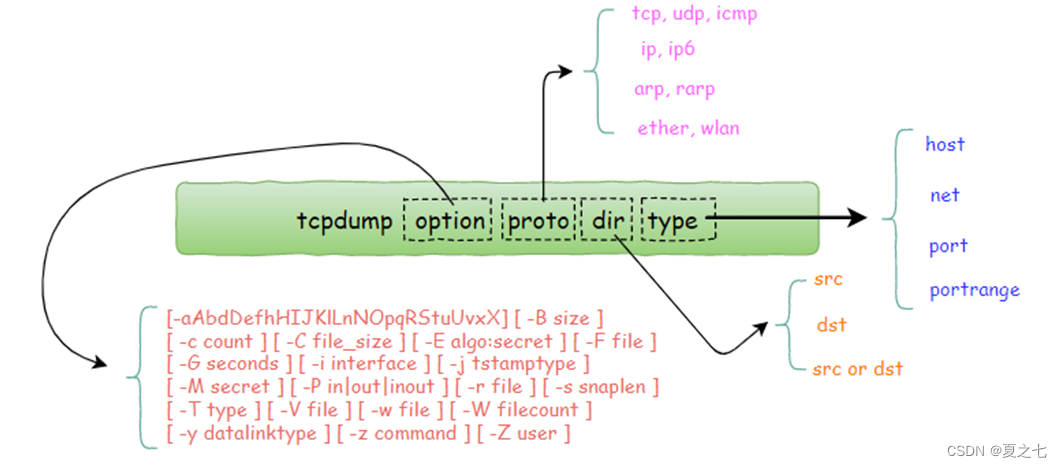
LVM: Sequential Modeling Enables Scalable Learning for Large Vision Models
TL; DR:本文提出一种纯视觉的序列建模方法 LVM,不需要任何文本数据。通过 visual sentences 的形式,统一图像/视频/标注/3D数据,使用 VQGAN 将视觉数据编码为 token,然后进行预测下一个 token 的自回归式训练。在测试时,通过构建合适的 visual prompt,可以处理各种各样的视觉任务,展现出一定的视觉智能。
引言
本文定义了一种称为 “visual sentences” 的通用格式,它既可以表征原始的图像/视频数据,也可以表征带标注的视觉数据,如分割图、深度图重建等。并且,visual sentences 只需要图像像素本身,而无需任何其他 meta 数据。作者构建了一个含有 420B 视觉 token 的超大数据集。把视觉 token 组织成 visual sentences 序列之后,模型的训练目标就是自回归式的预测序列中的下一个 token,通过交叉熵函数来优化。实验表明,在增大模型参数量时,LVM 的性能也稳步上升,具有良好的可扩展性。
数据
为了将各种各样的视觉数据(图片、视频、3D、标注图)统一起来,本文提出了 visual sentences 的概念,将有连续或相近语义的图像放到同一个 visual sentence 中。下图具体展示了各种视觉数据组织成 visual sentence 的方式,文中也有详尽的描写,这里不逐个说了。总之关键就是把语义连续或相近的视觉数据,放到一起,让模型学习到某种变换(时序/位置)。

方法
采用两阶段的训练方式,1) 先训练一个大型的视觉 tokenizer(该阶段的训练仅需在单张图像上进行);2) 训练自回归的 transformer 模型,预测下一个 token (该阶段需要 visual sentences 序列)

Image Tokenization
transformer 最开始提出时是用于处理自然语言这种序列数据,而图像数据天然不是序列数据。要使用 transformer 来处理图像,需要先转换成 token,一般有两种做法:一是直接将图像网格切分成 patch,映射为特征,并按照扫描序来排成一个序列,如 ViT;二是将网格图像切成 patch 提取特征之后,将特征聚类离散化到一个 codebook 中,然后排成一个序列,如 vqvae、vqgan 等。
后一种做法的好处是能将天然连续的图像数据离散化为 codebook 中的有限个的 token,这里的 codebook 就相当于 NLP 中的词表,特征提取器(如 vqgan)就相当于 NLP 中的 tokenizer。从而,就可以用交叉熵损失来进行自回归式的预测下一个 token 的训练。
这里,LVM 要做视觉自回归预训练,自然选择的是第二种做法,具体来说,就是 vqgan。vqgan 由编码器和解码器组成,他们分别负责将真实图像编码为 token,和将 token 解码回真实图像。此外,vqgan 还包括一个量化层,用于将输入序列中的各个 token 映射到 codebook 中。
Sequence Modeling of Visual Sentences
第一阶段 vqgan 训练完成之后,使用 vqgan 提取每张图像的 tokens(256 个),然后将多张图像的 tokens 拼接起来,就是所谓的 visual sentences。这里值得一提的是,LVM 没有使用额外的特殊 token 来标识不同的任务,期望能得到更好的泛化性能。本阶段即训练一个 causal 的 transformer(LVM 采用了与 LLaMA 相同的结构),进行自回归式的预测下一个 token 的训练。
实验
可以看到,通过构建合适的 visual prompt,LVM 的确能完成各式各样的视觉任务。如关键点检测、语义分割等。

LVM 甚至能做一些智力题,纯视觉大模型展示出了一定的智能。作者称这为 “Sparks of AGI”。(AGI 的火花?个人感觉有点过了 hh

scaling 效果也不错,随着模型参数量堆上来,性能有明显的提升。

总结
LVM 是一篇很有价值的工作,找到一种方式统一了视觉数据,并进行预测下一个视觉 token 的自回归式训练。证明了不借助其他模态的数据(如文本),纯视觉视觉也有机会涌现出智能。






![[微服务 ]微服务集成中的3个常见缺陷,以及如何避免它们](https://img-blog.csdnimg.cn/img_convert/fc482cdd5d271782b818f2771f147112.jpeg)