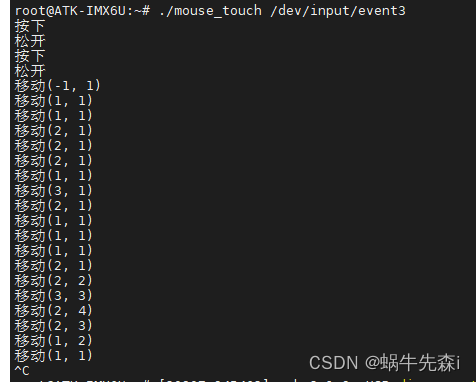
文章目录
- 简介
- 能调整的代价模型的参数有哪些?
- mysql.server_cost
- mysql.engine_cost
- 如何修改这些代价参数?
- 代价模型具体是如何计算的
- 参考文献
简介
大部分RDBMS都支持基于代价的优化器CBO,但其实CBO仍然存在缺陷(比如参数配置的不合理等),接下来我们会通过CBO的工作原理,来辅助了解优化器的执行过程。
能调整的代价模型的参数有哪些?
MySQL中的COST Model,就是优化器用来统计各种步骤的代价模型。
在5.7.10版本之后,MySQL引入了两张系统数据表,里面规定了各种步骤的预估代价,我们可以通过查看这两张表,来查看这些步骤的代价:
- mysql.server_cost,统计在server层的代价;
- mysql.engine_cost,统计在物理引擎层的代价。
mysql.server_cost
SQL > SELECT * FROM mysql.server_cost
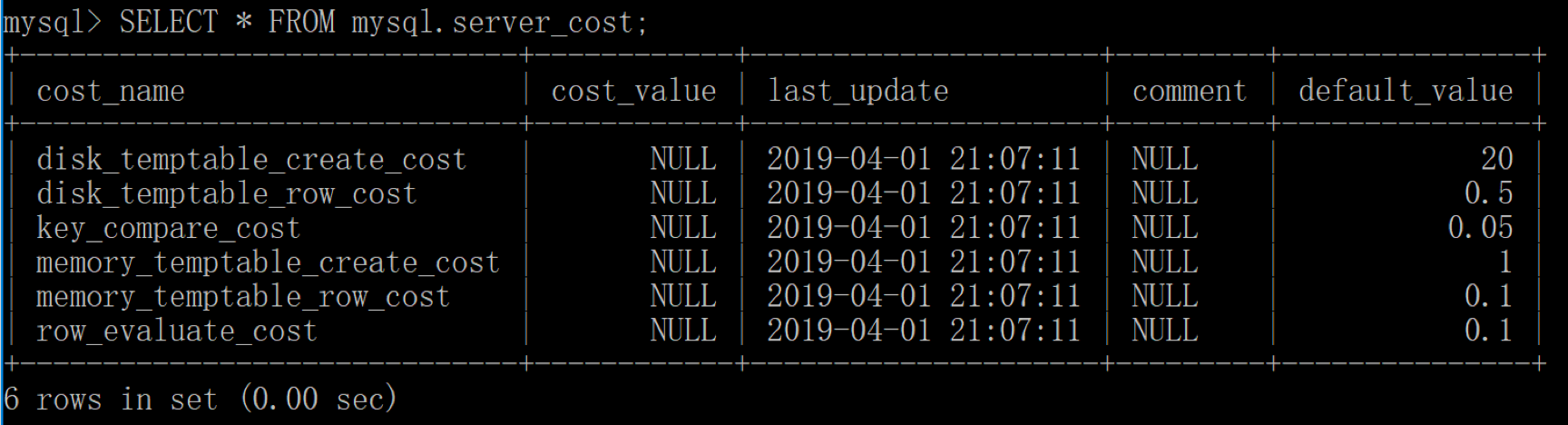
部分低版本MySQL打印不出default_value这一列,比如说我的5.7.37版本就只有前4列,但是我的8.0版本可以打印出全部的5列。
可以看到,一共有6行。
这6行具体的含义如下:
disk_temptable_create_cost,表示临时表文件(MyISAM或者InnoDB)的创建代价,默认是20;disk_temptable_row_cost,表示临时表文件的行代价,默认是0.5;key_compare_cost,表示键比较的代价。键比较的次数越多,这项的代价就越大,默认是0.5。重要指标memory_temptable_create_cost,在内存中创建临时表的代价,默认值是1;memory_temptable_row_cost,内存中临时表的行代价,默认值是0.1;row_evaluate_cost,统计符合条件的行代价。如果符合情况的行越多,那么这一项的代价就越大。默认值是0.1。重要指标
从上面来看,在磁盘上(非内存)创建一个临时表的代价还是很高的。
mysql.engine_cost
SQL > SELECT * FROM mysql.engine_cost

engine_cost这张表,主要统计了页加载的代价。
一共有两项:
io_block_read_cost,从磁盘上读取一页数据的代价,默认是1;memory_block_read_cost,从内存中读取一页数据的代价,默认是0.25。
如何修改这些代价参数?
既然数据表已经提供给了我们,那我们就可以根据实际情况,来修改这些参数。
比如说,如果使用的是普通磁盘,那么可以考虑适当增加io_block_read_cost的数值。
那么如果我想把这个值设置成2.0,使用下面的命令就可以:
UPDATE mysql.engine_cost
SET cost_value = 2.0
WHERE cost_name = 'io_block_read_cost';
FLUSH OPTIMIZER_COSTS;
之后再查看engine_cost表的时候,io_block_read_cost的cost_value就被改成了2.0。
但如果我只是想针对单个存储引擎,比如说我只让InnoDB的io_block_read_cost参数设置成2.0,那么可以使用下面的命令:
INSERT INTO mysql.engine_cost(engine_name, device_type, cost_name, cost_value, last_update, comment)
VALUES ('InnoDB', 0, 'io_block_read_cost', 2,
CURRENT_TIMESTAMP, 'Using a slower disk for InnoDB');
FLUSH OPTIMIZER_COSTS;
之后再查看engine_cost表的时候,会发现多了一行:

代价模型具体是如何计算的
这个过程比较复杂。
论文《Access Path Selection-in a Relational Database Management System》里给出了计算模型。如图:
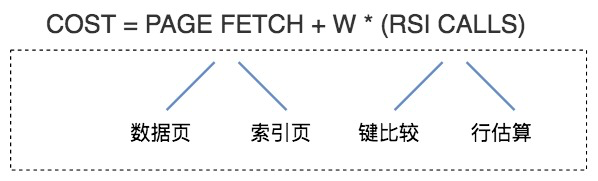
可以简单的认为,总的执行代价等于IO代价 + CPU代价。
PAGE FETCH就是IO代价,也就是页加载的代价,包括数据页的加载和索引页的加载。
W*(RSI CALLS),就是CPU代价。
W在这里是个权重因子,表示了CPU到IO之间转化的相关系数。
RSI CALLS表示CPU的代价估算,包括了键比较以及行估算的代价。
需要说明的是,MySQL5.7版本之后,上面的代价模型又被完善了,进一步考虑了内存计算和远程操作的代价,即演变成了:
总代价 = IO代价 + CPU代价 + 内存代价 + 远程代价
这个了解下就可以了,后两个代价没有前两个代价那么重要。
参考文献
- 32丨查询优化器是如何工作的?