目录
简介
定义模型
注册中间件
创建doc实例,并进行增删改查
方法名和注册的中间件名相匹配
执行结果
分析
错误处理中间件
手动抛出错误
注意点
简介
在mongoose中,中间件是一种允许在执行数据库操作前(pre)或后(post)执行自定义逻辑的机制。
定义模型
const mongoose = require('mongoose');
const schema = new mongoose.Schema(
{
name: {
type: String,
required: true
}
},
);注册中间件
pre为前置中间件,post为后置中间件,允许正则匹配
schema.pre('validate', function(next){
// this指向正在验证的doc
console.log('doc validate before')
next()
})
schema.post('validate', function(doc) {
//this == doc true
console.log('doc validated')
})
schema.pre('save', function(next){
// this指向正在验证的doc
console.log('doc save brfore')
next()
})
schema.post('save', function(doc) {
//this == doc true
console.log('doc saved')
})
schema.pre('init', function(doc) {
// doc是查询的文档
console.log('doc init before')
})
schema.post('init', function(doc) {
// this == doc true
console.log('doc inited')
})
schema.pre(/find/, function() {
//this指向Query实例
console.log('doc find')
})
schema.post(/find/, function(doc) {
// doc是查询的文档
console.log('doc finded')
})
schema.pre('updateOne', function(next){
//this指向Query实例 _conditions: { _id: new ObjectId('658147685eca07e7b0c52259') }
console.log('doc update before')
next()
})
schema.post('updateOne', function(res) {
// res更新结果
console.log('doc updated')
})
schema.pre('deleteOne', function(next){
//this指向Query实例 _conditions: { _id: new ObjectId('658147685eca07e7b0c52259') }
console.log('doc remove before')
next()
})
schema.post('deleteOne', function() {
// res删除结果
console.log('doc removed')
})
schema.pre('aggregate', function() {
// this指向正在处理的aggregate
})
schema.pre('aggregate', function() {
// this指向正在处理的aggregate
})
const Model = mongoose.model('SchemaIdentify', schema)
创建doc实例,并进行增删改查
app.post('/', async (req, res) => {
const doc = new Model({
name: 'saaaaaaaaaa',
})
await doc.save()
await Model.findById(doc._id)
await Model.updateOne({_id: doc._id}, {name: 'hahahahah'})
await Model.deleteOne({_id: doc._id})
res.status(200).json()
})方法名和注册的中间件名相匹配
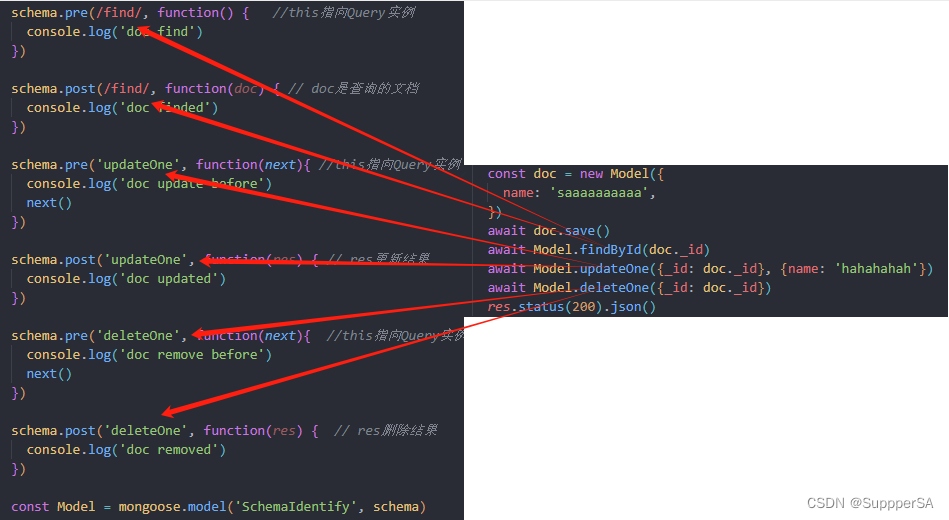
执行结果

分析
Mongoose 内部有一个内置的 pre('save') 钩子,它会调用 validate() 方法,从而触发中间件。因此,在执行 save() 之前,所有注册的 pre('validate') 和 post('validate') 钩子都会被调用

schema.pre('save', async function(next){ // 模拟内置
await this.validate() // this指向正在处理的doc
next()
})注册validate、save、/find/ 、/update/、/delete/等前置中间件接收一个next函数,可以控制next决定是否继续执行注册的中间件, 回调函数中的this有不同的指向,validate、save中间件指向正在处理的文档, /find/ 、/update/、/delete/等中间件中的this指向Query实例。后置中间件validate、save接收一个参数表示处理过的doc,/find/接收一个参数表示查询结果doc或docs、/update/、/delete/等中间件接收一个参数表示处理的结果, 第二个参数为next。
/find/ :

/update/:

/delete/:

错误处理中间件
当执行某操作的时候如果发生错误,后置中间件会接收一个error参数,并且不会继续执行后续的中间件,规定定义三个参数
 不传入更新的内容
不传入更新的内容
schema.post('updateOne', function(error, res, next) { // res更新结果
console.log('doc updated', error)
next()
})
手动抛出错误
不管是前置、后置,任何中间件中手动抛出一个错误也不会继续往下执行中间件
schema.post(/find/, function(doc) {
throw new Error('eeeerrror')
})注意点
1、中间件如果不声明next参数,执行完则默认继续执行下一个中间件,如果中间件声明了next不调用则卡在这个中间件(声明必调用,要不就不声明)
2、在const Model = mongoose.model('SchemaIdentify', schema) 编译之前声明中间件,否则中间件不会执行
3、/update/ 中间件并不会触发save中间件,也就不会调用validate(),即也不会执行validate中间件。可以调用Model.findOneAndUpdate或findByIdAndUpdat,设置第三个参数options { runValidators: true },允许monggose进行数据校验。