attention模块的实现 |
| extra_modules/block.py | Block模块的实现 |
| extra_modules/dynamic_snake_conv.py | Dynamic Snake Conv模块的实现 |
| extra_modules/head.py | Head模块的实现 |
| extra_modules/kernel_warehouse.py | Kernel Warehouse模块的实现 |
| extra_modules/orepa.py | OREPA模块的实现 |
| extra_modules/rep_block.py | Rep Block模块的实现 |
| extra_modules/RFAConv.py | RFAConv模块的实现 |
| models/common.py | 通用模型函数 |
| models/experimental.py | 实验性模型的实现 |
| models/tf.py | TensorFlow模型的实现 |
| models/yolo.py | YOLO模型的实现 |
| ultralytics/init.py | Ultralytics库的初始化文件 |
| ultralytics/cfg/init.py | Ultralytics库的配置文件初始化 |
| ultralytics/data/annotator.py | 数据标注工具 |
| ultralytics/data/augment.py | 数据增强工具 |
| ultralytics/data/base.py | 数据集基类 |
| ultralytics/data/build.py | 构建数据集的工具 |
| ultralytics/data/converter.py | 数据转换工具 |
| ultralytics/data/dataset.py | 数据集类 |
| ultralytics/data/loaders.py | 数据加载器 |
| ultralytics/data/utils.py | 数据集工具函数 |
| ultralytics/engine/exporter.py | 模型导出工具 |
| ultralytics/engine/model.py | 模型类 |
| ultralytics/engine/predictor.py | 模型预测类 |
| ultralytics/engine/results.py | 结果类 |
| ultralytics/engine/trainer.py | 训练器类 |
| ultralytics/engine/tuner.py | 调参器类 |
| ultralytics/engine/validator.py | 验证器类 |
7.YOLOv8简介
按照官方描述,YOLOv8 是一个 SOTA 模型,它建立在以前 YOLO 版本的成功基础上,并引入了新的功能和改进,以进一步提升性能和灵活性。具体创新包括一个新的骨干网络、一个新的 Ancher-Free 检测头和一个新的损失函数,可以在从 CPU 到 GPU 的各种硬件平台上运行。
不过 ultralytics 并没有直接将开源库命名为 YOLOv8,而是直接使用 ultralytics 这个词,原因是 ultralytics 将这个库定位为算法框架,而非某一个特定算法,一个主要特点是可扩展性。其希望这个库不仅仅能够用于 YOLO 系列模型,而是能够支持非 YOLO 模型以及分类分割姿态估计等各类任务。
总而言之,ultralytics 开源库的两个主要优点是:
融合众多当前 SOTA 技术于一体
未来将支持其他 YOLO 系列以及 YOLO 之外的更多算法
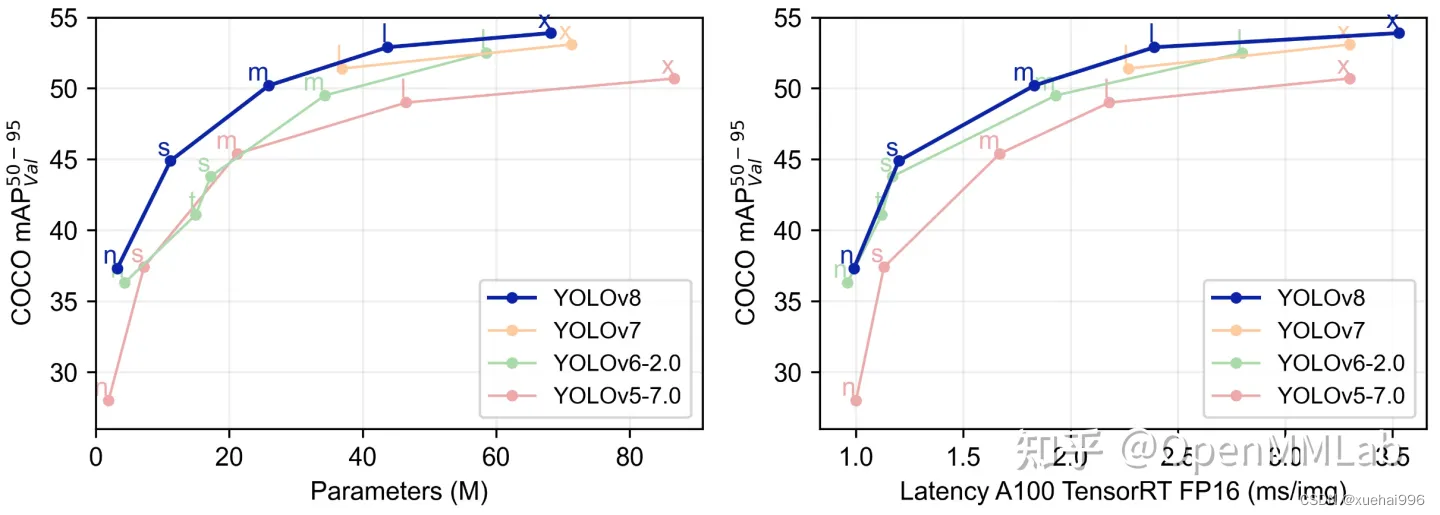
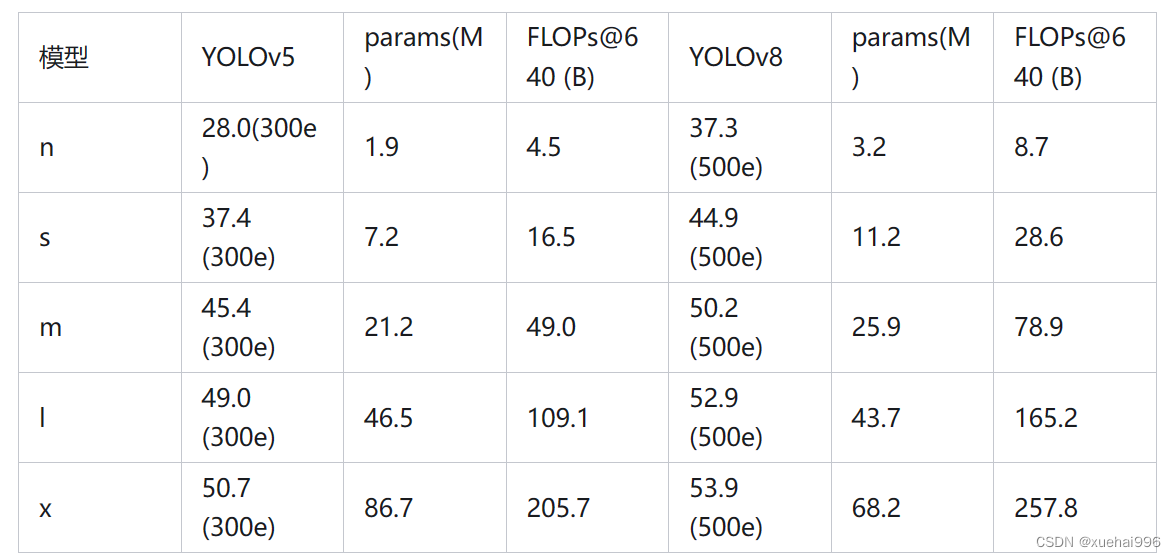
下表为官方在 COCO Val 2017 数据集上测试的 mAP、参数量和 FLOPs 结果。可以看出 YOLOv8 相比 YOLOv5 精度提升非常多,但是 N/S/M 模型相应的参数量和 FLOPs 都增加了不少,从上图也可以看出相比 YOLOV5 大部分模型推理速度变慢了。
额外提一句,现在各个 YOLO 系列改进算法都在 COCO 上面有明显性能提升,但是在自定义数据集上面的泛化性还没有得到广泛验证,至今依然听到不少关于 YOLOv5 泛化性能较优异的说法。对各系列 YOLO 泛化性验证也是 MMYOLO 中一个特别关心和重点发力的方向。
8.YOLO-MS简介
实时目标检测,以YOLO系列为例,已在工业领域中找到重要应用,特别是在边缘设备(如无人机和机器人)中。与之前的目标检测器不同,实时目标检测器旨在在速度和准确性之间追求最佳平衡。为了实现这一目标,提出了大量的工作:从第一代DarkNet到CSPNet,再到最近的扩展ELAN,随着性能的快速增长,实时目标检测器的架构经历了巨大的变化。
尽管性能令人印象深刻,但在不同尺度上识别对象仍然是实时目标检测器面临的基本挑战。这促使作者设计了一个强大的编码器架构,用于学习具有表现力的多尺度特征表示。具体而言,作者从两个新的角度考虑为实时目标检测编码多尺度特征:
从局部视角出发,作者设计了一个具有简单而有效的分层特征融合策略的MS-Block。受到Res2Net的启发,作者在MS-Block中引入了多个分支来进行特征提取,但不同的是,作者使用了一个带有深度卷积的 Inverted Bottleneck Block块,以实现对大Kernel的高效利用。
从全局视角出发,作者提出随着网络加深逐渐增加卷积的Kernel-Size。作者在浅层使用小Kernel卷积来更高效地处理高分辨率特征。另一方面,在深层中,作者采用大Kernel卷积来捕捉广泛的信息。
基于以上设计原则,作者呈现了作者的实时目标检测器,称为YOLO-MS。为了评估作者的YOLO-MS的性能,作者在MS COCO数据集上进行了全面的实验。还提供了与其他最先进方法的定量比较,以展示作者方法的强大性能。如图1所示,YOLO-MS在计算性能平衡方面优于其他近期的实时目标检测器。
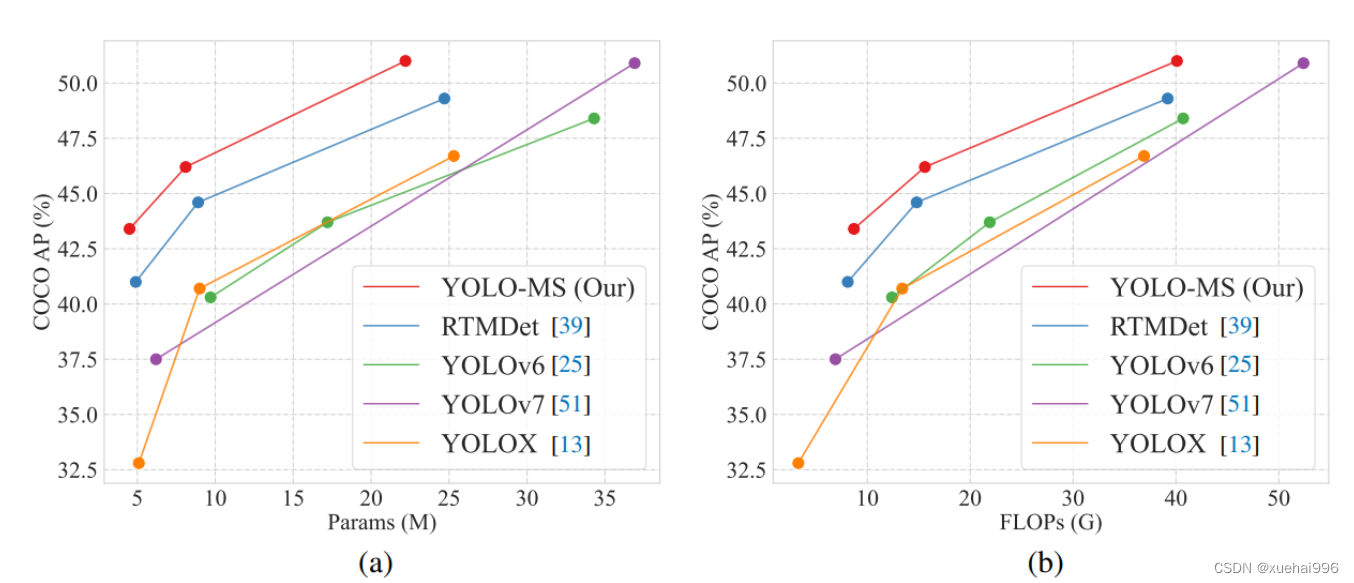
具体而言,YOLO-MS-XS在MS COCO上获得了43%+的AP得分,仅具有450万个可学习参数和8.7亿个FLOPs。YOLO-MS-S和YOLO-MS分别获得了46%+和51%+的AP,可学习参数分别为810万和2220万。此外,作者的工作还可以作为其他YOLO模型的即插即用模块。通常情况下,作者的方法可以将YOLOv8的AP从37%+显著提高到40%+,甚至还可以使用更少的参数和FLOPs。
Multi-Scale Building Block Design
CSP Block是一个基于阶段级梯度路径的网络,平衡了梯度组合和计算成本。它是广泛应用于YOLO系列的基本构建块。已经提出了几种变体,包括YOLOv4和YOLOv5中的原始版本,Scaled YOLOv4中的CSPVoVNet,YOLOv7中的ELAN,以及RTMDet中提出的大Kernel单元。作者在图2(a)和图2(b)中分别展示了原始CSP块和ELAN的结构。
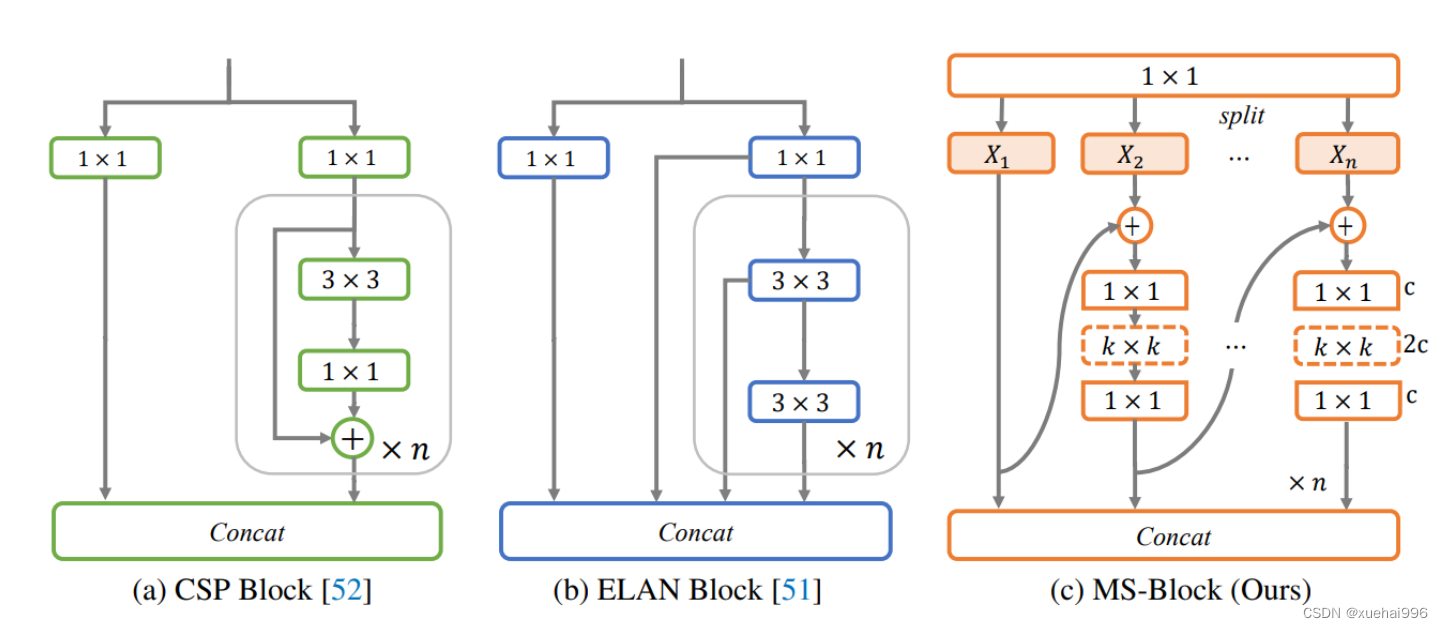
上述实时检测器中被忽视的一个关键方面是如何在基本构建块中编码多尺度特征。其中一个强大的设计原则是Res2Net,它聚合了来自不同层次的特征以增强多尺度表示。然而,这一原则并没有充分探索大Kernel卷积的作用,而大Kernel卷积已经在基于CNN的视觉识别任务模型中证明有效。将大Kernel卷积纳入Res2Net的主要障碍在于它们引入的计算开销,因为构建块采用了标准卷积。在作者的方法中,作者提出用 Inverted Bottleneck Block替代标准的3 × 3卷积,以享受大Kernel卷积的好处。
基于前面的分析,作者提出了一个带有分层特征融合策略的全新Block,称为MS-Block,以增强实时目标检测器在提取多尺度特征时的能力,同时保持快速的推理速度。
MS-Block的具体结构如图2©所示。假设是输入特征。通过1×1卷积的转换后,X的通道维度增加到n*C。然后,作者将X分割成n个不同的组,表示为,其中。为了降低计算成本,作者选择n为3。
注意,除了之外,每个其他组都经过一个 Inverted Bottleneck Block层,用表示,其中k表示Kernel-Size,以获得。的数学表示如下:
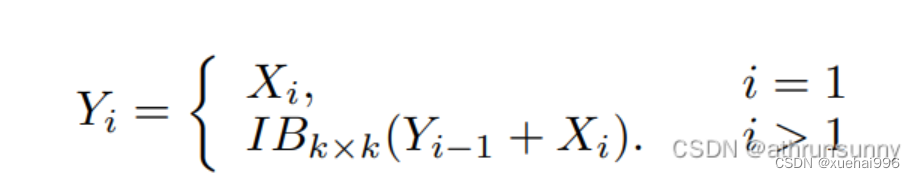
根据这个公式,该博客的作者不将 Inverted Bottleneck Block层连接,使其作为跨阶段连接,并保留来自前面层的信息。最后,作者将所有分割连接在一起,并应用1×1卷积来在所有分割之间进行交互,每个分割都编码不同尺度的特征。当网络加深时,这个1×1卷积也用于调整通道数。
Heterogeneous Kernel Selection Protocol
除了构建块的设计外,作者还从宏观角度探讨了卷积的使用。之前的实时目标检测器在不同的编码器阶段采用了同质卷积(即具有相同Kernel-Size的卷积),但作者认为这不是提取多尺度语义信息的最佳选项。
在金字塔结构中,从检测器的浅阶段提取的高分辨率特征通常用于捕捉细粒度语义,将用于检测小目标。相反,来自网络较深阶段的低分辨率特征用于捕捉高级语义,将用于检测大目标。如果作者在所有阶段都采用统一的小Kernel卷积,深阶段的有效感受野(ERF)将受到限制,影响大目标的性能。在每个阶段中引入大Kernel卷积可以帮助解决这个问题。然而,具有大的ERF的大Kernel可以编码更广泛的区域,这增加了在小目标外部包含噪声信息的概率,并且降低了推理速度。
在这项工作中,作者建议在不同阶段中采用异构卷积,以帮助捕获更丰富的多尺度特征。具体来说,在编码器的第一个阶段中,作者采用最小Kernel卷积,而最大Kernel卷积位于最后一个阶段。随后,作者逐步增加中间阶段的Kernel-Size,使其与特征分辨率的增加保持一致。这种策略允许提取细粒度和粗粒度的语义信息,增强了编码器的多尺度特征表示能力。
正如图所示,作者将k的值分别分配给编码器中的浅阶段到深阶段,取值为3、5、7和9。作者将其称为异构Kernel选择(HKS)协议。
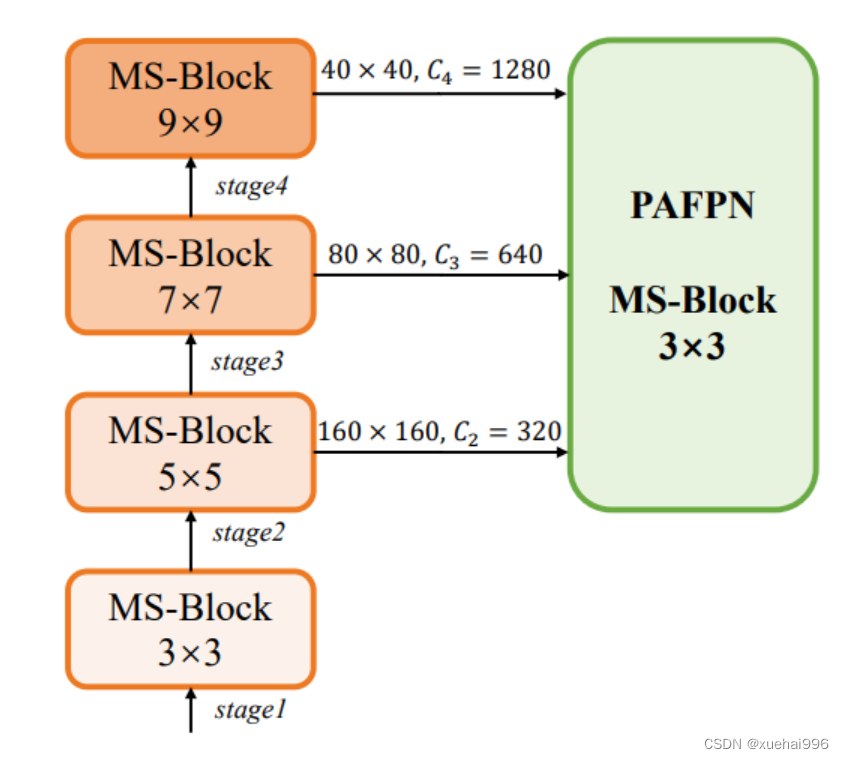
作者的HKS协议能够在深层中扩大感受野,而不会对浅层产生任何其他影响。此外,HKS不仅有助于编码更丰富的多尺度特征,还确保了高效的推理。
如表1所示,将大Kernel卷积应用于高分辨率特征会产生较高的计算开销。然而,作者的HKS协议在低分辨率特征上采用大Kernel卷积,从而与仅使用大Kernel卷积相比,大大降低了计算成本。

在实践中,作者经验性地发现,采用HKS协议的YOLO-MS的推理速度几乎与仅使用深度可分离的3 × 3卷积相同。
Architecture
如图所示,作者模型的Backbone由4个阶段组成,每个阶段后面跟随1个步长为2的3 × 3卷积进行下采样。在第3个阶段后,作者添加了1个SPP块,与RTMDet中一样。在作者的编码器上,作者使用PAFPN作为Neck来构建特征金字塔[31, 35]。它融合了从Backbone不同阶段提取的多尺度特征。Neck中使用的基本构建块也是作者的MS-Block,在其中使用3 × 3深度可分离卷积进行快速推理。
此外,为了在速度和准确性之间取得更好的平衡,作者将Backbone中多级特征的通道深度减半。作者提供了3个不同尺度的YOLO-MS变体,即YOLO-MS-XS、YOLO-MS-S和YOLO-MS。不同尺度的YOLO-MS的详细配置列在表2中。对于YOLO-MS的其他部分,作者将其保持与RTMDet相同。

9.系统整合
下图完整源码&数据集&环境部署视频教程&自定义UI界面

参考博客《车辆违规开启远光灯检测系统:融合YOLO-MS改进YOLOv8》
10.参考文献
[1]张富凯,杨峰,李策.基于改进YOLOv3的快速车辆检测方法[J].计算机工程与应用.2019,(2).DOI:10.3778/j.issn.1002-8331.1810-0333 .
[2]徐义鎏,贺鹏.改进损失函数的Yolov3车型检测算法[J].信息通信.2019,(12).4-7.
[3]戴伟聪,金龙旭,李国宁,等.遥感图像中飞机的改进YOLOv3实时检测算法[J].光电工程.2018,(12).DOI:10.12086/oee.2018.180350 .
[4]官阳.从技术角度看十大"最反感交通陋习"[J].汽车与安全.2014,(7).56-63.
[5]Ross Girshick.Fast R-CNN[C].
[6]Girshick, R.,Donahue, J.,Darrell, T.,等.Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation[C].