一.介绍
首先我们看一个项目中的下单业务整体流程:

由于订单、购物车、商品分别在三个不同的微服务,而每个微服务都有自己独立的数据库,因此下单过程中就会跨多个数据库完成业务。而每个微服务都会执行自己的本地事务:
- 交易服务:下单事务
- 购物车服务:清理购物车事务
- 库存服务:扣减库存事务
整个业务中,各个本地事务是有关联的。因此每个微服务的本地事务,也可以称为分支事务。多个有关联的分支事务一起就组成了全局事务。我们必须保证整个全局事务同时成功或失败。
二.认识Seata
解决分布式事务的方案有很多,但实现起来都比较复杂,因此我们一般会使用开源的框架来解决分布式事务问题。在众多的开源分布式事务框架中,功能最完善、使用最多的就是阿里巴巴在2019年开源的Seata了。官网地址
其实分布式事务产生的一个重要原因,就是参与事务的多个分支事务互相无感知,不知道彼此的执行状态。因此解决分布式事务的思想非常简单:就是找一个统一的事务协调者,与多个分支事务通信,检测每个分支事务的执行状态,保证全局事务下的每一个分支事务同时成功或失败即可。大多数的分布式事务框架都是基于这个理论来实现的。
Seata也不例外,在Seata的事务管理中有三个重要的角色:
TC (Transaction Coordinator) - 事务协调者:维护全局和分支事务的状态,协调全局事务提交或回滚。TM (Transaction Manager) - 事务管理器:定义全局事务的范围、开始全局事务、提交或回滚全局事务。RM (Resource Manager) - 资源管理器:管理分支事务,与TC交谈以注册分支事务和报告分支事务的状态,并驱动分支事务提交或回滚。
Seata的工作架构如图所示:
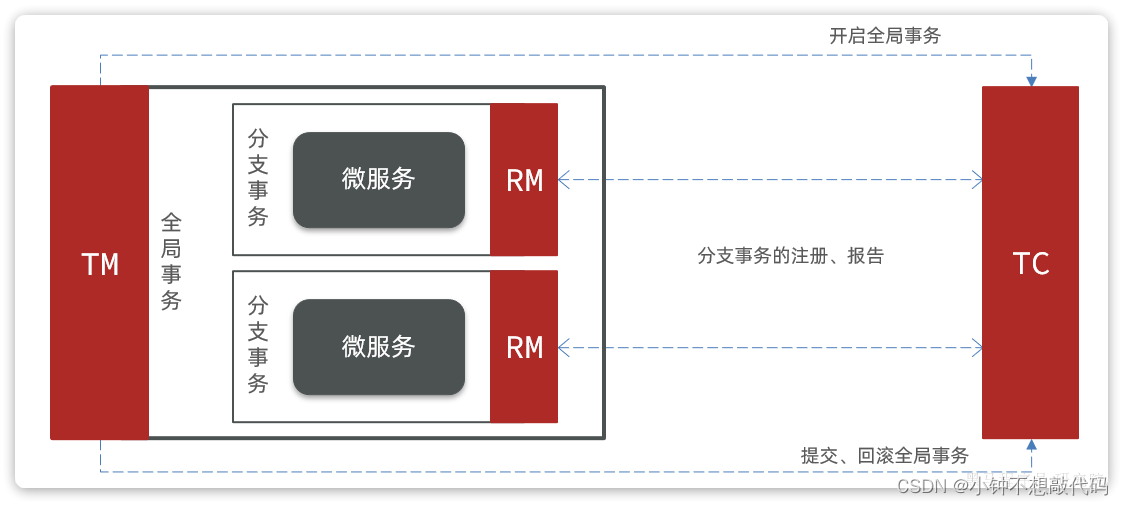
其中,TM和RM可以理解为Seata的客户端部分,引入到参与事务的微服务依赖中即可。将来TM和RM就会协助微服务,实现本地分支事务与TC之间交互,实现事务的提交或回滚。
而TC服务则是事务协调中心,是一个独立的微服务,需要单独部署。
三.部署TC服务
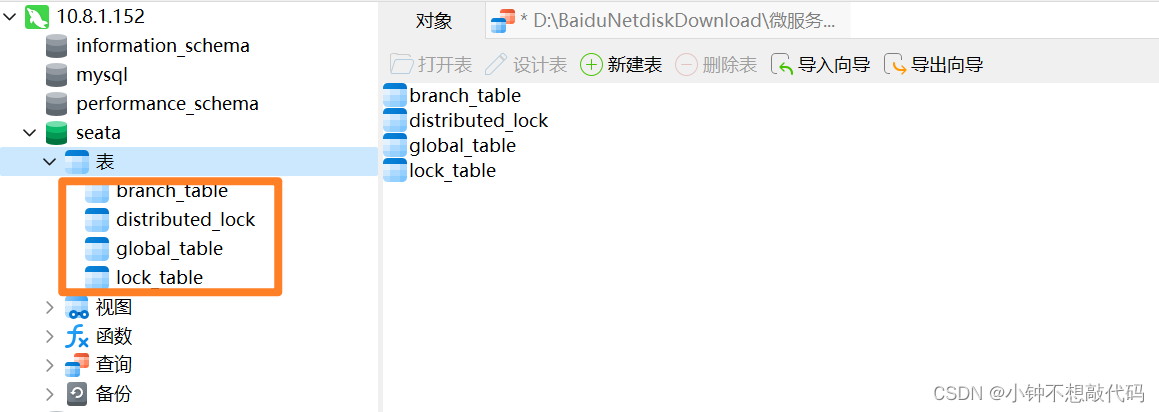
3.1 准备数据库表
Seata支持多种存储模式,但考虑到持久化的需要,我们一般选择基于数据库存储。执行如下sql脚本,导入数据库表:
CREATE DATABASE IF NOT EXISTS `seata`;
USE `seata`;
-- the table to store GlobalSession data
CREATE TABLE IF NOT EXISTS `global_table`
(
`xid` VARCHAR(128) NOT NULL,
`transaction_id` BIGINT,
`status` TINYINT NOT NULL,
`application_id` VARCHAR(32),
`transaction_service_group` VARCHAR(32),
`transaction_name` VARCHAR(128),
`timeout` INT,
`begin_time` BIGINT,
`application_data` VARCHAR(2000),
`gmt_create` DATETIME,
`gmt_modified` DATETIME,
PRIMARY KEY (`xid`),
KEY `idx_status_gmt_modified` (`status` , `gmt_modified`),
KEY `idx_transaction_id` (`transaction_id`)
) ENGINE = InnoDB
DEFAULT CHARSET = utf8mb4;
-- the table to store BranchSession data
CREATE TABLE IF NOT EXISTS `branch_table`
(
`branch_id` BIGINT NOT NULL,
`xid` VARCHAR(128) NOT NULL,
`transaction_id` BIGINT,
`resource_group_id` VARCHAR(32),
`resource_id` VARCHAR(256),
`branch_type` VARCHAR(8),
`status` TINYINT,
`client_id` VARCHAR(64),
`application_data` VARCHAR(2000),
`gmt_create` DATETIME(6),
`gmt_modified` DATETIME(6),
PRIMARY KEY (`branch_id`),
KEY `idx_xid` (`xid`)
) ENGINE = InnoDB
DEFAULT CHARSET = utf8mb4;
-- the table to store lock data
CREATE TABLE IF NOT EXISTS `lock_table`
(
`row_key` VARCHAR(128) NOT NULL,
`xid` VARCHAR(128),
`transaction_id` BIGINT,
`branch_id` BIGINT NOT NULL,
`resource_id` VARCHAR(256),
`table_name` VARCHAR(32),
`pk` VARCHAR(36),
`status` TINYINT NOT NULL DEFAULT '0' COMMENT '0:locked ,1:rollbacking',
`gmt_create` DATETIME,
`gmt_modified` DATETIME,
PRIMARY KEY (`row_key`),
KEY `idx_status` (`status`),
KEY `idx_branch_id` (`branch_id`),
KEY `idx_xid_and_branch_id` (`xid` , `branch_id`)
) ENGINE = InnoDB
DEFAULT CHARSET = utf8mb4;
CREATE TABLE IF NOT EXISTS `distributed_lock`
(
`lock_key` CHAR(20) NOT NULL,
`lock_value` VARCHAR(20) NOT NULL,
`expire` BIGINT,
primary key (`lock_key`)
) ENGINE = InnoDB
DEFAULT CHARSET = utf8mb4;
INSERT INTO `distributed_lock` (lock_key, lock_value, expire) VALUES ('AsyncCommitting', ' ', 0);
INSERT INTO `distributed_lock` (lock_key, lock_value, expire) VALUES ('RetryCommitting', ' ', 0);
INSERT INTO `distributed_lock` (lock_key, lock_value, expire) VALUES ('RetryRollbacking', ' ', 0);
INSERT INTO `distributed_lock` (lock_key, lock_value, expire) VALUES ('TxTimeoutCheck', ' ', 0);
3.2 准备配置文件
准备了一个
seata目录,其中包含了seata运行时所需要的配置文件:
server:
port: 7099 # Seata服务器监听的端口号
spring:
application:
name: seata-server # Spring应用程序的名称
logging:
config: classpath:logback-spring.xml
file:
path: ${user.home}/logs/seata # 日志文件存储路径
console:
user:
username: admin # 控制台登录用户名
password: admin # 控制台登录密码
seata:
config:
type: nacos # 配置中心类型,支持nacos、consul、apollo、zk、etcd3
nacos:
server-addr: nacos:8848 # Nacos服务器地址
group : "DEFAULT_GROUP" # Nacos配置组
namespace: "" # Nacos命名空间
dataId: "seataServer.properties" # Seata配置文件在Nacos中的数据ID
username: "nacos" # Nacos用户名
password: "nacos" # Nacos密码
registry:
type: nacos # 注册中心类型,支持nacos、eureka、redis、zk、consul、etcd3、sofa
nacos:
application: seata-server # 在Nacos中注册的应用程序名称
server-addr: nacos:8848 # Nacos服务器地址
group : "DEFAULT_GROUP" # Nacos配置组
namespace: "" # Nacos命名空间
username: "nacos" # Nacos用户名
password: "nacos" # Nacos密码
seata.server:
max-commit-retry-timeout: -1
max-rollback-retry-timeout: -1
rollback-retry-timeout-unlock-enable: false
enable-check-auth: true
enable-parallel-request-handle: true
retry-dead-threshold: 130000
xaer-nota-retry-timeout: 60000
enableParallelRequestHandle: true
recovery:
committing-retry-period: 1000
async-committing-retry-period: 1000
rollbacking-retry-period: 1000
timeout-retry-period: 1000
undo:
log-save-days: 7
log-delete-period: 86400000
session:
branch-async-queue-size: 5000
enable-branch-async-remove: false
store:
mode: db # 存储模式,支持file、db、redis
session:
mode: db
lock:
mode: db
db:
datasource: druid # 数据库连接池类型
db-type: mysql # 数据库类型
driver-class-name: com.mysql.jdbc.Driver # JDBC驱动类名
url: jdbc:mysql://mysql:3306/seata?rewriteBatchedStatements=true # 数据库连接URL
user: root # 数据库用户名
password: 123 # 数据库密码
min-conn: 10 # 数据库连接池最小连接数
max-conn: 100 # 数据库连接池最大连接数
global-table: global_table # 全局事务日志表名
branch-table: branch_table # 分支事务日志表名
lock-table: lock_table # 锁表名
distributed-lock-table: distributed_lock # 分布式锁表名
query-limit: 1000 # 查询限制
max-wait: 5000 # 获取连接的最大等待时间(毫秒)
redis:
mode: single # Redis模式,支持单机模式、哨兵模式、集群模式
database: 0 # Redis数据库索引
min-conn: 10 # Redis连接池最小连接数
max-conn: 100 # Redis连接池最大连接数
password: # Redis密码
max-total: 100 # Redis连接池最大连接数
query-limit: 1000 # 查询限制
single:
host: # Redis主机地址
port: 6379 # Redis端口号
metrics:
enabled: false # 是否启用指标监控
registry-type: compact # 注册表类型
exporter-list: prometheus # 导出者列表
exporter-prometheus-port: 9898 # Prometheus导出者监听的端口号
transport:
rpc-tc-request-timeout: 15000 # RPC事务协调器请求超时时间(毫秒)
enable-tc-server-batch-send-response: false # 是否启用事务协调器服务器批量发送响应
shutdown:
wait: 3 # 关闭等待时间(秒)
thread-factory:
boss-thread-prefix: NettyBoss # Boss线程名称前缀
worker-thread-prefix: NettyServerNIOWorker # Worker线程名称前缀
boss-thread-size: 1 # Boss线程数
我们将整个seata文件夹拷贝到虚拟机:
3.3 Docker部署
在虚拟机执行下面的命令:
docker run --name seata \
-p 8099:8099 \
-p 7099:7099 \
-e SEATA_IP=服务器ip地址 \
-v ./seata:/seata-server/resources \
--privileged=true \
--network liming \
-d \
seataio/seata-server:1.5.2
四.微服务集成Seata
参与分布式事务的每一个微服务都需要集成Seata
4.1 引入依赖
<!--统一配置管理-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId>
</dependency>
<!--读取bootstrap文件-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-bootstrap</artifactId>
</dependency>
<!--seata-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-seata</artifactId>
</dependency>
<!--sentinel-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-sentinel</artifactId>
</dependency>
4.2 改造配置
首先在nacos上添加一个共享的seata配置,命名为shared-seata.yaml:
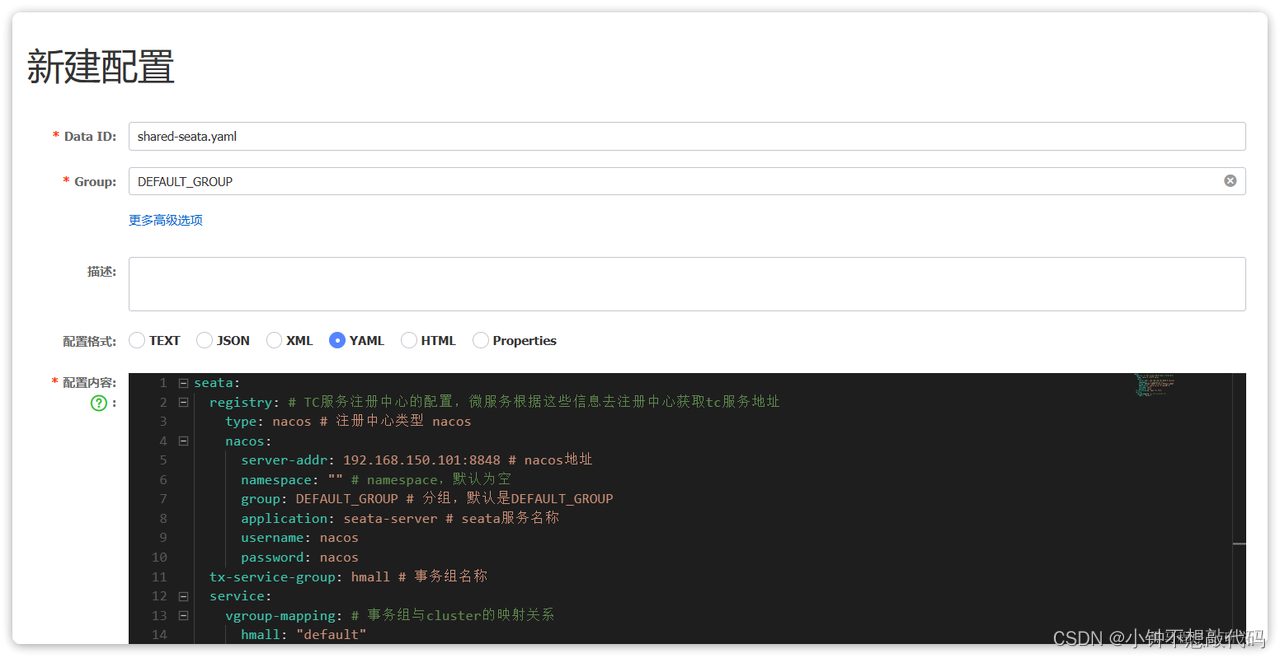
内容如下:
seata:
registry: # TC服务注册中心的配置,微服务根据这些信息去注册中心获取tc服务地址
type: nacos # 注册中心类型 nacos
nacos:
server-addr: 192.168.150.101:8848 # nacos地址
namespace: "" # namespace,默认为空
group: DEFAULT_GROUP # 分组,默认是DEFAULT_GROUP
application: seata-server # seata服务名称
username: nacos
password: nacos
tx-service-group: liming # 事务组名称
service:
vgroup-mapping: # 事务组与tc集群的映射关系
hmall: "default"
然后,改造trade-service模块,添加bootstrap.yaml:
内容如下:
spring:
application:
name: trade-service # 服务名称
profiles:
active: dev
cloud:
nacos:
server-addr: 192.168.150.101 # nacos地址
config:
file-extension: yaml # 文件后缀名
shared-configs: # 共享配置
- dataId: shared-jdbc.yaml # 共享mybatis配置
- dataId: shared-log.yaml # 共享日志配置
- dataId: shared-swagger.yaml # 共享日志配置
- dataId: shared-seata.yaml # 共享seata配置
然后改造application.yaml文件,内容如下:
server:
port: 8085
feign:
okhttp:
enabled: true # 开启OKHttp连接池支持
sentinel:
enabled: true # 开启Feign对Sentinel的整合
hm:
swagger:
title: 交易服务接口文档
package: com.hmall.trade.controller
db:
database: hm-trade
4.3 添加数据库表
seata的客户端在解决分布式事务的时候需要记录一些中间数据,保存在数据库中。因此我们要先准备一个这样的表。将这张表分别导入
各个服务模块数据库中:
-- for AT mode you must to init this sql for you business database. the seata server not need it.
CREATE TABLE IF NOT EXISTS `undo_log`
(
`branch_id` BIGINT NOT NULL COMMENT 'branch transaction id',
`xid` VARCHAR(128) NOT NULL COMMENT 'global transaction id',
`context` VARCHAR(128) NOT NULL COMMENT 'undo_log context,such as serialization',
`rollback_info` LONGBLOB NOT NULL COMMENT 'rollback info',
`log_status` INT(11) NOT NULL COMMENT '0:normal status,1:defense status',
`log_created` DATETIME(6) NOT NULL COMMENT 'create datetime',
`log_modified` DATETIME(6) NOT NULL COMMENT 'modify datetime',
UNIQUE KEY `ux_undo_log` (`xid`, `branch_id`)
) ENGINE = InnoDB
AUTO_INCREMENT = 1
DEFAULT CHARSET = utf8mb4 COMMENT ='AT transaction mode undo table';
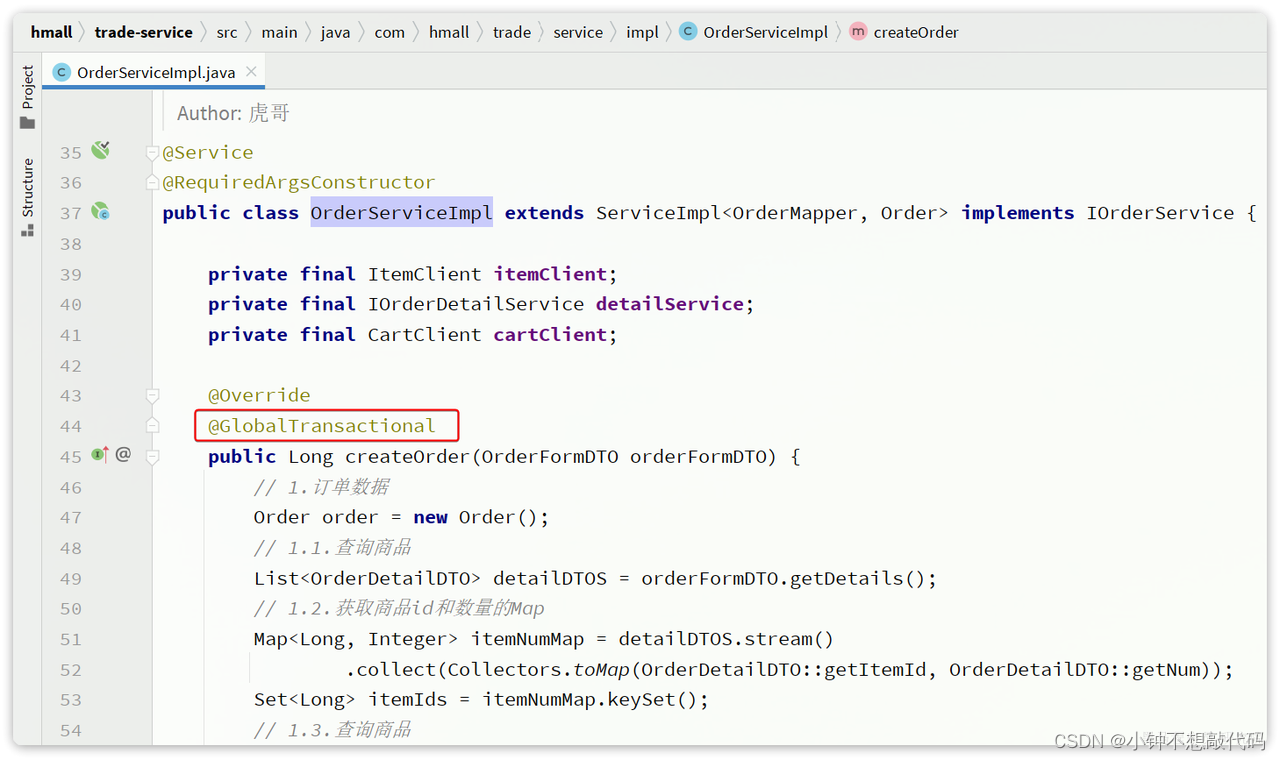
4.4 使用
@GlobalTransactional注解就是在标记事务的起点,将来TM就会基于这个方法判断全局事务范围,初始化全局事务。
五.XA模式
Seata支持四种不同的分布式事务解决方案:
- XA
- TCC
- AT
- SAGA
XA规范 是X/Open组织定义的分布式事务处理(DTP,Distributed Transaction Processing)标准,XA 规范 描述了全局的TM与局部的RM之间的接口,几乎所有主流的数据库都对 XA 规范 提供了支持。
5.1 两阶段提交
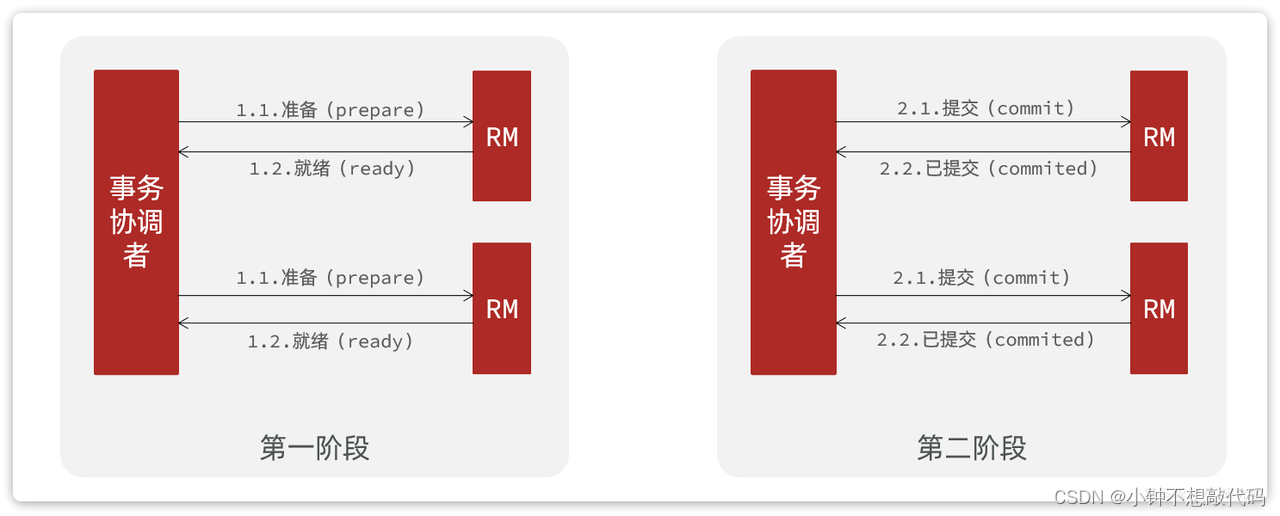
A是规范,目前主流数据库都实现了这种规范,实现的原理都是基于两阶段提交。
正常情况:
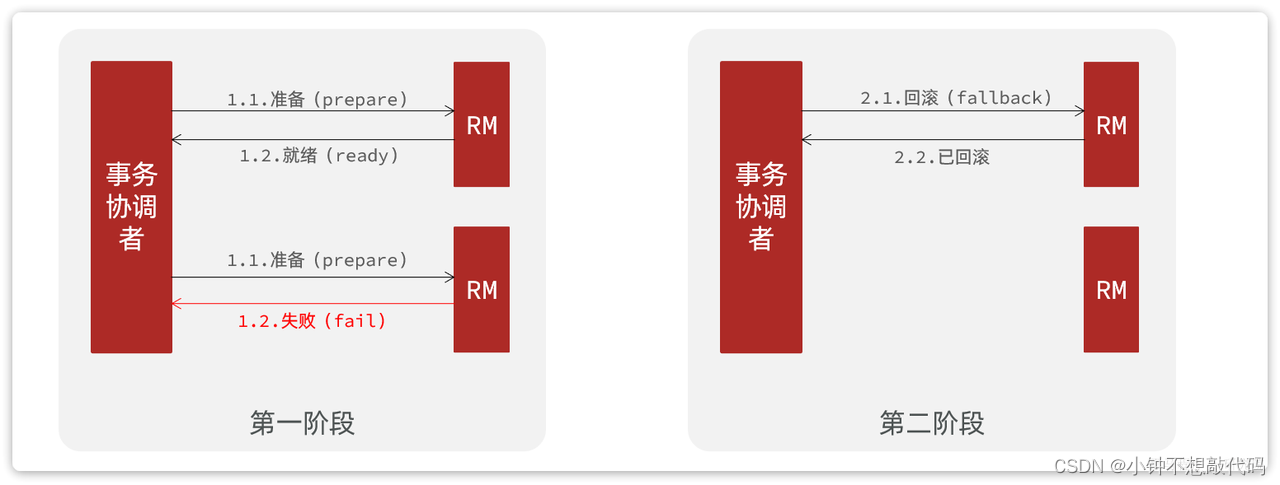
异常情况:
一阶段:
- 事务协调者通知每个事务参与者执行本地事务
- 本地事务执行完成后报告事务执行状态给事务协调者,此时事务不提交,继续持有数据库锁
二阶段:
- 事务协调者基于一阶段的报告来判断下一步操作
- 如果一阶段都成功,则通知所有事务参与者,提交事务
- 如果一阶段任意一个参与者失败,则通知所有事务参与者回滚事务
5.2 Seata的XA模型
Seata对原始的XA模式做了简单的封装和改造,以适应自己的事务模型,基本架构如图:
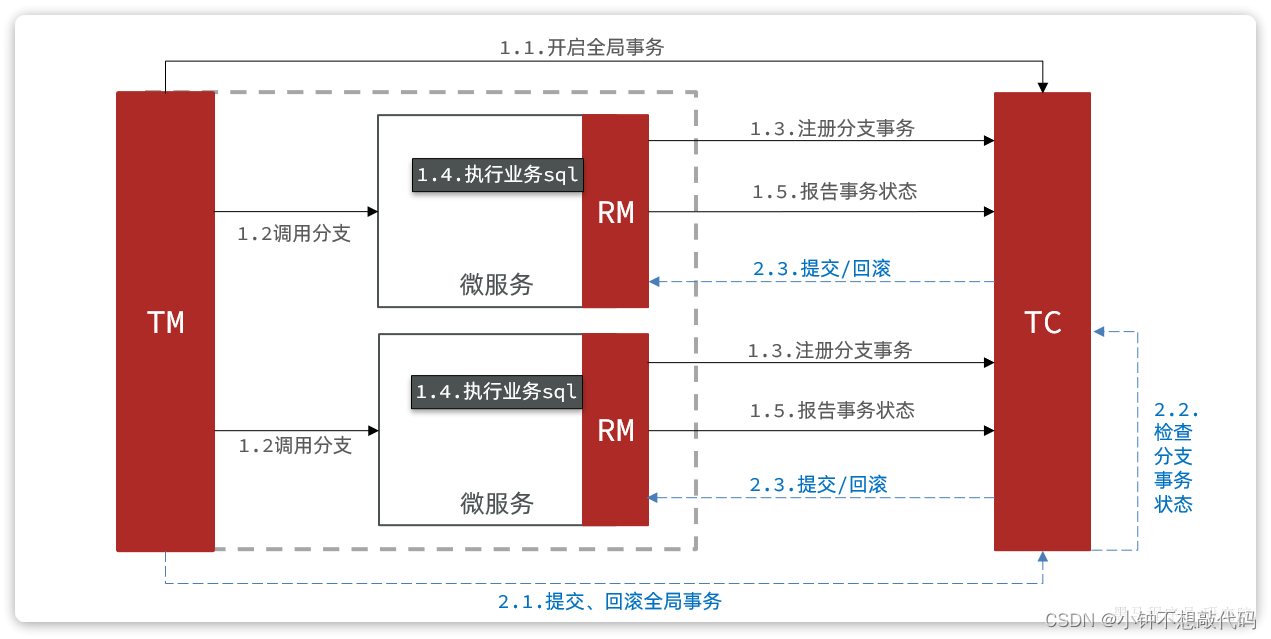
RM一阶段的工作:
- 注册分支事务到TC
- 执行分支业务sql但不提交
- 报告执行状态到TC
TC二阶段的工作:
- TC检测各分支事务执行状态
- 如果都成功,通知所有RM提交事务
- 如果有失败,通知所有RM回滚事务
RM二阶段的工作:
- 接收TC指令,提交或回滚事务
5.3 优缺点
XA模式的优点是什么?
- 事务的强一致性,满足ACID原则
- 常用数据库都支持,实现简单,并且没有代码侵入
XA模式的缺点是什么?
- 因为一阶段需要锁定数据库资源,等待二阶段结束才释放,性能较差
- 依赖关系型数据库实现事务
六.AT模式
AT模式同样是分阶段提交的事务模型,不过缺弥补了XA模型中资源锁定周期过长的缺陷。
6.1 Seata的AT模型
基本流程图:
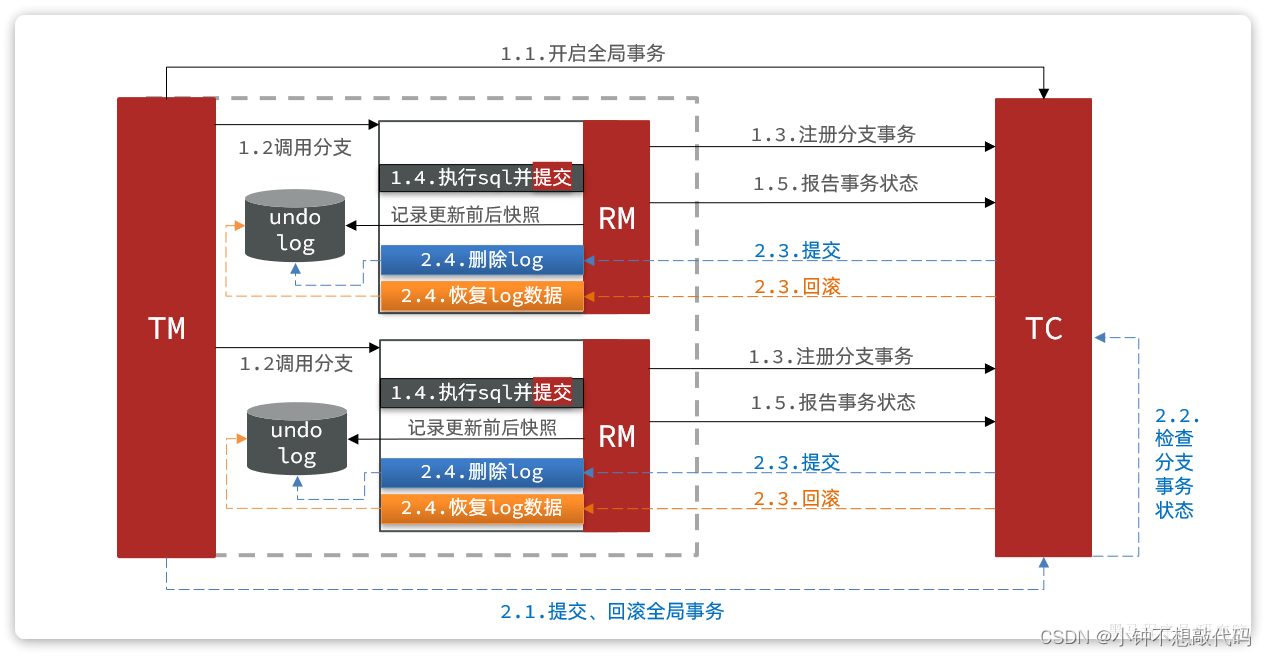
阶段一RM的工作:
- 注册分支事务
- 记录undo-log(数据快照)
- 执行业务sql并提交
- 报告事务状态
阶段二提交时RM的工作:
- 删除undo-log即可
阶段二回滚时RM的工作:
- 根据undo-log恢复数据到更新前
6.2 流程梳理
我们用一个真实的业务来梳理下AT模式的原理。
比如,现在有一个数据库表,记录用户余额:
| id | money |
|---|---|
| 1 | 100 |
其中一个分支业务要执行的SQL为:
update tb_account set money = money - 10 where id = 1
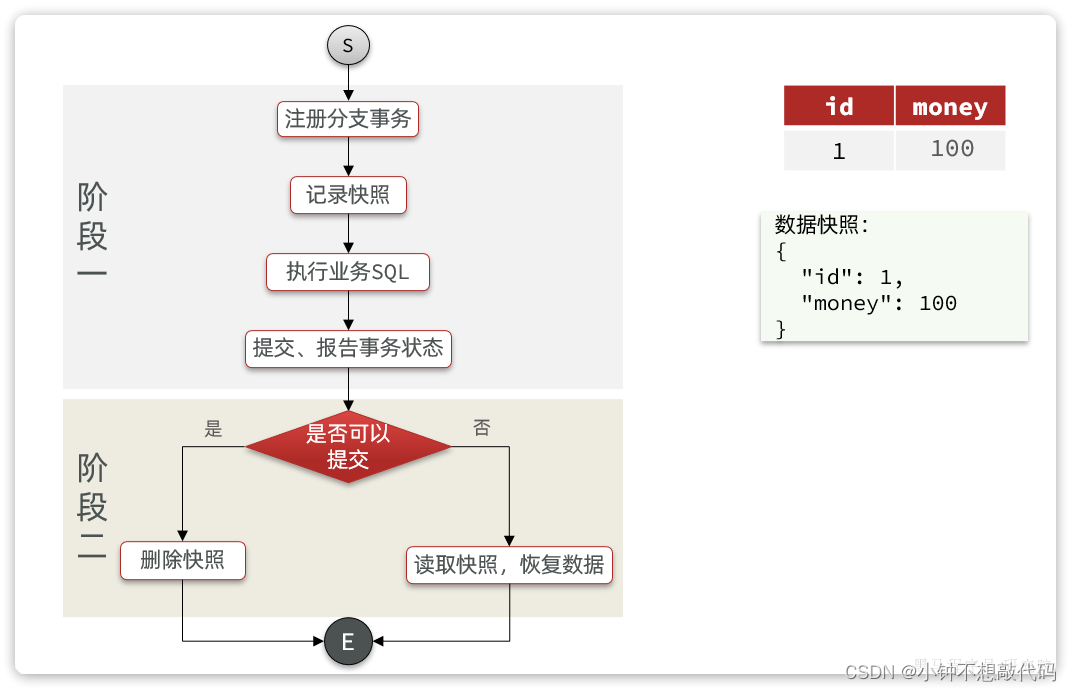
AT模式下,当前分支事务执行流程如下:
一阶段:
- TM发起并注册全局事务到TC
- TM调用分支事务
- 分支事务准备执行业务SQL
- RM拦截业务SQL,根据where条件查询原始数据,形成快照。
{
"id": 1, "money": 100
}
- RM执行业务SQL,提交本地事务,释放数据库锁。此时 money = 90
- RM报告本地事务状态给TC
二阶段:
- TM通知TC事务结束
- TC检查分支事务状态
- 如果都成功,则立即删除快照
- 如果有分支事务失败,需要回滚。读取快照数据({“id”: 1, “money”: 100}),将快照恢复到数据库。此时数据库再次恢复为100
流程图:
6.3 AT与XA的区别
简述AT模式与XA模式最大的区别是什么?
- XA模式一阶段不提交事务,锁定资源;AT模式一阶段直接提交,不锁定资源。
- XA模式依赖数据库机制实现回滚;AT模式利用数据快照实现数据回滚。
- XA模式强一致;AT模式最终一致
可见,AT模式使用起来更加简单,无业务侵入,性能更好。因此企业90%的分布式事务都可以用AT模式来解决。