Python新闻文本分类系统的设计与实现:基于Flask、贝叶斯算法的B/S架构
- 引言
- 数据获取与处理
- 数据分析与可视化
- 文本分类模型
- 结论
引言
在信息爆炸的时代,新闻数据的快速获取和准确分类变得尤为重要。本文将介绍一种基于Python语言、Flask技术、B/S架构以及贝叶斯算法的新闻文本分类系统的设计与实现。我们通过爬取中国新闻网站的网页数据来构建我们的数据集,并借助Python爬虫代码实现对新闻数据的获取。

数据获取与处理
首先,我们通过Python爬虫代码对新闻数据进行获取。这些新闻数据包含了相应的分类标签,为后续的文本分类奠定了基础。然后,我们对获取的新闻数据进行了一系列处理,包括去除重复值、去除异常值、截取纯文本和标签列等。这确保了我们的数据质量,并为后续的分析和分类做好了准备。
数据分析与可视化
在对新闻数据进行处理后,我们进行了简单但重要的分析和可视化工作,以了解数据的分布规律。通过可视化图表,我们可以更清晰地看到不同分类的新闻数据在数据集中的分布情况,为进一步的分类模型建立提供了有力支持。
文本分类模型
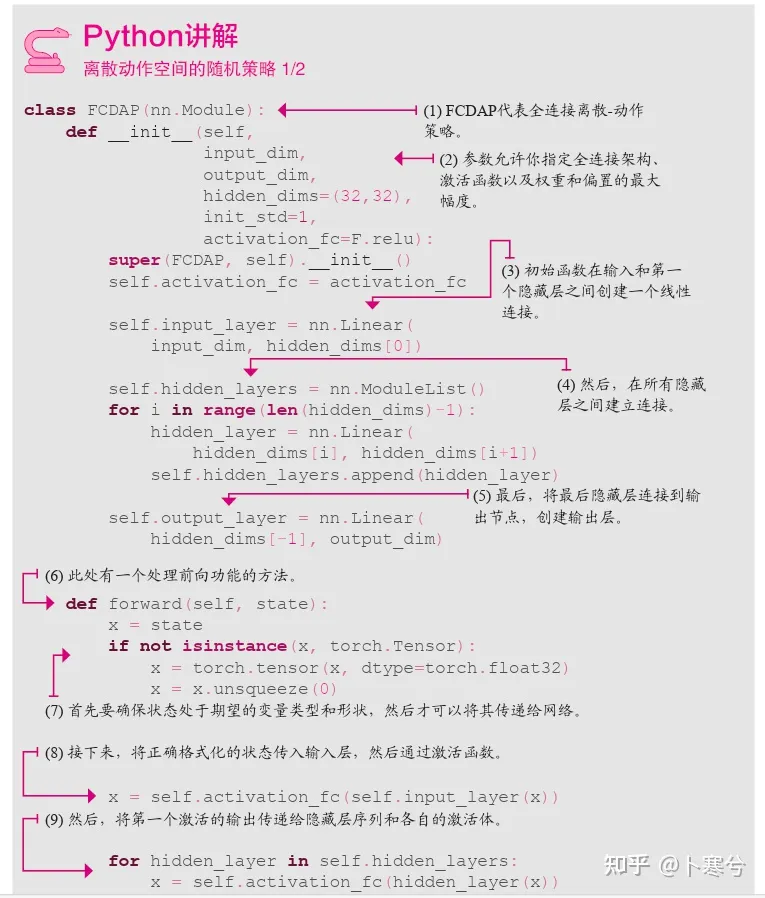
为了实现新闻文本的准确分类,我们引入了朴素贝叶斯模型。在分类之前,我们进行了分词、去停用词、向量化等处理,以便更好地表征文本特征。通过训练和评估模型,我们最终得到了一个高效的新闻文本分类系统。
结论
通过本文介绍的新闻文本分类系统,我们成功地利用Python语言、Flask技术和贝叶斯算法构建了一个B/S架构的系统。这个系统不仅实现了对新闻数据的高效获取和处理,还通过朴素贝叶斯模型实现了准确的文本分类。这为类似应用提供了一个有益的参考,展示了Python在处理大规模文本数据中的强大能力。