场景
本篇分享以前在广州一家互联网公司工作时遇到的状况及解决方案,这家公司有一个项目是SOA的架构,这个架构那几年是很流行的,哪怕是现在依然认为这个理念在当时比较先进。
当时的项目背景大概是这样,这家公司用的是某软提供的方案,项目已经运行3年多,整体稳定。
数据库是MySQL,订单表的数据量已经达到3000多万条记录,并且随着项目的推广,最近那一年订单表数据量也在快速增长。
结果就是,客户方查询订单相关的业务时速度越来越慢,后期不论打开还是刷新都差不多要七八秒。
可以说已经严重影响了客户体验,降低了对方日常办事的效率,要求我们尽快解决,且敦促我们这是一件优先级非常高的事情。
在客户和公司领导的双重压力下,如何快速优化几千万数据的订单表,对于当时的团队着实是一个难题摆在面前。
整体方案
首先常规方案能想到的无非是这些:增加合理的数据库索引、优化核心SQL语句、优化代码等。
这里可以告诉大家,一般的IT公司,但凡团队Leader是个有经验的人,这些基础方案都是会提前做的,会对项目上线后可能遇到的瓶颈有个基本的评估,因为真正运营周期变长以后,数据量逐渐增多,修改生产库是一种风险操作。
不知道大家有没有过给某个生产库数据量比较大的表添加字段或索引的经历,而且是在白天上班操作,或者说你自己见过别人这么干,我只能说……这些都是狠人,要对其常怀敬畏之心。
目前所在的公司就比较规范,研发人员建表时一定要提交申请走流程,且附带合理的索引,一起提交审核,最终通过了才能由主管审核执行。
话题扯回来,正因前面所讲,在当前的问题下,这些基础方案实际上已经存在,在这里显然是用不上了,加上紧急问题紧急处理,没有那么多时间给你去对既有架构大动干戈。
因此,当时立马能想到且有效的临时性方案迅速在团队讨论中率先冒出来,就是数据库分区。
1、数据库分区
理解数据库分区,只需要记住以下两点:
- 数据库分区是把一张表的数据
分在了不同的硬盘上,但仍是一张表,说硬盘可能不完全准确,但就这样理解是最容易的。 - 不要把数据库分区和分库分表混淆,一个是
数据库级别的操作,一个是代理工具的操作,前者限制较多,后者更灵活。
知道这两点其实就足够了,数据库分区和分库分表也是面试中喜欢问的,因为确实有一些类似的地方。
好了,有了基本认识,那接下来就说下数据库分区如何操作的,先看个图有个画面。
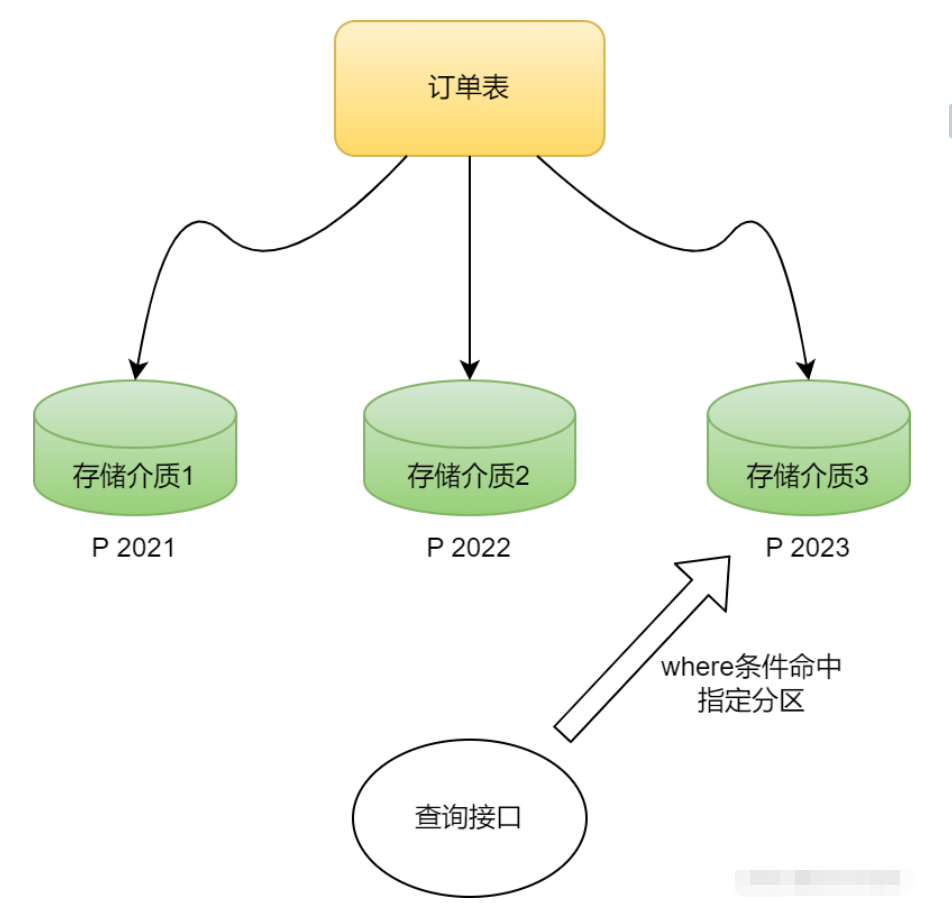
接着举个示例,我们假设有一张订单表,那么对这张订单表按照年份进行分区的命令如下:
-- 创建订单表
CREATE TABLE orders (
id INT PRIMARY KEY AUTO_INCREMENT,
order_number VARCHAR(20),
order_date DATE,
customer_id INT,
total_amount DECIMAL(10, 2)
);
-- 按照年份对订单表进行分区
ALTER TABLE orders
PARTITION BY RANGE(YEAR(order_date)) (
PARTITION p2018 VALUES LESS THAN (2019),
PARTITION p2019 VALUES LESS THAN (2020),
PARTITION p2020 VALUES LESS THAN (2021),
PARTITION p2021 VALUES LESS THAN (2022),
PARTITION p2022 VALUES LESS THAN (2023),
PARTITION p2023 VALUES LESS THAN (2024)
);
这样一来