爬取电影TOP250
- 1 知识小课堂
- 1.1 什么是爬虫
- 1.2 爬虫能做什么
- 2 代码解析
- 2.1 运行环境
- 2.2 过程解析
- 2.2.1 第一步:引入两个模块
- 2.2.2 找到网址
- 2.2.3 拉去页面全内容
- 2.2.4
- 2.3 完整代码
1 知识小课堂
1.1 什么是爬虫

爬虫,也叫网络蜘蛛,如果把互联网比喻成一个蜘蛛网,那么蜘蛛就是在网上爬来爬去的蜘蛛。网络爬虫按照系统结构和实现细节,大体可以分为以下几种:
- 通用网络爬虫:这是一种基本的爬虫程序,通过请求URL地址,根据响应的内容进行解析和采集数据。例如,如果响应内容是HTML,它会分析DOM结构,进行DOM解析或者正则匹配;如果响应内容是XML/JSON数据,它会将数据转换为数据对象,然后对数据进行解析。
- 聚焦网络爬虫:这是一种针对特定主题和领域的爬虫程序,它只爬取和主题或领域相关的网页。例如,它可以爬取所有的新闻网站,或者所有的电商网站。
- 增量式网络爬虫:这种爬虫程序会定期爬取互联网上的新内容,而不是重新爬取所有的网页。
- 深层网络爬虫:这种爬虫程序会爬取互联网上隐藏较深的网页,例如需要登录、填写表单等才能访问的网页。
爬虫的主要作用是利用程序批量爬取网页上的公开信息,也就是前端显示的数据信息。因为这些信息是完全公开的,所以是合法的。其实就像浏览器一样,浏览器解析响应内容并渲染为页面,而爬虫解析响应内容采集想要的数据进行存储。
1.2 爬虫能做什么
爬虫能做的事情非常多,以下是详细介绍:

- 收集数据:爬虫程序可以用于收集大量数据。由于爬虫程序可以快速地爬取大量网页,因此可以用于收集各种类型的数据,例如新闻、社交媒体、产品价格、股票价格等等。这些数据可以用于各种分析,例如市场调研、商业分析、竞争分析等等。
- 调研:爬虫程序也可以用于调研。例如,可以爬取某个公司的网站,收集其产品信息、销售情况、客户反馈等等,以便更好地了解该公司的运营情况。此外,爬虫程序还可以用于监测网站的内容变化,以便及时了解该网站的最新动态。
- 刷流量和秒杀:爬虫程序还可以用于刷流量和秒杀。例如,可以在电商网站上爬取大量的商品信息,然后利用爬虫程序模拟用户的购买行为,从而增加该网站的流量和销售额。此外,爬虫程序还可以用于抢购限时优惠商品,例如秒杀活动等等。
- 自动化测试:爬虫程序也可以用于自动化测试。例如,可以利用爬虫程序模拟用户的操作行为,对网站进行各种测试,例如登录测试、表单提交测试、页面跳转测试等等。这样可以大大提高测试的效率和准确性。
- 搜索引擎优化:爬虫程序还可以用于搜索引擎优化。例如,可以利用爬虫程序收集竞争对手的网站信息,分析其关键词使用情况、页面结构等等,从而优化自己的网站,提高在搜索引擎中的排名。
总之,爬虫程序是一个非常强大的工具,可以用于各种领域和用途。但是需要注意的是,在使用爬虫程序时需要遵守网站的规则和法律法规,不得侵犯他人的权益和隐私。
2 代码解析
这里使用Python做爬虫,具体代码解析如下:
2.1 运行环境
- PyCharm
- Python3.10
2.2 过程解析
2.2.1 第一步:引入两个模块
requests和re
- request 模块
requests是一个很实用的Python HTTP客户端库,爬虫和测试服务器响应数据时经常会用到,它是python语言的第三方的库,专门用于发送HTTP请求,使用起来比urllib更简洁也更强大。 - re 模块
Python的re模块是Python内置的正则表达式处理模块,首先需要导入该模块,然后使用re模块中的函数和方法来进行正则表达式的匹配和处理。它提供了对正则表达式的支持,使得我们可以使用正则表达式来匹配和处理字符串。
下面是一些常用的re模块函数和方法:
compile():该函数用于编译正则表达式,返回一个Pattern对象。
import re
pattern = re.compile(r'\d+')
match():该方法用于从字符串的开头开始匹配正则表达式,如果匹配成功,返回一个匹配对象,否则返回None。
import re
pattern = re.compile(r'\d+')
match = pattern.match('123abc')
if match:
print(match.group()) # 输出: 123
search():该方法用于在字符串中搜索正则表达式,如果匹配成功,返回一个匹配对象,否则返回None。它会从字符串的开头开始搜索。
import re
pattern = re.compile(r'\d+')
match = pattern.search('abc123def')
if match:
print(match.group()) # 输出: 123
findall():该方法用于在字符串中查找所有与正则表达式匹配的子串,并返回一个包含所有匹配结果的列表。
import re
pattern = re.compile(r'\d+')
matches = pattern.findall('abc123def456ghi')
print(matches) # 输出: ['123', '456']
除了以上几个常用的函数和方法外,re模块还提供了其他一些功能,如替换、分割字符串等。具体可以参考Python官方文档或相关教程来了解更多内容。
2.2.2 找到网址
https://movie.douban.com/top250
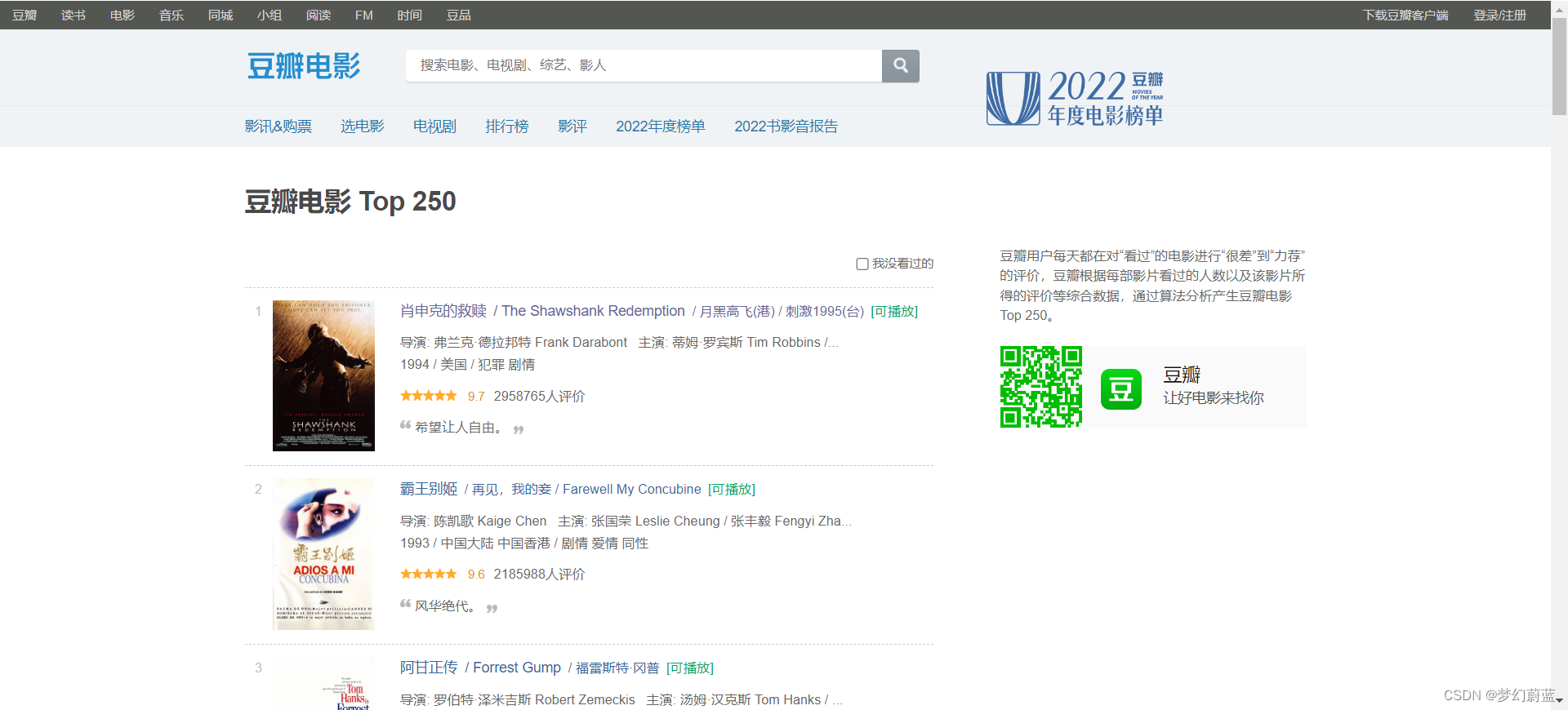
2.2.3 拉去页面全内容
import requests
import re
url = 'https://movie.douban.com/top250'
response = requests.get(url)
print(response.text)
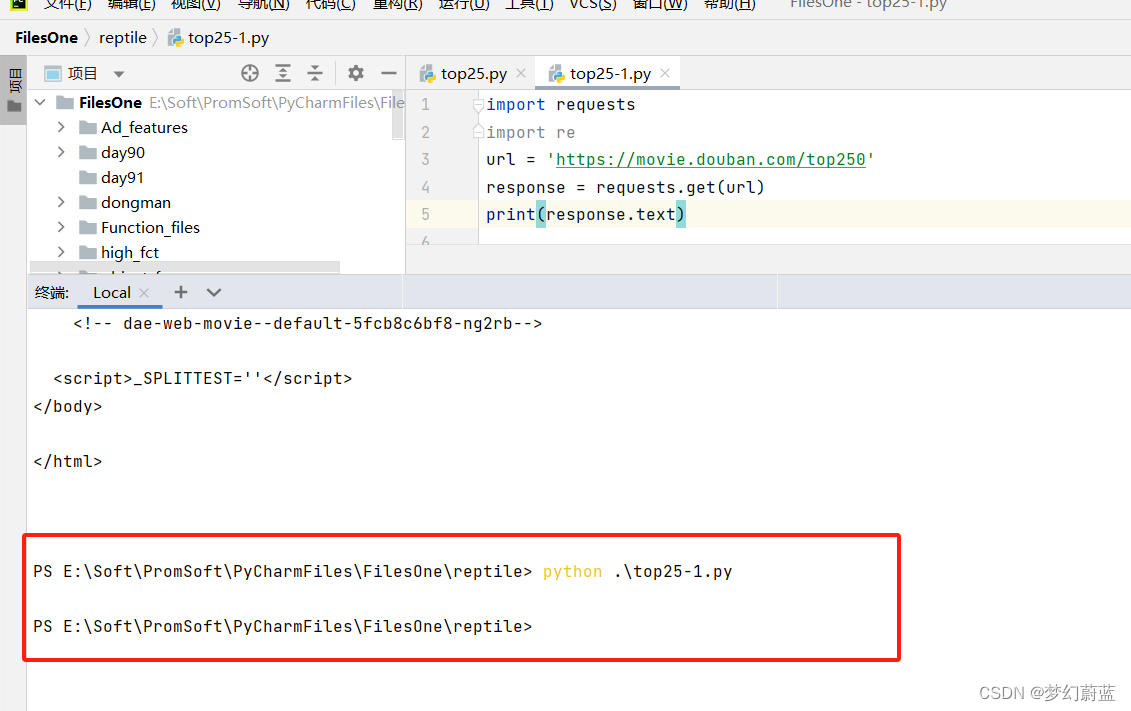
发现没反应,也没报错,这是为什么呢?因为网站有反扒机制,没有获取到网址,被浏览器拦截掉了。那该怎么办呢?小问题,骗过浏览器就行了。
加上一个headers,这行是通用的,可保存留着以后用。
headers = {
'User-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/1'
}
整合到上面代码再请求一次。
import requests
import re
headers = {
'User-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/1'
}
url = 'https://movie.douban.com/top250'
response = requests.get(url, headers=headers)
print(response.text)
运行之后,能发现网站页面全部拉去下来了,但是咱们不需要这么多信息,这就需要用到re库来筛选咱们需要的内容。
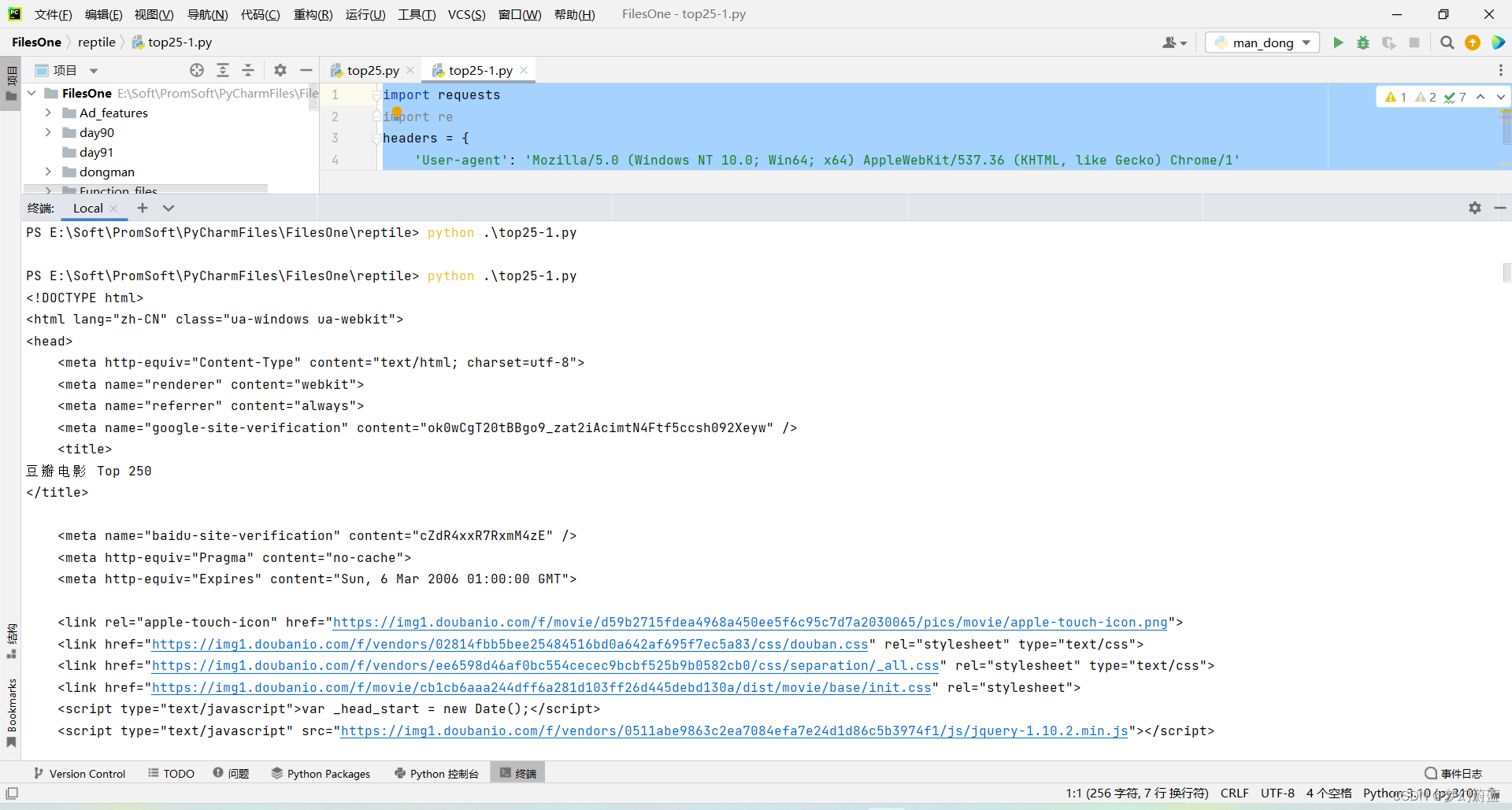
2.2.4
2.3 完整代码
import requests
import re
'''爬取豆瓣电影top20'''
def top250_crawer(url, sum):
headers = {
'User-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/1'
}
response = requests.get(url, headers=headers)
# print(response.text)
title = re.findall('<span class="title">(.*?)</span>', response.text, re.S)
new_title = []
for t in title:
if ' / ' not in t:
new_title.append(t)
data = re.findall('<br>(.*?)</p>', response.text, re.S)
time = []
country = []
for str1 in data:
str1 = str1.replace(' ', '')
str1 = str1.replace('\n', '')
time_data = str1.split(' / ')[0]
country_data = str1.split(' / ')[1]
time.append(time_data)
country.append(country_data)
for j in range(len(country)):
sum += 1
print(str(sum) + '.' + new_title[j] + ',' + country[j] + ',' + time[j])
url = 'https://movie.douban.com/top250'
sum = 0
'遍历10页数据,250条结果'
for a in range(10):
if sum == 0:
top250_crawer(url, sum)
sum += 25
else:
page = '?start=' + str(sum) + '&filter='
new_url = url + page
top250_crawer(new_url, sum)
sum += 25