文章目录
- 前言
- 开始
- 语法规范
- 有函数式方法的尽量用
- 判断字符串为空不要自己写
- equals判定,常量写前面
- 少用魔法值,定义常量
- 无状态方法,可选择定义为类静态
- 逻辑简化
- 明确主体逻辑
- 语法简化:三元运算符
- 语法简化:Optional
- 方法独立存在的必要性讨论
- 继续拓展:定义枚举
- 值枚举构建
- 关系枚举构建
- 继续拓展:设计模式
- 策略模式-简单实现
- 策略工厂-手动容器
- 注册与发现&策略工厂-Spring容器
- 注册与发现&责任链
- 其他拓展
- 参考
前言
读到一篇关于代码优化的文章, 加深自己的记忆手动整理一下
开始
起初是一段很简单的代码,开始仅仅是将外域的一些标识符转换为域内的标识符。
public Integer parseSaleType(String saleTypeStr){
if(saleTypeStr == null || saleTypeStr.equals("")){
return null;
}
if(saleTypeStr.equals("JX")){
return 1;
}
return null;
}
逻辑上很简单,实现的逻辑看上去也没啥大问题,基本学校的老师也是这么教的。
语法规范
但是必须得来挑挑毛病, 下面给出几个代码修改建议
有函数式方法的尽量用
//saleTypeStr == null
Objects.isNull(saleTypeStr)
首先呢,虽然由于判断null这么写不会报错,但是按照常量写==前面的要求,应该倒过来写。
另外,这种有JDK原生函数式的判断方法,还是优先使用函数式的写法,一来是有方法名比较直观,另外也是方便之后熟练使用Lamada,别写出.filter(x -> null == x)这样的写法,还是.filter(Objects::isNull)更可读些。
判断字符串为空不要自己写
判断字符串为空不要自己写, 容易漏逻辑,尽量使用现成的方法
//if(saleTypeStr == null || saleTypeStr.equals(""))
if(StringUtils.isBlank(saleTypeStr))
虽然原方法里无论判不判断空字符或者空格字符都不会影响最终方法的表征,但是从第一行想表达的判断“字符串是不是为空”这件事来看,这行并不能判断“空格字符”存在的情况,所以词不达意,另外也趁机强化记忆下isBlank和isEmpty的区别。
org.apache.commons.lang3里有很多工具类,方法比较成熟逻辑也比较完整。
同理org.apache.commons.collections4.CollectionUtils还有一堆集合操作的工具。
equals判定,常量写前面
//if(saleTypeStr.equals("JX"))
if("JX".equals(saleTypeStr))
虽然前面判断过null,所以这里并不会报空指针,但是但凡之后书写前面漏了,这里就开始报错了。
少用魔法值,定义常量
private static final String JX_SALE_TYPE_STR = "JX";
private static final Integer JX_SALE_TYPE_INT = 1;
但凡同一个魔法值在多处用,就怕漏改,所以收束定义在常量下,至少能保证全局引用的统一性。
无状态方法,可选择定义为类静态
//public Integer parseSaleType(String saleTypeStr)
public static Integer parseSaleType(String saleTypeStr)
方法本身跟所在类的实例对象状态无关,且不会诱发线程安全问题,故符合被定义为static的条件,可先于对象创建在方法区,防止每个对象创建一次的时候,堆内存创建一次。
逻辑简化
前面将语法的问题说了一下,接下来再琢磨琢磨这段逻辑需不需要这么多代码来表述了,乍眼一看没问题,但其实没必要写这么多。
明确主体逻辑
判断入参有效性 -> 处理核心逻辑 -> 缺省返回,其实这个方法的构建思路是非常标准且合乎常理的,思考习惯很好,只是在这个简单的方法场景不免逻辑有些冗余。
其实再看这个方法,最核心的逻辑就是把字符串对应到数字上,其他不命中的情况返回null就可以了,那么简化逻辑后,为空判定其实可以去掉,直接变为:
private static final String JX_SALE_TYPE_STR = "JX";
private static final Integer JX_SALE_TYPE_INT = 1;
public static Integer parseSaleType(String saleTypeStr){
if(JX_SALE_TYPE_STR.equals(saleTypeStr)){
return JX_SALE_TYPE_INT;
}
return null;
}
语法简化:三元运算符
再仔细看下场景有没有成熟的范式,【布尔式+返回值+非此即彼】,三元运算符可堪一用。
public static Integer parseSaleType(String saleTypeStr){
return JX_SALE_TYPE_STR.equals(saleTypeStr) ? JX_SALE_TYPE_INT : null;
}
语法简化:Optional
这个场景范式也满足,【可能为空,有后续处理,有条件,有缺省值】,Optional也算完美契合。
public static Integer parseSaleType(String saleTypeStr){
Optional.ofNullable(saleTypeStr).filter(JX_SALE_TYPE_STR::equals).map(o -> JX_SALE_TYPE_INT).orElse(null);
}
方法独立存在的必要性讨论
其实语法简化到三元运算符和Optional这一步,如果一个方法体内只有这一行,这个方法独立存在的必要性的就开始存疑了,如果所有的转换流程都能收束在工程中的某个环节上,且保证这个方法的引用仅存在一处,那么这一行代码其实放在主干代码上更好,防止来回跳转的代码阅读障碍,当然这也仅仅是在现状下的讨论,如果存在且不仅限于以下几种状况时还得独立出来:
未来除了一种逻辑分支外,还会扩展其他分支,并且有被扩展的可能;
- 虽然还是一种逻辑分支,但是判断的内容变长了,跟上下文和调用状态有关;
- 虽然还是一种逻辑分支,但是逻辑总在调整;
- 一处定义,多点引用;
继续拓展:定义枚举
假如这个传入的字符其实还有很多种,返回的映射也有很多种的时候,其实在这里继续写一堆常量定义就很不理智了。
值枚举构建
考虑继续将入参的所有可能和出参的所有可能,可以构建为两组枚举值,这样所有的同簇常量就被放到一起了。
public enum SaleTypeStrEnum{
JX,
// OTHERS
;
}
@AllArgsConstructor
@Getter
public enum SaleTypeIntEnum{
JX(1),
// OTHERS
;
private Integer code;
}
但是这个枚举功能并不完善,因为从入参映射为SaleTypeStrEnum,依然需要一段转换的逻辑,需要用到SaleTypeStrEnum::name来判定传参命中了哪个,所以这个逻辑不应该放在枚举外,继续补充:
public enum SaleTypeStrEnum{
JX,
// OTHERS
;
public static SaleTypeStrEnum getByName(String saleTypeStr){
for (SaleTypeStrEnum value : SaleTypeStrEnum.values()) {
if(value.name().equals(saleTypeStr)){
return value;
}
}
return null;
}
}
方法有了,但是每次传进来值都要遍历整个枚举,O(n)效率太低了,还是老规矩,空间换时间。
public enum SaleTypeStrEnum{
JX,
// OTHERS
;
/**
* 预热转换关系到内存
*/
private static Map<String, SaleTypeStrEnum> NAME_MAP = Arrays.stream(SaleTypeStrEnum.values()).collect(Collectors.toMap(SaleTypeStrEnum::name, Function.identity()));
public static SaleTypeStrEnum getByName(String saleTypeStr){
return NAME_MAP.get(saleTypeStr);
}
}
这样每次检索就是O(1)了,那么最终方法体内也能使用switch管理原本的if-else
public static Integer parseSaleType(String saleTypeStr){
switch(SaleTypeStrEnum.getByName(saleTypeStr)){
case JX:return SaleTypeIntEnum.JX.getCode();
// OTHERS
default:return null;
}
}
关系枚举构建
再仔细思考下,其实这里在描述的内容,无论是哪个枚举描述的内容都是同一件事物,方法本身就是描述两个不同编码的转换关系,且转换关系本身就是单向的,且映射路径极度简单,所以简单化一点,可以直接构建转换关系枚举。
@Getter
@AllArgsConstructor
public enum SaleTypeRelEnum {
// 不在分别定义两类变量,而是直接定义变量映射关系
JX("JX", 1),
// OTHERS
;
private String fromCode;
private Integer toCode;
private static Map<String, SaleTypeRelEnum> FROM_CODE_MAP = Arrays.stream(SaleTypeRelEnum.values()).collect(Collectors.toMap(SaleTypeRelEnum::getFromCode, Function.identity()));
public static SaleTypeRelEnum get(String saleTypeStr){
return FROM_CODE_MAP.get(saleTypeStr);
}
public static Integer parseCode(String saleTypeStr){
return Optional.ofNullable(SaleTypeRelEnum.get(saleTypeStr)).map(SaleTypeRelEnum::getToCode).orElse(null);
}
}
如果将转关系作为枚举,那么从职责上划分,转换这个动作应该是封闭在枚举内的固有行为,而不该暴露在外,故原来对方法的引用其实应该转为对关系枚举中SaleTypeEnum::parseCode方法的引用,O(1)检索且封闭性良好,同时支持更多简单单向映射关系的管理,要是以后出现的新场景都是这种关系,那够扛很久嘞
继续拓展:设计模式
枚举的前提还是基于无状态前提,如果转换的的映射关系不再单纯,变得复杂,枚举的简单映射管理就不work了。
“万事不决,上设计模式”
策略模式-简单实现
首先,依然将传入的字符串作为路由依据,但是传入的内容为了防止有未来扩展,所以构造一个上下文,策略本身基于上下文来处理,借助上文定义的值枚举做策略路由。
/**
* 定义策略接口
*/
public interface SaleTypeParseStrategy{
Integer parse(SaleTypeParseContext saleTypeParseContext);
}
/**
* 策略实现
*/
public class JxSaleTypeParseStrategy implements SaleTypeParseStrategy{
@Override
public Integer parse(SaleTypeParseContext saleTypeParseContext) {
return SaleTypeIntEnum.JX.getCode();
}
}
/**
* 调用上下文
*/
@Data
public class SaleTypeParseContext{
private SaleTypeStrEnum saleTypeStr;
private SaleTypeParseStrategy parseStrategy;
public Integer pasre(){
return parseStrategy.parse(this);
}
}
public static Integer parseSaleType(String saleTypeStr){
SaleTypeStrEnum saleTypeEnum = SaleTypeStrEnum.getByName(saleTypeStr);
SaleTypeParseContext context = new SaleTypeParseContext();
context.setSaleTypeStr(saleTypeEnum);
switch(saleTypeStr){
// 策略路由
case JX:context.setParseStrategy(new JxSaleTypeParseStrategy());break;
// 继续扩展
default:return null;
}
return context.parse();
}
当然,如果是这种没有上下文强依赖的策略,无论是静态单例还是Spring单例都会是一个不错的选择。SaleTypeParseContext本身可以继续扩展内容和其他属性继续丰富参数,策略实现中也可以继续针对更多参数扩充逻辑。
策略工厂-手动容器
策略是个好东西,但是简单实现下,这里依然将策略实现的路由过程交给了调用方来做,那么每增加一种实现,调用点还要继续改,要是恰好有若干调用点就完犊子了,并不优雅,所以搞个中间层容器工厂,解耦一下依赖。
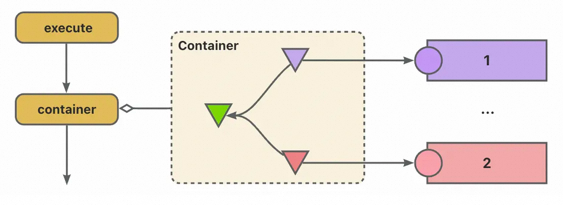
@Component
public static class SaleTypeParseStrategyContainer{
public final static Map<SaleTypeStrEnum, SaleTypeParseStrategy> STRATEGY_MAP = new HashMap<>();
@PostConstruct
public void init(){
STRATEGY_MAP.put(SaleTypeStrEnum.JX, new JxSaleTypeParseStrategy());
// 继续拓展
}
public Integer parse(SaleTypeParseContext saleTypeParseContext){
return Optional.ofNullable(STRATEGY_MAP.get(saleTypeParseContext.getSaleTypeStr())).map(strategy-> strategy.parse(saleTypeParseContext)).orElse(null);
}
}
容器内手动创建各个策略的实现的单例后进行托管,那调用方只需要去构建上下文就好了,实际调用的方法更换为 SaleTypeParseStrategyContainer::parse,那后续无论策略如何丰富,调用方都不需要再感知这部分变化。后续出现了新的策略实现,则在工厂内继续追加路由表即可。
注册与发现&策略工厂-Spring容器
如果考虑到策略会依赖Spring的bean和其他有状态对象,那么这里也可以改成Spring的注入模式,同时继续将“支持哪种情况”由托管方容器移动至策略内部,改成由策略实现自身去注册到容器中。
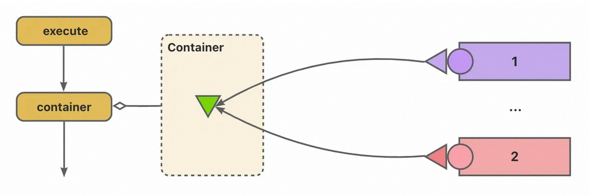
public interface SaleTypeParseStrategy{
Integer parse(SaleTypeParseContext saleTypeParseContext);
// 所支持的情况
SaleTypeStrEnum support();
}
@Component
public class JxSaleTypeParseStrategy implements SaleTypeParseStrategy{
@Override
public Integer parse(SaleTypeParseContext saleTypeParseContext) {
return SaleTypeIntEnum.JX.getCode();
}
@Override
public SaleTypeStrEnum support() {
return SaleTypeStrEnum.JX;
}
}
@Component
public static class SaleTypeParseStrategyContainer{
public final static Map<SaleTypeStrEnum, SaleTypeParseStrategy> STRATEGY_MAP = new HashMap<>();
@Autowired
private List<SaleTypeParseStrategy> parseStrategyList;
@PostConstruct
public void init(){
parseStrategyList.stream().forEach(strategy-> STRATEGY_MAP.put(strategy.support(), strategy));
}
public Integer parse(SaleTypeParseContext saleTypeParseContext){
return Optional.ofNullable(STRATEGY_MAP.get(saleTypeParseContext.getSaleTypeStr())).map(strategy-> strategy.parse(saleTypeParseContext)).orElse(null);
}
}
这样的话,连容器都不用改了,追加策略实现的改动只与当前策略有关,调用方和容器类都不需要感知了,但是缺点就在于如果有俩策略支持的情况相同,取到的是哪个就听天由命了~
注册与发现&责任链
当然如果不能事先知道“支持哪种情况”,只能在运行时判断“是否支持”,将事前判定改为运行时判定,广义责任链会是一个不错的选择,把所有策略排成一排,谁举手说自己能处理就谁处理。
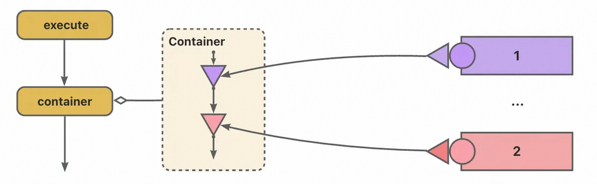
public interface SaleTypeParseStrategy{
Integer parse(SaleTypeParseContext saleTypeParseContext);
// 用于判断是否支持
boolean support(SaleTypeParseContext saleTypeParseContext);
}
@Component
public class JxSaleTypeParseStrategy implements SaleTypeParseStrategy{
@Override
public Integer parse(SaleTypeParseContext saleTypeParseContext) {
return SaleTypeIntEnum.JX.getCode();
}
@Override
public boolean support(SaleTypeParseContext saleTypeParseContext) {
return SaleTypeStrEnum.JX.equals(saleTypeParseContext.getSaleTypeStr());
}
}
@Component
public static class SaleTypeParseStrategyContainer{
@Autowired
private List<SaleTypeParseStrategy> parseStrategyList;
public Integer parse(SaleTypeParseContext saleTypeParseContext){
return parseStrategyList.stream()
.filter(strategy->strategy.support(saleTypeParseContext))
.findAny()
.map(strategy->strategy.parse(saleTypeParseContext))
.orElse(null);
}
}
这样的实现,依然可以将改动收束在策略本体上,修改相对集中,可以无耦地进行扩展。
其他拓展
以上还只是在JAVA语言内去玩一些花样,在当前这种场景下肯定是有过度设计的嫌疑,7行代码可以缩到1行,也可以扩充到70行,所以说:“用代码行数来考量一个程序员是不太合适滴!~”
当然了,也还可以继续借助其他的中间件搞花样,包括但不限于:
- 植入Diamond走走动态配置开关的思路;
- 植入QLExpress搞搞逻辑表达式的思路;
- 把策略实现改成HsfProvider走分布式调用思路;
- 借助一些成熟的网关走服务路由的的调用思路;
就不再此再过多展开了。
参考
侵删
好好的“代码优化”是怎么一步步变成“过度设计”的